
Análisis e implementación de un sistema de computation ...
140
Análisis e implementación de un sistema de computation offloading en plataforma de Internet de las Cosas para aplicaciones de monitorización medioambiental OCTUBRE 2020 Benjamín Sánchez Lloréns DIRECTOR DEL TRABAJO FIN DE GRADO: Gabriel Mujica Rojas Benjamín Sánchez Lloréns TRABAJO FIN DE GRADO PARA LA OBTENCIÓN DEL TÍTULO DE GRADUADO EN INGENIERÍA EN TECNOLOGÍAS INDUSTRIALES
Transcript of Análisis e implementación de un sistema de computation ...

Análisis e implementación de un sistema de computation offloading en plataforma de Internet de las Cosas para aplicaciones de monitorización
medioambiental
OCTUBRE 2020
Benjamín Sánchez Lloréns
DIRECTOR DEL TRABAJO FIN DE GRADO:
Gabriel Mujica Rojas
Ben
jam
ín S
ánch
ez L
loré
ns
TRABAJO FIN DE GRADO PARA LA OBTENCIÓN DEL TÍTULO DE GRADUADO EN INGENIERÍA EN TECNOLOGÍAS INDUSTRIALES


Universidad Politécnica de Madrid
Escuela Técnica Superior de Ingenieros Industriales
Departamento de Automática, Ingeniería Eléctrica y Electrónica e Informática Industrial
Grado en Ingeniería en Tecnologías Industriales
Análisis e implementación de un sistema de computation offloading en
plataforma de Internet de las Cosas para aplicaciones de monitorización
medioambiental
Autor: Benjamín Sánchez Lloréns
Director: Gabriel Mujica Rojas
Octubre 2020
Trabajo Fin de Grado


Me lo contaron y lo olvidé; lo vi y lo entendí; lo hice y lo aprendí.
(Confucio)


AGRADECIMIENTOS
A mi tutor por introducirme en el mundo del IoT y especialmente en lo referente al Extreme Edge.
A mi familia y especialmente a mis padres por estar siempre a mi lado.
A mis tíos ingenieros por haberme inculcado la pasión por la ingeniería desde pequeño. Un recuerdo especial para los parientes ausentes; les habría hecho mucha ilusión ver esta memoria finalizada.
A Casilda, por su paciencia y los ánimos recibidos durante la elaboración de este trabajo. A mis compañeros y amigos, por todo su apoyo durante esta etapa.


RESUMEN La globalización de nuestra sociedad está basada en la interconexión de la población mediante herramientas TIC que permiten la utilización de diversas aplicaciones con fines comerciales, industriales, de ocio o de seguridad. Éstas se basan en la conexión de múltiples redes inalámbricas descentralizadas (Wireless Sensor Networks, WSN) formadas por una infinidad de dispositivos o nodos conectados, que conforman el Internet de las cosas (IoT por sus siglas en inglés). Los nodos de estas redes tienen la capacidad de realizar mediciones mediante sensores, procesar información y comunicarse. Como resultado de esta interconexión, se genera una gran cantidad de datos, cuya explotación tiene un gran valor social y económico.
Esta nueva arquitectura del IoT supone una revolución respecto a la anterior, que estaba basada en redes centralizadas muy jerarquizadas, en las que sus dispositivos recogían los datos y los enviaban directamente a la nube para su procesamiento y realizar los cálculos oportunos. La descentralización de las redes, y la imposibilidad de que la nube absorba completamente las tareas relacionadas con el procesamiento y cálculo de los datos, ha provocado un cambio de paradigma, conocido como “Edge Computing”, en el que parte de dichas tareas se ha desplazado hacia el extremo de la red en el que se encuentran los dispositivos, el Edge. Otra parte de estas tareas se realiza en capas superiores de la red.
No obstante, el “Edge Computing” de las WSN tiene que afrontar diversas limitaciones, que están asociadas en general a la portabilidad y bajo coste de los dispositivos, y a que sus nodos operan con tecnologías de baja potencia. Ello conlleva un ancho de banda reducido, una limitada capacidad de procesamiento, unas capacidades restringidas de envío de datos (<10 a 270 Kbps), y su alimentación mediante baterías de baja capacidad. Esta última característica es muy relevante porque la transmisión de los datos consume mayor energía que su procesamiento. Por ello, el paradigma “Edge Computing” determina que se tengan que realizar estrategias específicas para cada red, en función de su objetivo y de la calidad del servicio que deba ofrecer. Estas estrategias tratan de maximizar la duración de la batería de los dispositivos, repartiendo tareas entre los nodos de la red siguiendo las metodologías de “Resource Allocation”, y realizando determinadas tareas de procesamiento en el Edge, pero dejando que las tareas más complicadas de computación o de mayor consumo energético se realicen en las capas superiores de la red, siguiendo las metodologías de “Computation Offloading”. Una forma de solventar los compromisos entre calidad de servicio, procesamiento, computación, transmisión de datos y consumo de batería, es establecer distintos niveles de operación de la red en función de la capacidad de la batería.
La investigación sobre las oportunidades que ofrece el paradigma “Edge Computing” y sus metodologías asociadas (“Resource allocation” y “Computation offloading”) para la gestión de las redes de IoT es de gran interés. Ello se debe a su aplicabilidad práctica en actividades comerciales y servicios públicos, con una gran demanda social.
Una aproximación válida para realizar dicha investigación es la creación de entornos de simulación en los que los desarrolladores comprueben la eficacia y la eficiencia de la aplicación de los conceptos mencionados, y que puedan evaluar su aplicabilidad en casos concretos, asociados a cualquiera de los múltiples usos del IoT. La gran ventaja de este enfoque es que no requiere hacer inversiones reales hasta que quede demostrada su operatividad y viabilidad. Ello permite reducir los costes asociados al desarrollo de las WSN y que las soluciones a aportar no queden limitadas por la elección inicial de unos determinados dispositivos, que podrían no ser óptimos o incluso quedar obsoletos una vez que se implemente la red. Además, posibilitan analizar la influencia de variables aisladas y su interconexión, proporcionando soluciones para dificultades concretas, si bien sus resultados deben ser adaptados antes de ser transferidos a situaciones reales.

En este trabajo se ha creado un entorno de simulación para analizar el comportamiento de una red inalámbrica de sensores de medida de la contaminación atmosférica, combinando distintas estrategias relacionadas con “Edge Computing”. Para ello se utilizó el simulador denominado Cooja que incorpora el sistema operativo Contiki-NG. Para garantizar la aplicabilidad del estudio, la simulación se ha alimentado con los datos reales de contaminantes atmosféricos registrados en la estación de medida “Escuelas Aguirre” de la Red de Vigilancia de la Calidad del Aire del Ayuntamiento de Madrid. Esta estación está clasificada como “urbana” y está muy influenciada por el tráfico de vehículos de su entorno. En la simulación se han utilizado los registros obtenidos en dicha estación relativos a los promedios horarios de las concentraciones de los cinco contaminantes atmosféricos (SO2, NO2, O3, PM10 y PM2,5) en los que se basa el Índice de Calidad del Aire, que determina las acciones que las autoridades deben adoptar bajo condiciones episódicas de contaminación.
La simulación contempló el análisis de una red inalámbrica de cinco sensores (nodos sensor), con cinco nodos de enlace, todos ellos conectados a un Gateway o nodo coordinador, que hace de interface entre dichos nodos y las capas superiores de la red. Los nodos de los sensores estaban alimentados por una batería de 2.600 mAh. La red inalámbrica simulada serviría de apoyo a las medidas realizadas en las estaciones de medida de calidad del aire, ya que se ha demostrado que las medidas registradas en las estaciones pueden no ser representativas de la exposición de los habitantes de los barrios circundantes.
Para optimizar la operatividad de la red simulada se establecieron los diferentes criterios y especificaciones, atendiendo a la calidad de servicio que debe dar la red y la optimización de la capacidad de la batería.
En lo que respecta a la calidad del servicio de la red, al tratarse de datos de interés para la salud humana, los datos deben transmitirse siempre a las capas superiores pero el grado de procesamiento en el Edge y la velocidad de transmisión de los datos puede ser diferente, en función de los niveles de contaminación alcanzados.
Para la optimización del uso de la batería, la simulación realizada contempla empaquetar los datos captados por el nodo hasta un máximo de 5 horas, para posteriormente transmitirlos al Gateway. No obstante, para garantizar la calidad del servicio, la frecuencia de transmisión de los datos se adapta a las condiciones de calidad del aire registradas por los nodos. Esta es mayor en condiciones episódicas de contaminación que cuando la calidad del aire no entraña riesgos para la salud.
Además, la frecuencia de transmisión de datos atendió a la dinámica de cada contaminante. Ello supuso el análisis previo de los datos de los cinco contaminantes atmosféricos seleccionados. Así, los niveles de SO2 no alcanzaron nunca valores que comprometieran la salud humana, los niveles de PM10 y PM2,5 que alcanzaron niveles de riesgo para la salud estuvieron estrechamente asociados entre sí, al tiempo que no se apreciaron variaciones relevantes en sus ciclos diarios, semanales y estacionales. Por el contrario, las concentraciones de NO2 mostraron sus máximos diarios asociados al tráfico, especialmente en los meses de otoño e invierno. Finalmente, los niveles de O3 fueron máximos desde las horas centrales del día hasta el atardecer en los meses de verano. Estas dinámicas fueron tenidas en cuenta en la frecuencia de transmisión de datos.
Así, la simulación consideró la mayor probabilidad de que se produjera una menor frecuencia de emisión de datos de SO2 durante todo el año; una mayor frecuencia en la emisión de datos de NO2 durante los días laborables de la semana, y especialmente en otoño e invierno, además de una mayor frecuencia de emisión de datos de O3 desde las horas centrales del día hasta el anochecer en los meses de verano. No se aplicaron restricciones a la frecuencia de emisión de los datos registrados por los sensores de PM10 y PM2.5.

El flujo de trabajo a realizar por la red de sensores es el siguiente: 1) los nodos asociados a los sensores de contaminantes recogerían cada segundo los registros de los sensores de los contaminantes que tienen asociados; 2) Cálculo del promedio horario correspondiente a dichos registros; 3) Cálculo del Índice de Calidad correspondiente a cada contaminante; 4) Comparación de los Índices de Calidad del aire de cada contaminante y comprobar si se producen superaciones de sus umbrales; 5) Cálculo del Índice de Calidad general (considerando todos los contaminantes) y 6) Determinación del modo de operación de la red. El máximo número de datos que podía almacenar un determinado nodo fue de cinco datos ya que es conveniente priorizar la emisión de datos a las capas superiores de la red lo más rápidamente posible para que se pueda alertar con prontitud a la población en el caso de que se produzcan situaciones episódicas.
Atendiendo a los criterios de calidad de servicio y optimización de batería, se establecieron cuatro modos (1 a 4) de procesamiento de cada nodo y de transmisión al coordinador de la red. El modo 1 suponía la transmisión directa al Gateway de los datos registrados cada 10 segundos. Por el contrario, el modo 4 en el que el nodo de contaminante realiza las tareas de computación que abarcan desde los registros de cada 10 segundos hasta el cálculo Índice de Calidad de cada contaminante. En todos los modos, el Gateway es el que calcula el Índice de Calidad de la red, a partir de la información individual recibida de cada nodo asociado a un sensor específico para cada contaminante, y determina el modo de operación de la red. Debido a la mayor frecuencia en el envío de datos del modo 1, su consumo energético es mucho mayor que el del modo 4.
Además, se establecieron dos niveles de operación de la red en función de la capacidad restante de la batería de los nodos. Cuando esta era mayor del 50%, la red de sensores operaba según los criterios mencionados anteriormente. Sin embargo, cuando la capacidad restante de la batería era inferior al 50% o se producía un pico de consumo igual o superior a 4 mA, la red entraba en un modo de operación de menor consumo energético, primando los modos de trabajo 3 y 4.
A partir de estos criterios, se implementó un algoritmo de optimización de la red de sensores mediante la creación de un programa escrito en código Contiki-NG. Los resultados del consumo de batería fueron obtenidos al implementar este algoritmo fueron comparados con los consumos correspondientes a cada uno de los modos de trabajo.
Los resultados de las simulaciones de la caída de la batería para el nodo de NO2 mostraron grandes diferencias entre los distintos modos de trabajo. El modo 4 fue el de determinó un menor consumo; el agotamiento completo de la batería se produjo a los 268 días, frente a 179, 91 y 6 días para los modos 3, 2, y 1, respectivamente.
La simulación para evaluar las ventajas del algoritmo implementado para optimizar la gestión de la red tuvo una duración de 40 horas, correspondiéndose con 2.771 horas de mediciones de contaminantes. Ello muestra la robustez del código empleado. Se apreció el distinto comportamiento de los distintos nodos asociados a los contaminantes. La batería de los nodos de NO2, PM10 y PM2.5 decayó al 50% de su capacidad entre 40 y 46 d, mientras que este declive se produjo entre 5 y 11 días más tarde que en los en el SO2 y O3. En efecto, el tiempo de caída de la batería al 50% de su capacidad es muy similar en el caso del SO2 y el O3 (51 días), el tiempo en que la batería decaería a ese nivel si la red estuviera funcionando continuamente en el modo 4 (54 días).

Comparación del decaimiento de la capacidad de la batería entre los tres modos de operación de los nodos y los
resultados obtenidos al emplear el algoritmo diseñado para optimizar la gestión de la red
Ello se debe a que al ser las concentraciones de NO2, PM10 y PM2.5 más elevadas que las de los otros dos contaminantes, inducen con mayor frecuencia situaciones episódicas de contaminación, que determinan que sus nodos asociados trabajen un mayor número de horas en los modos 2 y 3 que los otros nodos, tal y como determinan las condiciones del algoritmo implementado en la simulación. Por ello, su frecuencia de transmisión de datos en dichos modos fue casi el doble, y ello conlleva también un mayor consumo de batería.
Desde el punto de vista de ahorro del consumo energético de la batería, el algoritmo implementado permitió mantener los niveles de batería cercanos a los del modo 4 (mínimo consumo) sin que resintiera la calidad del servicio de la red.
En efecto, cuando los niveles de contaminación alcanzaron niveles de riesgo para la salud, los nodos pasaron a modos de operación asociados permitiendo transmitir los datos con mucha mayor frecuencia. Ello facilitaría que las autoridades sanitarias alertasen a la población de dichos riesgos, y activasen los protocolos de actuación oportunos.
El entorno de simulación creado en este trabajo tiene un gran potencial, ya que permite comparar diferentes algoritmos diseñados para optimizar la gestión de otras redes, incluso pertenecientes a ámbitos distintos al de la contaminación ambiental.

ÍNDICE DE CONTENIDO 1 Introducción .......................................................................................................................... 1
1.1 Redes inalámbricas de sensores .................................................................................. 1 1.2 Optimización de las redes de sensores mediante las metodologías de “Resource allocation” y “Computation offloading” .................................................................................... 2 1.3 Motivación ................................................................................................................... 3 1.4 Objetivos ...................................................................................................................... 3
2 Estado del arte ...................................................................................................................... 5 2.1 Gestión de recursos en el Edge: Resource Allocation y Computation Offloading ....... 6
2.1.1 Computation Offloading .......................................................................................... 7 2.1.2 Resource Allocation ................................................................................................. 7
3 Metodología ......................................................................................................................... 9 3.1 Sistema operativo Contiki-NG ...................................................................................... 9
3.1.1 Instalación de Contiki-NG ...................................................................................... 10 3.2 Diseño básico de una red inalámbrica de sensores. .................................................. 11
3.2.1 Esquema de la red ................................................................................................. 11 3.2.2 Protocolos empleados para la comunicación en la red: IPv6, 6LoWPAN, UDP, RPL 12 3.2.3 Conexión entre la red inalámbrica de sensores simulada en Cooja y una red externa 13
3.3 Validación del entorno de simulación mediante la utilización de datos reales de contaminación atmosférica registrados en la ciudad de Madrid............................................ 19
3.3.1 Contaminación atmosférica en la ciudad de Madrid ............................................ 19 3.3.2 Sistema de Vigilancia de la Calidad del Aire del Ayuntamiento de Madrid. ......... 20 3.3.3 Índice Nacional de Calidad del Aire. ...................................................................... 22 3.3.4 Propuesta de mejora de la red de medida de la contaminación atmosférica de la ciudad de Madrid mediante la incorporación de microsensores ....................................... 24 3.3.5 Descarga y preprocesamiento de los datos de mediciones de contaminación atmosférica aportados por el Ayuntamiento de Madrid. ................................................... 27 3.3.6 Selección de las estaciones a considerar en la simulación. Análisis de los datos de contaminación atmosférica previamente preprocesados. ................................................. 29
3.4 Simulación de la captación de datos por parte de los nodos equipados con sensores para la medición de contaminantes atmosféricos. ................................................................. 47 3.5 Modelado de la batería de los nodos equipados con sensores de contaminantes atmosféricos. ........................................................................................................................... 48
3.5.1 Consumos reales del Sky Mote .............................................................................. 49 3.5.2 Cuantificación del tiempo que permanece activa cada componente de un nodo 49 3.5.3 Modelo de la batería ............................................................................................. 50
3.6 “Resource allocation” y “Computation offloading” ................................................... 51 3.6.1 Modos de procesamiento del nodo y transmisión al Gateway............................. 51

3.6.2 Algoritmo que establece el nivel de operación de la red y el modo de trabajo de cada uno de los nodos. ........................................................................................................ 53
3.7 Programación de los nodos que contienen los sensores atmosféricos. .................... 55 3.7.1 Proceso encargado de la gestión de la fecha y hora del nodo .............................. 56 3.7.2 Proceso que contiene el ciclo de trabajo del nodo ............................................... 58 3.7.3 Recepción de mensajes por el nodo ...................................................................... 60
3.8 Programación del nodo Gateway. ............................................................................. 62 3.8.1 Inicialización del nodo Gateway de la red. ............................................................ 62 3.8.2 Thread de Comunicación ....................................................................................... 63 3.8.3 Thread de Procesamiento ..................................................................................... 65
4 Resultados y discusión ....................................................................................................... 69 4.1 Consumo de batería según el modo de trabajo. ....................................................... 69 4.2 Ventajas de la aplicación del efecto del algoritmo basado en “resource allocation” y “computation offloading”. ...................................................................................................... 70
4.2.1 Simulación para comprobar la optimización del consumo de batería de la Red Inalámbrica de Sensores aplicando el algoritmo basado en “Resource Allocation” y “Computation offloading”. .................................................................................................. 70
5 Conclusiones y líneas futuras ............................................................................................. 75 5.1 Conclusiones .............................................................................................................. 75 5.2 Líneas futuras ............................................................................................................. 75
6 Bibliografía .......................................................................................................................... 77 7 Planificación temporal y presupuesto ............................................................................... 81
7.1 Planificación de actividades ....................................................................................... 81 7.2 Planificación temporal (Diagrama de Gantt) ............................................................. 83 7.3 Presupuesto ............................................................................................................... 84
Anexo 1 ....................................................................................................................................... 85 Anexo 1.1: Código en C con el que se programa el nodo para comunicación simple entre WSN y Gateway................................................................................................................................ 85 Anexo 1.2: Código en C con el que se programa el Border Router ......................................... 87 Anexo 1.3: Código en C con el que se programan los nodos sensor....................................... 89 Anexo 1.4: Código en Python con el que se programa el Gateway ........................................ 97 Anexo 1.5: Código en C con el que se programan los nodos enlace ..................................... 117
Anexo 2 ..................................................................................................................................... 119 Anexo 2.1: Código Python para el preprocesado de las mediciones de contaminación atmosférica aportadas por el Ayuntamiento de Madrid ...................................................... 119

ÍNDICE DE FIGURAS
Figura 1: Capas del IoT .................................................................................................................. 5 Figura 2: Inicialización de Contiki-NG desde el "Windows Power Shell" .................................... 10 Figura 3: "Windows Power Shell" mostrando el funcionamiento correcto del ejemplo "Hello world" .......................................................................................................................................... 10 Figura 4: Ventana con el simulador Cooja .................................................................................. 11 Figura 5: Esquema de la red ........................................................................................................ 12 Figura 6: Esquema de conexión entre la red inalámbrica de sensores y otra red externa ......... 13 Figura 7: Captura de pantalla del Serial Socket (SERVER) de Cooja ............................................ 14 Figura 8: Terminal de Docker ejecutando tunslip ....................................................................... 15 Figura 9: Serial Socket (SERVER) de Cooja con un cliente conectado ......................................... 15 Figura 10: Dirección de red de cada nodo en la ventana network de Cooja .............................. 16 Figura 11: Respuesta ante un ping al nodo 1 .............................................................................. 16 Figura 12: Respuesta ante un ping al nodo 2 .............................................................................. 16 Figura 13: Comunicación bidireccional entre el nodo Cooja y el nodo Python .......................... 17 Figura 14: Código del nodo Python. Hace eco de los mensajes que recibe ................................ 17 Figura 15: terminal del nodo Python .......................................................................................... 18 Figura 16: Mote Output de Cooja ............................................................................................... 18 Figura 17: Wireshark ................................................................................................................... 19 Figura 18: Plano con las estaciones de calidad aire del Ayuntamiento de Madrid. Fuente [33] 21 Figura 19: Dataframe de pandas con los datos correspondientes al año 2019 .......................... 29 Figura 20: Proceso de importación de los datos previamente preprocesados, para proceder a su análisis ......................................................................................................................................... 30 Figura 21: Variación del Índice de Calidad del Aire de SO2 en las estaciones de las Escuelas Aguirre (Estación 8) y de la de la Casa de Campo (estación 24) en función del día de la semana .......... 36 Figura 22: Variación del Índice de Calidad del Aire de NO2 en las estaciones de las Escuelas Aguirre (Estación 8) y de la de la Casa de Campo (estación 24) en función del día de la semana ..................................................................................................................................................... 37 Figura 23: Variación del Índice de Calidad del Aire de PM10 en las estaciones de las Escuelas Aguirre (Estación 8) y de la de la Casa de Campo (estación 24) en función del día de la semana ..................................................................................................................................................... 38 Figura 24: Variación del Índice de Calidad del Aire de PM2,5 en las estaciones de las Escuelas Aguirre (Estación 8) y de la de la Casa de Campo (estación 24) en función del día de la semana ..................................................................................................................................................... 39 Figura 25: Variación del Índice de Calidad del Aire de O3 en las estaciones de las Escuelas Aguirre (Estación 8) y de la de la Casa de Campo (estación 24) en función del día de la semana .......... 40 Figura 26 Histogramas con la frecuencia (número de horas) correspondiente a cada categoría de Índice de Calidad del Aire (IC) durante el invierno en las estaciones de medida de la contaminación atmosférica de Escuelas Aguirre (Estación 8) y Casa de campo (Estación 24). El IC varía entre 1 (“muy malo”) y 5 (“muy bueno”). .......................................................................... 41 Figura 27: Histogramas con la frecuencia (número de horas) correspondiente a cada categoría de Índice de Calidad del Aire (IC) durante la primavera en las estaciones de medida de la contaminación atmosférica de Escuelas Aguirre (Estación 8) y Casa de campo (Estación 24). El IC varía entre 1 (“muy malo”) y 5 (“muy bueno”). .......................................................................... 42 Figura 28: Histogramas con la frecuencia (número de horas) correspondiente a cada categoría de Índice de Calidad del Aire (IC) durante la primavera en las estaciones de medida de la contaminación atmosférica de Escuelas Aguirre (Estación 8) y Casa de campo (Estación 24). El IC varía entre 1 (“muy malo”) y 5 (“muy bueno”). .......................................................................... 43 Figura 29: Histogramas con la frecuencia (número de horas) correspondiente a cada categoría de Índice de Calidad del Aire (IC) durante la primavera en las estaciones de medida de la

contaminación atmosférica de Escuelas Aguirre (Estación 8) y Casa de campo (Estación 24). El IC varía entre 1 (“muy malo”) y 5 (“muy bueno”). .......................................................................... 44 Figura 30: Evolución de los promedios horarios de los Índices de Calidad de los contaminantes considerados, registrados en las estaciones de medida de Escuelas Aguirre (Estación 8) y Casa de Campo (Estación 24) en las cuatro estaciones del año. ......................................................... 46 Figura 31: Cadena de caracteres correspondiente al instante en el que se inicializa el nodo. .. 47 Figura 32: Representación de los cuatro bloques de datos en los que se divide el mes. ........... 48 Figura 33: Cadena de caracteres en la que un nodo equipado con sensores almacena las mediciones horarias de un contaminante atmosférico, después de recibir los datos correspondientes al último bloque de días. ................................................................................ 48 Figura 34: Curva de descarga de la batería CR2032 en condiciones de intensidad constante o heterogénea [43] ........................................................................................................................ 50 Figura 35: Criterios de cambio en el nivel de operación de la red .............................................. 53 Figura 36: Nivel de operación de la red con un mayor consumo energético ............................. 54 Figura 37: Nivel de operación de la red con un menor consumo energético ............................. 55 Figura 38: Sección del código de un nodo sensor donde se especifica su estación y el contaminante que mide .............................................................................................................. 56 Figura 39: “Defines" en los que se establece el umbral de concentración a partir del cual el nodo envía las mediciones almacenadas al Gateway, independientemente del modo de trabajo en el que se encuentre ......................................................................................................................... 56 Figura 40: Estructura del código de un nodo sensor................................................................... 56 Figura 41: Proceso que gestiona la fecha y hora en los nodos equipados con sensores de contaminación atmosférica ......................................................................................................... 58 Figura 42: Ciclo de trabajo de los nodos equipados con sensores de contaminación atmosférica ..................................................................................................................................................... 60 Figura 43: Gestión de los mensajes que reciben los nodos equipados con sensores de contaminación atmosférica ......................................................................................................... 61 Figura 44: Estructura del código Python del Gateway ................................................................ 62 Figura 45: Thread de comunicación del nodo coordinador de la red o Gateway ....................... 64 Figura 46: Gestión de las listas que almacenan los mensajes recibidos por el nodo coordinador de la red o Gateway .................................................................................................................... 65 Figura 47: Thread de procesamiento .......................................................................................... 67 Figura 48: Consumo estimado de un nodo trabajando en cada uno de los modos ................... 69 Figura 49: Disposición de nodos para la simulación de la red diseñada ..................................... 71 Figura 50: Cobertura del nodo 11 (parte izquierda) y del nodo de enlace 5 (parte derecha) .... 71 Figura 51: Extracto del fichero .csv generado por uno de los nodos .......................................... 72 Figura 52: Decaimiento de la batería los nodos de los cinco contaminantes atmosféricos considerados ............................................................................................................................... 72 Figura 53: Visualización de cambios entre modos de operación del nodo de SO2 (parte superior) y detalle de tiempo de permanencia en cada modo. Datos de la simulación completa. ........... 73 Figura 54: Visualización de cambios entre modos de operación del nodo de NO2 (parte superior) y detalle de tiempo de permanencia en cada modo. Datos de la simulación completa. ........... 73 Figura 55: Comparación del decaimiento de la capacidad de la batería entre los tres modos de operación de los nodos y el algoritmo diseñado para optimizar la gestión de la red. ............... 74 Figura 56: EDP del proyectoPlanificación temporal (Diagrama de Gantt) .................................. 82 Figura 57: Diagrama de Gantt ..................................................................................................... 83

ÍNDICE DE TABLAS Tabla 1: Dirección de memoria de cada nodo para red interna de Cooja y para la red externa a Cooja ........................................................................................................................................... 16 Tabla 2: Clasificación de las estaciones según su fin. .................................................................. 22 Tabla 3: Índice Nacional de Calidad del Aire según cada contaminante. Orden TEC/351/2019, de 18 de marzo. ................................................................................................................................ 23 Tabla 4: Umbrales para cada contaminante que componen el IC para la protección de la salud. Fuente [35]. ................................................................................................................................. 24 Tabla 5: Microsensores utilizados en la bibliografía para medir los contaminantes atmosféricos más relevantes ............................................................................................................................ 25 Tabla 6: Formato de los ficheros con los datos de contaminación atmosférica del Ayuntamiento de Madrid .................................................................................................................................... 28 Tabla 7: Contaminantes que puede medir cada Estación de Calidad del Aire del Ayuntamiento de Madrid .................................................................................................................................... 32 Tabla 8: Valor de la columna "EST_ANO" según el mes al que pertenecen los datos de las mediciones de un determinado contaminante atmosférico. ..................................................... 33 Tabla 9: Valor de la columna "IC_XX" para la hora XX según el Índice Nacional de Calidad del Aire. ..................................................................................................................................................... 34 Tabla 10: Consumos del Sky Mote según [40] ............................................................................ 49 Tabla 11: Duración de la batería en días para cada modo de operación del nodo .................... 70 Tabla 12: Comparación del tiempo (días) de caída de la batería (50% y 78%) de los nodos de los diferentes contaminantes. .......................................................................................................... 73 Tabla 13: Frecuencia (nº de horas) en que los nodos de los cinco contaminantes trabajaron en los modos de operación 2, 3 y 4 .................................................................................................. 73 Tabla 14: Coste asociado al software empleado ......................................................................... 84 Tabla 15: Coste asociado a la amortización de equipos ............................................................. 84 Tabla 16: Coste asociado al equipo de ingeniería ....................................................................... 84


Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 1
1 Introducción
La globalización propia del siglo XXI se caracteriza por la interconexión de toda su población a través de herramientas TIC que permiten la utilización de múltiples aplicaciones con fines comerciales, industriales, de ocio o de seguridad.
En la actualidad, existen una gran cantidad de dispositivos generando datos continuamente. Estos datos pueden provenir de sensores acoplados a smartphones o smartwatches, coches conectados, Smart Grids, Smart Cities o plataformas de industria 4.0. Los datos generados pueden ser muy diversos: relacionados con la salud, actividades deportivas, transacciones bancarias, consumo de energía, etc. Se espera que el número de dispositivos conectados aumente enormemente en el futuro; para el año 2022 se espera que su número supere los 22 billones [1].
Normalmente los datos son utilizados por el propio usuario. No obstante, el análisis del conjunto de las grandes poblaciones de datos tiene un gran valor añadido, al permitir el seguimiento de la trazabilidad de las actividades humanas. Su valor comercial es muy elevado y por ello se discute si el usuario inicial tiene derecho a acceder a este valor al ser su proveedor. Los datos tienen también un gran valor social porque permiten identificar necesidades, planificar mejor las ciudades, la movilidad, la distribución de productos y servicios, la logística e incluso predecir las tendencias futuras.
En realidad, las aplicaciones asociadas al IoT pueden ser infinitas, e incluso entrar en el ámbito epidemiológico. En el momento de redactarse este trabajo, existe una aplicación que permite trazar si una persona está en riesgo por haber tenido contacto directo con personas infectadas por COVID-19. Todo este potencial es posible gracias al grupo de tecnologías encuadradas bajo la denominación internacional Internet of Things (IoT). El IoT es una mezcla de hardware y software que permite la interconexión de una gran cantidad de dispositivos muy heterogéneos, desde pequeños dispositivos limitados en cuanto a recursos y tecnologías de comunicación, hasta superordenadores en la nube [2].
1.1 Redes inalámbricas de sensores
Gracias a los avances de los sistemas electromecánicos, las comunicaciones inalámbricas, y la electrónica digital, se ha hecho posible el desarrollo de pequeños nodos sensores de bajo coste y consumo, multifuncionales y con capacidad de comunicarse a corta distancia [3]. Estos nodos sensores tienen la capacidad de realizar mediciones mediante sensores, procesar información y comunicarse. Ello permite la creación de redes inalámbricas de sensores o Wireless Sensor Networks (WSN) basadas en la colaboración entre nodos sensores. En la nomenclatura actual, los nodos sensores formarían parte de los dispositivos que conforman el Edge del IoT [4].
Los nodos de la red inalámbrica de sensores tienen la ventaja de que al tener capacidad de procesamiento, no tienen que enviar necesariamente los datos en crudo recogidos por el sensor al nodo encargado de fusionarlos con los de otros nodos. No obstante, tienen una capacidad de procesamiento limitada y, por ello, parte de esta tarea debe ser realizada en otras capas jerárquicamente superiores del IoT. El envío de datos a estas capas supone un segundo reto, ya que los nodos sensor operan con tecnologías inalámbricas de baja potencia. Ello supone una capacidad muy limitada de envío de datos por unidad de tiempo (<10 a 270 Kbps), independientemente de que estos sean crudos o procesados [4].

