
Aplicaciones de Inteligencia Computacional para el … · Los sistemas de cómputo y...
28
Aplicaciones de Inteligencia Computacional para el Minado de Conjuntos de Datos Integralmente Reducidos Angel Kuri-Morales Instituto Tecnológico Autónomo de México [email protected]
Transcript of Aplicaciones de Inteligencia Computacional para el … · Los sistemas de cómputo y...

Aplicaciones de Inteligencia
Computacional para el Minado de
Conjuntos de Datos Integralmente
Reducidos
Angel Kuri-Morales
Instituto Tecnológico Autónomo de México

Agenda
1. Qué es Big Data
1. Big Data está aquí para quedarse
2. El dilema tecnológico
2. Solución Conceptual al dilema
1. Información
2. Entropía
3. Modelado
3. Solución Técnica al dilema
4. Aplicación – Caso de Estudio

Qué es Big Data
En este seminario ya se ha
definido el fenómeno
Big Data.
Datos
Altamente distribuidos
Sin estructura aparente
De gran volumen

Big Data está aquí para quedarse
Grandes volúmenes de datos nacidos de:
Ciencias
Meteorología Genómica
Física Astronomía
Biología
Finanzas
Negocios Economía
Banca Análisis Estadísticos
Redes Sociales
Facebook Twitter

El Dilema Tecnológico
En esencia, el fenómeno Big Data se suscita por
dos razones históricas:
Los sistemas de cómputo y telecomunicaciones (C&T) se
han abaratado en órdenes de magnitud
Los sistemas de C&T se han hecho más eficientes y
poderosos
Esto origina un efecto de “bola de nieve”
Aumenta el número de usuarios
Se invierte más en I&D
Los sistemas se hacen mejores y más baratos…

El efecto “Bola de Nieve”
Lo anterior demanda mejores herramientas para el
almacenamiento, transmisión y tratamiento de
los datos
Estas herramientas demandan mejores
desarrollos
Estos redundan en más datos…
Soluciones tecnológicas
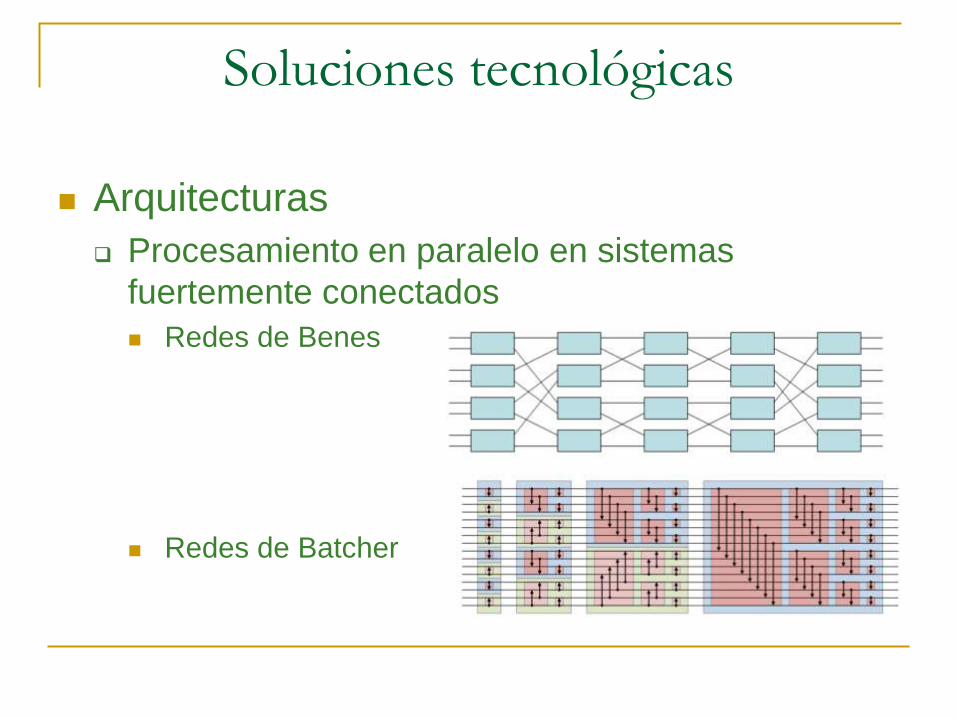
Arquitecturas
Procesamiento en paralelo en sistemas
fuertemente conectados
Redes de Benes
Redes de Batcher

Nuevas tecnologías
Tecnologías:
Cómputo paralelo
Optimización de algoritmos de agrupamiento
Cómputo distribuído
Computación Grid

Nuevos paradigmas
Ópticas (Láser)
Criogénicas (Supercondutores)
Biológicas (Computación con ADN)
Cuánticas (Qubits)

Enfoque tecnológico
En todos estos casos, sin importar qué tan
eficientes sean las tecnologías implicadas, se
alcanzará un límite físico y, eventualmente, será
indispensable encontrar un nuevo enfoque para
tratar Big Data

No es lo mismo “Data” que Información
Hay que exprimir
los datos para
obtener jugo…

Pero una gran
naranja no
necesariamente
implica mucho
jugo

La entropía y la información
En las disciplinas de cómputo es necesaria una definición precisa de lo que entendemos por información. La definición de entropía (información promedio) es
En donde “X” es el mensaje, pi es la probabilidad de que aparezca un símbolo, m es el número de símbolos y n es la cantidad de datos.