Capítulo 1: Introducción
ETSII UPM 2
Una limitación adicional de estos nodos sensor es que tienen una batería con una capacidad muy reducida [4]. Por ello, este tipo de redes debe primar el bajo consumo energético frente a otras métricas de las redes tradicionales, como la latencia o el rendimiento. Para alargar la vida de la batería es necesario optimizar el tiempo de comunicación para transmitir los datos a otras capas superiores del IoT, ya que este es el factor que demanda un mayor gasto de energía. Para lograr el objetivo de mantener un bajo consumo energético es necesario implementar o recurrir a sofisticados protocolos de comunicación altamente eficientes y capaces de gestionar las comunicaciones entre un gran número de nodos.
1.2 Optimización de las redes de sensores mediante las metodologías de “Resource allocation” y “Computation offloading”
Una forma de solventar las limitaciones ya comentadas del uso de nodos sensores es establecer una arquitectura de IoT en la que estos estén conectados a capas intermedias (Gateways). Estas capas permiten la conexión de los nodos sensor con otras redes, al tiempo que proporcionan mayor capacidad de procesamiento.
La conexión de los nodos sensor con el Gateway permite explotar al máximo las capacidades de procesamiento en el Edge del IoT. De hecho, se tiende a que todas las tareas relacionadas con el procesado de los datos y los cálculos asociados se realicen de forma descentralizada en el Edge, siguiendo un paradigma denominado Edge Computing [5]. No obstante, aún es necesario contar con la capacidad de almacenamiento y la mayor capacidad de computación de las capas superiores.
Para optimizar los recursos de procesamiento y computación del Edge, las tareas asociadas se pueden descomponer en subtareas que pueden ser derivadas (offloaded) a otros equipos del Edge para conseguir una ejecución más eficiente. La aplicación de las metodologías de Resource Allocation y Computation offloading contribuyen a mejorar esta eficiencia [5].
Los métodos de Resource Allocation se dirigen a optimizar los recursos de computación del Edge (procesamiento, almacenamiento y ancho de banda de la red) en función del consumo de energía, la relevancia de los retrasos en la ejecución del procesado y el coste de descargar determinadas tareas en otras capas superiores [6]. Los métodos de Computation Offloading se refieren a la descarga hacia el Edge o a los servidores del Edge de las tareas de computación intensiva o sensibles a los tiempos de latencia [7].
Las aplicaciones concretas de ambas metodologías dependen del objetivo de la red de microsensores, y de las limitaciones de batería y velocidad de transmisión de sus dispositivos. Normalmente, las redes de sensores son muy heterogéneas, dado que sus dispositivos son muy diversos, con distintos tiempos de recepción y procesado de datos, y consumos energéticos. Ello hace que la gestión de la red sea muy compleja.
Existen diversos sistemas operativos para gestionar las redes inalámbricas de nodos sensor, con tendencia a especializarse en optimizar el rendimiento de aspectos específicos o de determinados tipos de redes. Los tres más comúnmente utilizados en el Edge del IoT son Contiki, RIOT y Zephyr [8]. El sistema operativo Contiki-NG, está especialmente concebido para redes inalámbricas de sensores formadas por nodos sensor muy limitados en recursos, y ha ido evolucionando para dar soporte a nodos de mayor potencia de procesamiento como los actuales [9].
La investigación acerca de los beneficios de la utilización de las metodologías de Resource Allocation y Computation offloading en el Edge se puede realizar basándose en redes reales o simuladas. La utilización de redes reales tiene la ventaja de su aplicabilidad, pero en cambio la optimización no puede ser directamente aplicable a otras redes, debido a la gran cantidad de variables interactuantes y a su especificidad. Por el contrario, los trabajos realizados en entornos

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 3
de simulación permiten aislar variables y proporcionar soluciones para dificultades concretas, si bien sus resultados deben ser adaptados antes de ser transferidos a situaciones reales. En este trabajo hemos optado por una aproximación intermedia, mediante la creación de un entorno de simulación alimentado con datos reales de la Red de Vigilancia de la Calidad del Aire del Ayuntamiento de Madrid. Para ello se utilizó el simulador denominado Cooja que utiliza el sistema operativo Contiki-NG.
1.3 Motivación
El presente trabajo tiene por finalidad crear un entorno de simulación que permita analizar las ventajas de las metodologías de Resource Allocation y Computation Offloading en el Edge.
La creación de dicho entorno facilitará a los futuros desarrolladores comprobar la eficacia y eficiencia de diferentes conceptos de WSN, así como evaluar su aplicabilidad a casos concretos asociados a cualquiera de los múltiples usos del IoT. La gran ventaja de este enfoque es que no requiere hacer inversiones reales hasta que quede demostrada su operatividad y viabilidad. Ello permite reducir los costes asociados al desarrollo de las WSN y que las soluciones a aportar no queden limitadas por la elección inicial de unos determinados dispositivos, que podrían no ser óptimos o incluso quedar obsoletos una vez que se implemente la red.
La investigación sobre los beneficios de las estrategias asociadas a la utilización de los conceptos de Resource Allocation y Computation Offloading se realizó simulando una red inalámbrica conformada por microsensores para la medida de contaminantes atmosféricos. En las simulaciones se utilizaron datos reales de la Red de Vigilancia de la Calidad del Aire del Ayuntamiento de Madrid [31]. Desde el punto de vista de la arquitectura del IoT, este tipo de redes suponen importantes retos por la necesidad de recoger y procesar sus datos con la adecuada velocidad, especialmente en situaciones episódicas de contaminación atmosférica. Además, la dinámica de los distintos contaminantes e incluso los propios analizadores utilizados para su medida, determinan una gran heterogeneidad en el comportamiento de la red. Su complejidad determina plantear distintas estrategias para optimizar su gestión, lo que la hace ser especialmente adecuada para los objetivos de este proyecto.
1.4 Objetivos
El objetivo general de este proyecto es el diseño, desarrollo y simulación de una red inalámbrica de sensores formada por múltiples nodos y un Gateway. Este último contará con un algoritmo que gestione la red según los principios de Computation Offloading y Resource Allocation, asegurando al tiempo la calidad del servicio.
Así mismo, se han planteado los siguientes objetivos específicos:
• Diseñar una red inalámbrica de sensores para la medición de distintos contaminantes atmosféricos.
• Recopilar los datos reales de los contaminantes atmosféricos en la ciudad de Madrid y analizar su dinámica diaria, semanal y estacional.
• Establecer comunicación entre dos redes: la red inalámbrica de sensores (simulada en Cooja) y la red externa en la que se encuentra el Gateway (simulado en el ordenador).
• Implementar un modelo que caracterice la capacidad de la batería de cada nodo teniendo en cuenta sus consumos energéticos.
• Crear e implementar distintos modos de trabajo de los nodos, estableciendo diferentes cargas de procesamiento y comunicación.
• Diseño e implementación de un algoritmo que permita una gestión de la red basada en Resource Allocation y Computation Offloading, manteniendo su calidad de servicio.

Capítulo 1: Introducción
ETSII UPM 4

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 5
2 Estado del arte En los inicios del Cloud Computing, los dispositivos del IoT simplemente se encargaban de recoger datos y enviarlos a la nube, donde eran procesados y almacenados. Sin embargo, esta aproximación está limitada porque el procesamiento en la nube de todos los datos generados por la inmensa cantidad de dispositivos conectados actualmente requeriría de un ancho de banda, una velocidad de procesamiento y almacenamiento inalcanzables, además de una gran energía total consumida, con elevados costes. Por otro lado, está arquitectura centralizada es incompatible con las rápidas respuestas y bajas latencias necesarias para ciertas aplicaciones, ya que puede reducir la fiabilidad de los datos [4]. Además, lleva asociada posibles problemas de privacidad y seguridad [5].
Para superar estas limitaciones se tiende a utilizar un IoT basado en cuatro capas distintas (Figura 1) que forman un continuo desde los dispositivos hasta la nube [10].
Edge
Fog
Cloud
Extreme Edge
Figura 1: Capas del IoT
En esta arquitectura los dispositivos del IoT conforman el Edge de la red, formando parte de redes inalámbricas descentralizadas. Algunos autores [2] diferencian dentro de esta capa una capa adicional, denominada Extreme Edge, compuesta por pequeños dispositivos que se encargan de realizar las medidas. Normalmente estos dispositivos están compuestos por sensores, microcontroladores de gama baja, un módulo de comunicaciones y una batería o fuente de alimentación. Éstos se comunican entre sí formando redes denominadas Wireless Sensor Networks o redes inalámbricas de sensores. El Edge puede incluir una interface, denominada Gateway, que por un lado permite la conexión entre las redes inalámbricas de bajo consumo de los nodos con otras redes, y por otro facilita el procesamiento local de datos en el propio Edge [4]. En esta capa no es necesaria la comunicación con la nube [11] ya que los datos recogidos por un determinado dispositivo pueden ser procesados y almacenados en el propio equipo. También se pueden procesar en él los datos que le llegan desde la nube.
Aunque hay cierta controversia, muchos autores distinguen una capa intermedia entre el Edge y la nube, denominada Fog. Esta capa combina el almacenamiento y recursos de computación similares a los de la nube, ambos cercanos a la fuente de datos [2]. Según [10] está compuesto por agregaciones de elementos individuales de tamaño reducido formando una red descentralizada, permitiendo una escasa planificación de los recursos, requiriendo una intervención humana mínima, pudiendo apoyar las aplicaciones que requieren latencias por debajo de los 10 milisegundos, proporcionando servicios ininterrumpidos independientemente

Capítulo 2: Estado del arte
ETSII UPM 6
de que exista conexión a internet. Por último, en el Fog las necesidades de ancho de banda a largo plazo están determinadas por la cantidad de datos que necesitan ser enviados a la nube, una vez filtrados por el Fog, en lugar de por la cantidad de datos generados por todos los clientes como ocurre en la nube. Estos autores indican que el Fog puede ayudar solventar muchos de los retos actuales del IoT como las restricciones debidas a la latencia, el ancho de banda, los recursos limitados de los dispositivos del Edge y la seguridad.
La nube es la capa superior que proporciona recursos permanentes y suficientes para procesar las grandes cantidades de datos provenientes de los dispositivos conectados. En general, este modelo funciona bien cuando la energía no es una limitación y cuando no se requiere tomar una decisión rápidamente, a partir de la información recibida [2].
Esta nueva arquitectura del IoT permite el procesado eficaz y eficiente de los datos provenientes de redes de dispositivos muy heterogéneos, aplicando el paradigma denominado Edge Computing. Propone el procesamiento de los datos y los cálculos asociados se realicen lo más cerca posible de la fuente que los produce, no siendo indispensable la conexión con la nube [2]. Ello conlleva importantes cambios respecto a la arquitectura clásica del Cloud Computing, ya que deriva recursos de computación, comunicación, y almacenamiento hacia el Edge [5]. Esta transformación es posible gracias a la evolución de los dispositivos. Han pasado de ser estar basados en microcontroladores de 8-bits, encargados de recoger datos mediante sensores y enviarlos a la nube para ser procesados, a apoyarse en dispositivos con mayor capacidad de procesamiento, a la vez que mantienen un bajo consumo energético. Al acercarse el procesamiento al dispositivo que genera los datos se disminuye la latencia, a la vez que se mejora la fiabilidad y eficiencia de la red a la que están conectados [5].
El Edge Computing tiene múltiples aplicaciones. Por ejemplo, [12] identifican once campos industriales y más de cien casos concretos de uso. Estiman que sólo considerando el hardware asociado, sus aplicaciones industriales pueden conllevar una inversión de al menos 200 billones de dólares entre los años 2020-2025. En este sentido, se debe destacar la aplicación del Edge Computing a la problemática relacionada con la casa, el transporte o la ciudad inteligentes. En efecto, las casas inteligentes cuentan cada vez más con dispositivos conectados que recopilan información. Si todos estos datos se enviaran a la nube para su procesamiento, se pondría en riesgo la privacidad de la vivienda. Del mismo modo, el transporte inteligente supone la conexión de los sensores de tráfico con las cámaras y vehículos; al igual que en el caso anterior, el procesamiento de datos en la nube sería inviable debido a la latencia. Finalmente, la información generada en las ciudades inteligentes, al ser el resultado de la conexión de ciudadanos y casas, infraestructuras, transporte y logística inteligentes requiere el procesamiento en tiempo real. Ello impide la utilización del procesamiento completo de los datos en la nube, por conllevar un periodo de latencia que mermaría su aplicabilidad [5]. El Edge Computing solventa estas limitaciones del Cloud Computing, y por eso es el modelo más prometedor. De hecho, es altamente probable que su uso aumente con la entrada del 5G [13].
2.1 Gestión de recursos en el Edge: Resource Allocation y Computation Offloading
La arquitectura del IoT basada en Edge Computing presenta algunos problemas. El primero es que debido a su portabilidad o su bajo coste, los dispositivos del Edge tienen una limitada capacidad de procesamiento, computación y comunicación, además de estar alimentados por baterías con una capacidad muy reducida [4, 14]. Por ello, a menudo el procesado de datos se traslada al Gateway, lo que también tiene sus limitaciones, ya que los dispositivos del Edge operan con tecnologías inalámbricas de baja potencia (BLE, ANT, ZigBee, HaLoW, LoRa o SigFox). Ello supone una capacidad muy limitada de envío de datos por unidad de tiempo (<10 a 270

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 7
Kbps), independientemente de que estos sean crudos o procesados [4]. Además, esta conectividad tiene un importante coste energético, ya que la energía necesaria para la comunicación es mayor que la que requiere la computación [14]. Por ello, este tipo de redes debe primar el bajo consumo energético frente a otras métricas de las redes tradicionales, como la latencia o el rendimiento. De hecho, es importante considerar el coste energético de ambos procesos para estimar la duración de la batería que alimenta a estos dispositivos, así como idear estrategias que disminuyan los consumos de energía y alargar la vida de la batería.
Otros autores [4] han señalado la existencia de otros problemas en el Edge, como la distribución del limitado ancho de banda disponible en las redes inalámbricas de dispositivos IoT, asociado a su baja energía.
Finalmente, las redes de dispositivos IoT son muy heterogéneas en términos de configuración de su hardware, software, medios de conexión, y entornos y objetivos de sus aplicaciones. Como consecuencia, el volumen de datos, la velocidad con la que se generan y la calidad del servicio son muy diversos. Esta heterogeneidad supone una dificultad añadida a la gestión de recursos en el Edge, ya que demanda soluciones específicas para cada red.
Para solventar estos problemas, la gestión de los recursos en el Edge contempla dos pilares fundamentales: la distribución de tareas entre los distintos elementos que lo componen (Resource Allocation), y el denominado Computation Offloading [5]. Estos principios han sido validados en redes muy diversas, como las sanitarias [15], comunicaciones en redes WiFi [16] o comunicación en 5G [13].
Como se deduce de la nueva arquitectura del IoT, debe existir una colaboración entre el Edge y la nube. La tecnología de computación en el Edge (Edge Computing) puede explotar las capacidades de computación de sus dispositivos, reduciendo así la demanda computacional en la nube y el ancho de banda necesario para transmitir una inmensa cantidad de datos. Además, puede reducir el periodo de latencia, potenciar la protección de la privacidad y reducir el consumo de energía.
Finalmente, es importante distribuir adecuadamente las tareas que deben realizar cada uno de los componentes de la red. Ello supone la descomposición de las tareas en varias subtareas que puedan ser realizadas de forma independiente, basándose en los distintos elementos que componen la red, para conseguir un resultado final óptimo en términos de eficacia y eficiencia de la red. Esta distribución es posible a partir de la información puntual de variables tales como los recursos, la batería y el tiempo de respuesta del nodo, manteniendo la semántica de la tarea completa.
2.1.1 Computation Offloading
La gestión de recursos en el Edge mediante Computation Offloading permite garantizar la calidad del servicio, derivando las tareas que requieran una mayor demanda de computación o una menor latencia a los dispositivos con mayores recursos. Por otro lado, cuando los nodos del Edge no tienen suficiente capacidad de procesamiento, la computación global o una parte de ella pueden ser migradas a una capa superior.
No obstante, se prefiere que el Edge realice la mayor parte posible de la computación dentro de sus limitadas capacidades, para evitar la saturación de las capas jerárquicamente superiores de la red, ya que de otra forma tendrían que procesar los datos procedentes de una infinidad de dispositivos [4].
2.1.2 Resource Allocation
La distribución de las tareas en el Edge debe tener en cuenta los limitados recursos de computación, almacenamiento, y conectividad I/O de sus dispositivos. Además, se deben tener

Capítulo 2: Estado del arte
ETSII UPM 8
en cuenta otras restricciones, como la cuota de uso, el consumo energético, la duración de la batería, la latencia, y la gestión del ancho de banda de la red.
Es imposible establecer un proceso general de gestión de recursos en el Edge debido a la casuística tan variada asociada al IoT. En general, se considera que la planificación de recursos es óptima cuando se contemplan conjuntamente todas las restricciones indicadas anteriormente.
El eje fundamental para la asignación adecuada de los recursos es decidir qué operaciones de computación deben ser realizadas en los dispositivos y cuáles deben ser realizadas en las capas jerárquicamente superiores, como los cloud data centers. Ello depende de la capacidad de computación de los dispositivos.
Se suelen establecer distintos niveles de Offloading de tareas, que implican distinto procesamiento de los datos, así como la transmisión de datos crudos o parcialmente procesados a través de las distintas capas de IoT (dispositivos, Gateway, etc.). Ello se realiza para optimizar la eficiencia de la red, reducir los consumos energéticos, maximizar la calidad del servicio de la red o la vida de la batería de los nodos, al tiempo que se tienen en cuenta las propias limitaciones de la red, tales como su ancho de banda, capacidad de almacenamiento o la capacidad de procesamiento [4]. En función de la dinámica de los parámetros limitantes, se puede cambiar entre distintos niveles de Offloading, optimizando así el funcionamiento global de la red.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 9
3 Metodología 3.1 Sistema operativo Contiki-NG
Los dispositivos de la parte inferior del Edge cuentan con las limitaciones en recursos propios de los sistemas embebidos, además de requerir consumos energéticos muy reducidos. También deben contar con una adecuada conectividad e interoperabilidad, apoyándose en diversos protocolos de comunicación, y ser capaces de procesar datos en tiempo real y mantener la seguridad y privacidad de los datos recogidos [8] .
Debido a la heterogeneidad de los dispositivos embebidos actuales, se han desarrollado múltiples sistemas operativos en los que cada uno tiende a especializarse en un área de aplicación específica, con intereses concretos (computación en tiempo real, bajo consumo o un equilibrio entre ambos). Según [8], los tres más empleados en la capa inferior del IoT son Contiki, RIOT y Zephyr.
Para el desarrollo de este TFG se ha elegido el sistema operativo Contiki-NG, concebido para redes inalámbricas de sensores formadas por nodos sensores muy limitados en recursos. Contiki-NG ha ido evolucionando para dar soporte a nodos de mayor potencia de procesamiento como los actuales [9]. Además, este sistema operativo cuenta con un simulador denominado Cooja que será la principal herramienta empleada en este proyecto.
Contiki-NG se distribuye como una imagen Docker que se ejecuta desde un contenedor Docker. Ello supone grandes ventajas frente al empleo de una máquina virtual [17]:
• Un contenedor Docker únicamente contiene aquellas partes del sistema operativo que difieren del sistema operativo anfitrión, mientras que una máquina virtual recoge el otro sistema operativo completo, con la sobrecarga que ello conlleva.
• Los contenedores Docker hacen un uso más eficiente del sistema anfitrión en cuanto a procesamiento y memoria RAM, al compartir el núcleo del sistema operativo y bibliotecas.
• Los contenedores Docker tienen la ventaja de ser totalmente portables, pueden ejecutarse desde cualquier ordenador, independientemente de su sistema operativo.
• Son seguros, ya que restringen y aíslan los procesos sin tener que tomar precauciones. Cada contenedor únicamente interactúa con una imagen Docker que contiene todo lo necesario para su funcionamiento.
Una vez instalado y ejecutado Contiki-NG en el contenedor Docker, se puede emplear la herramienta Cooja para simular redes inalámbricas de sensores formadas por nodos sensor que ejecutan el sistema operativo Contiki-NG. Cooja permite la simulación del funcionamiento de cada uno de los nodos, incluyendo el enrutamiento y las comunicaciones con los restantes nodos de la red. En Cooja vienen implementados de serie algunos nodos como el Sky mote, el MicaZ mote o el Cooja mote. Además, también permite importar nodos implementados en Java.
El nodo escogido en este trabajo es el “Sky mote” [18]. Se trata de un nodo de muy bajo consumo, que cuenta con un microprocesador MSP430, y el transceptor de radio CC2420 compatible con el estándar IEEE 802.15.4 por el que se rige Zigbee. Además, el nodo incorpora sensores de humedad, de temperatura y de luz. También tiene 16 pines de expansión para poder añadir sensores como los de contaminación atmosférica en el caso se este proyecto.
Este nodo tiene la ventaja de que ya se encuentra implementado en Cooja, por lo que para ejecutar las simulaciones únicamente hay que introducir el código en C que determina el comportamiento del nodo. Además, se trata de un nodo ampliamente utilizado en redes inalámbricas de sensores, por lo que hay mucha literatura disponible acerca de él. Esto es

Capítulo 3: Metodología
ETSII UPM 10
importante, ya que los consumos reales del nodo serán estimados a partir de la bibliografía (véase sección 3.5.1).
3.1.1 Instalación de Contiki-NG
La instalación de Contiki-NG se ha realizado siguiendo los pasos expuestos en [19] para el sistema operativo Windows.
El primer paso es instalar Docker. En su página web se encuentra disponible el instalador para Windows, Mac, Linux y centros de datos (AWS y Azure). Se descarga e instala la versión para Windows 10.
El segundo paso consiste en instalar el programa VcXsrv (XLaunch). Es el programa encargado de ejecutar la parte gráfica del contenedor Docker. En el caso de este TFG será el que ejecute la parte gráfica del simulador Cooja.
El tercer paso es descargar la imagen de Contiki-NG que se encuentra en el repositorio de Docker Hub. Para ello, se necesita obtener del repositorio de Docker Hub el “Docker Pull Command” y posteriormente introducirlo “Windows Power Shell” para que comience la descarga. El comando es: docker pull contiker/contiki-ng.
Por último, se debe clonar el repositorio de Contiki-NG que se encuentra en GitHub [20]. Con ello, la instalación quedaría completa.
Antes de ejecutar Contiki-NG se deben abrir los programas Docker y VcXsrv (XLaunch). Una vez abiertos, ya se puede iniciar Contiki introduciendo en el “Windows Power Shell” el siguiente comando:
docker run --privileged --sysctl net.ipv6.conf.all.disable_ipv6=0 --mount type=bind,source=/c/Users/benja/Documents/GitHub/contiki-ng,destination=/home/user/contiki-ng -e DISPLAY="host.docker.internal:0.0" -ti contiker/contiki-ng
En dicho comando se debe especificar como fuente (source=….) la ubicación en memoria donde se encuentra almacenado el repositorio de GitHub que ha sido clonado.
Si tanto la instalación, como la inicialización de Contiki-NG se han producido correctamente, la ruta raíz del “Windows Power Shell” debe cambiar, tal y como se observa en la Figura 2.
Figura 2: Inicialización de Contiki-NG desde el "Windows Power Shell"
También se puede realizar una prueba sencilla con el ejemplo “hello world” incluido en la carpeta “examples” del repositorio clonado de GitHub. Este ejemplo se ejecuta introduciendo los siguientes comandos en el “Windows Power Shell”:
>> cd examples/hello-world >> make TARGET=native >> ./hello-world.native
En la captura de pantalla de la Figura 3 se observa como cada cierto tiempo imprime en el terminal “Hello, world”. Por tanto, funciona correctamente.
Figura 3: "Windows Power Shell" mostrando el funcionamiento correcto del ejemplo "Hello world"
Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 11
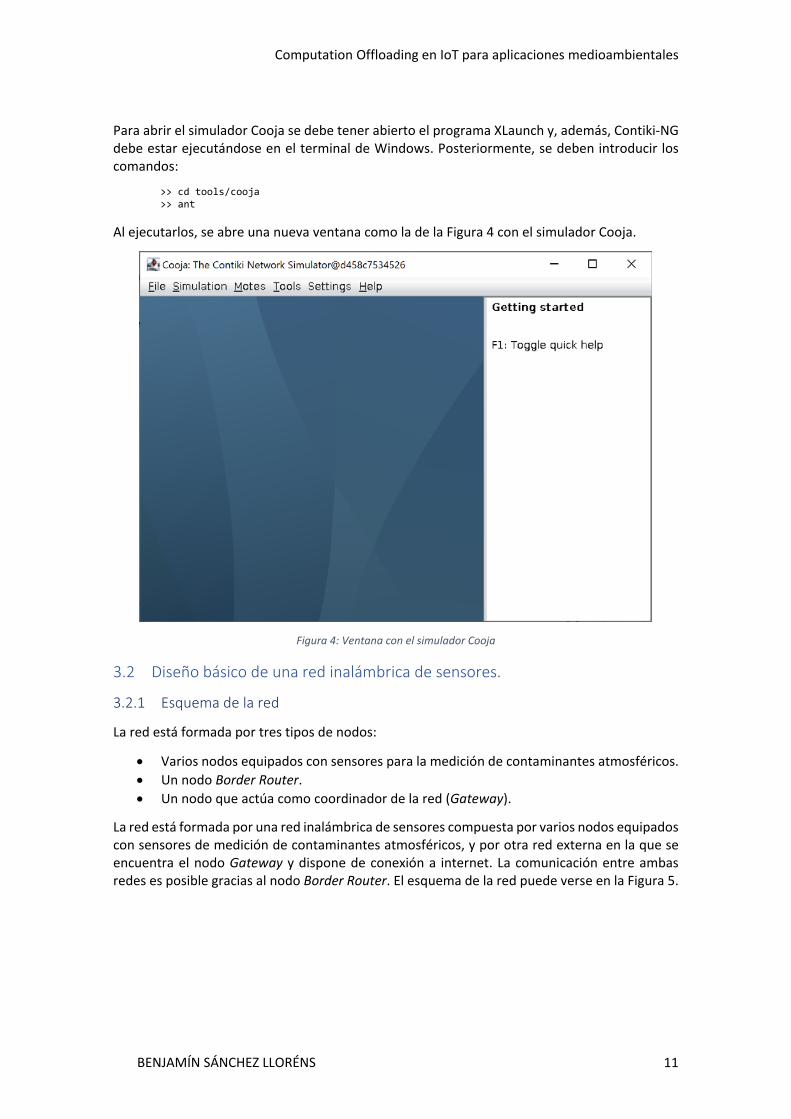
Para abrir el simulador Cooja se debe tener abierto el programa XLaunch y, además, Contiki-NG debe estar ejecutándose en el terminal de Windows. Posteriormente, se deben introducir los comandos:
>> cd tools/cooja >> ant Al ejecutarlos, se abre una nueva ventana como la de la Figura 4 con el simulador Cooja.
Figura 4: Ventana con el simulador Cooja
3.2 Diseño básico de una red inalámbrica de sensores.
3.2.1 Esquema de la red
La red está formada por tres tipos de nodos:
• Varios nodos equipados con sensores para la medición de contaminantes atmosféricos. • Un nodo Border Router. • Un nodo que actúa como coordinador de la red (Gateway).
La red está formada por una red inalámbrica de sensores compuesta por varios nodos equipados con sensores de medición de contaminantes atmosféricos, y por otra red externa en la que se encuentra el nodo Gateway y dispone de conexión a internet. La comunicación entre ambas redes es posible gracias al nodo Border Router. El esquema de la red puede verse en la Figura 5.

Capítulo 3: Metodología
ETSII UPM 12
COORDINADORDE LA RED
NODO 5
NODO 4
NODO 3
NODO 2
NODO 1
BORDERROUTER
RED INALÁMBRICADE SENSORES RED EXTERNA
Figura 5: Esquema de la red
Los nodos equipados con sensores para la medición de contaminantes atmosféricos se encargan de tomar mediciones periódicamente y enviar los datos recogidos al coordinador de la red. Si fuese necesario, antes de enviar los datos al coordinador de la red, el nodo puede procesar total o parcialmente los datos, reduciendo así el tiempo de envío y consiguiendo un menor gasto energético. Estos nodos cuentan con el sistema operativo Contiki-NG y son programados en C.
El Border Router es un dispositivo encargado de establecer comunicación entre la red inalámbrica de sensores, formada por los nodos que portan sensores de contaminación atmosférica, y el mundo exterior en el que se encuentra el coordinador de la red conectado a internet. También cuenta con el sistema operativo Contiki-NG y se programa en C.
La misión del nodo coordinador de la red o Gateway es recopilar los datos de contaminación atmosférica de los distintos nodos, y almacenarlos o enviarlos a la nube. Además, al conocer las mediciones realizadas por todos los nodos, junto con el estado de batería de los distintos nodos, es el encargado de establecer el modo de trabajo en el que debe funcionar cada nodo para así aumentar la vida útil de la red. Estos modos fueron creados previamente por el autor de este trabajo; en función de las condiciones de la red (véase apartado 3.6.2), el algoritmo de Resource allocation y Computation Offloading) determina el nivel en el que debe operar cada nodo.
3.2.2 Protocolos empleados para la comunicación en la red: IPv6, 6LoWPAN, UDP, RPL
En este apartado del TFG se señalan los aspectos fundamentales de los protocolos de comunicación que intervienen en la red simulada.
3.2.2.1 Protocolo IPv6 En la actualidad conviven dos Protocolos de Internet, el IPv4 y el IPv6. Aunque el IPv6 es el protocolo más reciente, aun se sigue utilizando el IPv4 ya que no todos los dispositivos soportan

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 13
el nuevo protocolo. EL IPv4 emplea direcciones de 32 bits, lo que permite crear 4.294.967.296 direcciones distintas. Sin embargo, debido al creciente número de dispositivos conectados, se han agotado las direcciones disponibles de este protocolo. El protocolo IPv6, emplea direcciones de 128 bits, lo que permite poder generar 340 sextillones de direcciones.
El IPv6 ofrece más ventajas que su potencial de generar muchas más direcciones que el IPv4. Permite manejar los paquetes de una manera más eficiente, mejorar el rendimiento y aumentar la seguridad. Además, presenta tablas de enrutamiento más pequeñas que las empleadas con el protocolo IPv4.
3.2.2.2 Protocolo 6LoWPAN El protocolo 6LoWPAN (IPv6 Low-power Wireless Personal Area Network) es una adaptación del protocolo IPv6 para las redes de bajo consumo, y diseñada para el envío de paquetes IPv6 sobre redes IEEE 802.15.4.
En este trabajo se emplea el protocolo 6LoWPAN en la red inalámbrica de sensores simulada en Cooja y la red externa emplea el protocolo IPv6. El border router será el encargado de realizar las conversiones entre ambos protocolos cuando se tenga que intercambiar mensajes entre la red inalámbrica de sensores y el mundo exterior.
3.2.2.3 Protocolo RPL El protocolo de comunicación RPL (Routing protocol for lossy and low-power networks) es un protocolo IPv6 diseñado para redes con pérdidas y de muy bajo consumo.
Este protocolo es el que emplea Contiki-NG [21]. Un nodo router RPL se encarga de realizar el enrutamiento de los paquetes de comunicación en sentido ascendente, descendente o entre nodos.
En este proyecto se ha empleado el enrutamiento RPL Lite que es el que utiliza Contiki-NG por defecto. No permite que los nodos almacenen rutas preferentes para el envió de sus mensajes.
3.2.3 Conexión entre la red inalámbrica de sensores simulada en Cooja y una red externa
El esquema para realizar una primera conexión entre una red inalámbrica de sensores simulada en Cooja y otra exterior con acceso a internet (en este caso, el ordenador), es el de la Figura 6.
RED INALÁMBRICA DE SENSORES(COOJA) RED EXTERNA
ORDENADORNODOUDP-Client
BORDERROUTER
Serial Socket Server Tunslip 6
Figura 6: Esquema de conexión entre la red inalámbrica de sensores y otra red externa
La red empleada para el establecimiento de la conexión entre ambas redes está compuesta por un nodo con el código del ejemplo “udp-client.c”, incluido en el repositorio de Contiki-NG [20] y otro con el código “udp-rpl-border-router.c”, incluido también en dicho repositorio. Ambos

Capítulo 3: Metodología
ETSII UPM 14
nodos se simulan desde Cooja. El ordenador, externo a la red inalámbrica de sensores, se comunica con dicha red a través del Border Router que actúa como router 6LoWPAN.
El Border Router puede ser un ordenador, una Raspberry Pi, o cualquier dispositivo de red. Este nodo hace de puente para atender todas las peticiones realizadas por los nodos de la red inalámbrica de sensores y/o de los dispositivos de red que forman la red exterior.
Los pasos que se deben seguir para comenzar la simulación de esta red vienen expuestos en [22] y son los siguientes:
1. Añadir un nodo del tipo Sky Mote con el código border-router.c que se encuentra en el directorio examples/rpl-border-router de Contiki-NG. Este será el nodo 1.
2. Añadir un nodo del tipo Sky Mote con el código udp-client.c que se encuentra en el directorio contiki-ng/examples/rpl-udp de Contiki-NG. Este será el nodo 2.
3. Colocar la herramienta Serial Socket (SERVER) sobre el nodo 1. Se deja el puerto de escucha (listen port) que viene por defecto y se pulsa el botón “start” para que el socket quede a la escucha. Esta herramienta se encuentra en la pestaña tools de Cooja. En la Figura 7 se observa la ventana del Serial Socket (SERVER).
Figura 7: Captura de pantalla del Serial Socket (SERVER) de Cooja
4. Una vez el socket se encuentra a la espera de que se le conecte un cliente, es el momento de lanzar la herramienta tunslip6 de Contiki-NG. Esta herramienta se encarga de crear una nueva interfaz de red “tun0”, mediante la cual se produce la comunicación entre ambas redes. Para lanzar tunslip6 se debe abrir un nuevo terminal en Docker, cambiar el directorio de trabajo al que contiene el código de ejemplo del Border Router (contiki-ng/examples/rpl-border-router) e introducir el comando: “make TARGET=sky connect-router-cooja”. En la captura de pantalla de la Figura 8 se observa un terminal en el que se ha lanzado tunslip6 y comenzado la simulación de Cooja.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 15
Figura 8: Terminal de Docker ejecutando tunslip
En la ventana del Serial Socket (SERVER) de Cooja se puede observar cómo hay un cliente conectado con dirección “127.0.0.1” y puerto 45558. Ver Figura 9.
Figura 9: Serial Socket (SERVER) de Cooja con un cliente conectado
Con ello, queda establecida la conexión entre la red interna de Cooja (red inalámbrica de sensores) y la externa (ordenador).
Las direcciones internas de los nodos de la red de Cooja se pueden observar desde la ventana “Network” de Cooja, tal y como aparece en la Figura 10. Estas direcciones cambian si se quiere establece comunicación con la red de Cooja desde la red externa. Esto se debe a que el Border Router hace corresponder cada dirección de la red inalámbrica de sensores a otra de la red externa. Las direcciones de la red interna tienen la forma “fe80::xxx:xxxx:x:xxx” mientras que las de la externa tienen la forma “fd00::xxx:xxxx:x:xxx”. Es decir, lo que cambia es el prefijo, pero el resto de la dirección permanece igual. En la Tabla 1 se observa la dirección interna y externa para el nodo 1 y para el nodo 2.

Capítulo 3: Metodología
ETSII UPM 16
Figura 10: Dirección de red de cada nodo en la ventana network de Cooja
Tabla 1: Dirección de memoria de cada nodo para red interna de Cooja y para la red externa a Cooja
Nodo 1 Nodo 2
Direcciones de los nodos internas a Cooja fe80::212:7401:1:101 fe80::212:7402:2:202
Direcciones de los nodos desde la red externa a Cooja fd00::212:7401:1:101 fd00::212:7402:2:202
Para comprobar el correcto funcionamiento de la comunicación desde el exterior con cada uno de los nodos de la red inalámbrica de sensores se realiza un ping a la dirección de cada nodo. Al estar contactando con la red de Cooja desde la red externa, se deben usar las direcciones en formato “fd00::xxx:xxxx:x:xxx”. Para realizar los pings a los nodos uno y dos se deben introducir sendos comandos desde un terminal Docker:
>>ping6 fd00::212:7401:1:101 para comprobar la conexión con el nodo 1.
>>ping6 fd00::212:7402:2:202 para comprobar la conexión con el nodo 2.
En las Figuras 11 y 12 se puede observar la respuesta al realizar individualmente un ping a los nodos 1 y 2, respectivamente. Se aprecia que ambos nodos contestan al ping que reciben. Ello confirma el correcto funcionamiento de la comunicación entre ambas redes.
Figura 11: Respuesta ante un ping al nodo 1 Figura 12: Respuesta ante un ping al nodo 2
Una vez establecida la conexión de la red inalámbrica de sensores simulada en Cooja con la red externa, el siguiente paso es establecer comunicación bidireccional entre un nodo de la red de Cooja y otro de la red externa.
Se denomina nodo 2 al nodo simulado en Cooja que se comunicará con el nodo de la red externa. El nodo 2 estará programado con el código del Anexo 1.1. El Border Router, será el nodo 1 y estará programado con el código del Anexo 1.2. Por último, el nodo de la red externa será el Gateway, que opera según el código escrito en Python de la Figura 14, ejecutado desde el propio

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 17
ordenador. En la Figura 13 puede verse el esquema de las redes y la sucesión de las comunicaciones que se deben producir.
RED INALÁMBRICA DE SENSORES(COOJA) RED EXTERNA
NODOCOORDINADOR
DE LA RED(Python)
NODO2
BORDERROUTER
Serial Socket Server Tunslip 6
1) Mensaje desde el nodo 2 al nodo de la red externa
2) Mensaje de respuesta desde el nodo de la red externa al nodo 2
Figura 13: Comunicación bidireccional entre el nodo Cooja y el nodo Python
Para el establecimiento de la comunicación bidireccional expuesta en la Figura 13, se siguen los pasos enumerados a continuación:
1. Se disponen los nodos en Cooja con el programa en C que les corresponde. 2. Se coloca el “Serial Socket (SERVER)” sobre el Border Router y se inicia el socket 3. Se lanza tunslip6 desde un terminal Docker. 4. Se ejecuta el código Python del Gateway de la red desde otro terminal Docker. 5. Se pulsa en el botón que comienza la simulación de Cooja.
Una vez arrancada la simulación, se produce la siguiente secuencia:
1. El código Python crea un socket de tipo UDP, con el que establece conexión con la red inalámbrica de sensores a través del Border Router.
2. El nodo 2 envía un mensaje al nodo de la red externa a través del Border Router. 3. El nodo Python recibe el mensaje y lo envía de vuelta como eco a la dirección que se lo
ha enviado.
Figura 14: Código del nodo Python. Hace eco de los mensajes que recibe

Capítulo 3: Metodología
ETSII UPM 18
La Figura 15 corresponde a el terminal de Cooja en el que está corriendo el código escrito en Python del Gateway de la red. Se observa como al recibir el mensaje “hello 1” de la dirección “fd00::212:7402:2:202”, contesta enviando el mensaje recibido “hello 1”. Además, se observa que cuando el mensaje recibido pasa a ser “hello 2”, contesta con un “hello 2”, por lo que funciona a la perfección.
La Figura 16 contiene una captura de pantalla de la ventana “Mote output” de Cooja en la que el nodo 2 imprime los mensajes recibidos y enviados. Se observa que el funcionamiento también es correcto.
Figura 15: terminal del nodo Python
Figura 16: Mote Output de Cooja
Por último, la Figura 17 contiene una captura de pantalla del programa Wireshark. Este programa es útil para ver si existen errores, ya que permite analizar todas las comunicaciones que tienen lugar en la red inalámbrica de sensores. Para estudiarlas, es necesario abrir la ventana “Radio Messages” del menú “tools” de Cooja, y en dicha ventana seleccionar la opción de “6LoWPAN Analyzer with PCAP” del menú “Analyzer”. Esto hace que se genere un fichero, dentro del directorio en el que se encuentre el repositorio de Contiki-NG, que puede ser abierto con el programa Wireshark.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 19
En la Figura 17 se aprecia la comunicación correcta entre ambas redes realizadas mediante el socket UDP (véase los recuadros en rojo).
Figura 17: Wireshark
3.3 Validación del entorno de simulación mediante la utilización de datos reales de contaminación atmosférica registrados en la ciudad de Madrid
3.3.1 Contaminación atmosférica en la ciudad de Madrid
La calidad del aire es una de las principales preocupaciones de las urbes del mundo [23] y de Europa [24]. La ciudad de Madrid no es ajena a esta inquietud, ya que en ella se exceden los límites legales de diversos contaminantes establecidos en la Directiva 2008/50/EC [25]. Existen numerosos estudios que relacionan la contaminación atmosférica con problemas respiratorios, enfermedades cardiovasculares y distintos tipos de cáncer [26] y [27].
La calidad del aire de Madrid se ve afectada por su carácter de gran urbe (la cuarta en tamaño de Europa por población), por estar inmersa en una provincia en la que habitan cerca de 6,5 millones de habitantes (85% en la ciudad de Madrid) y diversos polígonos industriales, y en la que además existe un notable transporte de personas y mercancías tanto en la provincia como en el interior de la ciudad [28].
A pesar de que la calidad del aire de Madrid ha mejorado en las últimas décadas debido a diversas causas [29], aun se siguen superando los niveles de contaminación establecidos en la legislación. Así, en 2015, se superó este último límite 95 veces en el barrio de El Pilar [26]. El tráfico rodado en la ciudad de Madrid explica el 80% de las emisiones de NOx y CO, el 48% de las partículas PM10 y el 65% de la formación de O3 troposférico [26]. En 2016, se excedió el límite anual de 40 µg.m-3 de NO2 en 9 de las 24 estaciones de medida de la contaminación atmosférica de Madrid y en 4 estaciones se superó el límite horario anual de 200 µg.m-3 de dicho contaminante [30]. Estos autores indicaron la presencia de ciclos diarios en las concentraciones de los distintos contaminantes motivados fundamentalmente por los desplazamientos con vehículo dentro de la ciudad y sus accesos, y por las reacciones entre contaminantes y las variaciones diarias y estacionales de la radiación solar y la temperatura del aire, que favorecen

Capítulo 3: Metodología
ETSII UPM 20
la formación de contaminantes secundarios como el O3. También señalaron la existencia de ciclos semanales, relacionados con la actividad laboral, así como ciclos estacionales relacionados también con la actividad laboral, las variaciones de las condiciones meteorológicas y el uso de calefacciones. Cuando se ponen en funcionamiento las calefacciones se registran las concentraciones máximas de CO y de NO, coincidiendo también con los niveles mínimos de O3. Según [26], una vez que aumenta la contaminación atmosférica en Madrid como consecuencia del tráfico en la ciudad, las industrias cercanas, las calefacciones y otras fuentes, disminuye la importancia de las emisiones locales de cada distrito respecto de este fondo acumulado, exceptuando en las zonas con mayor tráfico. Los episodios de contaminación de NO2 y de otros contaminantes se suelen producir en otoño e invierno, cuando los sistemas de altas presiones favorecen el estancamiento de las masas de aire y los contaminantes se acumulan en la atmósfera. Esta situación puede persistir durante una o dos semanas. De hecho, la contaminación atmosférica en la ciudad es altamente dependiente de las condiciones meteorológicas que facilitan su dispersión o lavado por precipitación. La dispersión de los contaminantes se ve dificultada en algunas zonas de la ciudad por el efecto cañón que se produce en las calles estrechas (street canyons) que provoca efectos locales, como vórtices de contaminación cuando el viento es perpendicular a la calle o flujos canalizados cuando es paralelo a la calle [26].
Debido a los ciclos diarios, semanales y estacionales indicados, además de las reacciones que se producen entre contaminantes, existen relaciones significativas entre ellos. Así, [28], al analizar las concentraciones de contaminantes registradas entre 2010 y 2017 en 20 estaciones de medida localizadas en la ciudad de Madrid y en otras áreas urbanas y rurales de la Comunidad de Madrid, encontraron correlaciones positivas entre NO y NO2 (r = 0.99), PM10 (r = 0.63) y negativas con O3 (r = -0.81). Igualmente, las concentraciones de NO2 se correlacionaron positivamente con las de PM10 (r = 0.54) y negativamente con las de O3 (r = -0.89). Finalmente, las concentraciones de O3 se correlacionaron negativamente con las de PM10 (r = -0.81).
3.3.2 Sistema de Vigilancia de la Calidad del Aire del Ayuntamiento de Madrid.
El sistema de vigilancia de la calidad del aire del Ayuntamiento de Madrid [31] está formado por 24 estaciones automatizadas, dos puntos adicionales para partículas en suspensión PM2,5, dos puntos de muestreo para metales pesados y uno para benzo(a)pireno, todos ellos encuadrados en el Sistema Integral de Vigilancia, Predicción e Información [32]. Estas recogen información de los niveles de diferentes gases y partículas para evaluar la calidad del aire y activar protocolos para la reducción de la contaminación en las situaciones que lo requieran.
Las estaciones realizan mediciones de contaminantes atmosféricos en continuo, mediante equipos de alta precisión que cumplen con la Directiva 2008/50/EC y el Real Decreto 102/2011. Los métodos de referencia para la medición en continuo de SO2 (UNE-EN 14212:2013), NOx (UNE-EN 14211:2013), CO (UNE-EN 14626:2013) y O3 (UNE-EN 14625:2013) son, respectivamente, la fluorescencia ultravioleta, quimioluminiscencia, espectroscopía de infrarrojos no dispersivos y fotometría ultravioleta. La Directiva y el Real decreto mencionados indican que la gravimetría es el método de referencia para la determinación de PM10 (UNE-EN 12341:2015) y PM2,5 (UNE-EN 12341:2015), si bien permite la utilización de analizadores en continuo, como por ejemplo los basados en la atenuación de la radiación β, una vez que sus medidas son calibradas frente al método gravimétrico.
Estos analizadores automáticos registran un valor medio cada cinco segundos. Estos datos son procesados e integrados en el Centro de Control del Servicio de Calidad del Aire. En este centro se generan posteriormente diferentes promedios, necesarios para validar la calidad de los datos obtenidos y para ajustar la presentación de los datos a la forma en que la normativa establece los valores límite. Así se calculan datos diezminutales a partir de los 120 datos registrados cada 10 minutos. En cada hora se registran por lo tanto 6 datos diezminutales. A partir de estos

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 21
registros se calculan los promedios horarios; se consideran válidos si se basan en al menos cuatro datos diezminutales válidos. Del mismo modo, se calculan datos octohorarios (son válidos si se basan en al menos 6 datos horarios válidos), diarios (son válidos si al menos tres cuartas partes de los datos horarios en los que se basan también lo son), y anuales (son válidos cuando los son las tres cuartas partes de los datos horarios en los que se basan).
Existen distintos tipos de estaciones, cada uno pretende caracterizar diferentes tipos de exposición a la contaminación atmosférica.
Las estaciones urbanas de fondo son representativas de la exposición de contaminantes a los que está expuesto la población urbana en general. En azul en la Figura 18.
Las estaciones urbanas de tráfico se encuentran en lugares de la ciudad en los que su nivel de contaminación esté principalmente determinado por las emisiones procedentes de una calle o carretera próxima. En rojo en la Figura 18.
Las estaciones suburbanas se encuentran a las afueras de la ciudad, lugares en los que los niveles de ozono son máximos. En verde en la Figura 18.
Figura 18: Plano con las estaciones de calidad aire del Ayuntamiento de Madrid. Fuente [33]
En la Tabla 2 se clasifican las distintas estaciones según sus características [31]. Los números entre paréntesis hacen referencia al número de Estación asignado por el Ayuntamiento.

Capítulo 3: Metodología
ETSII UPM 22
Tabla 2: Clasificación de las estaciones según su fin.
Urbanas de fondo Urbanas de tráfico Suburbanas Arturo Soria (16) Plaza de España (4) Casa de Campo (24) Villaverde (17) Escuelas Aguirre (8) El pardo (58) Farolillo (18) Avda. Ramón y Cajal (11) Juan Carlos I (59)
Barajas Pueblo (27) Moratalaz (36)
Pza. del Carmen (35) Cuatro Caminos (38) Vallecas (40) Barrio del Pilar (39)
Méndez Álvaro (47) Castellana (48) Parque del Retiro (49) Plaza de Castilla (50)
Ensanche de Vallecas (54) Plaza Elíptica (56) Urb. Embajada (55)
Sanchinarro (57) Tres olivos (60)
El Ayuntamiento de Madrid proporciona en su web [34] las mediciones horarias y diarias de las distintas estaciones entre los años 2001 y 2020.
3.3.3 Índice Nacional de Calidad del Aire.
El Índice Nacional de Calidad del Aire (IC) está legislado en la Orden TEC/351/2019, de 18 de marzo y clasifica la calidad del aire entre muy bueno, bueno, regular, malo, y muy malo. Este índice se establece en función de cinco contaminantes:
• Partículas en suspensión PM10 • Partículas en suspensión PM2,5 • Ozono troposférico (O3) • Dióxido de nitrógeno (NO2) • Dióxido de azufre (SO2)
El cálculo del IC varía según el contaminante del que se trata: • Para el ozono troposférico, el dióxido de nitrógeno y el dióxido de azufre se emplean los
valores de las concentraciones horarias. • Para las partículas en suspensión PM2,5 y PM10 se emplea la media móvil de las 24
horas anteriores.
Una vez obtenidos los IC de cada uno de los contaminantes que componen el Índice Nacional de Calidad del Aire, se establece que el IC para esa fecha y hora se corresponde con el peor de los cinco índices de calidad previamente calculados.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 23
En la Tabla 3 se muestran los rangos que componen cada nivel del IC según el contaminante del que se trata.
Tabla 3: Índice Nacional de Calidad del Aire según cada contaminante. Orden TEC/351/2019, de 18 de marzo.
Contaminantes Muy bueno Bueno Regular Malo Muy malo
Partículas PM2,5 0-10 11-20 21-25 26-50 51-800 Partículas PM10 0-20 21-35 36-50 51-100 101-1200 Dióxido de Nitrógeno (NO2) 0-40 41-100 101-200 201-400 401-1000 Ozono (O3) 0-80 81-120 121-180 181-240 241-600 Dióxido de azufre (SO2) 0-100 101-200 201-350 351-500 501-1250
3.3.3.1 Umbrales para la activación de protocolos de actuación del Ayuntamiento de Madrid ante episodios de contaminación
Los contaminantes que más preocupan a las autoridades de Madrid porque exceden con frecuencia los niveles de riesgo para la salud humana son el NO2 y las partículas (PM10 y PM2,5). Por ello, el Ayuntamiento de Madrid, en cumplimiento de la Directiva 2008/50/EC, ha realizado un protocolo de actuación a corto plazo para reducir el riesgo de que se excedan los límites legales de las concentraciones de los distintos contaminantes, así como para reducir la duración de los episodios de contaminación. Este plan de actuación se basa en la división de la ciudad en cinco zonas, de acuerdo con la distribución de la población y la red de carreteras de acceso y salida de la ciudad.
En el caso del NO2, el plan contempla cuatro fases. La primera (preaviso) se activa cuando se supera el umbral de 180 µg/m3 durante dos horas consecutivas en dos estaciones de medida de una misma zona. Supone limitar la velocidad a 70 km/h en la M-30 y accesos a la ciudad. La segunda se activa cuando se supera la condición anterior durante dos días consecutivos o cuando se sobrepasa la concentración de aviso (200 µg.m-3) durante un día en dos estaciones de una determinada zona. Obliga a prohibir el aparcamiento desde las 9:00 a las 21:00 dentro del perímetro de la M-30. La tercera fase se activa cuando se supera el nivel de aviso durante dos días consecutivos. Además de las medidas asociadas a las anteriores fases, conlleva la restricción del acceso a la zona 1 (centro de la ciudad) a los vehículos privados (matrículas pares o impares, excepto los de bajas emisiones) desde las 6:30 a las 21:00. La última fase o fase cuatro se produce cuando se supera la concentración de 400 µg/m3 durante tres horas consecutivas. En ella, se extiende la limitación de acceso al anillo interno de la M-30, además de las medidas asociadas a cada una de las fases anteriores. Al tiempo, se restringe la circulación a los taxis sin pasajeros. Las medidas del plan de acción tienen un notable impacto económico, social y político.
El protocolo de actuación ante episodios de contaminación de O3 cuenta con tres niveles de acción distintos. El primer nivel es el de preaviso que se activa, al superar los 160 µg/m3. Se trata de un nivel de carácter interno en el que se realiza un análisis de los datos comprobando su validez y se analiza la tendencia de los valores en las estaciones en los que se registran los valores más elevados. El siguiente nivel es el de información a la población, se activa al superar los 180 µg/m3. Se comunica a las personas, Departamentos y organismos correspondientes para que valoren la situación y, en caso de que se espere que los valores lleguen al nivel de alerta atmosférica, introducir un anuncio en la web del Ayuntamiento de Madrid indicando la alerta y dando recomendaciones a los sectores de la población más vulnerables. Por último, el nivel de

Capítulo 3: Metodología
ETSII UPM 24
alerta atmosférica se activa al superar los 240 µg/m3. Se declara la alerta atmosférica, se convoca a la Comisión de Calidad del Aire y se introduce la alerta en la página web del Ayuntamiento de Madrid junto con recomendaciones a los sectores de la población más vulnerables.
Así mismo, existen unos umbrales establecidos por cada contaminante para asegurar la protección de la salud [35], representados en la Tabla 4.
Tabla 4: Umbrales para cada contaminante que componen el IC para la protección de la salud. Fuente [35].
Compuesto Valor límite / Umbral de Alerta Concentración Nº máximo de
superaciones
PM10 Media anual 40 µg/m3
35 días/año Media diaria 50 µg/m3
PM2,5 Media anual 25 µg/m3
SO2
Media diaria 125 µg/m3
3 días/año 24 días/año
Media horaria 350 µg/m3 Umbral de alerta (3 horas consecutivas en un área representativa de 100 km o
zona de aglomeración entera) 500 µg/m3
NO2
Media anual 40 µg/m3
18 horas/año Media horaria 200 µg/m3
Umbral de alerta (3 horas consecutivas en un área representativa de 100 km o
zona de aglomeración entera) 400 µg/m3
O3
Máxima diaria de las medias móviles octohorarias 120 µg/m3 25 días/año,
Promediados en un período de 3 años
Umbral de información. Media horaria 180 µg/m3
Umbral de alerta. Media horaria 240 µg/m3
3.3.4 Propuesta de mejora de la red de medida de la contaminación atmosférica de la ciudad de Madrid mediante la incorporación de microsensores
Para evitar las situaciones de riesgo derivadas de la contaminación atmosférica y la implementación de las actuaciones de control asociadas, es importante disponer de una red de medida de la calidad del aire que permita comprobar que no se superan los niveles establecidos en la normativa ambiental, ayudar a establecer medidas para la gestión adecuada de la calidad del aire. Además, esta red contribuye a la obtención de series temporales de mediciones de contaminantes que permiten modelizar y predecir los episodios de contaminación y su distribución en la ciudad con antelación. Estas redes se basan en diversas estaciones que contienen instrumentos de medida de contaminantes atmosféricos en continuo, que proporcionan datos de alta calidad, al seguir procedimientos normalizados tanto para las mediciones como para su calibración [36]. Estos instrumentos tienen un coste elevado y requieren un mantenimiento periódico. Por ello, las redes de calidad del aire tienen un número limitado de estaciones. Por ejemplo, la red de calidad del aire que gestiona el Ayuntamiento de Madrid está formada por 24 estaciones de medida.
Este reducido número de estaciones puede no ser suficiente para caracterizar la exposición a la contaminación atmosférica de los viandantes ya que su distribución no contempla la casuística particular de dilución o acumulación de contaminantes en las distintas calles que componen los diferentes barrios [36]. Además, pueden no ser completamente representativas de la contaminación atmosférica que se registra en el propio vecindario en el que están instaladas,

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 25
dado que pueden estar afectadas por condiciones particulares de tráfico (rotondas, semáforos), y por las perturbaciones que ejercen los edificios cercanos o estar ubicadas en áreas con mayor o menor ventilación que las calles inmediatamente adyacentes.
Estas carencias son relevantes porque dificultan el establecimiento de medidas proporcionadas y eficaces de control de la contaminación. Por otro lado, al no existir datos desagregados con una elevada resolución espacial y temporal, no es posible determinar la exposición y el impacto en la salud de los viandantes y habitantes de las diferentes barriadas, ni tampoco esclarecer las condiciones meteorológicas que favorecen los episodios de contaminación en los distintos barrios y las mayores tasas de morbilidad y mortalidad [27].
Una forma de solventar estas carencias es utilizar conjuntamente microsensores portátiles de calidad del aire, que incorporan las últimas tecnologías, con una fiabilidad y precisión aceptables, aunque inferiores a la de los instrumentos de medida de las estaciones de calidad del aire. Su menor coste permite disponer una gran cantidad de ellos en la ciudad, y cartografiar con mayor precisión la distribución de los contaminantes en las urbes [36]. De hecho, la utilización conjunta de las estaciones de medida con microsensores de contaminantes atmosféricos tales como NO, NO2, CO, O3, PM10, y PM2.5, distribuidos con mayor densidad en las calles de la ciudad de los distintos barrios ha mostrado ser útil para evaluar la representatividad de las medidas procedentes de las redes de medición [27], así como para caracterizar la exposición real de los habitantes y usuarios de los distintos barrios a la contaminación atmosférica). Utilizando estas tecnologías estos autores observaron que las concentraciones de NOx en Pamplona (> 200 µg.m-3) no sólo son elevadas en las calles y arterias de la ciudad en las que el tráfico es elevado, sino también en las calles estrechas (street canyons) con menor circulación, pero con ventilación reducida.
Por ello, la incorporación de microsensores de contaminantes atmosféricos de bajo coste a la red de medición de la contaminación atmosférica del Ayuntamiento de Madrid mejoraría sus prestaciones. Entre otros, [37] emplearon satisfactoriamente los sensores de la serie B4 de la empresa Alphasense (Tabla 5), diseñados para ser utilizados en redes inalámbricas situadas al aire libre. El método de medida de los sensores de NO2, SO2 y O3 es de tipo electroquímico y para los de PM10 y PM2,5 es de tipo óptico. [37] indican que los sensores realizan cinco mediciones por segundo, calculando y almacenando la media de estas mediciones cada diez segundos, para posteriormente, a los treinta minutos, enviar los datos almacenados al servidor por GPRS.
Estos microsensores fueron evaluados por [36] e indicaron que existe una aceptable relación entre sus resultados y los correspondientes a los métodos estándar de medida en continuo para O3 (r2 = 0.7), NO2 (r2 = 0.89), NO (r2 = 0.8) y CO (r2 = 0.87). Sin embargo, encontraron una pobre relación con los métodos estándar de medida en continuo para SO2 (r2 = 0.2) o para partículas.
Tabla 5: Microsensores utilizados en la bibliografía para medir los contaminantes atmosféricos más relevantes
NO2 SO2 PM2,5 PM10 O3 NO2-B43F SO2-B4 OPC-R1 OPC-R1 OX-B431