Y es posible “exprimir” los datos para
quedarnos con la información relevante
H(bmp) Esta naranja “pesa” 369,994 bytes.
H(jpg) Esta, en cambio, “pesa” solamente 21,895 bytes
¡17:1!

Reducción de los Datos como Alternativa
Práctica
Una posible alternativa es tratar de ser más
eficientes en el tratamiento de la
información.
En, prácticamente, todos los casos la
información contenida en las bases de datos
puede preservarse sin necesidad de usar
todos los datos.

La idea clave es
“En vez de trabajar con una gran cantidad
de datos, trabajemos con la información
equivalente”.
Extraigamos la muestra mínima que nos
proporcione la misma información que los
datos originales

Determinación del tamaño de la
muestra mínima
Podemos entonces plantear la siguiente hipótesis:
“La información contenida en una muestra aleatoria (tomada de una gran base de datos D) de tamaño M es aproximadamente igual a la de D cuando las entropías son similares”.
Y “El comportamiento de las variables de M debe ser similar al de las variables de D”.

Los dos pasos
Paso 1: Encontrar una muestra reducida con
las misma cantidad de información
Paso 2: Modelar las variables del sistema para
certificar que en ambos conjuntos de datos
(D y M) las variables se inter-relacionan de
manera análoga.
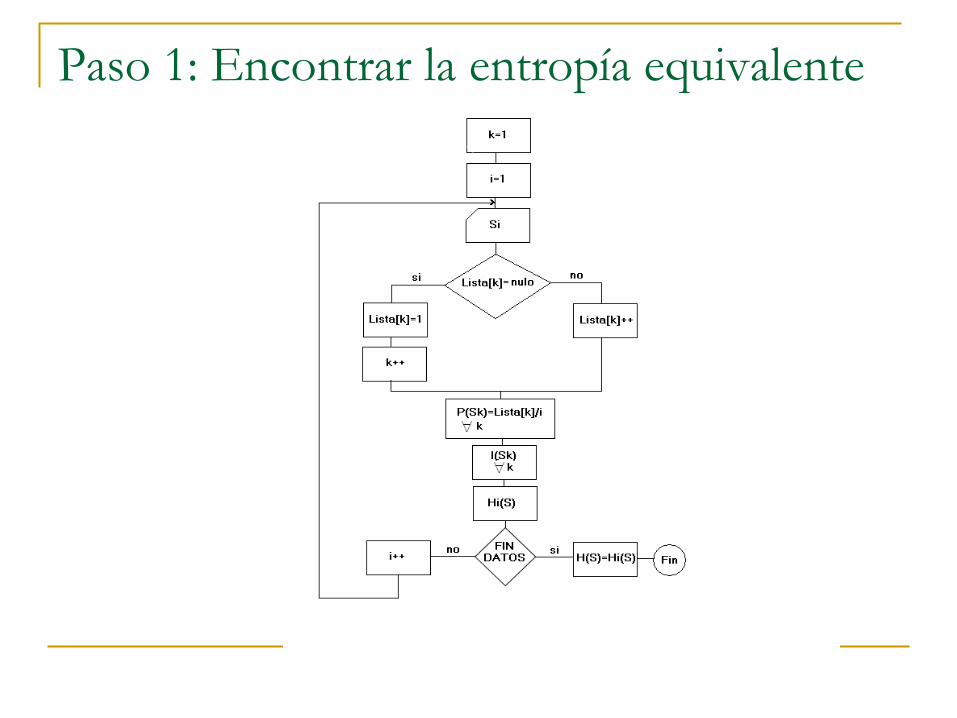
Paso 1: Encontrar la entropía equivalente

Paso 2: Modelar las variables

Publicaciones académicas
Kuri-Morales, A., "An Automated Search Space Reduction Methodology for Large DataBases", Springer, Editor(s)): Perner, Petra, ISBN: 9783642397356, ISSN: 0302-9743, 16/07/2013.
Kuri-Morales, A., "Application of a Method Based on Computational Intelligence for the Optimization of Resources Determined from Multivariate Phenomena", MICAI 2012, Springer, Unpublished, Editor(s)): Batryshin, I. et al, ISBN: 9783642377976, ISSN: 0302-9743, 15/11/2012.
Kuri-Morales, A., Lozano, A., "Sampling for Information and Structure Preservation when Mining Large Data Bases", Springer, 174-183, Editor(s)): Angel Kuri-Morales, ISBN: 3-642-16951-1, ISSN: 0302-9743, 03/11/2010.
Kuri-Morales, A., Erazo-Rodríguez, F., "A Search Space Reduction Methodology for Data Mining in Large Databases", Engineering Applications of Artificial Intelligence, Elsevier, 57-65, ISBN: 9780769534411, ISSN: 0952-1976, 01/02/2009.
Kuri-Morales, A., Rodríguez-Erazo, F., "A Search Space Reduction Methodology for Large Databases: A Case Study", Advances in Data Mining: Theoretical Aspects and Applications, LNAI 4597, Best Paper Award, Springer, 199-213, Editor(s)): Petra Perner, ISBN: 3-540-73434-1, ISSN: 0302-9743, 14/07/2007.

CASO de Estudio
Se efectuó un proyecto de minería de datos para
una empresa multi-nacional (a la que nos
referiremos como “La Compañía”).
La Compañía tiene grandes bases de datos
incluyendo datos acerca de servicios prestados,
facturación (registrados en períodos de varios
años) y otros muchos datos pertinentes.

Validación Estadística
Modelo 1: obtenido de la muestra
Modelo 2: obtenido de los datos originales
Clust. Modelo
1 (%)
Modelo2
(%) Dif. (%)
A 30 27 3
B 21 20 1
C 15 18 3
D 12 15 3
E 12 12 0
F 10 8 2
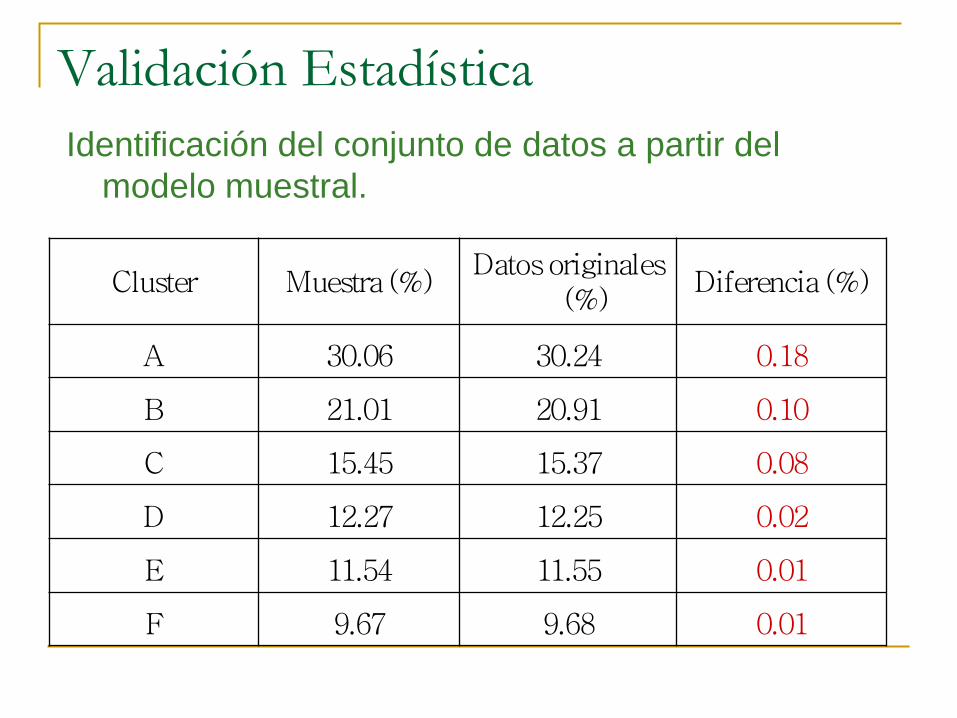
Validación Estadística
Identificación del conjunto de datos a partir del
modelo muestral.
Cluster Muestra (%) Datos originales
(%) Diferencia (%)
A 30.06 30.24 0.18
B 21.01 20.91 0.10
C 15.45 15.37 0.08
D 12.27 12.25 0.02
E 11.54 11.55 0.01
F 9.67 9.68 0.01

Aplicación Práctica
A raíz del estudio descrito, la Compañía disminuyó los tiempos de proceso de sus datos de 35 días a 10.
Consecuentemente, las decisiones estratégicas de la Compañía pueden efectuarse con mayor eficiencia.
Los directivos de la Compañía pueden efectuar análisis personales sin necesidad de acceder a las bodegas de datos y/o a la red de servidores.

Aplicación Práctica
Una vez que se constató la efectividad del método
propuesto, la determinación y uso de la muestra óptima
se pusieron a prueba, a nivel internacional, durante 6
meses.
Debido a los resultados positivos obtenidos, esta
estrategia se adoptó como un estándar en la Compañía.

Conclusiones
La generación de Big Data es un proceso
irreversible.
Las tecnologías de punta irán siendo
remplazadas conforme los volúmenes de
datos se hagan cada vez mayores.
Una alternativa interesante consiste en
identificar la información valiosa cuando la
toma de decisiones estratégicas así lo
amerite.

Conclusiones
Al identificar solamente la información valiosa, es posible eficientar los procesos de manejo de información.
Claramente, los detalles puntuales dejan de estar al acceso de los tomadores de decisiones.
Típicamente estos detalles no influyen en el establecimiento de políticas de información.
Como un beneficio adicional, se evitan problemas asociados a la confidencialidad y la privacía que subyacen a Big Data y se reduce el efecto Big Brother.


