Capítulo 3: Metodología
ETSII UPM 26
La conectividad y procesado de información que permite el IoT en las ciudades aconseja la utilización de microsensores de este tipo, porque la integración de todos los datos de calidad del aire de la red con los datos meteorológicos, de intensidad de tráfico en las distintas vías1, y con los de ingresos hospitalarios, permitiría prever las alertas antes de que se produzcan, establecer medidas más efectivas de control de tráfico por sectores, y también determinar de manera precisa el impacto de la contaminación atmosférica sobre la salud de los habitantes y usuarios de Madrid. Estos microsensores tienen la ventaja adicional de que pueden ser transportados por viandantes, corredores o ciclistas, proporcionando valiosos datos de contaminación atmosférica en tiempo real, que pueden ser cruzados con los datos de esfuerzo físico y de posición, y así calcular con precisión su inhalación de contaminantes.
La utilización de los microsensores para la medición de contaminantes atmosféricos conlleva la superación de ciertas dificultades para garantizar la calidad de la medida [37]. Las concentraciones de los contaminantes que se registran en el aire ambiente de las ciudades se encuentran cerca del extremo inferior de su rango de medida. Ello supone una baja relación entre la señal obtenida y el ruido, así como una gran sensibilidad a las interferencias. Incluso los sensores más fiables del mercado tienen un bajo nivel de reproducibilidad. Sin embargo, es posible mejorar sensiblemente sus resultados analizando a posteriori el gran volumen de datos que generan, mediante la aplicación de filtros basados en la varianza de los datos para eliminar interferencias asociadas a capacitancia, desarrollo de protocolos para obtener parámetros de calibración o para estimar las interferencias entre los gases, o el uso de métodos estadísticos para mejorar sensiblemente los parámetros de calibración proporcionados por los fabricantes. Aplicando estas técnicas, y mejorando los procedimientos analíticos de los microsensores, [37] incrementaron la calidad de la señal y la intercalibración de los microsensores en cerca de un orden de magnitud. [38] mostraron resultados similares aplicando técnicas de inteligencia artificial, pero resaltaron que en realidad estos protocolos suponen una calibración específica para cada lugar de medida, basada en los datos obtenidos previamente.
No obstante, la implantación de estos microsensores supone importantes retos tecnológicos relacionados con la gestión de la información que aportan. Ello se debe, en primer lugar, al volumen de información que proporcionan ya que, típicamente, cada sensor ofrece lecturas cada cinco segundos. En segundo lugar, a la necesidad de procesar la información; los datos generados deben ser agregados en forma de promedios horarios para después analizar si se superan los niveles de información, alerta y alarma establecidos por el protocolo de actuación del Ayuntamiento de Madrid. Ello demanda realizar promedios considerando intervalos de tiempo menores, que permitirán determinar la validez de un dato horario. De forma extrema, este procesado puede realizarse previamente en el nodo al que se asocia cada sensor o por el contrario ejecutarse en cualquiera de las capas jerárquicas superiores del IoT. El tercer reto se relaciona con la gestión de la batería del nodo que alimenta a los sensores, ya que tanto la transmisión como el procesado de los datos consumen energía. Un cuarto y último reto estaría asociado a la gestión eficaz del ancho de banda disponible.
En este trabajo se centra en la gestión eficaz de la batería del nodo asociado a los sensores de los contaminantes atmosféricos, utilizando las metodologías de Resource Allocation y Computation Offloading de las redes inalámbricas de sensores. Como se ha indicado anteriormente, la gestión de la batería del nodo está muy relacionada con la toma de decisiones sobre cuándo se transmiten los datos, su grado de procesamiento y la capa jerárquica en la que se procesan los datos. Estas decisiones se pueden establecer a priori, predeterminando los tiempos de procesado y emisión de datos desde el nodo a la capa inmediatamente superior de la red. Pero también existen otras opciones intermedias, como enviar los datos cuando los
1 La ciudad de Madrid tiene instalados cerca de 3.800 sensores de tráfico que registran el flujo de vehículos, ocupación, tipo de vehículo y velocidad, cada 15 minutos.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 27
niveles de contaminación superan un determinado umbral. Indudablemente, el conocimiento previo de las situaciones en las que existe una mayor probabilidad de que se superen los umbrales de información, alerta y alarma, puede contribuir a que las decisiones sobre emisión y procesado de datos se ajusten más a las necesidades del gestor de la red de contaminación, además de optimizar la energía de la batería del nodo.
El análisis de la opción óptima de la gestión de la batería del nodo asociado a los microsensores de contaminantes atmosféricos requiere la utilización de un entorno de simulación relacionado con la gestión de la información en el Edge. Este trabajo se centra en la construcción de este entorno de simulación, así como en la propuesta del modo óptimo de gestión de la batería del nodo asociado a la medición de contaminantes atmosféricos mediante microsensores. En tal sentido, debido a que tanto los modos de operación de los nodos sensores como a su vez la gestión de comunicaciones inalámbricas y capas de red son las que proporcionan un mayor peso en terminos de consumo de energía, los algoritmos empleados de gestión mediante las técnicas de computation offloading se han centrado en estos aspectos y se ha considerado que la magnitud de consumo de los microsensores es comparativamente reducida.
3.3.5 Descarga y preprocesamiento de los datos de mediciones de contaminación atmosférica aportados por el Ayuntamiento de Madrid.
Mediante el Jupyter Notebook, compuesto por el código en Python del Anexo 2, se han preparado los datos de las mediciones horarias de contaminación atmosférica aportadas por el Ayuntamiento de Madrid para su posterior análisis y utilización en la red inalámbrica de sensores simulada.
Para el análisis de los datos y para la posterior simulación de la red inalámbrica de sensores, se han escogido los registros correspondientes a las mediciones de contaminación atmosférica de los años comprendidos entre 2011 y 2019. Existen datos del presente año 2020, pero se ha optado por no incluirlos al tratarse de un año atípico debido a la COVID-19. La población ha estado sometida a una cuarentena de casi tres meses, y tras la cuarentena los hábitos de los ciudadanos de Madrid, y de España en general, han cambiado. La población evita los potenciales focos de contagio como pueden ser las grandes aglomeraciones de personas, el transporte público o incluso el acudir presencialmente al trabajo, optando por el teletrabajo cuando ello es posible. Los datos de las mediciones de contaminación atmosférica de Madrid se descargan de la web del Ayuntamiento de Madrid [34]. En ella hay disponible un fichero “zip” distinto por cada año, que puede contener hasta tres ficheros distintos por cada mes del año: uno en formato “csv”, otro en formato “txt” y otro en formato “xml”. Además, el Ayuntamiento también cuenta con la opción de acceder a los datos de contaminación atmosférica mediante una API.
En la web de Ayuntamiento de Madrid también se encuentra disponible un documento [39] que explica cómo interpretar los ficheros con las mediciones horarias de contaminación atmosférica. En la Tabla 6 se observa que los datos descargados presentan una gran heterogeneidad, ya que los distintos ficheros presentan diversos formatos. Esta diversidad es aún mayor porque incluso en los ficheros que comparten la misma extensión, las columnas correspondientes a las distintas emplean distintos separadores. Por ejemplo, los ficheros “txt” de los años 2019, 2018 y parte del 2017 tienen como separador de columnas una coma, pero el resto de los años seleccionados no incluyen un separador de columnas, sino que estas vienen determinadas por un número fijo de caracteres.

Capítulo 3: Metodología
ETSII UPM 28
Tabla 6: Formato de los ficheros con los datos de contaminación atmosférica del Ayuntamiento de Madrid
.csv .txt Encabezado Sí No
Separación entre columnas “;” “,” o número caracteres fijo Separación entre filas Salto de línea Salto de línea
Para los años seleccionados en este proyecto se han de tener en cuenta 108 ficheros de datos, equivalentes a los nueve años de mediciones con sus respectivos doce ficheros por año. Esto supone la importación de las mediciones realizadas durante 3.285 días, lo que implica obtener aproximadamente 78.840 mediciones horarias por cada contaminante y estación, siendo un total de 10.326.432 mediciones. Es fundamental realizar una importación correcta de los datos de las mediciones desde Python, que permita se homogeneicen los datos para su posterior análisis y uso en las simulaciones de la red inalámbrica de sensores.
Los datos de las mediciones de contaminación atmosférica se importan en Python y se cargan en dataframes de la librería Pandas. Esto permite una gestión altamente eficiente y sencilla de este gran volumen de datos, a la vez que facilita realizar operaciones con ellos o aplicar filtros.
Los datos de las mediciones correspondientes al año 2019 se han importado desde los ficheros de extensión “csv” para facilitar la importación de la cabecera de las columnas. Al tener ya importada la cabecera de las columnas en el dataframe, se ha decidido importar el resto de los ficheros en formato “txt”, al ser el formato que todos los años comparten. Aun así, se debe hacer distinción a la hora de importar los datos entre los ficheros que cuentan con separadores de columnas y aquellos en los que cada columna tiene un número fijo de caracteres. Los datos correspondientes a un año determinado se archivaron en una carpeta nombrada con ese año y en su interior se incluyeron todos los ficheros con los datos de los meses de ese año.
El código Python empleado se apoya en la librería “os” para permitir que una vez que se accede a la carpeta de un año en concreto, se pueda importar cada uno de los ficheros “csv” o “txt” que se encuentran en su interior. Para el proceso de la importación de los datos de un año completo se emplean dos dataframes de pandas. El primero será el general, que contendrá todos los datos de ese año, y el otro será uno auxiliar. Primero se cargan los datos en el auxiliar y se elimina la columna de la variable “PUNTO_MUESTREO” si el formato es “csv” o las columnas 4 y 5 si el formato es “txt”. Posteriormente, se concatena el dataframe auxiliar al dataframe general del año. Este preprocesamiento requiere de mucho tiempo; por ello, una vez que el dataframe general del año está completo, se exporta en formato “csv” con nombre “aire_XX”, siendo XX las dos últimas cifras del año al que pertenecen los datos. Así, cuando el futuro se quieran emplear los datos, estos se importarán de manera rápida sin tener que ser preprocesados de nuevo.
En la Figura 19 se observa el dataframe correspondiente a los datos de las mediciones del año 2019 desde un Jupyter Notebook.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 29
Figura 19: Dataframe de pandas con los datos correspondientes al año 2019
3.3.6 Selección de las estaciones a considerar en la simulación. Análisis de los datos de contaminación atmosférica previamente preprocesados.
3.3.6.1 Selección de las estaciones a considerar en la simulación Como se indicó en la sección 3.3.3, sólo cinco contaminantes intervienen en el Índice Nacional de Calidad del Aire. Por ello, es necesario identificar las estaciones de medida de calidad del aire que registran datos de estos cinco contaminantes y la disponibilidad de estos registros en los diferentes años.
Para ello, una vez preprocesados los datos con el código Python del Anexo 2, se utilizó otro Jupyter Notebook para analizar y graficar la dinámica de los contaminantes atmosféricos en la ciudad de Madrid. Este código emplea dos librerías que deben ser importadas al inicio del código: pandas para la gestión de los datos, y matplotlib para la visualización de los datos mediante gráficos.
Para el análisis de los datos, es imprescindible importar los datos previamente preprocesados. El proceso se describe en la Figura 20. Se comienza importando el fichero “csv” con los datos del año 2019 al dataframe denominado “aire_df”. El siguiente paso consiste en importar el fichero “aire_18.csv” al dataframe “aire_aux”, y a continuación se concatena dicho dataframe al “dataframe aire_df”. Este último paso, se repite sucesivamente con cada uno de los ficheros de extensión “csv” correspondiente a uno de los años restantes.

Capítulo 3: Metodología
ETSII UPM 30
Datos 2019
Datos 2018
Datos 2017
Datos 2016
Datos 2015
Datos 2014
Datos 2013
Datos 2012
Datos 2011
aire_df
aire_19.csv
aire_18.csv
Se importa aldataframe aire_aux
aire_18.csv
aire_aux
aire_17.csvaire_17.csv
aire_auxSe importa al
dataframe aire_aux
aire_16.csv
Se importa aldataframe aire_aux
aire_16.csv
aire_aux
aire_15.csvaire_15.csv
aire_auxSe importa al
dataframe aire_aux
aire_14.csv
Se importa aldataframe aire_aux
aire_14.csv
aire_aux
aire_13.csvaire_13.csv
aire_auxSe importa al
dataframe aire_aux
aire_12.csv
Se importa aldataframe aire_aux
aire_12.csv
aire_aux
aire_11.csv
Se importa aldataframe aire_aux
aire_11.csv
aire_aux
Se crea el dataframe aire_df con los datos del fichero aire_19.csv1
2
3
4
5
6
7
8
9
Se concatena el dataframe aire_aux al dataframe aire_df
Fichero “csv” con los datos
Nº de paso
Dataframe de pandas
Figura 20: Proceso de importación de los datos previamente preprocesados, para proceder a su análisis
Una vez importados los datos, se puede proceder a su análisis. El análisis comienza con el estudio de qué contaminantes atmosféricos puede medir cada Estación de Calidad del Aire del Ayuntamiento de Madrid. Esta información puede observarse en la Tabla 6, una “x” indica que la estación puede medir ese contaminante y un “-” indica que no puede medirlo.
En la Tabla 7 puede observarse que las estaciones 8 (Escuelas Aguirre) y 24 (Casa de Campo) son las únicas en las que se miden los cinco contaminantes atmosféricos con los que se establece el Índice Nacional de Calidad del Aire. Además, como se aprecia en la Tabla 2, la Estación de las Escuelas Aguirre es de tipo urbana de tráfico y la de la Casa de Campo es de tipo suburbana; es decir, son representativas de diferentes tipos de contaminación. Según [26] el tráfico cercano a la estación de las Escuelas Aguirre se encuentra entre los más elevados registrados en el interior de la ciudad, ya que está instalada en la unión de tres arterias de comunicación. Se encuentra en una zona abierta, rodeada por el parque y edificios de seis pisos, y por ello no está afectada por el efecto cañón que se manifiesta en las calles estrechas. La influencia de El Retiro podría reducir el impacto del tráfico circundante. Igualmente, estos autores clasificaron a la estación de medida de Casa de Campo como suburbana. La carretera más cercana está a 1.6 km de distancia, lo que limita el impacto de las emisiones locales de tráfico. Del mismo modo, [28] analizaron las concentraciones de contaminantes registradas entre 2010 y 2017 en 20 estaciones de medida localizadas en la ciudad de Madrid y en otras áreas urbanas y rurales de

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 31
la Comunidad de Madrid. Las clasificaron realizando análisis de componentes principales y de clúster. En ambos casos, la estación de medida ubicada en la Escuelas Aguirre fue incluida entre las estaciones de marcado carácter urbano, influidas por tráfico, mientras que la estación de Casa de Campo quedó agrupada con las estaciones urbanas y rurales no directamente afectadas por el tráfico o poco pobladas.
Por estas razones, se ha optado por considerar únicamente estas dos estaciones de medida de la calidad del aire y a los cinco contaminantes que intervienen en el cálculo del IC. Por ello, se ha realizado una copia del dataframe “aire”, denominada “aire_df”, pero que sólo contiene los datos de las dos estaciones y los cinco contaminantes seleccionados.
Cada fila del dataframe “aire” contiene los datos de las mediciones horarias de un sensor de contaminación atmosférica concreto a lo largo de un día. A cada medición horaria, le corresponden dos columnas: una para el valor de la medición y otra para indicar si dicha medición es válida o no. Se analizó el número de mediciones válidas con valor igual a cero, y al ser muy escasas, junto con que la mayoría de las mediciones no válidas tienen registrado como medida un valor igual a cero, se optó por asociar el valor cero a todas las mediciones no válidas. De esta manera ya no es necesario recurrir a la columna de validación para ver si una medida horaria es válida o no. Cuando una medida de NO2, O3 o SO2 no es válida, no se puede calcular su IC para esa hora. En cambio, si la medida no válida es para la medición de PM2,5 o PM10, no se podrá calcular el IC hasta transcurridas veinticuatro horas del último cero medido. Esto es así, porque el IC de estos dos contaminantes se calcula en función de la media móvil de las últimas veinticuatro horas.

Capítulo 3: Metodología
ETSII UPM 32
Tabla 7: Contaminantes que puede medir cada Estación de Calidad del Aire del Ayuntamiento de Madrid
CONTAMINANTE SO2 CO NO NO2 PM2.5 PM10 NOx O3 Tolueno Benceno Etilbenceno Hidrocarburos
totales Metano
Hidrocarburos no metánicos ESTACIÓN
4 x x x x - - x - - - - - - - 8 x x x x x x x x x x x x x x
11 - - x x - - x - x x x - - - 16 - x x x - - x x - - - - - - 17 x x x - - x x - - - - - - 18 x x x x - x x x x x x - - - 24 x x x x x x x x x x x x x x 27 - - x x - - x x - - - x - x 35 x x x x - - x x - - - - - - 36 x x x x - x x - - - - - - - 38 x - x x x x x - x x x - - - 39 - x x x - - x x - - - - - - 40 x - x x - x x - - - - - - - 47 - - x x x x x - - - - - - - 48 - - x x x x x - - - - - - - 49 - - x x - - x x - - - - - - 50 - - x x x x x - - - - - - - 54 - - x x - - x x - - - - - - 55 - - x x - x x - x x x x x x 56 - x x x x x x x - - - - - - 57 x x x x - x x - - - - - - - 58 - - x x - - x x - - - x - x 59 - - x x - - x x - - - - - - 60 - - x x - x x x - - - - - -

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 33
3.3.6.2 Análisis de los datos de contaminación atmosférica previamente preprocesados.
[29] mostraron la existencia de variaciones horarias, diarias (entre fines de semana y días laborables), y estacionales en las concentraciones de los contaminantes de interés durante el periodo 1999-2012. No obstante, los cambios que se han producido en los últimos diez años en la movilidad urbana de Madrid, la introducción de vehículos menos contaminantes, y las propias actuaciones del Ayuntamiento de Madrid para reducir la contaminación atmosférica, demandan un análisis específico para el periodo considerado en este trabajo (2011-2019). [29], [26], [30] y [28] subrayaron que la dinámica de estos patrones es diferente en las estaciones de medida de calidad del aire de Escuelas Aguirre (EA) y Casa de Campo (CC). Por ello, se ha realizado el análisis de dichos patrones a partir de los datos preprocesados de las dos estaciones seleccionadas. Los resultados de este análisis pueden tener relevancia para la simulación propuesta en el estudio. En caso de verificarse los patrones mencionados y su diferente comportamiento en EA y CC, se podría incrementar la eficiencia de la red inalámbrica de sensores, apoyándose en dicha para determinar la frecuencia con la que se envía la información desde los nodos al nodo coordinador, y el grado de procesamiento con el que se envían dichos datos.
Para ello, se ha añadido una columna denominada “DIA_SEM” que contendrá el día de la semana. La columna se ha rellenado con la ayuda de la librería datatime, que permite obtener el día de la semana en inglés (Monday/Tuesday/Wednesday/Thursday/Friday/Saturday /Sunday) a partir de un año, mes y día.
También se ha añadido una columna al dataframe “aire” considerando la estación del año, para poder estudiar la influencia de esta variable en las concentraciones de los contaminantes atmosféricos que forman el Índice de Calidad en las dos estaciones seleccionadas. Esta columna se rellena de acorde a la Tabla 8.
Tabla 8: Valor de la columna "EST_ANO" según el mes al que pertenecen los datos de las mediciones de un determinado contaminante atmosférico.
Valor columna “EST_ANO” Estación año Meses 0 Invierno Diciembre/Enero/Febrero 1 Primavera Marzo/Abril/Mayo 2 Verano Junio/Julio/Agosto 3 Otoño Septiembre/Octubre/Noviembre
Para facilitar el análisis de los datos de cada contaminante, se han realizado copias del dataframe “aire”, pero cada una de ellas contiene únicamente los datos de las mediciones de un solo contaminante. Las copias son:
• “aire_SO2”: con los datos de las mediciones de SO2 de las estaciones 8 y 24. • “aire_NO2”: con los datos de las mediciones de NO2 de las estaciones 8 y 24. • “aire_PM25”: con los datos de las mediciones de PM2,5 de las estaciones 8 y 24. • “aire_PM10”: con los datos de las mediciones de PM10 de las estaciones 8 y 24. • “aire_O3”: con los datos de las mediciones de O3 de las estaciones 8 y 24.
A cada uno de estos cinco dataframes se les ha añadido veinticuatro columnas (“IC_XX”, siendo XX la hora), una por hora del día, con el Índice Nacional de Calidad del Aire que tendría el contaminante de la fila en cuestión a una hora determinada. Estas columnas facilitarán el análisis de los datos, ya que los Índices de Calidad de distintos elementos son comparables, mientras que las medidas directas de cada contaminante no lo son. La columna calidad del aire se ha rellenado de acorde a la Tabla 8.

Capítulo 3: Metodología
ETSII UPM 34
Tabla 9: Valor de la columna "IC_XX" para la hora XX según el Índice Nacional de Calidad del Aire.
Valor columna “IC_XX” Índice Nacional de Calidad del Aire
0 No válido 5 Muy bueno 4 Bueno 3 Regular 2 Malo 1 Muy malo
Cada uno de estos cinco dataframes se ha dividido a su vez en dos, una división para los datos de la Estación de Escuelas Aguirre y la otra para los datos de la Estación de la Casa de Campo. Por tanto, se utilizaron diez dataframes distintos para el análisis de los datos.
Una vez terminado el procesamiento de los datos, se procedió a su análisis.
3.3.6.3 Análisis de la evolución del IC de cada contaminante en función de los días de la semana. El primer análisis realizado estudia la evolución del IC de cada uno de los contaminantes considerados en los diferentes días de la semana (lunes, martes, miércoles, etc.), para determinar si los niveles de contaminación son más elevados en determinados días de la semana que en otros.
Para ello se han creado cinco histogramas, uno por cada por cada contaminante considerado en el IC Nacional, un histograma por cada nivel de IC (NO2, SO2, PM2,5, PM10 y O3). En ellos se representa el número de horas que ha permanecido un determinado contaminante en cada nivel del IC y en cada estación, y en cada uno de los días de la semana. Dichos histogramas se presentan en las Figuras 21 a 25. En azul están representados los datos de la Estación de Calidad del Aire de las Escuelas Aguirre y en naranja los de la Estación de la Casa de Campo.
En la Figura 21 se presentan los datos correspondientes a la evolución de los niveles de IC de SO2 a lo largo de la semana. Se aprecia que no se registran niveles “regulares”, “malos” o “muy malos” en ninguna de las dos estaciones y no se aprecia variación alguna a lo largo de la semana. Estos datos muestran que este contaminante no conlleva riesgos para la salud humana, y constatan que la sustitución de calefacciones de carbón (reducción del 81%) y gasoil (disminución del 44%) por las de gas natural (incremento del 64%) entre 1999 y 2012, tuvieron un efecto importante en la disminución de los niveles de SO2 por estas fuentes (reducción del 36%) [29]. También tuvo un gran efecto la entrada en vigor en 2009 de la Directiva 2003/17/EC, que limitaba la concentración de azufre en los combustibles de los vehículos a 10 mg/kg, suponiendo disminuciones del 58% de las emisiones de tráfico [29].
En el caso del NO2 (Figura 22), se puede apreciar que no se registran niveles de IC de este contaminante “regulares”, “malos” o “muy malos” en la estación de la Casa de Campo. Por el contrario, estos niveles sí se alcanzan en la estación de las Escuelas Aguirre, y además se aprecia que en esta estación estos índices más perjudiciales tienen mucha menor incidencia (casi la mitad) durante el fin de semana (sábado y domingo), incrementando el lunes, manteniéndose de martes a jueves, y disminuyendo el viernes. Además, el número de horas en que el IC del NO2 es “muy bueno” es siempre superior en la estación de Casa de Campo (CC) que en la de Escuelas Aguirre (EA). Los patrones observados coinciden con el carácter de estación suburbana de CC que recoge la contaminación de fondo, y con el de estación urbana influenciada por el tráfico de EA. Es de resaltar que en EA no se registran niveles de IC de este contaminante “muy malos” y sólo una hora se registró un valor “malo”. [29] señalaron que el cambio ya mencionado del

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 35
tipo de calefacción supuso una reducción del 76% de las concentraciones de NO2 relacionadas con estas fuentes.
En lo que respecta a los niveles de PM10 (Figura 23), se aprecia que la frecuencia de los niveles de IC de este contaminante de la categoría “muy buenos” es superior en CC respecto a EA, independientemente del día de la semana. Por el contrario, la suma de las frecuencias correspondientes a las categorías “regular”, “malo” y “muy malo” es muy superior en EA que en CC, y que, al igual que ocurre con el NO2, se produce una disminución de las concentraciones de PM10 durante el fin de semana, incrementándose el lunes y permaneciendo prácticamente constantes entre martes y viernes. Estos resultados refuerzan los perfiles de EA y CC, como estación urbana influenciada por el tráfico y de fondo, respectivamente. El comportamiento de los niveles de PM2,5 (Figura 24) es muy similar al de PM10.
[29] indicaron que el cambio a vehículos de gasoil provocó inicialmente (1992-2009) mayores emisiones de PM y de NOx. La entrada posterior de los vehículos EURO diésel, mucho menos contaminantes, provocó una reducción de las emisiones por vehículo de PM2,5 y NO por vehículo, al tiempo que se incrementaba el de NO2. Por ello, entre 1999 y 2007 las concentraciones de NO2 permanecieron estables. Finalmente, la reducción del tráfico rodado en la ciudad entre 2007 y 2012, se tradujo en menores emisiones de NOx y PM que en el periodo anterior.
En contraposición con los registros de NO2, PM10 y PM2,5, la suma de frecuencias del IC de O3 correspondientes a las categorías “regular”, “malo” y “muy malo” no mostró variación entre los días de la semana. Igualmente, en contraste con los resultados de esos contaminantes, dicha suma de frecuencias fue superior en CC que en EA. Ello se debe a que el NO emitido por los vehículos reacciona con el O3 que existe en el interior de la ciudad, provocando una disminución de la concentración de este último al tiempo que se eleva la concentración de NO2. Este fenómeno no se produce en CC al ser una estación de fondo y no estar afectada por el tráfico local [29].

Capítulo 3: Metodología
ETSII UPM 36
Figura 21: Variación del Índice de Calidad del Aire de SO2 en las estaciones de las Escuelas Aguirre (Estación 8) y de la de la Casa de Campo (estación 24) en función del día de la semana

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 37
Figura 22: Variación del Índice de Calidad del Aire de NO2 en las estaciones de las Escuelas Aguirre (Estación 8) y de la de la Casa de Campo (estación 24) en función del día de la semana

Capítulo 3: Metodología
ETSII UPM 38
Figura 23: Variación del Índice de Calidad del Aire de PM10 en las estaciones de las Escuelas Aguirre (Estación 8) y de la de la Casa de Campo (estación 24) en función del día de la semana

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 39
Figura 24: Variación del Índice de Calidad del Aire de PM2,5 en las estaciones de las Escuelas Aguirre (Estación 8) y de la de la Casa de Campo (estación 24) en función del día de la semana

Capítulo 3: Metodología
ETSII UPM 40
Figura 25: Variación del Índice de Calidad del Aire de O3 en las estaciones de las Escuelas Aguirre (Estación 8) y de la de la Casa de Campo (estación 24) en función del día de la semana

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 41
3.3.6.4 Análisis de la variación de la frecuencia de los episodios de contaminación asociados a los distintos contaminantes según la estación del año
[29] indicaron la existencia de importantes variaciones estacionales tanto en las concentraciones de los cinco contaminantes considerados (NO2, SO2, O3, PM10 y PM2,5), como en la frecuencia de los episodios de contaminación durante el periodo 1999-2012. Por ello, se ha realizado un análisis de la variación frecuencia (número de horas) con la que se registran las diferentes categorías de los ICs de los distintos contaminantes en función de la estación del año para el intervalo temporal 2011-2019 considerado en este trabajo (Figuras 26 a 29).
Las representaciones de los datos correspondientes al invierno pueden verse en la Figura 26. Se observa que los ICs de NO2, SO2 y O3 en EA y CC permanecen durante prácticamente la totalidad de esta estación del año en la categoría de “muy bueno”. Además, en el caso del IC de NO2, se registra un número muy escaso de horas en el que fue “regular”, no apreciándose episodios por debajo de esta categoría. Por el contrario, los ICs de PM2,5 y PM10 bajo la categoría de “muy bueno” fue menor que para los contaminantes anteriores, al tiempo que las frecuencias de las categorías “regular”, “mala” y “muy mala” fue mayor que para los contaminantes anteriores. En general estas situaciones de episodios de contaminación fueron más frecuentes en EA que en CC, siendo debidas muy probablemente al carácter urbano de la primera estación de medida de calidad del aire.
Figura 26 Histogramas con la frecuencia (número de horas) correspondiente a cada categoría de Índice de Calidad del Aire (IC) durante el invierno en las estaciones de medida de la contaminación atmosférica de Escuelas Aguirre
(Estación 8) y Casa de campo (Estación 24). El IC varía entre 1 (“muy malo”) y 5 (“muy bueno”).
Las representaciones de los datos correspondientes a la primavera pueden verse en la figura 27. Los IC del NO2 y del SO2 permanecieron durante prácticamente la totalidad de esta estación en la categoría “muy bueno”. El IC del O3 e se mantuvo durante la mayor parte de este periodo entre los niveles “muy bueno” y “bueno”. Ha de destacarse que CC permanece más horas con un nivel IC de este contaminante inferior al de EA. Los histogramas de los ICs de PM2,5 y PM10

Capítulo 3: Metodología
ETSII UPM 42
son muy similares, apreciándose que permanecen muchas menos horas a nivel “muy bueno” que el resto de los otros tres contaminantes y se observa que el IC para estos contaminantes es peor en la EA que en CC. Salvo en el caso del O3, no se aprecian diferencias relevantes en los ICs de los contaminantes entre invierno y primavera.
Figura 27: Histogramas con la frecuencia (número de horas) correspondiente a cada categoría de Índice de Calidad del Aire (IC) durante la primavera en las estaciones de medida de la contaminación atmosférica de Escuelas Aguirre
(Estación 8) y Casa de campo (Estación 24). El IC varía entre 1 (“muy malo”) y 5 (“muy bueno”).
Durante el verano (figura 28), los ICs de NO2 y SO2 permanecen prácticamente en la categoría de “muy bueno”. Respecto a la primavera, en este periodo disminuye el número de horas en que el IC de O3 se mantiene en la categoría de “muy bueno”, aumentándola frecuencia de ICs de las categorías “bueno” y “regular”. La estación de CC permanece muchas más horas con peor IC de este contaminante que EA. También, es más frecuente que el IC de las PM2,5 y de las PM10 se encuentre a un nivel “regular” o “malo” que en la primavera. Además, se observa como las horas que permanecen los IC de estos dos contaminantes es mucho mayor para la Estación de las Escuelas Aguirre que para la Estación de la Casa de Campo.
Las representaciones de los datos correspondientes al otoño pueden verse en la Figura 29. Se observa como el NO2, el SO2 y el O3 permanecen prácticamente la totalidad de este periodo de con un índice de calidad muy bueno. El tiempo que permanecen los IC del PM2,5 y PM10 en el nivel “muy bueno” es muy inferior al de los tres contaminantes anteriores, siendo más elevadas las frecuencias de las categorías “bueno”, “regular” y “malo”. El número de horas de estas tres categorías fue superior en EA que en CC, correspondiendo con sus caracteres de estación urbana y de fondo, respectivamente. Además, se apreció un incremento de la frecuencia de ICs de PM10 de la categoría “regular” respecto a la primavera y las otras estaciones del año. Ello puede deberse a episodios de contaminación atmosférica bajo condiciones en las que los sistemas de
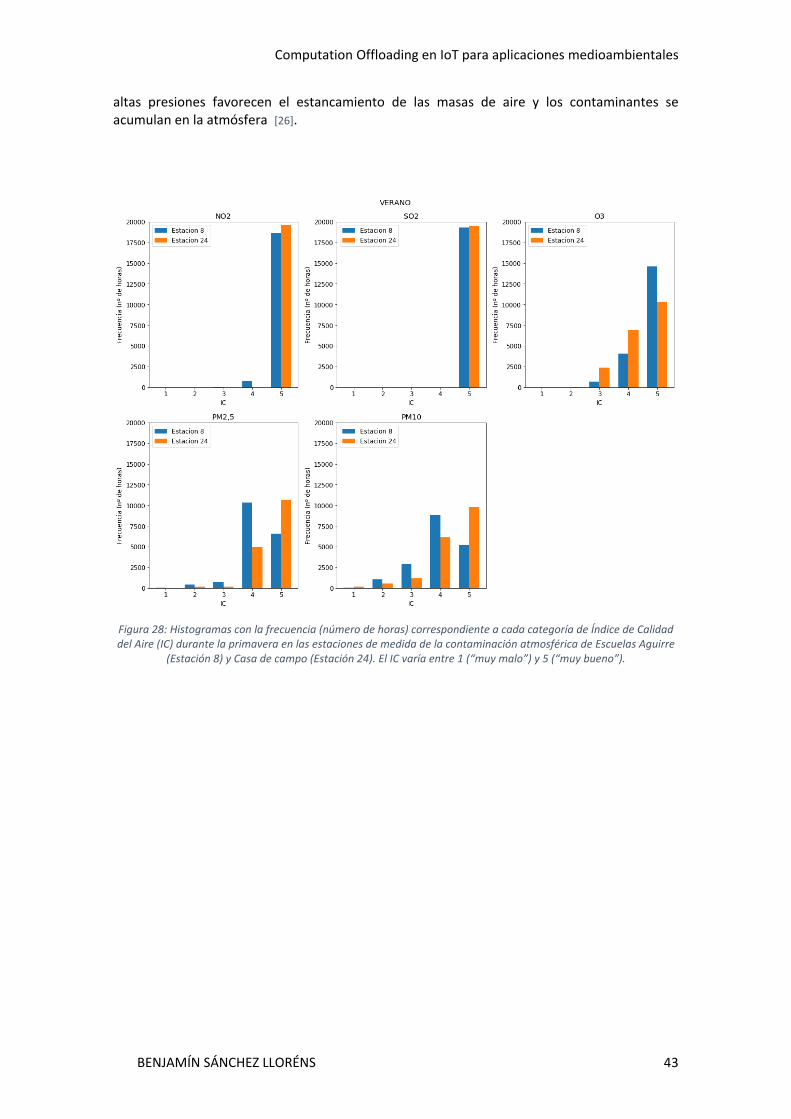
Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 43
altas presiones favorecen el estancamiento de las masas de aire y los contaminantes se acumulan en la atmósfera [26].
Figura 28: Histogramas con la frecuencia (número de horas) correspondiente a cada categoría de Índice de Calidad del Aire (IC) durante la primavera en las estaciones de medida de la contaminación atmosférica de Escuelas Aguirre
(Estación 8) y Casa de campo (Estación 24). El IC varía entre 1 (“muy malo”) y 5 (“muy bueno”).

Capítulo 3: Metodología
ETSII UPM 44
Figura 29: Histogramas con la frecuencia (número de horas) correspondiente a cada categoría de Índice de Calidad del Aire (IC) durante la primavera en las estaciones de medida de la contaminación atmosférica de Escuelas Aguirre
(Estación 8) y Casa de campo (Estación 24). El IC varía entre 1 (“muy malo”) y 5 (“muy bueno”).
3.3.6.5 Análisis de la evolución del promedio horario del Índice de Calidad de cada contaminante en las dos estaciones de medida de calidad del aire consideradas, durante las cuatro estaciones del año
[26] y [30] señalaron la existencia ciclos diarios en los niveles de contaminantes atmosféricos en la ciudad de Madrid, influenciados tanto por las emisiones correspondientes a las horas en las que existe un mayor tráfico, como por las interacciones entre los contaminantes [28], que a su vez está influenciadas por variables meteorológicas tales como la temperatura del aire y la radiación ultravioleta. Como ya se comentó en el apartado anterior, las concentraciones máximas alcanzadas en cada estación del año pueden estar también afectadas por las emisiones de las calefacciones en otoño e invierno o por la mayor radiación ultravioleta en verano, además de por el éxodo de los madrileños hacia sus segundas residencias u otros destinos durante el verano.
Por ello se ha realizado un análisis de la evolución del promedio horario del IC de los cinco contaminantes (NO2, SO2, PM10, PM2,5 y O3) y las dos estaciones de medida de calidad del aire (Escuelas Aguirre -EA y Casa de Campo - CC) consideradas en este estudio, en las cuatro estaciones del año (véase la Figura 30).
Cada fila de gráficos contiene los datos de una estación del año, mientras que cada columna de gráficos contiene los datos de una Estación de Calidad del Aire. La columna izquierda contiene los datos de la estación EA y la derecha los de la estación CC. En el eje de las abscisas se presenta la hora del día (1 a 24), y en el de ordenadas el Índice de Calidad de Aire promedio de cada cada contaminante (IC) para una hora determinada. Conviene recordar que el IC oscila entre valores de 1 a 5, el guarismo 1 a la categoría “muy malo” y el 5 a la de “muy bueno”. Puede apreciarse

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 45
que todos los valores representados se encuentran por encima de un IC 3,5. Por ello, y para facilitar la visualización de las fluctuaciones que sufren los contaminantes según la hora del día, se ha limitado el eje de ordenadas a los valores comprendidos entre tres y cinco.
A partir de los gráficos correspondientes al invierno, se observa que en ambas estaciones el peor IC medio horario es el del PM2,5, con valores en el límite superior de la categoría “bueno” y el siguiente peor es el del PM10, con valores en el límite inferior de la categoría “muy bueno”. Ambos contaminantes permanecen prácticamente estables a lo largo de todo día. También, se puede observar que el valor casi constante de ambos ICs es ligeramente inferior en EA que en CC. El resto de los contaminantes presentan IC muy superiores a los dos anteriormente citados, correspondiendo siempre a la categoría “muy bueno”. El IC del SO2 se encuentra en el rango alto de la categoría “bueno” y en la categoría “muy bueno”. El O3 registra un comportamiento similar, debido a que la temperatura del aire y la radiación solar no favorecen su formación en esta época del año. El NO2 presenta en EA una cierta disminución de su IC entre las seis de la tarde y las 10 de la noche, posiblemente como consecuencia del aumento del tráfico y el encendido de las calefacciones.
En los gráficos correspondientes a la primavera se observa que PM10 y PM2,5 presentan valores de sus ICs inferiores al resto de contaminantes, siempre en el rango inferior de la categoría “bueno”, siendo constantes y muy parejos entre sí a lo largo del día. Los ICs del resto de contaminantes se encuentran en el rango alto de la categoría “bueno” (O3), llegando a alcanzar la categoría de “muy bueno” los ICs de SO2 y NO2 durante algunas horas. Se debe destacar la evolución diaria del IC del O3, que aunque siempre se encuentra en la categoría “bueno”, disminuye a partir de las nueve de la mañana, presentando un mínimo en torno a las cuatro de la tarde y comienza su ascenso hasta las nueve de la noche, hora en la que se estabiliza a un nivel próximo a muy bueno hasta las nueve de la mañana. Este descenso es más marcado en CC, cuyo mínimo del IC de O3 es similar a los valores de los IC de PM2,5 y las PM10. Como ya se indicó en la sección anterior, el O3 reacciona con las emisiones de los vehículos cuando hay más tráfico, disminuyendo su concentración, y sus máximos se registran cuando hay menos tráfico y cuando la radiación solar es más elevada. El hecho de que CC presente valores menores del IC de O3 que EA, se debe a que es una estación que recoge el fondo de contaminación, en la que las emisiones de NO del tráfico no provocan una disminución del O3 al reaccionar con este contaminante. Durante el verano, el IC de PM10 permanece constante, con valores en el rango superior de la categoría “regular”, al igual que el IC de PM2,5, si bien sus niveles se encuentran en el rango inferior de la categoría “bueno”. El mínimo del IC de O3 es más marcada en esta estación del año que en primavera, quedando sus valores en el límite inferior de la categoría “bueno” en el caso de EA y el límite superior de la categoría “regular” en el caso de CC. Los ICs de SO2 se mantienen entre el rango alto de la categoría “bueno” y en la categoría “muy bueno”, al igual que los de NO2.
En otoño, de nuevo los niveles de los IC de PM10 y PM2,5 son menores que para el resto de los contaminantes, encontrándose siempre en el rango inferior de la categoría “bueno”. Los Ic de los otros tres contaminantes permanece en el rango alto de la categoría “bueno” o en la de “muy bueno”. Se aprecia una reducción en el nivel mínimo diurno de O3 respecto al verano, siendo este mínimo menor en CC que en EA. También se observa que una disminución del IC del NO2 desde las 16 a las 22 horas, al igual que sucedía en invierno, motivada igualmente por el tráfico, y el encendido de las calefacciones.
A partir de los análisis realizados por el autor de este trabajo, descritos en los apartados 3.3.6.2, 3.3.6.3., y 3.3.6.4, se pueden extraer diversas conclusiones. Los ICs de SO2 se mantienen en niveles no preocupantes para la salud humana en EA y CC, independientemente de la hora del día, el día de la semana o la estación del año. Por el contrario, los ICs de NO2, PM10 y PM2,5 alcanzaron mayor frecuencia de valores preocupantes para la salud en días laborables que

Capítulo 3: Metodología
ETSII UPM 46
durante el fin de semana, siendo mayor el número de horas con este tipo de ICs para PM10 y PM2,5 que para NO2. Se apreció un aumento de este tipo de ICs en PM10 durante el verano, en comparación con otras épocas del año. Se registraron concentraciones No se encontraron variaciones en el ciclo diario de los ICs de PM10 y PM2,5, apreciándose un aumento de las concentraciones de NO2 desde las 16 a las 22 horas. En todos los casos, EA registró una mayor frecuencia de ICs asociados a riesgos para la salud que CC.
En el caso de los ICs de O3, no se apreciaron diferencias entre días laborables y no laborables, aunque sí se registró un marcado ciclo diurno en sus concentraciones durante la primavera y el verano, alcanzando sus mayores concentraciones entre las 13 y las 19 horas, y registrándose niveles de riesgo para la salud. La frecuencia de estos niveles fue mayor en CC que en EA, en contraposición con los resultados obtenidos para los tres contaminantes anteriores.
Figura 30: Evolución de los promedios horarios de los Índices de Calidad de los contaminantes considerados,
registrados en las estaciones de medida de Escuelas Aguirre (Estación 8) y Casa de Campo (Estación 24) en las cuatro estaciones del año.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 47
3.4 Simulación de la captación de datos por parte de los nodos equipados con sensores para la medición de contaminantes atmosféricos.
El objetivo de este trabajo es la creación de un entorno de simulación de una red inalámbrica de sensores para comprobar la efectividad de la aplicación de las metodologías del Resource Allocation y el Computation Offloading. Al tratarse de una simulación, no se cuenta con sensores físicos que aporten los datos de las mediciones. Ello implica tener que sustituir la captación física de datos por una captación simulada, pero considerando los datos reales facilitados por el Ayuntamiento de Madrid. Por ello, se implementó el sistema de computation offloading basado en datos totalmente reales, pero simulando que estos son recogidos por los nodos simulados.
Si se desplegase físicamente la red inalámbrica de sensores, la recogida de datos sería directa. Cada nodo estaría conectado a un sensor de un contaminante atmosférico en concreto, y cada medio segundo, el nodo obtendría una medición de dicho contaminante para su posterior procesamiento o envío al Gateway. Sin embargo, esta opción no es válida cuando se consideran simulaciones basadas en datos reales y por ello se han tenido que explorar distintas soluciones.
Los datos disponibles en la página web del Ayuntamiento de Madrid, se corresponden con los promedios horarios de los diferentes contaminantes atmosféricos. Sin embargo, los monitores de medición en continuo proporcionan mediciones cada 0,5 segundos. Para asegurar que la frecuencia de entrada de datos a los nodos de la red utilizada en el presente trabajo se corresponde con la de las estaciones reales, se optó inicialmente por considerar 7.200 mediciones con el valor del promedio horario para cada hora de la simulación.
Los nodos de las redes inalámbricas de sensores son dispositivos con recursos muy limitados al estar diseñados para mantener un consumo energético mínimo y un coste reducido. Ello implica limitaciones en las capacidades de procesamiento y memoria.
En un principio se valoró la opción de almacenar los datos de los nueve años de mediciones de un contaminante atmosférico en el propio nodo empleando una cadena de caracteres o un vector. De esta manera, cada cierto tiempo el nodo accedería a la posición adecuada de la cadena de caracteres o del vector y extraería la medición.
Tras la realización de ciertas comprobaciones, se dedujo que debido a la limitación en memoria con la que cuentan estos nodos, esta opción no es viable ya que esta se satura con los datos correspondientes a las mediciones de un único mes.
Para solventar la captación de datos simulada, se han distinguido dos fases de actividad del nodo. En la fase de configuración del nodo, se cargan los datos reales de mediciones de contaminación atmosférica. En la otra fase, se ejecuta la simulación del comportamiento del nodo, empleando los datos previamente almacenados. El cambio de una fase a la otra es iterativo.
La propuesta para la fase de configuración consiste en que cada nodo cuenta con una cadena de caracteres con la capacidad de almacenar las veinticuatro mediciones diarias correspondientes a ocho días, es decir, 192 mediciones horarias. Estas mediciones se guardan como números enteros que ocupan tres caracteres. La estructura de la cadena puede observarse en la Figura 31. En esta figura se representa la cadena de caracteres en el instante inicial, ya que está completamente rellena de ceros.
000 000 … 000 000 … 000 … … 000 … 000
Figura 31: Cadena de caracteres correspondiente al instante en el que se inicializa el nodo.
Día 1 Día 2 Día 8
Hora 1 Hora 2 Hora 24 Hora 1 Hora 24

Capítulo 3: Metodología
ETSII UPM 48
Para la implementación de esta solución se ha considerado que los meses están compuestos por cuatro bloques de ocho días, es decir, treinta y dos días por mes. En la Figura 32 se muestran los cuatro bloques de datos que formarían un mes.
Día 1 Día 2 Día 3 Día 4 Día 5 Día 6 Día 7 Día 8
Día 9 Día 10 Día 11 Día 12 Día 13 Día 14 Día 15 Día 16
Día 17 Día 18 Día 19 Día 20 Día 21 Día 22 Día 23 Día 24
Día 25 Día 26 Día 27 Día 28 Día 29 Día 30 Día 31 Día 32
Figura 32: Representación de los cuatro bloques de datos en los que se divide el mes.
Una vez inicializado el nodo, establece contacto con el Gateway y le solicita los datos de las mediciones horarias correspondientes a los días del bloque en el que se encuentra la fecha de inicio de la simulación. Por ejemplo, si la simulación tiene el día cinco como fecha de inicio de simulación, el nodo solicitará al Gateway las mediciones comprendidas entre los días uno y el ocho, ambos incluidos.
Al llegar al final de los datos almacenados pertenecientes a un bloque, el nodo debe solicitar al Gateway que le facilite los datos correspondientes a las mediciones horarias de los días pertenecientes al siguiente bloque. Siguiendo con el ejemplo anterior, los datos se acabarían al llegar al de las doce de la noche del día ocho. Entonces, el nodo debe solicitar al Gateway los datos de las mediciones comprendidas entre los días día 9 y el dieciséis, ambos incluidos. Una vez almacenados los datos del nuevo bloque, se continuaría con la fase de simulación.
Para el envío de los datos del último bloque de días desde el Gateway al nodo, se rellena con ceros las mediciones de los días inexistentes. Por ejemplo, el mes de abril tiene 30 días; por tanto, al ir a enviar el último bloque de datos del mes, se enviarán ceros como las mediciones de los días 31 y 32. Un ejemplo de ello se puede ver en la Figura 33.
012 011 … 017 019 … 018 … … 000 … 000 000 …. 000
Figura 33: Cadena de caracteres en la que un nodo equipado con sensores almacena las mediciones horarias de un contaminante atmosférico, después de recibir los datos correspondientes al último bloque de días.
Se debe resaltar que se ha tenido que optar por la simulación de la captación de datos, basada en el intercambio de datos entre el Gateway y el nodo equipado del sensor, al no poder realizar mediciones mediante sensores. Por ello, al tratarse de un recurso empleado de cara a la simulación y no ser parte del funcionamiento estricto del nodo, se descuenta del consumo propio de la batería, el gasto de batería asociado a la petición, recepción y almacenamiento de los datos por parte del nodo equipado con el sensor.
3.5 Modelado de la batería de los nodos equipados con sensores de contaminantes atmosféricos.
La implementación de un algoritmo basado en Computation Offloading y Resource Allocation requiere conocer determinados parámetros de la red, así como el estado de cada uno de los nodos que la forman. La capacidad de batería restante de cada nodo es un parámetro fundamental para este tipo de algoritmos, ya que, dependiendo de la configuración de la red, si un nodo se queda sin batería puede suponer que el Gateway pierda la comunicación con el resto de los nodos.
Hora 1 Hora 2 Hora 24 Hora 1 Hora 24 Hora 1 Hora 24
Día 25 Día 26 Día 32 Día 31

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 49
Para conocer la capacidad restante de batería se recurre a un modelo que periódicamente calcule su estado. El modelo debe tener en cuenta la capacidad inicial de la batería, los consumos reales del nodo, y el tiempo que el nodo procesa o se comunica.
3.5.1 Consumos reales del Sky Mote
Para el modelado de la batería se requiere conocer el consumo de los distintos componentes que forman el nodo con la mayor precisión posible. A mayor precisión en los consumos, más fiel a la realidad será el modelo.
Una opción es considerar los consumos de corriente reflejados en la hoja de especificaciones técnicas del Sky Mote. Sin embargo, es mucho más preciso emplear los consumos reales del Sky Mote. En [40] se proporcionan los consumos reales de los distintos componentes del nodo (ver Tabla 10). Estos consumos serán los empleados en el presente trabajo.
Tabla 10: Consumos del Sky Mote según [40]
Componente y estado Consumo real Microprocesador activo 2,33 mA Microprocesador en modo bajo consumo 1,80 µA Radio TX 20,47 mA Radio RX 19,37 mA Radio Off 2,4mA
3.5.2 Cuantificación del tiempo que permanece activa cada componente de un nodo
Para el modelado de la capacidad de la batería de un nodo, también se requiere conocer el tiempo que el nodo permanece con:
• La radio activa y transmitiendo • La radio activa y a la escucha • El microprocesador activo • El microprocesador en modo de bajo consumo
Contiki-NG cuenta con un módulo denominado Energest [41] que permite obtener estos tiempos. En la API de Contiki-NG se explica cómo se debe incluir este módulo a través del fichero makefile, y las distintas funciones que incluye. Para cada función hay una explicación de cuál es su fin y de cómo se emplea.
En concreto, las funciones empleadas para la implementación del modelo de la batería son:
- energest_type_time(ENERGEST_TYPE_CPU): devuelve el tiempo en segundos que el microprocesador ha permanecido activo.
- energest_type_time(ENERGEST_TYPE_LPM): devuelve el tiempo en segundos que el microprocesador ha permanecido en modo de bajo consumo.
- energest_type_time(ENERGEST_TYPE_TRANSMIT): devuelve el tiempo en segundos que la radio ha permanecido encendida y transmitiendo.
- energest_type_time(ENERGEST_TYPE_LISTEN): devuelve el tiempo en segundos que la radio ha permanecido encendida y a la escucha de mensajes.
El tiempo que devuelven las mencionadas funciones es acumulativo desde la inicialización del nodo. Por ello, si se desea conocer cuánto tiempo ha estado transmitiendo un nodo en los últimos cinco minutos, se debe solicitar el tiempo en el que ha transmitido el nodo hasta justo

Capítulo 3: Metodología
ETSII UPM 50
antes de esos cinco minutos, y el tiempo de transmisión una vez transcurridos los cinco minutos. Así, el tiempo durante el cual el nodo ha transmitido en esos cinco minutos se obtiene restando el tiempo inicial del tiempo final.
El tiempo total de la simulación se obtiene sumando el tiempo en el que el microprocesador ha permanecido activo con el que ha permanecido en modo de bajo consumo. Por otro lado, el período en el que el nodo ha permanecido con la radio apagada se obtiene restando del tiempo total, el tiempo que el nodo ha permanecido transmitiendo o a la escucha.
3.5.3 Modelo de la batería
Una vez conocidos los consumos reales de los distintos componentes que forman el nodo, y conociendo cómo obtener los tiempos que permanecen activos dichos componentes, se debe recurrir a un modelo que actualice periódicamente la capacidad restante de la batería. La capacidad de la batería representa la cantidad de energía almacenada cuando la batería se encuentra completamente cargada y se mide en miliamperios-hora (mAh).
La capacidad de una batería se mide con la batería inicialmente completamente cargada; se somete a un proceso de descarga a intensidad constante hasta que la tensión cae por debajo de un determinado valor. Por ejemplo, la batería más utilizada en redes inalámbrica de sensores es la batería de litio CR2032. Su capacidad se mide sometiéndola a un proceso de descarga a intensidad constante de 0,5 mA, hasta alcanzar los 2 voltios.
Existen múltiples factores que afectan a la capacidad de la batería, como la tasa de descarga, la de autodescarga, y el tiempo de uso o la temperatura. La tasa de descarga o la intensidad de corriente cedida por la batería es el factor más influyente [42].
Al incrementar la intensidad constante a la que se produce la descarga, se reduce la capacidad de la batería. Esta reducción se produce en mayor medida cuando la intensidad presenta picos, en lugar de ser constante. En la Figura 34 se observan los distintos comportamientos de la capacidad de la batería en función de la intensidad de descarga y su heterogeneidad.
Figura 34: Curva de descarga de la batería CR2032 en condiciones de intensidad constante o heterogénea [43]
Para la realización de este proyecto se ha escogido el modelo de batería expuesto en la publicación “Battery Capacity Estimation of Wireless Sensor Node” [43].
Este modelo se basa en la corriente que consume un nodo durante un periodo de tiempo. Cada vez que transcurre dicho periodo de tiempo, se actualiza la capacidad de batería restante y comienza un nuevo periodo.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 51
El modelo [43] es un método iterativo que se debe actualizar cada vez que se completa un ciclo de trabajo del nodo. El modelo queda definido mediante la siguiente ecuación:
𝐶𝐶(𝑖𝑖) = 𝑘𝑘 ∗ 𝐶𝐶(𝑖𝑖 − 1) − 𝐼𝐼 ∗ 𝑇𝑇𝑤𝑤 , 𝑖𝑖 = 1, … ,𝑛𝑛
En la ecuación, k corresponde al factor de eficiencia de la batería, C(0) es la capacidad máxima de la batería, I representa la intensidad media durante el último ciclo de trabajo, Tw es la duración del periodo del ciclo de trabajo y n representa el número de ciclos de trabajo completados en un periodo de tiempo.
El factor de eficiencia k depende de la intensidad I; tiende a uno cuando la tasa de descarga es baja y tiende a cero cuando la tasa de descarga es alta. El factor de eficiencia se calcula como:
𝑘𝑘 =𝐶𝐶𝑒𝑒𝑒𝑒𝑒𝑒𝐶𝐶𝑚𝑚𝑚𝑚𝑚𝑚
Siendo Ceff la capacidad efectiva de la batería y Cmax la capacidad máxima de la batería. Ceff depende de la demanda de corriente y se puede definir como el producto de la intensidad de descarga por el periodo de descarga.
Cuanto más se aproxime k a uno, mayor duración tendrá la batería. Normalmente, las baterías de litio-ion tienen el factor k comprendido entre 0,9960 y 0,9999. Para este trabajo se ha tomado k igual a 0,99795, al tratarse del valor intermedio del rango que especifica la publicación.
La I empleada en la ecuación que actualiza la capacidad restante de batería es una media ponderada de los consumos de corriente de cada componente con el tiempo que han permanecido activos en el ciclo de trabajo que se está teniendo en cuenta.
Para las simulaciones realizadas en este trabajo se ha considerado una batería de 2600 mAh de capacidad. La batería de la marca Saft, modelo “LS 14500” [44] cumple con estas especificaciones. Se trata de una batería de 3,6 V, con una capacidad nominal de 2600 Ah y una energía nominal de 9,36 Wh.
3.6 “Resource allocation” y “Computation offloading”
Para la implementación de un algoritmo basado en las metodologías “Resource Allocation” y “Computation Offloading”, se deben establecer en primer lugar unos niveles de trabajo en los que varíe el grado de procesamiento realizado por el nodo equipado con sensores, así como la frecuencia y cantidad de datos enviados al Gateway de la red. Posteriormente, se debe diseñar e implementar un algoritmo que establezca a qué nivel debe trabajar cada nodo de la red en función de una serie de parámetros.
3.6.1 Modos de procesamiento del nodo y transmisión al Gateway.
El flujo de trabajo consiste en recoger la medida del contaminante de interés, calcular el promedio horario, y a partir de él, calcular el IC para dicho contaminante. En el caso de los nodos asociados a los sensores, se han diseñado cuatro modos distintos de trabajo, cada uno con distintos grados de procesamiento y de comunicación. Por ello, en función del grado de procesamiento realizado en los nodos asociados a los sensores, el Gateway recibirá un mayor o menor número de datos y tendrá que realizar un distinto esfuerzo de procesamiento para cumplir todas las tareas del flujo de trabajo indicado. Ello supondría un mayor o menor consumo de energía por parte de los nodos asociados a los sensores. Los cuatro modos de trabajo propuestos para la simulación son los siguientes, ordenados de mayor a menor consumo de energía:

Capítulo 3: Metodología
ETSII UPM 52
• Modo 1: el nodo realiza una medición cada segundo. Transcurridos 10 segundos, envía un promedio de las mediciones realizas durante ese periodo de tiempo. La radio se mantiene siempre encendida, y el Gateway es el encargado de procesar las medias horarias a partir de los datos que recibe del nodo asociado al sensor.
• Modo 2: el nodo realiza una medición cada segundo. Transcurrida una hora, envía un promedio de las mediciones realizadas durante ese periodo de tiempo. De cara a la simulación, este modo es muy similar al modo 1. Se diferencia en que el modo 2 envía menos datos al Gateway, al realizar un mayor preprocesamiento. Además, en este modo se mantiene la radio apagada durante la mayor parte del ciclo de trabajo, reduciéndose drásticamente el consumo energético. Únicamente se activa la radio en la parte del ciclo en la que el nodo debe comunicarse con el Gateway.
• Modo 3: el nodo realiza una medición cada segundo. Cada hora realiza un promedio de las mediciones correspondientes a dicha hora, y lo almacena en un vector en el que pueden acumularse un máximo de tres mediciones. Al tiempo, comprueba si el último dato sobrepasa el umbral a partir del cual el IC sería “regular” o peor. En el caso de no sobrepasarlo, el nodo espera a acumular tres mediciones horarias para enviarlas al Gateway. En caso contrario, envía los promedios horarios almacenados en el vector. Cada vez que el nodo envía datos al Gateway, el vector queda vacío.
• Modo 4: este modo prioriza mantener un mínimo consumo energético. Este modo es similar al modo 3, pero con la diferencia de que el vector tiene una capacidad máxima de cinco mediciones.
En todos los modos de trabajo, cuando el nodo se encuentra desocupado pasa de su estado activo al estado de bajo consumo.
Los nodos podrían trabajar siempre en el modo de trabajo 4, que garantiza un mínimo consumo energético. Sin embargo, en el caso de un episodio de contaminación, el Gateway únicamente recibiría rápidamente la alerta del contaminante que ha superado el umbral en una determinada estación, pero si el resto de los contaminantes no superan su umbral de riesgo para la salud, estos seguirían enviando sus mediciones cada cinco horas al Gateway. Ello supondría que este llevaría siempre un retraso considerable (hasta cuatro horas) en tener información del estado completo de la red y en transmitir las alertas a los gestores de la red. En estas condiciones, los gestores ambientales no podrían conocer la evolución en tiempo real de los contaminantes, lo que impediría que activasen las adecuadas medidas de actuación para garantizar la salud de la población. Esto situación es claramente indeseable, y por ello es necesario que los nodos de la red puedan variar su modo de trabajo. El modo 3 reduce esta limitación, ya que, en condiciones episódicas, el Gateway recibiría la información completa de la red en un periodo de tiempo máximo de dos horas. Por último, este problema es inexistente cuando la red opera en modo 2 ya que los nodos informan al Gateway cada hora.
Por tanto, debe existir un compromiso entre el modo de operación de la red, el consumo energético y la calidad del servicio de la red. La aproximación que se ha realizado en este trabajo es utilizar los modos 2 y 3 en situaciones episódicas, y el modo 4 el resto del tiempo. No se considera el modo 1 por su elevadísimo consumo energético (ver sección 4.1).
Al trabajar con datos ya validados por el Ayuntamiento de Madrid, esta simulación no contempla el proceso de validación que sería idéntico al descrito en la sección 3.4.1 para los monitores de medición de contaminantes en continuo de las Estaciones de Calidad del Aire de Madrid. Para facilitar la simulación, se ha optado por trabajar directamente con los promedios horarios de los valores de los diferentes contaminantes, en lugar de con los datos de las mediciones realizadas cada medio segundo. Se comprobó previamente que la gestión de la recogida de datos provenientes de los sensores y el cálculo de los promedios de las mediciones no suponen un

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 53
gasto de batería significativo, en comparación con el consumo energético que suponen las comunicaciones.
Los consumos reales de un determinado nodo cuando opera en cada uno de los modos considerados se presentan en la sección 4.1 de este trabajo. Dado que la simulación de la operación del nodo en modo 1 indicó que la batería se agotaba en seis días, se optó por descartar dicho modo de trabajo de cara al diseño e implementación del algoritmo de Resource Allocation y Computation Offloading.
3.6.2 Algoritmo que establece el nivel de operación de la red y el modo de trabajo de cada uno de los nodos.
El algoritmo diseñado contempla simultáneamente los parámetros relacionados con la calidad del aire (IC, hora, día de la semana y estación del año), y los parámetros relacionados con la batería de los nodos.
Así, en función de los parámetros relacionados con la batería, se han establecido dos niveles de operación de la red. Uno prima en mayor medida minimizar el consumo energético, mientras que el otro prioriza el cambio de nivel hacia otro en el que se envían datos al Gateway con mayor frecuencia.
Una vez seleccionado el nivel de operación de la red, se determina el modo de trabajo de cada uno de los nodos, en función de los parámetros relacionados con la calidad del aire. Cuando la calidad del aire no entraña riesgos para la salud, se prima reducir el consumo energético del nodo, haciendo que éste procese las mediciones de contaminación atmosférica, en lugar del Gateway, reduciendo su tiempo de transmisión de datos, al ser este parámetro el que determina el mayor consumo energético.
3.6.2.1 Asignación del nivel de operación de la red El criterio para asignar el nivel de operación de la red se presenta en el diagrama de la Figura 35. Cuando la capacidad restante de batería es superior al 50% de su capacidad máxima y no está teniendo un consumo desmesurado (superior a 4 mA), el nodo trabajará en el nivel de operación de mayor consumo energético.
Si la capacidad de batería restante es inferior al 50%, o se ha detectado un consumo desmesurado en las últimas mediciones (inferior o igual a 4 mA), se trabaja en el modo que prima el bajo consumo energético.
Mayor consumo energético
Menor consumo energético
¿C > 50% Cmax?SI NO
¿Pico de consumo en las últimas 8-14 horas?
SI
Figura 35: Criterios de cambio en el nivel de operación de la red

Capítulo 3: Metodología
ETSII UPM 54
3.6.2.2 Nivel de operación de la red asociado a un mayor consumo energético Al iniciarse la simulación de la red de sensores inalámbrica, los nodos comienzan en este nivel de operación y en el modo de trabajo 2. Los nodos permanecen en este modo de trabajo durante al menos las cinco primeras horas. Una vez que un nodo ha acumulado al menos cinco medidas horarias de mediciones de contaminantes, cambia su modo de trabajo dependiendo del número de horas en que el IC de la red es inferior o igual a 3 (“regular” o peor), o mayor o igual que 4 (“bueno” o “muy bueno”).
En la Figura 36 se presentan las condiciones que debe cumplir un nodo para pasar de un modo de trabajo a otro (bloques con fondo naranja de la figura. En caso de no cumplir ninguna condición, el nodo permanece en el modo de trabajo en el que se encontraba.
Si un nodo se encuentra en el modo 2 y los últimos cinco valores de IC de la red son “bueno” o “muy bueno”, el nodo puede cambiar al modo de trabajo 3 o al 4. El cambio a uno o a otro depende de las condiciones enumeradas en la Figura 36; el cumplimiento de una de las cuatro condiciones es suficiente para que se verifique el cambio hacia el modo 4 en lugar de hacia el modo 3.
Mayor consumo energético
Modo 2
2/10 mediciones con IC “regular” o peor
2/10 mediciones con IC “regular” o peor
5/5 mediciones con IC “bueno” o “muy bueno”
Modo 4 Modo 3
NO
SI
10/10 mediciones con IC “bueno” o “muy bueno”
¿Se cumple alguna de estas condiciones?
Sensor: O3invierno/otoño
Sensor: SO2
Sensor: NO2Hora: 2-12
verano/primavera
Sensor: NO2sábado/domingo
1/5 mediciones con IC “regular” o peor
SI
NO
Figura 36: Nivel de operación de la red con un mayor consumo energético
3.6.2.3 Nivel de operación de la red asociado a un menor consumo energético
El nivel de operación de la red con un menor consumo energético se activa cuando la capacidad de batería restante de un determinado nodo es inferior al 50% o cuando se ha producido un consumo desmesurado en las últimas horas de simulación y se estaba trabajando en el otro nivel de operación.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 55
El cambio de nivel de operación de la red, no implica un cambio automático en el modo de trabajo de los nodos. Por el contrario, estos permanecen en el modo de trabajo que tenían anteriormente, si bien en este nivel de operación las condiciones para que se verifiquen los cambios de modo de trabajo son los representados en la Figura 37.
Se puede observar en la Figura 37 que basta que la red registre cuatro de las seis últimas mediciones con IC “bueno” o “muy bueno” para pasar desde el modo 2 directamente al modo 4. Este cambio es mucho más rápido que en el otro modo del algoritmo en el que este cambio requería de al menos 10 horas con un IC “bueno” o “muy bueno” o 5 horas con dicho índice si se cumplía una de las condiciones no relacionadas con el IC.
Menor consumo energético
Modo 3 Modo 2
3/6 mediciones con IC “regular” o peor
4/6 mediciones con IC “regular” o peor
4/6 mediciones con IC “bueno” o “muy bueno”
Modo 4
4/6 mediciones con IC “bueno” o “muy bueno”
Figura 37: Nivel de operación de la red con un menor consumo energético
3.7 Programación de los nodos que contienen los sensores atmosféricos.
Como parte del sistema operativo Contiki-NG, se ha creado un código genérico escrito en C, que permite programar todos los nodos encargados de realizar mediciones de contaminantes atmosféricos (ver Anexo 1.3). Sin embargo, este código genérico debe particularizarse para cada nodo, dependiendo del contaminante que mida. Por ello, en el código correspondiente a cada nodo, debe especificarse qué contaminante mide y la Estación de Calidad del Aire a la que pertenece, tal y como se observa en la sección del código resaltada en amarillo de la Figura 38. Dicho código tiene la forma “i,X,Y” siendo X, el número de la Estación de Calidad del Aire (8 para la de las Escuelas Aguirre y 24 para la de la Casa de Campo) e Y, el contaminante atmosférico que mide el nodo en cuestión (NO2/SO2/PM10/PM25/O3). Además, debe descomentarse el “define” correspondiente al contaminante que mide el nodo (ver Figura 39). El “define” contiene el umbral máximo a partir del cual el nodo envía la media horaria del contaminante, independientemente del modo de trabajo en el que se encuentre trabajando. Se ha tomado como umbral para cada contaminante la concentración a partir de la cual se considera que el contaminante tiene un IC “regular” o peor.

Capítulo 3: Metodología
ETSII UPM 56
Figura 38: Sección del código de un nodo sensor donde se especifica su estación y el contaminante que mide
Figura 39: “Defines" en los que se establece el umbral de concentración a partir del cual el nodo envía las mediciones
almacenadas al Gateway, independientemente del modo de trabajo en el que se encuentre
El código del Anexo 1.3 contempla la ejecución de una función que se encarga del procesamiento de los mensajes que recibe el nodo. También se encarga de ejecutar dos procesos diferentes; el primero gestiona la fecha y la hora, mientras que el segundo administra el ciclo de trabajo del nodo, en el que se incluye la gestión de las mediciones de un contaminante, y el envío de las mediciones junto con datos relacionados con la batería al Gateway. La estructura del código puede verse en la Figura 40.
Código de un nodo de medición
Proceso de gestión de la fecha y hora
Proceso con el ciclo de trabajo
RX_CALLBACK
Figura 40: Estructura del código de un nodo sensor
3.7.1 Proceso encargado de la gestión de la fecha y hora del nodo
Es importante que la fecha y la hora de la simulación esté sincronizada en todos los nodos para que el Gateway pueda decidir el modo de operación de la red. Además, el nodo debe conocer la fecha y hora en la que se produce la simulación. Ello se debe a que cuando el nodo no tiene almacenados datos, debe solicitar al Gateway nuevos datos, especificando la fecha y la hora correspondiente al inicio de la nueva serie de datos. Estas situaciones se producen cuando el nodo se acaba de inicializar o cuando ha trasmitido al Gateway todos los datos que tenía previamente almacenados. Además, cada vez que transcurre una hora, el nodo comienza un nuevo ciclo de trabajo en el que necesita acceder a los datos de las medidas horarias

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 57
almacenadas en la cadena de caracteres, y enviar o no dichas mediciones al Gateway, dependiendo del modo de trabajo. La posición a la que debe acceder dentro de la cadena de caracteres es función de la fecha y hora.
Al inicializarse el nodo, establece conexión con el nodo coordinador de la red (Gateway), y este le envía la fecha y hora de inicio de la simulación. A partir de ese momento es el propio nodo quien debe encargarse de mantener actualizadas tanto la fecha como la hora mediante este proceso.
Una vez que el nodo ha recibido del Gateway la hora de inicio de la simulación, el proceso actualiza periódicamente la fecha y hora. Este proceso se fundamenta en un timer que se activa cada vez que transcurre una hora. Cada vez que se activa el timer, el nodo actualiza la hora, el día, el mes y el año según los pasos representados en la Figura 41. Este proceso cíclico, tiene en cuenta tanto el número de días que tiene cada uno de los meses, como los años que son bisiestos. Una vez que el proceso ha actualizado la fecha y hora, se queda a la espera de que se vuelva a activar el timer y proceder con ello a una nueva actualización de la fecha y hora.

Capítulo 3: Metodología
ETSII UPM 58
hora = hora + 1
¿Hora == 25?
día = día + 1
¿día == ultimo día en memoria del nodo?
Cambiar datos memoria
SI
día = día + 1
NO
¿Mes== 1/3/5/7/8/10/12?
¿día == 32?
¿mes == 2?
SI
NO
¿añobisiesto?
SI
¿día == 29?¿día == 30?
NO
SI
¿día == 31?
NO
SI
¿mes == 13?
año = año + 1
mes = 1
Cambiar datos memoria
mes = mes + 1
dia = 1
Cambiar datos memoria
SI SI SI SI
Timer 1 h
Figura 41: Proceso que gestiona la fecha y hora en los nodos equipados con sensores de contaminación atmosférica
3.7.2 Proceso que contiene el ciclo de trabajo del nodo
El proceso que contiene el ciclo de trabajo del nodo informa al Gateway de su existencia, junto con la estación de medida a la que pertenece y el contaminante que mide. Así mismo, procesa la hora de inicio de la simulación que recibe del Gateway, solicita nuevos datos de mediciones al Gateway cada vez que no cuenta con nuevos datos disponibles, y se encarga de enviar las mediciones horarias del contaminante que mide, y los tiempos con la CPU activa, en modo bajo consumo, con la radio transmitiendo y con la radio a la escucha. La frecuencia con la que se producen estos envíos viene marcada por el modo de trabajo en el que se encuentre el nodo.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 59
Este proceso se ha implementado por medio de una máquina de estados. Esta cuenta con 8 estados distintos; en cada estado debe realizar una serie de acciones específicas y para pasar de uno a otro deben darse una serie de condiciones, que pueden ser desde finalizar las acciones correspondientes al estado en el que se encuentra, a tener que recibir un cierto mensaje proveniente del Gateway. El funcionamiento de la máquina de estados se ha representado en la Figura 42.
Al inicializarse el nodo, comienza en el estado 0, en el que envía al Gateway un mensaje indicando la estación de medida a la que pertenece y el contaminante que mide. Con este mensaje, el Gateway registra la dirección del nodo junto con los datos que le ha enviado y le contesta con otro mensaje en el que le indica la fecha y hora de inicio de la simulación. Cuando el nodo lo recibe, pasa al estado 1 en el que realiza el procesamiento del mensaje, y fija la fecha y hora del nodo. Al terminar las tareas asignadas a este estado, el nodo pasa al estado 2.
En el estado 2, el nodo debe solicitar los datos correspondientes al bloque de ocho días en el que se encuentre la fecha de inicio de simulación. En la petición de datos, el nodo solicita al Gateway los datos correspondientes a un determinado día. Al recibirlos, el nodo pasa al estado 3, en el que los almacena en la posición adecuada de la cadena de caracteres. Una vez almacenados, el nodo regresa al estado 2. Este proceso comienza con la petición de datos del primer día del bloque de ocho días que corresponde, y se repite hasta que el nodo ha recibido los datos de los ocho días que componen el bloque. Ha de destacarse que las peticiones de datos correspondientes al primer y último día de un bloque incluyen los tiempos con la CPU activa, en modo de bajo consumo, con la radio transmitiendo y a la escucha para que el Gateway pueda descontar este tiempo del consumo de la batería, ya que, si se desplegase físicamente la red, estos envíos no tendrían lugar. Una vez que el nodo cuenta con los datos de ocho nuevos días, recibe del Gateway un mensaje que le hace pasar al estado 4.
Una vez que el nodo se ha inicializado y tiene datos de mediciones de un contaminante disponibles, el nodo trabajará siguiendo un ciclo de trabajo que comenzará en el estado 4, y continuará en los estados 5, 6 y 7. Cada vez que el proceso de gestión de la fecha y hora se active actualizándolas, forzará el cambio al estado 4 para que vuelva a producirse la secuencia.
En el estado 4 el nodo incorpora la medición correspondiente a dicha fecha y hora a un vector en el que como máximo se pueden almacenar cinco mediciones. Este almacenamiento se realiza para poder conservar varias medias horarias del contaminante que mide, para su posterior envío conjunto en una sola vez. Esto es imprescindible para los modos de trabajo 3 y 4. El que se almacenen una, dos, tres, cuatro o cinco medidas depende del modo de trabajo del nodo y de si las medias horarias superan un umbral. Si por las condiciones establecidas, el nodo debe enviar las mediciones, enciende la radio y pasa al estado 5. Si por el contrario no las cumple, el nodo debe pasar al estado 7 en el que esperará a que se produzca un cambio de hora.
Si ha pasado al estado 5, el nodo envía las mediciones al Gateway y éste le confirma su recepción al recibirlas. Entonces, el nodo le envía los tiempos que ha permanecido con la CPU activa, en modo bajo consumo, con la radio transmitiendo y con la radio a la escucha. Cuando el Gateway los recibe, le confirma la recepción del mensaje y además, le asigna el modo de trabajo en el que debe operar. Posteriormente, el nodo apaga la radio y pasa al estado 7 quedando a la espera de que se produzca un cambio de hora.

Capítulo 3: Metodología
ETSII UPM 60
ESTADO 0
ESTADO 1
SI
Calculo la fecha
ESTADO 2ESTADO 3
¿Recibe “m,ok”de Gateway?
SI
“c,año,mes,dia”
DatoSensor
Al cambiarde hora
¿Se han acabado losdatos almacenados?
Pedir más datos
EstadosMensaje a Gateway
CondiciónAcciónRadio
¿Recibe“d,ok” deGateway?
ESTADO 7
¿Recibe“f,año,mes,dia,hora”
de Gateway? NO
“i,8,S02”
¿Recibedatos día solicitado
de Gateway?
SI
Almacena datos recibidos
NO
ESTADO 6
DatoBatería
¿Recibe“b,X*” deGateway?
NOSIAPAGO RADIO
ESTADO 4
SI
Al acabar cambio datos
“c,fin,CPU,LPM,TX,RX”
Envío mediciones almacenadas
+Dato
Sensor
ENCIENDORADIO
ESTADO 5
Almaceno enmedidas_m3_m4
SI
NO
¿Medida mayor queMAX_CONTAM?
¿N** MEDIDAS ALMACENADAS?
o
X* es el modo que asigna el Gateway al nodoN**=1 (modo 2) / 3 (modo 3) / 5 (modo 4)
Figura 42: Ciclo de trabajo de los nodos equipados con sensores de contaminación atmosférica
3.7.3 Recepción de mensajes por el nodo
En este apartado se describe lo que ocurre cuando el nodo recibe un mensaje de otro nodo de la red inalámbrica de sensores o de un nodo de la red externa, como puede ser el Gateway en el caso de las simulaciones de este trabajo.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 61
Al recibir un mensaje, este se almacena en la cadena de caracteres “str_recv” y se ejecuta automáticamente la función “udp_rx_callback”. Esta función se encarga de procesar el mensaje recibido y, dependiendo de su contenido, ejecuta unas acciones u otras. El funcionamiento de esta función se ha descrito en la Figura 43. En naranja se representan las condiciones, en rojo el apagado de la radio, y en los rectángulos azules el cambio de estado.
Como se puede observar, la primera acción es analizar el tipo de mensaje recibido, a partir de del primer carácter del mensaje. Una vez determinado el tipo de mensaje, se comprueba si es coherente haber recibido ese mensaje en el estado en el que se encuentra el nodo. En el caso de ser coherente, se procede a realizar las acciones que prosiguen a ambas condiciones; en caso contrario, no realiza ninguna acción.
¿str_recv[0]==f?
str_recv
¿str_recv[0]==c?
¿str_recv[0]==b?
¿str_recv[0]==m?
¿str_recv[0]==d?
NO
NO
NO
NO
¿Estado==0?
¿Estado==2?
¿Estado==2?
¿Estado==5?
¿Estado==6?
SI
SI
SI
SI
SI
Estado = 1
Estado = 3
Estado = 4
Estado = 6
RADIOOFF
SI
RADIOOFF
SI
SI
SI
SI
Estado = 7
Actualiza el modo de trabajo del nodo
Figura 43: Gestión de los mensajes que reciben los nodos equipados con sensores de contaminación atmosférica

Capítulo 3: Metodología
ETSII UPM 62
3.8 Programación del nodo Gateway.
El código Python que determina el comportamiento del Gateway se presenta en Anexo 1.4. Este código se ejecuta desde un terminal Docker en el ordenador en el que tiene lugar la simulación de la red inalámbrica de sensores.
Cada vez que se inicia Docker, ha de instalarse la librería Python denominada pandas. El código correspondiente al Gateway hace uso de esta librería para gestionar los datos que recibe provenientes de los nodos equipados con sensores. También la emplea para el almacenamiento de la capacidad de la batería que tiene cada nodo en una fecha y hora determinadas, y para almacenar el histórico del IC de la red. Para la instalación de la librería pandas se debe introducir el comando “sudo pip install pandas” en un terminal de Docker. Una vez instalada, si ya se ha ejecutado la herramienta tunslip, es el momento de ejecutar el código del Anexo 1.4.
El código Python del coordinador de la red (Gateway) emplea multithreading; es decir, puede haber varios threads ejecutándose en paralelo. Ello es fundamental para un adecuado funcionamiento de la red. Si no se emplease multithreading, el Gateway quedaría bloqueado a la espera de recibir un mensaje; y una vez lo recibiese, tendría que terminar el procesamiento del mensaje para poder volver a recibir otro mensaje. En cambio, con multithreading puede haber un thread encargado de la recepción de mensajes y otro encargado de procesarlos.
El código del Gateway desarrollado en el presente trabajo está compuesto por un código de inicialización y dos threads, uno para la recepción de mensajes, y el otro para el procesamiento de los mensajes recibidos y para el envío de mensajes a los nodos si la situación lo requiere (Figura 44).
Código del Gateway
ThreadComunicación
ThreadProcesamiento
Código de inicialización
Figura 44: Estructura del código Python del Gateway
3.8.1 Inicialización del nodo Gateway de la red.
El Gateway debe inicializarse siguiendo unos pasos concretos antes de empezar a comunicarse con los nodos de la red inalámbrica de sensores. El flujo de trabajo contiene las siguientes tareas:
1. Fijar la fecha y hora de inicio de la simulación. Esta fecha y hora determina los datos reales de contaminación atmosférica que usan los nodos como medidas simuladas. El año, mes, día y hora se fijan mediante las variables “inic_ano”, “inic_mes”, “inic_dia” y “inic_hora” respectivamente. Todos los nodos de la red inalámbrica de sensores se sincronizan con esta fecha y hora, una vez han notificado al Gateway la estación de medida a la que pertenecen y el contaminante atmosférico que miden.
2. Cargar los datos de las mediciones horarias de contaminación atmosférica. Como se mencionó anteriormente, una vez que se descargaron los datos de la web del

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 63
Ayuntamiento de Madrid, fueron preprocesados y almacenados en nueve ficheros de extensión “csv”, cada uno con las mediciones de un año. Estos ficheros han de importarse formando un único dataframe que contenga todos los datos. En este trabajo, el dataframe ha sido denominado “aire” y de él es de donde se extraen los datos de mediciones de contaminación atmosférica para ser enviadas a los nodos si estos lo demandan.
3. Iniciar un “socket” de tipo UDP que permita la comunicación entre el Gateway y los nodos equipados con sensores.
4. Iniciar los dos threads: el de comunicación y el de procesamiento.
3.8.2 Thread de Comunicación
El thread de comunicación es el encargado de la recepción de mensajes provenientes de los nodos de la red inalámbrica de sensores. Su funcionamiento se ha representado en la Figura 45. En los bloques naranjas se encuentran condiciones; en los azules, acciones que debe ejecutar el Gateway; y en los verdes, el mensaje que recibe el Gateway que siempre viene acompañado de la dirección y puerto de los que proviene.

Capítulo 3: Metodología
ETSII UPM 64
¿Mensaje nuevo?
NO
mensaje
direccion
puerto
SI
¿Mensajealmacenado
en lista?
¿Mensaje en uso enThread procesamiento?
NO
SI
SI
msg.insert (0, mensaje)
addr.insert (0, direccion)
port.insert (0, puerto)
NO
Figura 45: Thread de comunicación del nodo coordinador de la red o Gateway
El thread de comunicación se encuentra bloqueado por defecto, a la espera de recibir un mensaje. Al recibir un mensaje, la función encargada de captarlo devuelve su contenido, junto con una lista que contiene la dirección y puerto del que proviene.
El siguiente paso es comprobar si el mensaje recibido ya se encuentra en la lista de mensajes pendientes de ser procesados, o es idéntico al que está siendo procesado. Para realizar esta comparación, se debe tener en cuenta el contenido del mensaje y la dirección de la que proviene. En caso de que el mensaje sea igual a uno ya almacenado, se desecha el mensaje y el thread vuelve a quedar bloqueado a la escucha. En cambio, si el mensaje recibido es distinto, se procede a añadirlo a lista de mensajes pendientes.
Para almacenar un nuevo mensaje se emplean tres listas distintas. Una para el contenido del mensaje, otra para la dirección de la que proviene, y una última para el puerto del que proviene.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 65
En la Figura 46 se ha representado cómo evolucionan simultáneamente las tres listas ante la recepción de un mensaje por el Gateway. Al llegar un nuevo mensaje (no repetido), se inserta al inicio de la lista de mensajes, de direcciones y de puerto, el contenido del mensaje, la dirección de la que proviene, y el puerto del que proviene respectivamente. Cuando esto ocurre, el resto de elementos de la lista son desplazados una posición hacia la derecha. El elemento i-ésimo de cada una de las tres listas corresponde al mismo mensaje. Posteriormente, el thread de procesamiento extraerá el mensaje que lleva más tiempo almacenado que estará formado por el último elemento de cada una de las listas.
Recepción de un mensaje nuevo, será el mensaje 4.
Mensaje 3 Mensaje 2Mensaje 4
Dirección 3 Dirección 2Dirección 4
Puerto 3 Puerto 2Puerto 4
Lista de mensajes
0 1 2
Lista de direcciones
Lista de puertos
Posición
Mensaje 3 Mensaje 2Mensaje 4
Dirección 3 Dirección 2Dirección 4
Puerto 3 Puerto 2Puerto 4
Lista de mensajes
0 1 2
Lista de direcciones
Lista de puertos
Posición
Mensaje 1
Dirección 1
Puerto 1
3
El thread de procesamiento extrae el mensaje más antiguo para procesarlo.
Mensaje 2 Mensaje 1Mensaje 3
Dirección 2 Dirección 1Dirección 3
Puerto 2 Puerto 1Puerto 3
Lista de mensajes
0 1 2
Lista de direcciones
Lista de puertos
Posición
Figura 46: Gestión de las listas que almacenan los mensajes recibidos por el nodo coordinador de la red o Gateway
3.8.3 Thread de Procesamiento
En este trabajo, se ha diseñado al Gateway con una concepción completamente distinta a la de los nodos equipados con sensores. Los nodos tienen una máquina de estados que determina su ciclo de trabajo. En cambio, el Gateway se ha sido diseñado de tal manera que no tiene un ciclo de trabajo como tal; este se dedica únicamente a atender los mensajes que recibe, procesarlos,

Capítulo 3: Metodología
ETSII UPM 66
almacenar en dataframes ciertos datos y, en el caso de que sea necesario, contesta al mensaje recibido.
Al inicializarse el Gateway crea dos listas vacías denominadas en el código “nodos_dic” y “nodos_df”. Cada vez que un nodo no registrado envía un mensaje al Gateway, este añade un dataframe a la lista “nodos_df”, y un diccionario a la lista “nodos_dic”. De esta forma, cada nodo tiene su propio diccionario en el que almacenar parámetros suyos necesarios para la simulación, y su propio dataframe en el que almacenar datos que interese tener clasificados por fecha y horas. Por ejemplo, este es el caso de las mediciones de calidad del aire que recibe de los nodos, el modo de trabajo en el que se encuentra cada uno de los nodos, o la capacidad de batería que tiene cada nodo en cada fecha y hora.
El funcionamiento del thread de procesamiento se ha representado simplificadamente en la Figura 47. El bloque superior hace referencia a la extracción de un mensaje, junto con la dirección y puerto de los que proviene, de las listas en los que los había almacenado el otro thread al recibirlos.
En naranja se representan las condiciones, en azul las acciones que debe realizar el nodo, y en verde los posibles mensajes que podría recibir el Gateway para cumplir cada una de las condiciones.
La primera comprobación que realiza con cada mensaje recibido es consultar si el nodo se encuentra ya registrado. En el caso de no estar registrado, lo registra para posteriormente pasar a comprobar si el mensaje cumple cualquiera de las otras condiciones. Si ya estaba registrado, el nodo pasa directamente a comprobar si cumple cualquiera de las condiciones.
Como se observa, las condiciones se basan en analizar cuál es el primer carácter del mensaje recibido y actuar en función de él.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 67
Message=msg.pop ()
Address=addr.pop()
Port_send=port.pop()
¿Nodo registrado? Registra el nodoNO
¿Message[0] == ‘i’?
SI
¿Message[0] == ‘c’?
NO
¿Message[0] == ‘d’?
¿Message[0] == ‘b’?
NO
NO
i,8,SO2
c,fin,CPU,LPM,TX,RX
c,ini,CPU,LPM,TX,RX,año,mes,diac,año,mes,dia
d,medicion,
b,año,mes,dia,hora,CPU,LPM,TX,RX
d,medicion,medicion,medicion,…,
Actualizo capacidad restante de batería
SI Determinación próximo modo de trabajo según algoritmo
Envía al nodo:“f,año,mes,dia,hora”
SI
Envía al nodo los datos de las mediciones horarias del año, mes, día solicitado
SI
Almacenamiento de la medición o mediciones horarias
Calcula el IC de la medición o mediciones
Envía al nodo:“d,ok”
SI
Envía al nodo:“d,prox_modo”
Figura 47: Thread de procesamiento
El Gateway diseñado e implementado en este trabajo presenta una gran versatilidad y capacidad de adaptación. Opera ajustándose a las especificaciones introducidas en el código, independientemente del número de nodos con los que se tiene que comunicar y sin tener que especificar el número de nodos. Es decir, el código Python asociado al Gateway permanecerá invariable, independientemente de que se simule en Cooja un único nodo equipado con sensores o cinco de estos nodos.
Además, cada vez que el Gateway termina con el procesamiento de un mensaje, exporta en formato “csv” cada uno de los dataframes con los que cuenta, es decir, genera un fichero “csv” por cada nodo con el que se ha comunicado y otro con el histórico del IC de la red. Ello permitirá analizar los resultados obtenidos y graficar el histórico de ciertos parámetros a lo largo de la simulación.

Capítulo 3: Metodología
ETSII UPM 68
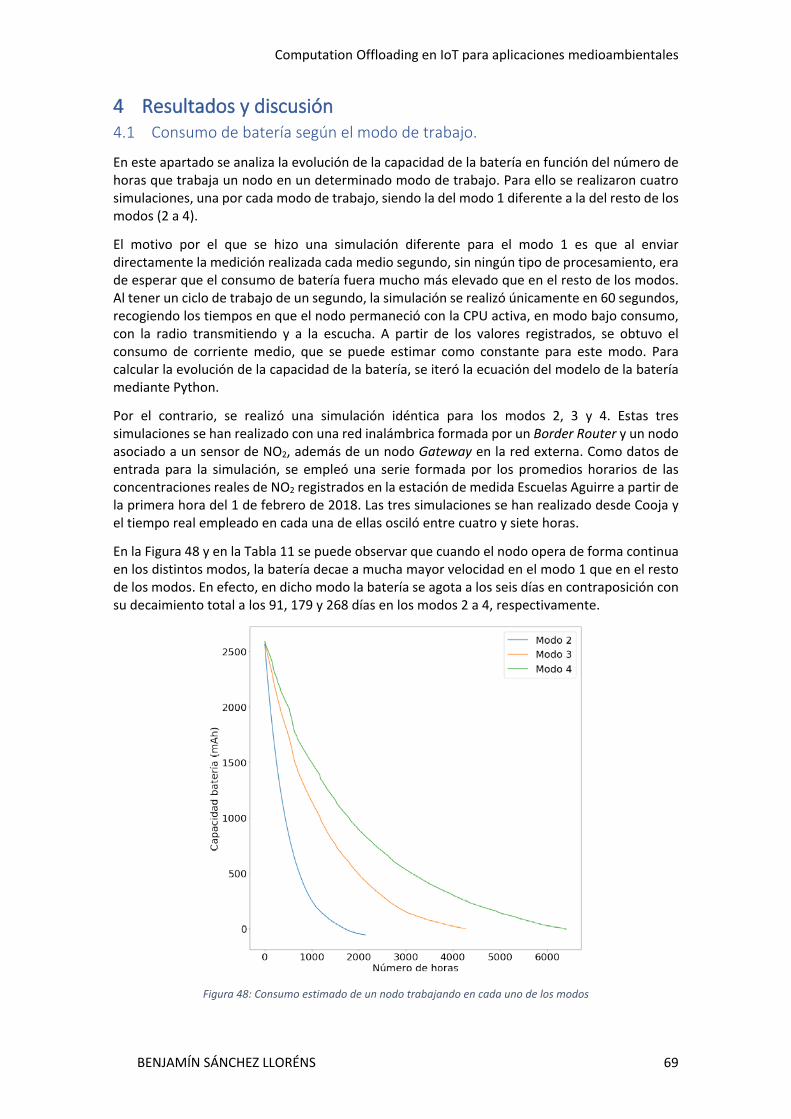
Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 69
4 Resultados y discusión 4.1 Consumo de batería según el modo de trabajo.
En este apartado se analiza la evolución de la capacidad de la batería en función del número de horas que trabaja un nodo en un determinado modo de trabajo. Para ello se realizaron cuatro simulaciones, una por cada modo de trabajo, siendo la del modo 1 diferente a la del resto de los modos (2 a 4).
El motivo por el que se hizo una simulación diferente para el modo 1 es que al enviar directamente la medición realizada cada medio segundo, sin ningún tipo de procesamiento, era de esperar que el consumo de batería fuera mucho más elevado que en el resto de los modos. Al tener un ciclo de trabajo de un segundo, la simulación se realizó únicamente en 60 segundos, recogiendo los tiempos en que el nodo permaneció con la CPU activa, en modo bajo consumo, con la radio transmitiendo y a la escucha. A partir de los valores registrados, se obtuvo el consumo de corriente medio, que se puede estimar como constante para este modo. Para calcular la evolución de la capacidad de la batería, se iteró la ecuación del modelo de la batería mediante Python.
Por el contrario, se realizó una simulación idéntica para los modos 2, 3 y 4. Estas tres simulaciones se han realizado con una red inalámbrica formada por un Border Router y un nodo asociado a un sensor de NO2, además de un nodo Gateway en la red externa. Como datos de entrada para la simulación, se empleó una serie formada por los promedios horarios de las concentraciones reales de NO2 registrados en la estación de medida Escuelas Aguirre a partir de la primera hora del 1 de febrero de 2018. Las tres simulaciones se han realizado desde Cooja y el tiempo real empleado en cada una de ellas osciló entre cuatro y siete horas.
En la Figura 48 y en la Tabla 11 se puede observar que cuando el nodo opera de forma continua en los distintos modos, la batería decae a mucha mayor velocidad en el modo 1 que en el resto de los modos. En efecto, en dicho modo la batería se agota a los seis días en contraposición con su decaimiento total a los 91, 179 y 268 días en los modos 2 a 4, respectivamente.
Figura 48: Consumo estimado de un nodo trabajando en cada uno de los modos

Capítulo 4: Resultados y discusión
ETSII UPM 70
Tabla 11: Duración de la batería en días para cada modo de operación del nodo
Modo de operación del nodo
Caída capacidad de la batería 50% 78% 100%
Modo1 2 5 6 Modo 2 14 29 91 Modo 3 35 77 179 Modo 4 54 120 268
4.2 Ventajas de la aplicación del efecto del algoritmo basado en “resource allocation” y “computation offloading”.
Para comprobar las ventajas del algoritmo diseñado e implementado basado en “Resource Allocation” y “Computation Offloading” se van a realizar una serie de simulaciones. Todas las simulaciones han comenzado empleando una serie de registros de promedios horarios de las concentraciones los cinco contaminantes atmosféricos considerados, correspondientes a la estación de las Escuelas Aguirre. La serie comenzaba a partir de la primera hora del 1 de febrero de 2018. Se ha escogido exactamente la misma fecha que se empleó en la simulación del apartado 4.1 para garantizar la comparabilidad de los resultados.
4.2.1 Simulación para comprobar la optimización del consumo de batería de la Red Inalámbrica de Sensores aplicando el algoritmo basado en “Resource Allocation” y “Computation offloading”.
En la primera simulación se han dispuesto 11 nodos, tal y como muestra la Figura 49. A continuación, se indica la correspondencia entre la numeración del nodo que aparece dicha figura y las características del nodo:
• Nodo 1: nodo Border Router. • Nodos 2-6: nodos de enlace entre el border router y los nodos equipados con sensores. • Nodo 7: nodo equipado con un sensor de NO2 • Nodo 8: nodo equipado con un sensor de SO2 • Nodo 9: nodo equipado con un sensor de O3 • Nodo 10: nodo equipado con un sensor de PM10 • Nodo 11: nodo equipado con un sensor de PM2,5

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 71
Figura 49: Disposición de nodos para la simulación de la red diseñada
El Border Router se ha situado en el centro de la red y en torno a él se han ubicado 5 nodos que actúan como enlace entre el Border Router y los nodos equipados con sensores. Más alejados del Border Router se encuentran los cinco nodos con sus correspondientes sensores.
En la Figura 50 se muestra la necesidad de utilizar nodos que actúen como enlace entre el Border Router y los nodos equipados con sensores. El área verde indica el área de alcance de los nodos 11 y 5 respectivamente. Tal y como se puede observar en la parte izquierda de la figura, el nodo 11 (sensor de PM2,5) está fuera del alcance del nodo 1. Para que el nodo 11 pueda enviar información al nodo 1 (parte derecha de la Figura), debe establecerse un enrutamiento que establezca que el mensaje deba pasar primero por el nodo 5 antes de llegar a su destino. Se han incluido nodos de enlace en la simulación para verificar la capacidad multisalto propia de las redes inalámbricas de sensores.
Figura 50: Cobertura del nodo 11 (parte izquierda) y del nodo de enlace 5 (parte derecha)
El tiempo de simulación empleado fue de 40 horas, si bien la estabilidad del simulador decaía al cabo de siete horas aproximadamente. Gracias a la robustez del código implementado, fue posible lanzar de nuevo la simulación cada vez que el simulador se ralentizaba en exceso. La disposición de los nodos era idéntica a la inicial, y además cada nodo comenzó la continuación de la simulación con la capacidad de batería con la que había finalizado la simulación inmediatamente anterior. Ello fue posible gracias a que los nodos exportaban periódicamente

Capítulo 4: Resultados y discusión
ETSII UPM 72
el dataframe que contiene sus mediciones y parámetros relacionados con la batería y los modos de trabajo (ver Figura 51).
Figura 51: Extracto del fichero .csv generado por uno de los nodos
Los resultados de la simulación muestran el distinto comportamiento de los distintos nodos asociados a los contaminantes (Figura 52 y Tabla 12). Se aprecia que la batería de los nodos de NO2, PM10 y PM2.5 decae al 50% de su capacidad entre 40 y 46 días, mientras que este declive se produce entre 5 y 11 días más tarde que en los en el SO2 y O3. En efecto, el tiempo de caída de la batería al 50% de su capacidad es muy similar en el caso del SO2 y el O3 (51 días) al tiempo en que la batería decaería a ese nivel si la red estuviera funcionando continuamente en el modo 4 (54 días, ver Tabla 11).
Figura 52: Decaimiento de la batería los nodos de los cinco contaminantes atmosféricos considerados

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 73
Tabla 12: Comparación del tiempo (días) de caída de la batería (50% y 78%) de los nodos de los diferentes contaminantes.
Contaminante Caída batería 50% 78%
NO2 40 100 PM2.5 43 106 PM10 46 108 O3 51 116 SO2 51 112
Ello se debe a que al ser las concentraciones del primer trío más elevadas que las de los otros dos contaminantes (ver sección 3.3.6.5), inducen con mayor frecuencia situaciones episódicas de contaminación, que determinan que sus nodos asociados trabajen un mayor número de horas en los modos 2 y 3 que los otros nodos (Tabla 13), tal y como determinan las condiciones del algoritmo implementado en la simulación. Por ello, su frecuencia de transmisión de datos en dichos modos es mayor, y ello conlleva también un mayor consumo de batería.
Tabla 13: Frecuencia (nº de horas) en que los nodos de los cinco contaminantes trabajaron en los modos de operación 2, 3 y 4
Contaminante Modo 2 Modo 3 Modo 4 NO2 98 212 2.461
PM2.5 91 237 2.443 PM10 84 237 2.452
O3 69 108 2.594 SO2 67 117 2.589
Al comparar las Figura 53 y 54, se puede apreciar cómo cuando cambia el modo de operación del nodo asociado al SO2 apenas cambia desde el modo 4 (menor transmisión de datos y consumo de batería) a los modos 2 y 3 (mayor transmisión de datos y consumo de batería). En la Figura 54 se observa que el nodo del NO2 cambia con mayor frecuencia que el de SO a los modos 2 y 3 y permanece más tiempo en ellos. Como se ha comentado, esto determina el diferente comportamiento en el consumo de batería de los diferentes contaminantes.
Figura 53: Visualización de cambios entre modos de operación del nodo de SO2 (parte superior) y detalle de tiempo
de permanencia en cada modo. Datos de la simulación completa.
Figura 54: Visualización de cambios entre modos de operación del nodo de NO2 (parte superior) y detalle de tiempo de permanencia en cada modo. Datos de la simulación completa.
Desde el punto de vista de ahorro del consumo energético de la batería, el algoritmo implementado permitió mantener los niveles de batería cercanos a los del modo 4 (mínimo consumo) sin que resintiera la calidad del servicio de la red (ver Figura 55).

Capítulo 4: Resultados y discusión
ETSII UPM 74
Figura 55: Comparación del decaimiento de la capacidad de la batería entre los tres modos de operación de los
nodos y el algoritmo diseñado para optimizar la gestión de la red.
En efecto, cuando los niveles de contaminación alcanzaron niveles de riesgo para la salud, los nodos pasaron a modos de operación asociados permitieron transmitir los datos con mucha mayor frecuencia. Ello facilitaría que las autoridades sanitarias alertasen a la población de dichos riesgos, y activasen los protocolos de actuación oportunos.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 75
5 Conclusiones y líneas futuras 5.1 Conclusiones
A partir de los resultados obtenidos en el presente trabajo, se destacan las siguientes conclusiones:
• Se ha diseñado y simulado una red inalámbrica de sensores formada por nodos equipados con sensores de contaminantes atmosféricos (simulada en Cooja), asociados a un Gateway (simulado en el ordenador).
• La red diseñada presentó la heterogeneidad suficiente como para poder implementar diferentes estrategias para optimizar su gestión, atendiendo a los siguientes criterios: calidad del servicio, consumo de batería de los nodos, y dinámica de los contaminantes atmosféricos (superación de umbrales, y variaciones diarias, semanales y estacionales de los contaminantes).
• La consideración de la evolución de los promedios horarios de las concentraciones de los contaminantes atmosféricos registrados en la ciudad de Madrid ente los años 2011 y 2019 permitió definir estrategias de gestión de la red basadas en la calidad de servicio e independientes de aquellas basadas en sus parámetros internos.
• Se ha diseñado e implementado un algoritmo que contempla las estrategias mencionadas en el punto anterior, aplicando los fundamentos de Resource allocation y Computation offloading.
• El código que determina el comportamiento de los nodos y el Gateway que incluye el algoritmo anterior, mostró una gran robustez al permitir realizar simulaciones complejas y duraciones superiores a siete horas.
• El algoritmo diseñado permitió que los niveles de consumo de la red permanecieran cercanos a los del modo de trabajo de menor consumo energético, sin comprometer la calidad del servicio.
• El entorno de simulación creado tiene un gran potencial ya que permite comparar diferentes algoritmos diseñados para optimizar la gestión de otras redes, incluso pertenecientes a ámbitos distintos al de la contaminación ambiental.
5.2 Líneas futuras
• Para validar el entorno de simulación creado y el algoritmo de optimización de la red se deberían contrastar los resultados obtenidos mediante simulación con un caso real idéntico al diseñado para la simulación.
• Contraste del potencial del entorno de simulación creado utilizando diseños de redes más complejas que incluyesen más o nodos en la red o que contemplasen la interacción con otras redes u otras fuentes de datos.
• Inclusión de algoritmos de optimización basados en aprendizaje automático o heurísticos para la toma de desiciones considerando la distribución temporal de las tareas de procesamiento.

Capítulo 5: Conclusiones y líneas futuras
ETSII UPM 76

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 77
6 Bibliografía
[1] A. Elnashar, “IoT evolution towards a super-connected world”, arXiv preprint arXiv:1907.02589, 2019.
[2] J. Portilla, G. Mujica, J. Lee and T. Riesgo, "The Extreme Edge at the Bottom of the Internet of Things: A Review,"
IEEE Sensors Journal, vol. 19, pp. 3179-3190, 2019.
[3] I.F. Akyildiz, “Wireless sensor networks”, Chichester, West Sussex, U.K.; Hoboken, NJ: Chichester, West Sussex,
U.K; Hoboken, NJ : Wiley, 2010.
[4] F. Samie, V. Tsoutsouras, L. Bauer, S. Xydis, D. Soudris and J. Henkel, "Computation offloading and resource allocation for low-power IoT edge devices", In 2016 IEEE 3rd World Forum on Internet of Things (WF-IoT). IEEE, 2016. p. 7-12.
[5] C. Jiang, X. Cheng, H. Gao, X. Zhou and J. Wan, "Toward Computation Offloading in Edge Computing: A Survey,"
IEEE Access, vol. 7, pp. 131543-131558, 2019.
[6] Liqing Liu, Zheng Chang, Xijuan Guo, Shiwen Mao and Tapani Ristaniemi, "Multiobjective Optimization for
Computation Offloading in Fog Computing," IEEE, vol. 5, Feb. 2018.
[7] P. Mach and Z. Becvar, "Mobile Edge Computing: A Survey on Architecture and Computation Offloading," IEEE
Communications Surveys & Tutorials, vol. 19, pp. 1628-1656, 2017.
[8] M. Silva, D. Cerdeira, S. Pinto and T. Gomes, "Operating Systems for Internet of Things Low-End Devices: Analysis
and Benchmarking", IEEE Internet of Things Journal, vol. 6, pp. 10375-10383, 2019.
[9] A. Dunkels, B. Gronvall and T. Voigt, "Contiki - a lightweight and flexible operating system for tiny networked sensors", in 29th annual IEEE international conference on local computer networks, pp. 455-462, 2004.
[10] M. Chiang and T. Zhang, "Fog and IoT: An Overview of Research Opportunities", IEEE Internet of Things Journal,
vol. 3, pp. 854-864, 2016.
[11] W. Shi, J. Cao, Q. Zhang, Y. Li and L. Xu, "Edge Computing: Vision and Challenges", IEEE Internet of Things Journal,
vol. 3, pp. 637-646, 2016.
[12] JM Chabas, Chandra Gnanasambandam, Sanchi Gupte and Mitra Mahdavian, "New demand, new markets: What
edge computing means for hardware companies", McKinsey Insights, Nov 8,. 2018.
[13] H. Hsieh, J. Chen and A. Benslimane", 5G Virtualized Multi-access Edge Computing Platform for IoT Applications,"
Journal of Network and Computer Applications, vol. 115, pp. 94-102, 2018.
[14] W.S. Ravindra and P. Devi", Energy balancing between computation and communication in IoT edge devices using
data offloading schemes", pp. 22-25, 2018.
[15] K. Lin, S. Pankaj and D. Wang, "Task offloading and resource allocation for edge-of-things computing on smart
healthcare systems", Comput.Electr.Eng., vol. 72, pp. 348-360, 2018.
[16] B.P. Rimal, D.P. Van and M. Maier, "Mobile Edge Computing Empowered Fiber-Wireless Access Networks in the
5G Era", IEEE Communications Magazine, vol. 55, pp. 192-200, 2017.
[17] Docker, "https://docs.docker.com/get-started/".
[18] Datasheet SkyMote, "https://insense.cs.st-andrews.ac.uk/files/2013/04/tmote-sky-datasheet.pdf".
[19] Instalación Contiki-NG, "https://github.com/contiki-ng/contiki-ng/wiki/Docker".
[20] Repositorio GitHub Contiki-NG, "https://github.com/contiki-ng/contiki-ng".
[21] Contiki-NG, "https://github.com/contiki-ng/contiki-ng" .
[22] A. Kurniawan, Practical Contiki-NG Programming for Wireless Sensor Networks, Berkeley, CA : Apress : Imprint:
Apress, 2018.

Capítulo 6: Bibliografía
ETSII UPM 78
[23] World Health Organization, "Ambient (outdoor) air quality and health. Fact sheet No 313, Updated March 2014"
2014.
[24] C. Guerreiro, A. González Ortiz and F.d. Leeuw, Air quality in Europe : 2017 report, Luxembourg: Luxembourg :
Publications Office, 2017.
[25] Ayuntamiento de Madrid, "Memoria Calidad del Aire Madrid 2016".
[26] I. Laña, J. Del Ser, A. Padró, M. Vélez and C. Casanova-Mateo, "The role of local urban traffic and meteorological
conditions in air pollution: A data-based case study in Madrid, Spain", Atmospheric Environment, vol. 145, pp.
424-438, 2016.
[27] E. Rivas, J.L. Santiago, Y. Lechón, F. Martín, A. Ariño, J.J. Pons and J.M. Santamaría, "CFD modelling of air quality
in Pamplona City (Spain): Assessment, stations spatial representativeness and health impacts valuation," Sci.Total
Environ., vol. 649, pp. 1362-1380, 2019.
[28] D. Núñez-Alonso, L.V. Pérez-Arribas, S. Manzoor and J.O. Cáceres, "Statistical Tools for Air Pollution Assessment:
Multivariate and Spatial Analysis Studies in the Madrid Region", Journal of Analytical Methods in Chemistry, vol.
2019, 2019.
[29] P. Salvador, B. Artíñano, M.M. Viana, A. Alastuey and X. Querol, "Multicriteria approach to interpret the variability
of the levels of particulate matter and gaseous pollutants in the Madrid metropolitan area, during the 1999–2012
period", Atmospheric Environment, vol. 109, pp. 205-216, 2015.
[30] R. Borge, B. Artíñano, C. Yagüe, F. Gomez-Moreno, A. Saiz-Lopez, M. Sastre, A. Narros, D. García-Nieto, N.
Benavent, G. Maqueda, M. Barreiro, J.M. de Andrés and Á Cristóbal, "Application of a short term air quality action
plan in Madrid (Spain) under a high-pollution episode - Part I: Diagnostic and analysis from observations", Sci.Total
Environ., vol. 635, pp. 1561-1573, 2018.
[31] Ayuntamiento de Madrid. Calidad del Aire,
"https://datos.madrid.es/portal/site/egob/menuitem.c05c1f754a33a9fbe4b2e4b284f1a5a0/?vgnextoid=9e42c
176313eb410VgnVCM1000000b205a0aRCRD&vgnextchannel=374512b9ace9f310VgnVCM100000171f5a0aRCR
D&vgnextfmt=default" .
[32] Anonymous
"http://www.mambiente.munimadrid.es/opencms/export/sites/default/calaire/Anexos/Memoria_2019.pdf" .
[33] Ayuntamiento de Madrid. Sistema de Vigilancia Calidad del Aire,
"http://www.mambiente.munimadrid.es/opencms/calaire/SistemaIntegral/SistVigilancia/" .
[34] Ayuntamiento de Madrid. Datos horarios de Calidad del Aire,
"https://datos.madrid.es/portal/site/egob/menuitem.c05c1f754a33a9fbe4b2e4b284f1a5a0/?vgnextoid=f3c0f7
d512273410VgnVCM2000000c205a0aRCRD&vgnextchannel=374512b9ace9f310VgnVCM100000171f5a0aRCRD
&vgnextfmt=default" .
[35] Ayuntamiento de Madrid. Umbrales por contaminante,
"http://www.mambiente.munimadrid.es/opencms/export/sites/default/calaire/Anexos/valores_limite_1.pdf" .
[36] C. Borrego, A.M. Costa, J. Ginja, M. Amorim, M. Coutinho, K. Karatzas, T. Sioumis, N. Katsifarakis, K. Konstantinidis, S. De Vito, E. Esposito, P. Smith, N. Andre, P. Gerard, L.A. Francis, N. Castell Balaguer, P. Schneider, M. Viana, M.C. Minguillon, W. Reimringer, R.P. Otjes, O. Von Sicard, R. Pohle, B. Elen, D. Suriano, V. Pfister, M. Prato, S. Dipinto and M. Penza, "Assessment of air quality microsensors versus reference methods: The EuNetAir joint exercise", Atmospheric Environment, vol. 147, pp. 246-263, 2016.
[37] J.M. Santamaría-Ulecia, A.H. Ariño-Plana, B. León-Anguiano and et al., "Reduction of exposure of cyclists to urban air pollution", Programa LIFE13 ENV/ES/000417, 2018. https://hdl.handle.net/10171/56028.

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 79
[38] C. Borrego, J. Ginja, M. Coutinho, C. Ribeiro, K. Karatzas, T. Sioumis, N. Katsifarakis, K. Konstantinidis, S. De Vito,
E. Esposito, M. Salvato, P. Smith, N. André, P. Gérard, L.A. Francis, N. Castell, P. Schneider and M. Viana,
"Assessment of air quality microsensors versus reference methods: The EuNetAir Joint Exercise – Part II",
Atmospheric Environment, vol. 193, pp. 127-142, 2018.
[39] Ayuntamiento de Madrid. Interpretación ficheros calidad del aire,
"https://datos.madrid.es/FWProjects/egob/Catalogo/MedioAmbiente/Aire/Ficheros/Interprete_ficheros_%20c
alidad_%20del_%20aire_global.pdf".
[40] A. Prayati, C. Antonopoulos, T. Stoyanova, C. Koulamas and G. Papadopoulos, "A modeling approach on the
TelosB WSN platform power consumption", The Journal of Systems & Software, vol. 83, pp. 1355-1363, 2010.
[41] Contiki-NG. Módulo Energest, "https://github.com/contiki-ng/contiki-ng/wiki/Documentation:-Energest".
[42] A. Da Cunha B., B. de Almeida R. and D. Da Silva C., "Remaining Capacity Measurement and Analysis of Alkaline
Batteries for Wireless Sensor Nodes," IEEE Transactions on Instrumentation and Measurement, vol. 58, pp. 1816-
1822, 2009.
[43] G. Nikolic, T. Nikolic, M. Stojcev, B. Petrovic and G. Jovanovic, "Battery capacity estimation of wireless sensor node", EEE 30th International Conference on Microelectronics vol. 2017-, pp. 279-282, 2017.
[44] Datasheet Batería, "https://www.mouser.com/datasheet/2/101/LS%2014500_0408_revised_0908.58ecd0c2-
6b62-44ca-8c7e-2392.pdf".

Capítulo 6: Bibliografía
ETSII UPM 80

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 81
7 Planificación temporal y presupuesto
En este capítulo se presenta la planificación de actividades mediante una Estructura de Descomposición del Proyecto (EDP), la planificación temporal mediante un diagrama de Gantt, y el presupuesto del proyecto.
7.1 Planificación de actividades
Se ha empleado una EDP (Figura 55) para representar los principales paquetes de trabajo del proyecto:
• Planificación del TFG: engloba la planificación del trabajo, la definición de objetivos y el análisis de los recursos necesarios.
• Entorno de simulación (Contiki-NG y Cooja): incluye la instalación de Contiki-NG a través de la imagen Docker, la familiarización con el código de Contiki-NG y su simulador Cooja, y la conexión de una red simulada en Cooja con otra externa.
• Análisis de los datos de contaminación atmosférica de Madrid: descarga de los datos de contaminación atmosférica de Madrid de la web del Ayuntamiento de Madrid, preprocesado de los datos horarios mensuales para estandarizar sus formatos, agregación de los datos por años y análisis de los datos. También incluye el análisis bibliográfico acerca de las redes inalámbricas de sensores empleadas para medir contaminación atmosférica.
• Red inalámbrica de sensores: en este paquete de trabajo se considera el diseño de la red nodal, la programación de los nodos y la simulación la red
• Algoritmo de gestión de la red: incluye el análisis bibliográfico de las publicaciones relacionadas con “Resource Allocation” y “Computation Offloading”, la definición de los modos de trabajo, el establecimiento de los niveles de operación de la red y la implementación del algoritmo que gestiona la red simulada.
• Documentación: redacción de la memoria del TFG.

Capítulo 7: Planificación temporal y presupuesto
ETSII UPM 82
Trabajo de Fin de Grado
PlanificaciónEntorno de simulación
(Contiki-NG y Cooja)
Análisis de datos de contaminación
atmosféricaAlgoritmo gestión
redDocumentación
Objetivos
Recursos
Familiarización con Contiki-NG y
Cooja
Conexión de una WSN con una red
externa
Estudio bibliográfico
Índice Calidad Aire
Obtención y procesamiento
datos de la contaminación atmosférica de
Madrid
Selección de estaciones para la
simulación
Análisis datos previamente procesados
Redacción de la memoria
Estudio bibliográfico Computation Offloading y
Resource Allocation
Definición modos de trabajo de los
nodos
Definición niveles de operación de
la red
Implementación del algoritmo
Red inalámbrica de sensores coordinada
por Gateway
Diseño de la red
Programación nodos
Simulación de la red
Alcance
Figura 56: EDP del proyectoPlanificación temporal (Diagrama de Gantt)

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 83
7.2 Planificación temporal (Diagrama de Gantt)
Figura 57: Diagrama de Gantt

Capítulo 7: Planificación temporal y presupuesto
ETSII UPM 84
7.3 Presupuesto
En este apartado del trabajo se recoge el presupuesto del proyecto. Para ello se distinguen tres tablas de costes:
• Presupuesto asociado al software empleado (Tabla 14). El software que se ha utilizado en este proyecto es de código abierto. Por tanto, su uso no tiene ningún coste.
Tabla 14: Coste asociado al software empleado
• Presupuesto asociado a la amortización de equipos (Tabla 15) Se ha considerado una amortización lineal en la que los equipos se amortizan en cuatro años y un tiempo de uso de los equipos de ocho meses.
Tabla 15: Coste asociado a la amortización de equipos
• Presupuesto asociado a los costes del equipo de ingeniería (Tabla 16).
Recoge los honorarios del personal implicado en el diseño y desarrollo del proyecto.
Tabla 16: Coste asociado al equipo de ingeniería
Personal Unidades Horas Euros/Hora Coste Total Técnico tutor 1 25 57 1.425
Estudiante 1 600 15 9.000
El coste total del proyecto es de 10.791,67 €
Producto Unidades Precio (euros) Coste Total Docker 1 0 0
Simulador Cooja 1 0 0 Jupyter Notebook 1 0 0
Producto Unidades Precio (euros) Amortización Coste Total Mac Book Pro 1 2.200 16,67% 366,67

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 85
Anexo 1 Anexo 1.1: Código en C con el que se programa el nodo para comunicación simple
entre WSN y Gateway #include "contiki.h" #include "net/routing/routing.h" #include "random.h" #include "net/netstack.h" #include "net/ipv6/simple-udp.h" #include "sys/log.h" #define LOG_MODULE "App" #define LOG_LEVEL LOG_LEVEL_INFO #define WITH_SERVER_REPLY 1 #define UDP_CLIENT_PORT 8765 #define UDP_SERVER_PORT 5678 #define SEND_INTERVAL (60 * CLOCK_SECOND) static struct simple_udp_connection udp_conn; /*---------------------------------------------------------------------------*/ PROCESS(udp_client_process, "UDP client"); AUTOSTART_PROCESSES(&udp_client_process); /*---------------------------------------------------------------------------*/ static void udp_rx_callback(struct simple_udp_connection *c, const uip_ipaddr_t *sender_addr, uint16_t sender_port, const uip_ipaddr_t *receiver_addr, uint16_t receiver_port, const uint8_t *data, uint16_t datalen) { LOG_INFO("Received response '%.*s' from ", datalen, (char *) data); LOG_INFO_6ADDR(sender_addr); #if LLSEC802154_CONF_ENABLED LOG_INFO_(" LLSEC LV:%d", uipbuf_get_attr(UIPBUF_ATTR_LLSEC_LEVEL)); #endif LOG_INFO_("\n"); } /*---------------------------------------------------------------------------*/ PROCESS_THREAD(udp_client_process, ev, data) { static struct etimer periodic_timer; static unsigned count; static char str[32]; uip_ipaddr_t dest_ipaddr; PROCESS_BEGIN(); /* Initialize UDP connection */ simple_udp_register(&udp_conn, UDP_CLIENT_PORT, NULL, UDP_SERVER_PORT, udp_rx_callback); etimer_set(&periodic_timer, random_rand() % SEND_INTERVAL); while(1) { PROCESS_WAIT_EVENT_UNTIL(etimer_expired(&periodic_timer)); if(NETSTACK_ROUTING.node_is_reachable()) {

Anexo 1
ETSII UPM 86
/* Send to Python Socket */ uip_ip6addr(&dest_ipaddr,0xfd00,0,0,0,0,0,0,1); LOG_INFO("Sending hello %u to ", count); snprintf(str, sizeof(str), "hello %d", count); LOG_INFO_6ADDR(&dest_ipaddr); LOG_INFO_("\n"); simple_udp_sendto_port(&udp_conn, str, strlen(str), &dest_ipaddr, UDP_SERVER_PORT); count++; } else { LOG_INFO("Not reachable yet\n"); } /* Add some jitter */ etimer_set(&periodic_timer, SEND_INTERVAL - CLOCK_SECOND + (random_rand() % (2 * CLOCK_SECOND))); } PROCESS_END(); }

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 87
Anexo 1.2: Código en C con el que se programa el Border Router * Copyright (c) 201, RISE SICS * All rights reserved. * * Redistribution and use in source and binary forms, with or without * modification, are permitted provided that the following conditions * are met: * 1. Redistributions of source code must retain the above copyright * notice, this list of conditions and the following disclaimer. * 2. Redistributions in binary form must reproduce the above * copyright notice, this list of conditions and the following * disclaimer in the documentation and/or other materials provided * with the distribution. * 3. Neither the name of the Institute nor the names of its * contributors may be used to endorse or promote products derived * from this software without specific prior written permission. * * THIS SOFTWARE IS PROVIDED BY THE INSTITUTE AND CONTRIBUTORS ``AS * IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT * LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS * FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE * INSTITUTE OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, * INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES * (INCLUDING,BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS * OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS * INTERRUPTION).HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, * WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING * NEGLIGENCE OR OTHERWISE) ARISING IN * ANY WAY OUT OF THE USE OF * THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. * * This file is part of the Contiki operating system. * */ #include "contiki.h" /* Log configuration */ #include "sys/log.h" #define LOG_MODULE "RPL BR" #define LOG_LEVEL LOG_LEVEL_INFO /* Declare and auto-start this file's process */ PROCESS(contiki_ng_br, "Contiki-NG Border Router"); AUTOSTART_PROCESSES(&contiki_ng_br); /*------------------------------------------------------------------*/ PROCESS_THREAD(contiki_ng_br, ev, data) { PROCESS_BEGIN(); #if BORDER_ROUTER_CONF_WEBSERVER PROCESS_NAME(webserver_nogui_process); process_start(&webserver_nogui_process, NULL); #endif /* BORDER_ROUTER_CONF_WEBSERVER */ LOG_INFO("Contiki-NG Border Router started\n"); PROCESS_END(); }

Anexo 1
ETSII UPM 88

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 89
Anexo 1.3: Código en C con el que se programan los nodos sensor #include "contiki.h" #include "net/routing/routing.h" #include "random.h" #include "net/netstack.h" #include "net/ipv6/simple-udp.h" #include "sys/energest.h" #include <string.h> #include <stdlib.h> #include "sys/log.h" #define LOG_MODULE "App" #define LOG_LEVEL LOG_LEVEL_INFO #define WITH_SERVER_REPLY 1 #define UDP_CLIENT_PORT 8765 #define UDP_SERVER_PORT 5678 /*--------------------------CONTAMINANTE----------------------------*/ // DESCOMENTAR EL “DEFINE” QUE REFERENTE AL CONTAMINANTE QUE SE MIDE //#define MAX_CONTAM 21 //PM,25 //#define MAX_CONTAM 36 //PM10 #define MAX_CONTAM 101 //NO2 //#define MAX_CONTAM 121 //O3 //#define MAX_CONTAM 201 //SO2 /*------------------------------------------------------------------*/ static struct simple_udp_connection udp_conn; static uint8_t modo=2; static uint8_t max_medidas; static char str_recv[78]; static uint8_t estado=0; static uint8_t ano, mes, dia, hora; static uint8_t fecha_recien_iniciada=1; static uint8_t medidas_m3_m4[6]; static uint8_t medidas_cont; static char c_dia=1; static char c_inic=1; static uint8_t c_dia_fin=0; static char c_no_enviado=0; static char d_no_enviado=0; static uint8_t envia=0; static char cad_aux[4]; static char datos_almac[] = "00000000000000000000000000000000000000000 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000"; /*------------------------------------------------------------------*/ PROCESS(actualizar_estado, "actualizar estado"); PROCESS(actualizar_fecha_hora, "actualizar fecha hora"); AUTOSTART_PROCESSES(&actualizar_estado, &actualizar_fecha_hora); /*------------------------------------------------------------------*/ static unsigned long to_seconds(uint64_t time) { return (unsigned long)(time / ENERGEST_SECOND); }

Anexo 1
ETSII UPM 90
/*------------------------------------------------------------------*/ static void cambia_datos(){ c_inic=1; c_no_enviado=1; estado=2; NETSTACK_RADIO.on(); } /*------------------------------------------------------------------*/ static void udp_rx_callback(struct simple_udp_connection *c, const uip_ipaddr_t *sender_addr, uint16_t sender_port, const uip_ipaddr_t *receiver_addr, uint16_t receiver_port, const uint8_t *data, uint16_t datalen) { strcpy(str_recv , (const char*)data); str_recv[datalen]='\0'; switch (str_recv[0]) { case 'f': if (estado==0) estado=1; break; case 'c': if (estado==2){ c_no_enviado=1; estado=3; } break; case 'm': if (estado==2){ d_no_enviado=1; estado=4; NETSTACK_RADIO.off(); } break; case 'd': if (estado==5){ d_no_enviado=1; estado=6; } break; case 'b': if (estado==6) NETSTACK_RADIO.off(); modo=(uint8_t)(str_recv[2]-'0'); estado = 7; //LOG_INFO("%d \n", estado); break; } #if LLSEC802154_CONF_ENABLED LOG_INFO_(" LLSEC LV:%d", uipbuf_get_attr(UIPBUF_ATTR_LLSEC_LEVEL)); #endif LOG_INFO_("\n"); } /*------------------------------------------------------------------*/ PROCESS_THREAD(actualizar_estado, ev, data) { static char str1[85]; uip_ipaddr_t dest_ipaddr; static struct etimer periodic_timer; static uint8_t rx_i; PROCESS_BEGIN();

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 91
simple_udp_register(&udp_conn, UDP_CLIENT_PORT, NULL, UDP_SERVER_PORT, udp_rx_callback); etimer_set(&periodic_timer, CLOCK_SECOND*20); // 20 segundos while(1) { PROCESS_WAIT_EVENT_UNTIL(etimer_expired(&periodic_timer)); switch (estado){ case 0: etimer_set(&periodic_timer, CLOCK_SECOND * 5); break; case 1: etimer_set(&periodic_timer, CLOCK_SECOND * 0.5); break; case 2: etimer_set(&periodic_timer, CLOCK_SECOND * 2); break; default: etimer_set(&periodic_timer, CLOCK_SECOND * 1); break; } if (envia==0){ switch (estado){ case 0: // i, numero estacion (8/24), contaminante SO2/ NO2/ PM10/ PM25/ O3) snprintf(str1, sizeof(str1), "i,8,NO2"); envia=1; break; case 1: cad_aux[0]=str_recv[2]; cad_aux[1]=str_recv[3]; cad_aux[2]='\0'; ano=atoi(cad_aux); cad_aux[0]=str_recv[4]; cad_aux[1]=str_recv[5]; cad_aux[2]='\0'; mes=atoi(cad_aux); cad_aux[0]=str_recv[6]; cad_aux[1]=str_recv[7]; dia=atoi(cad_aux); cad_aux[0]=str_recv[8]; cad_aux[1]=str_recv[9]; hora=atoi(cad_aux); fecha_recien_iniciada=1; break; case 2: if (c_inic){ if (dia<9){ c_dia=0; c_dia_fin=9; } else if (dia<17){ c_dia=8; c_dia_fin=17; } else if (dia<25){ c_dia=16; c_dia_fin=25; } else{ c_dia=24; c_dia_fin=33; } c_inic=0; }

Anexo 1
ETSII UPM 92
if (c_no_enviado){ c_dia++; if (c_dia==(c_dia_fin-8)){ snprintf(str1, sizeof(str1), "c,ini,%4lu,%4lu,%4lu,%4lu,%d,%d,%d", to_seconds(energest_type_time(ENERGEST_TYPE_CPU)), to_seconds(energest_type_time(ENERGEST_TYPE_LPM)), to_seconds(energest_type_time(ENERGEST_TYPE_TRANSMIT)), to_seconds(energest_type_time(ENERGEST_TYPE_LISTEN)), ano, mes, c_dia); envia=1; c_no_enviado=0; } else if (c_dia<c_dia_fin){ snprintf(str1, sizeof(str1), "c,%d,%d,%d", ano, mes, c_dia); envia=1; c_no_enviado=0; } else if (c_dia==c_dia_fin){ snprintf(str1, sizeof(str1), "c,fin,%4lu,%4lu,%4lu,%4lu", to_seconds(energest_type_time(ENERGEST_TYPE_CPU)), to_seconds(energest_type_time(ENERGEST_TYPE_LPM)), to_seconds(energest_type_time(ENERGEST_TYPE_TRANSMIT)), to_seconds(energest_type_time(ENERGEST_TYPE_LISTEN))); envia=1; c_no_enviado=0; } } break; case 3: cad_aux[0]=str_recv[2]; cad_aux[1]=str_recv[3]; cad_aux[2]='\0'; for (rx_i=0;rx_i<72;rx_i++){ datos_almac[(atoi(cad_aux)-(c_dia_fin-8))*72+rx_i] = str_recv[rx_i+5]; } c_no_enviado=1; break; case 4: cad_aux[0]=datos_almac[72*(dia-(c_dia_fin-8))+3*(hora-1)]; cad_aux[1]=datos_almac[72*(dia-(c_dia_fin-8))+3*(hora-1)+1]; cad_aux[2]=datos_almac[72*(dia-(c_dia_fin-8))+3*(hora-1)+2]; cad_aux[3]='\0'; medidas_m3_m4[medidas_cont] = atoi(cad_aux); medidas_cont++; if (atoi(cad_aux)<MAX_CONTAM){ estado = 7; } if (modo==4) max_medidas=5; if (modo==3) max_medidas=3; if (modo==2) max_medidas=1; //LOG_INFO("MODO %d ok", modo); if ((medidas_cont == max_medidas)|(atoi(cad_aux)>= MAX_CONTAM)){ NETSTACK_RADIO.on(); estado=5; d_no_enviado=1; } break; case 5: if (d_no_enviado){ switch (medidas_cont){ case 1: snprintf(str1, sizeof(str1), "d,%d,", medidas_m3_m4[0]); break; case 2:

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 93
snprintf(str1, sizeof(str1), "d,%d,%d,", medidas_m3_m4[0],medidas_m3_m4[1]); break; case 3: snprintf(str1, sizeof(str1), "d,%d,%d,%d,", medidas_m3_m4[0], medidas_m3_m4[1], medidas_m3_m4[2]); break; case 4: snprintf(str1, sizeof(str1), "d,%d,%d,%d,%d,", medidas_m3_m4[0], medidas_m3_m4[1], medidas_m3_m4[2], medidas_m3_m4[3]); break; case 5: snprintf(str1, sizeof(str1), "d,%d,%d,%d,%d,%d,", medidas_m3_m4[0], medidas_m3_m4[1], medidas_m3_m4[2], medidas_m3_m4[3], medidas_m3_m4[4]); break; case 6: snprintf(str1, sizeof(str1), "d,%d,%d,%d,%d,%d,%d,", medidas_m3_m4[0], medidas_m3_m4[1], medidas_m3_m4[2], medidas_m3_m4[3], medidas_m3_m4[4], medidas_m3_m4[5]); break; } medidas_cont = 0; envia=1; d_no_enviado=0; } break; case 6: if (d_no_enviado){ snprintf(str1, sizeof(str1), "b,%d,%d,%d,%d,%4lu,%4lu,%4lu,%4lu", ano, mes, dia, hora, to_seconds(energest_type_time(ENERGEST_TYPE_CPU)), to_seconds(energest_type_time(ENERGEST_TYPE_LPM)), to_seconds(energest_type_time(ENERGEST_TYPE_TRANSMIT)), to_seconds(energest_type_time(ENERGEST_TYPE_LISTEN))); envia=1; d_no_enviado=0; } break; default: break; } } if (envia){ if(NETSTACK_ROUTING.node_is_reachable()) { uip_ip6addr(&dest_ipaddr,0xfd00,0,0,0,0,0,0,1); simple_udp_sendto_port(&udp_conn, str1, strlen(str1), &dest_ipaddr, UDP_SERVER_PORT); envia=0; } } switch (estado){ case 1: estado=2; c_inic=1; c_no_enviado=1; break; case 3: if (c_no_enviado==1) { estado=2; } break;

Anexo 1
ETSII UPM 94
default: break; } } PROCESS_END(); } /*------------------------------------------------------------------*/ PROCESS_THREAD(actualizar_fecha_hora, ev, data) { static struct etimer periodic_timer_hora; static char bisiesto; PROCESS_BEGIN(); //LO AÑADO PARA RECIBIR PORCENTAJE BATERIA simple_udp_register(&udp_conn, UDP_CLIENT_PORT, NULL, UDP_SERVER_PORT, udp_rx_callback); etimer_set(&periodic_timer_hora, CLOCK_SECOND*5); // 5 segundos while(1) { PROCESS_WAIT_EVENT_UNTIL(etimer_expired(&periodic_timer_hora)); if (estado>3){ etimer_set(&periodic_timer_hora, CLOCK_SECOND*60*10);//Hago que cada 6 minutos es 1 h if (fecha_recien_iniciada){ fecha_recien_iniciada=0; } else{ hora++; d_no_enviado=1; estado=4; } if (hora==25){ dia++; //if (dia==17){ if (dia==c_dia_fin){ cambia_datos(); } hora=1; if ((mes==1)|(mes==3)|(mes==5)|(mes==7)|(mes==8)|(mes==10)| (mes==12)){ if (dia==32){ mes++; dia=1; cambia_datos(); } } //bisiesto==1 --> ano bisiesto //bisiesto==0 --> ano no bisiesto else if(mes==2){ if (ano%4==0){ if (ano%100==0){ if (ano%400==0) bisiesto=1; else bisiesto=0; } else bisiesto=1; } else bisiesto=0; if (((bisiesto==1)&(dia==30))|((!bisiesto)&(dia==29))){ mes++; dia=1; cambia_datos(); } } else{ if (dia==31){ mes++; dia=1; cambia_datos();

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 95
} } if (mes==13){ ano++; mes=1; cambia_datos(); } } } else{ etimer_set(&periodic_timer_hora, CLOCK_SECOND*20); } } PROCESS_END(); }

Anexo 1
ETSII UPM 96

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 97
Anexo 1.4: Código en Python con el que se programa el Gateway import socket import logging import time import threading import pandas as pd from datetime import datetime, date, time, timedelta UDP_IP = 'fd00::1' UDP_PORT_RECIBO = 5678 # Fecha y hora de la simulacion inic_ano = "18" inic_mes = "02" inic_dia = "01" inic_hora = "01" # VARIABLES ALGORITMO ICs_len = 5 prox_modo = 3 message = "" address = "" # Parametros para el modelo de la bateria C0 = 2600 # C0 capacidad maxima bateria (mAh) k_bateria = 0.99795 I_sky = [2.33, 0.0018, 20.47, 19.37] # en mA: MCU ON, LPM, TX, RX info_completa = 0 # Si a 1, muestra informacion completa arrays # Carga con datos anos 2011 a 2019 aire=pd.read_csv('datos_contaminantes/aire_19.csv', header = 0, delimiter=',') aire_aux=pd.read_csv('datos_contaminantes/aire_18.csv', header = 0, delimiter=',') aire=pd.concat([aire, aire_aux], axis=0, join='outer', ignore_index=True, keys=None,levels=None, names=None, verify_integrity=False, copy=True) aire_aux=pd.read_csv('datos_contaminantes/aire_17.csv', header = 0, delimiter=',') aire_aux["ANO"]=2017 aire=pd.concat([aire, aire_aux], axis=0, join='outer', ignore_index=True, keys=None,levels=None, names=None, verify_integrity=False, copy=True) aire_aux=pd.read_csv('datos_contaminantes/aire_16.csv', header = 0, delimiter=',') aire_aux["ANO"]=2016 aire=pd.concat([aire, aire_aux], axis=0, join='outer', ignore_index=True, keys=None,levels=None, names=None, verify_integrity=False, copy=True) aire_aux=pd.read_csv('datos_contaminantes/aire_15.csv', header = 0, delimiter=',') aire_aux["ANO"]=2015 aire = pd.concat([aire, aire_aux], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True) aire_aux = pd.read_csv('datos_contaminantes/aire_14.csv', header = 0, delimiter=',') aire_aux["ANO"]=2014 aire = pd.concat([aire, aire_aux], axis=0, join='outer', ignore_index=True, keys=None,levels=None, names=None, verify_integrity=False, copy=True) aire_aux=pd.read_csv('datos_contaminantes/aire_13.csv', header = 0, delimiter=',', low_memory=False) aire_aux["ANO"]=2013 aire=pd.concat([aire, aire_aux], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True)

Anexo 1
ETSII UPM 98
aire_aux=pd.read_csv('datos_contaminantes/aire_12.csv', header = 0, delimiter=',') aire_aux["ANO"]=2012 aire=pd.concat([aire, aire_aux], axis=0, join='outer', ignore_index=True, keys=None,levels=None, names=None, verify_integrity=False, copy=True) aire_aux=pd.read_csv('datos_contaminantes/aire_11.csv', header = 0, delimiter=',') aire_aux["ANO"]=2011 aire=pd.concat([aire, aire_aux], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True) # Ordena datos y elimina columnas del dataframe aire=aire.sort_values(by=['ANO','MES', 'DIA']) aire.drop(['PROVINCIA', 'MUNICIPIO'], axis = 'columns', inplace=True) aire.drop(['V01', 'V02', 'V03', 'V04', 'V05', 'V06', 'V07', 'V08', 'V09','V10', 'V11', 'V12'], axis = 'columns', inplace=True) aire.drop(['V13', 'V14', 'V15', 'V16', 'V17', 'V18', 'V19', 'V20', 'V21','V22', 'V23', 'V24'], axis = 'columns', inplace=True) # Dataframe con estaciones 4 y 8 aire=aire[((aire["ESTACION"]==4)|(aire["ESTACION"]==8))] aire["H09"] = pd.to_numeric(aire["H09"]) aire_SO2 = aire[aire["MAGNITUD"]==1] aire_NO2 = aire[aire["MAGNITUD"]==8] aire_PM25 = aire[aire["MAGNITUD"]==9] aire_PM10 = aire[aire["MAGNITUD"]==10] aire_O3 = aire[aire["MAGNITUD"]==14] # Dataframe que almacena el IC general de la red columnas = ['ano', 'mes', 'dia', 'tipo_dato'] for i in range(1,25): columnas.append (str(i)) IC_red = pd.DataFrame(columns=columnas) # Creacion de columnas dataframe que almacena datos recibidos de nodos columnas = ['ano', 'mes', 'dia', 'tipo_dato', 'est_ano', 'dia_sem'] for i in range(1,25): columnas.append (str(i)) # Establece conexion con red inalámbrica de sensores sock = socket.socket(socket.AF_INET6, socket.SOCK_DGRAM) sock.bind((UDP_IP, UDP_PORT_RECIBO)) class Database_Class: def __init__(self): self.msg=[] self.addr=[] self.port=[] self.text=str() self.nodos_dic=[] self.nodos_df=[] def thread_communication(self,name): logging.info("Thread %s: starting", name) while 1: data, addr_recv = sock.recvfrom(1024) # Comprobacion de si es un mensaje repetido recv_aux=0 for i in range (len(self.msg)): if (self.msg[i]==data): if (self.addr[i]==addr_recv[0]): recv_aux=1 if (message==data): if (address==addr_recv[0]): recv_aux=1 if recv_aux==0:

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 99
self.msg.insert(0, data) self.addr.insert(0, addr_recv[0]) self.port.insert(0, addr_recv[1]) logging.info("Thread %s: finishing", name) def thread_task(self,name): logging.info("Thread %s: starting", name) i = 0 while 1: if (len(self.msg)>0): print(self.msg) print(self.addr) message = self.msg.pop() address = self.addr.pop() port_send = self.port.pop() logging.info("Thread %s, mensaje recibido: %s", name, message) indice_nodo="no existe" for i in range(len(self.nodos_dic)): if (self.nodos_dic[i]['direccion'] == address): _nodo = i info("Thread "+str(name) + ", Nodo ya registrado con indice: "+str(indice_nodo)) if (indice_nodo == "no existe"): logging.info("Thread "+ str(name) + ", Registro direreccion: " + str(address) + "como nodo: " + str(indice_nodo)) datetime_d = datetime(int(inic_ano),int(inic_mes), int(inic_dia),int(inic_hora)-1) - timedelta(hours=1) #Anado nuevo nodo a la lista de nodos nodo_anadir_dic = { 'direccion': address, 'num_estacion': 0, 'sensor': str(), 'modo': 2, # Modo de trabajo en el que inicia el nodo 'd_len': 0, 'ult_ano': datetime_d.year, 'ult_mes': datetime_d.month, 'ult_dia': datetime_d.day, 'ult_hora': datetime_d.hour+1, 'ult_CPU': 0, 'ult_LPM': 0, 'ult_TX': 0, 'ult_RX': 0, 'ult_C': C0, 'c_ini_CPU': 0, 'c_ini_LPM': 0, 'c_ini_TX': 0, 'c_ini_RX': 0, 'ult_medidas': [], 'pico_consumo': 0 } nodo_anadir_df = pd.DataFrame(columns=columnas) self.nodos_dic.append(nodo_anadir_dic) self.nodos_df.append(nodo_anadir_df) indice_nodo = (len(self.nodos_dic)-1) if message[0]=='i': self.nodos_dic[indice_nodo]['num_estacion'] = int(message[2]) self.nodos_dic[indice_nodo]['sensor'] = message[4:] logging.info("Thread "+ str(name) + ", Nodo nuevo con sensor de: " + message[4:] + " de la estacion: " + message[2]) self.text = "f,"+inic_ano+inic_mes+inic_dia+inic_hora sock.sendto(self.text, (address, port_send)) .info("Thread " + str(name) + ", mensaje enviado: " +

Anexo 1
ETSII UPM 100
self.text ) elif message[0]=='c': if message[:5]=="c,fin": b_j = 0 b_CPU = "" b_LPM = "" b_TX = "" b_RX = "" for caracter in message[6:]: if caracter!=',': if b_j==0: b_CPU += caracter elif b_j==1: b_LPM += caracter elif b_j==2: b_TX += caracter else: b_RX += caracter else: b_j += 1 print("fin --> CPU: "+b_CPU+" LPM: "+b_LPM+" TX: " +b_TX+" RX: "+b_RX) self.nodos_dic[indice_nodo]['ult_CPU'] += (int(b_CPU) - self.nodos_dic[indice_nodo]['c_ini_CPU']) self.nodos_dic[indice_nodo]['ult_LPM'] += (int(b_LPM) - self.nodos_dic[indice_nodo]['c_ini_LPM']) self.nodos_dic[indice_nodo]['ult_TX'] += (int(b_TX) – self.nodos_dic[indice_nodo]['c_ini_TX']) self.nodos_dic[indice_nodo]['ult_RX'] += (int(b_RX) – self.nodos_dic[indice_nodo]['c_ini_RX']) self.text = "m,ok" else: c_aux = 0 c_ano = "" c_mes = "" c_dia = "" if message[:5]=="c,ini": b_j = 0 b_CPU = "" b_LPM = "" b_TX = "" b_RX = "" for caracter in message[6:]: if caracter!=',': if b_j==0: b_CPU += caracter elif b_j==1: b_LPM += caracter elif b_j==2: b_TX += caracter elif b_j==3: b_RX += caracter elif b_j==4: c_ano += caracter elif b_j==5: c_mes += caracter else: c_dia += caracter else: b_j += 1 self.nodos_dic[indice_nodo]['c_ini_CPU'] = int(b_CPU) self.nodos_dic[indice_nodo]['c_ini_LPM'] = int(b_LPM)

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 101
self.nodos_dic[indice_nodo]['c_ini_TX'] = int(b_TX) self.nodos_dic[indice_nodo]['c_ini_RX'] = int(b_RX) print("ini --> CPU: "+b_CPU+" LPM: "+b_LPM+" TX: " +b_TX+" RX: "+b_RX) else: for caracter in message[2:]: if caracter!=',': if c_aux==0: c_ano += caracter elif c_aux==1: c_mes += caracter elif c_aux==2: c_dia += caracter else: c_aux += 1 c_ano = int("20"+c_ano) c_mes = int(c_mes) c_dia = int(c_dia) lista=[] if c_dia<10: self.text = "c,0"+str(c_dia)+"," else: self.text = "c,"+str(c_dia)+"," if self.nodos_dic[indice_nodo]['sensor']=="SO2": if ((aire_SO2["ESTACION"]== self.nodos_dic[indice_nodo] ['num_estacion']) &(aire_SO2["ANO"]==c_ano) &(aire_SO2["MES"]==c_mes)& (aire_SO2["DIA"]==c_dia)).any(): df_c_i = (aire_SO2[(aire_SO2["ESTACION"]== self.nodos_dic[indice_nodo]['num_estacion']) &(aire_SO2['ANO']==c_ano) &(aire_SO2['MES']==c_mes) &(aire_SO2['DIA']==c_dia)].index[-1]) lista=aire_SO2.loc[df_c_i,"H01":].tolist() else: for i in range(1,25): lista.append(0) elif self.nodos_dic[indice_nodo]['sensor']=="NO2": if ((aire_NO2["ESTACION"]== self.nodos_dic[indice_nodo]['num_estacion']) &(aire_NO2['ANO']==c_ano) &(aire_NO2['MES']==c_mes) &(aire_NO2['DIA']==c_dia)).any(): df_c_i=(aire_NO2[(aire_NO2["ESTACION"]== self.nodos_dic[indice_nodo]['num_estacion']) &(aire_NO2['ANO']==c_ano) &(aire_NO2['MES']==c_mes) &(aire_NO2['DIA']==c_dia)].index[-1]) lista=aire_NO2.loc[df_c_i,"H01":].tolist() else: for i in range(1,25): lista.append(0) elif self.nodos_dic[indice_nodo]['sensor']=="O3": if ((aire_O3['ESTACION']== self.nodos_dic[indice_nodo]['num_estacion']) &(aire_O3['ANO']==c_ano) &(aire_O3['MES']==c_mes) &(aire_O3['DIA']==c_dia)).any(): df_c_i=(aire_O3[(aire_O3['ESTACION']== self.nodos_dic[indice_nodo]['num_estacion']) &(aire_O3['ANO']==c_ano)

Anexo 1
ETSII UPM 102
&(aire_O3['MES']==c_mes) &(aire_O3['DIA']==c_dia)].index[-1]) lista=aire_O3.loc[df_c_i,"H01":].tolist() else: for i in range(1,25): lista.append(0) elif self.nodos_dic[indice_nodo]['sensor']=="PM25": if ((aire_PM25['ESTACION']== self.nodos_dic[indice_nodo]['num_estacion']) &(aire_PM25['ANO']==c_ano) &(aire_PM25['MES']==c_mes) &(aire_PM25['DIA']==c_dia)).any(): df_c_i=(aire_PM25[(aire_PM25['ESTACION']== self.nodos_dic[indice_nodo]['num_estacion']) &(aire_PM25['ANO']==c_ano) &(aire_PM25['MES']==c_mes) &(aire_PM25['DIA']==c_dia)].index[-1]) lista=aire_PM25.loc[df_c_i,"H01":].tolist() else: for i in range(1,25): lista.append(0) elif self.nodos_dic[indice_nodo]['sensor']=="PM10": if ((aire_PM10['ESTACION']== self.nodos_dic[indice_nodo]['num_estacion']) &(aire_PM10['ANO']==c_ano) &(aire_PM10['MES']==c_mes) &(aire_PM10['DIA']==c_dia)).any(): df_c_i=(aire_PM10[(aire_PM10['ESTACION']== self.nodos_dic[indice_nodo]['num_estacion']) &(aire_PM10['ANO']==c_ano) &(aire_PM10['MES']==c_mes) &(aire_PM10['DIA']==c_dia)].index[-1]) lista=aire_PM10.loc[df_c_i,"H01":].tolist() else: for i in range(1,25): lista.append(0) for medida in lista: medida = int(medida) if medida<10: self.text = self.text + "00"+str(medida) elif medida<100: self.text = self.text + "0"+str(medida) else: self.text = self.text + str(medida) sock.sendto(self.text, (address, port_send)) logging.info("Thread " + str(name) + ", mensaje enviado: " + self.text + "\n") elif message[0]=='d': self.nodos_dic[indice_nodo]['d_len'] = 0 d_medida = "" for i_d in message[2:]: if i_d != ',': d_medida += i_d else: self.nodos_dic[indice_nodo]['d_len'] += 1 datetime_d = datetime(self.nodos_dic[indice_nodo]['ult_ano'], self.nodos_dic[indice_nodo]['ult_mes'], self.nodos_dic[indice_nodo]['ult_dia'], self.nodos_dic[indice_nodo]['ult_hora']-1) + timedelta(hours=1) d_ano = datetime_d.year d_mes = datetime_d.month d_dia = datetime_d.day d_hora = datetime_d.hour + 1

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 103
d_medida = int(d_medida) self.nodos_dic[indice_nodo]['ult_ano'] = d_ano self.nodos_dic[indice_nodo]['ult_mes'] = d_mes self.nodos_dic[indice_nodo]['ult_dia'] = d_dia self.nodos_dic[indice_nodo]['ult_hora'] = d_hora if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]["mes"]==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo]['tipo_dato'] ==self.nodos_dic[indice_nodo]['sensor'])).any() == False: print("No existe la fila") # ESTACION ANO # 0 -- Invierno -- Diciembre/Enero/Febrero # 1 -- Primavera -- Marzo/Abril/Mayo # 2 -- Verano -- Junio/Julio/Agosto # 3 -- Otono -- Septiembre/Octubre/Noviembre if ((self.nodos_dic[indice_nodo][ 'ult_mes'] ==12) | (self.nodos_dic[indice_nodo]['ult_mes'] ==1) |(self.nodos_dic[indice_nodo]['ult_mes'] ==2)): est_ano=0 elif ( (self.nodos_dic[indice_nodo]['ult_mes'==3)| (self.nodos_dic[indice_nodo]['ult_mes']==4)| (self.nodos_dic[indice_nodo]['ult_mes']==5)): est_ano=1 elif ( (self.nodos_dic[indice_nodo]['ult_mes']==6)| (self.nodos_dic[indice_nodo]['ult_mes']==7)| (self.nodos_dic[indice_nodo]['ult_mes']==8)): est_ano=2 else: est_ano=3 # DIA SEMANA datetime_d = datetime(int("20"+str(d_ano)),d_mes,d_dia) dia_sem=datetime_d.strftime("%A") fila_anadir=[d_ano, d_mes, d_dia, self.nodos_dic[indice_nodo][ 'sensor'],est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[ len(self.nodos_df[indice_nodo])] = fila_anadir else: print("Fila existente") df_i = self.nodos_df[indice_nodo][ (self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo]["tipo_dato"] ==self.nodos_dic[indice_nodo][ 'sensor'])].index[-1] self.nodos_df[indice_nodo].loc[df_i,str(d_hora)] =d_medida logging.info("Thread "+str(name) +", Medida: " + str(self.nodos_df[indice_nodo].loc[ df_i,str(d_hora)])) logging.info("Thread "+str(name) +", Mes: "+ str(d_mes) +" Dia: " + str(d_dia) + " Hora: "+ str(d_hora) + " SO2: " + str(d_medida))

Anexo 1
ETSII UPM 104
#INDICE DE CALIDAD IC_medida=self.nodos_df[ indice_nodo].loc[df_i,str(d_hora)] # NO2 if self.nodos_dic[indice_nodo]['sensor']=="NO2": if (IC_medida<=40): IC = 5 # Muy bueno elif ((IC_medida>=41)&(IC_medida<=100)): IC = 4 # Bueno elif ((IC_medida>=101)&(IC_medida<=200)): IC = 3 # Regular elif ((IC_medida>=201)&(IC_medida<=400)): IC = 2 # Malo else: IC = 1 #Muy malo # O3 elif self.nodos_dic[indice_nodo]['sensor']=="O3": if (IC_medida<=80): IC = 5 # Muy bueno elif ((IC_medida>=81)&(IC_medida<=120)): IC = 4 # Bueno elif ((IC_medida>=121)&(IC_medida<=180)): IC = 3 # Regular elif ((IC_medida>=181)&(IC_medida<=240)): IC = 2 # Malo else: IC = 1 #Muy malo # SO2 elif self.nodos_dic[indice_nodo]['sensor']=="SO2": if (IC_medida<=100): IC = 5 # Muy bueno elif ((IC_medida>=101) &(IC_medida<=200)): IC = 4 # Bueno elif ((IC_medida>=201)&(IC_medida<=350)): IC = 3 # Regular elif ((IC_medida>=351)&(IC_medida<=500)): IC = 2 # Malo else: IC = 1 #Muy malo else: # PM2,5 o PM10 --> media movil 24h self.nodos_dic[indice_nodo][ 'ult_medidas'].insert(0, IC_medida) if len(self.nodos_dic[indice_nodo][ 'ult_medidas'])<24: IC = 0 else: if len(self.nodos_dic[indice_nodo][ 'ult_medidas'])>24: self.nodos_dic[indice_nodo]['ult_medidas'].pop() IC_promedio = 0 for valor in self.nodos_dic[indice_nodo][ 'ult_medidas']: IC_promedio += valor IC_promedio = IC_promedio/len( self.nodos_dic[indice_nodo][ 'ult_medidas']) # PM2,5 if self.nodos_dic[indice_nodo][ 'sensor']=="PM25": if (IC_promedio<=10): IC = 5 # Muy bueno elif ((IC_promedio>=11) &(IC_promedio<=20)): IC = 4 # Bueno elif ((IC_promedio>=21) &(IC_promedio<=25)): IC = 3 # Regular elif ((IC_promedio>=26)

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 105
&(IC_promedio<=50)): IC = 2 # Malo else: IC = 1 #Muy malo # PM10 elif self.nodos_dic[indice_nodo][ 'sensor']=="PM10": if (IC_promedio<=20): IC = 5 # Muy bueno elif ((IC_promedio>=21)& (IC_promedio<=35)): IC = 4 # Bueno elif ((IC_promedio>=36)& (IC_promedio<=50)): IC = 3 # Regular elif ((IC_promedio>=51)& (IC_promedio<=100)): IC = 2 # Malo else: IC = 1 #Muy malo if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]["mes"]==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo]['tipo_dato']==( "IC_"+str(self.nodos_dic[indice_nodo][ 'sensor'])))).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, ("IC_"+str(self.nodos_dic[indice_nodo][ 'sensor'])),est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir else: print("Fila existente") df_i = self.nodos_df[indice_nodo][( self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo]["tipo_dato"] ==("IC_"+str(self.nodos_dic[ indice_nodo]['sensor'])))].index[-1] self.nodos_df[indice_nodo].loc[df_i,str(d_hora)]=IC # IC_GENERAL DE LA RED --> IC_red if((IC_red['ano']==d_ano)&(IC_red["mes"]==d_mes) &(IC_red['dia']==d_dia)).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, "IC"] for i in range(1,25): fila_anadir.append(-2) IC_red.loc[len(IC_red)] = fila_anadir fila_anadir=[d_ano, d_mes, d_dia, "contam"] for i in range(1,25): fila_anadir.append(-2) IC_red.loc[len(IC_red)] = fila_anadir else: print("Fila existente") df_red_i = IC_red[(IC_red['ano']==d_ano) &(IC_red['mes']==d_mes) &(IC_red['dia']==d_dia) &(IC_red['tipo_dato']=='IC')].index[-1] if ((IC_red.loc[df_red_i,str(d_hora)]==-2)| (IC_red.loc[df_red_i, str(d_hora)]>=IC))&(IC>0): IC_red.loc[df_red_i,str(d_hora)] = IC df_red_i2 = IC_red[(IC_red['ano']==d_ano)

Anexo 1
ETSII UPM 106
&(IC_red['mes']==d_mes) &(IC_red['dia']==d_dia) &(IC_red['tipo_dato']=='contam')].index[-1] IC_red.loc[df_red_i2,str(d_hora)] = self.nodos_dic[indice_nodo]['sensor'] #FILA MODO if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=='MODO')).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, "MODO",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir else: print("Fila existente") df_modo_i = self.nodos_df[indice_nodo][( self.nodos_df[indice_nodo]["ano"]==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=='MODO')].index[-1] print("df_modo_i: "+str(df_modo_i)) print("modo: "+ str(self.nodos_dic[indice_nodo]['modo'])) self.nodos_df[indice_nodo].loc[ df_modo_i,str(d_hora)] = self.nodos_dic[indice_nodo]['modo'] #FILA PROX_MODO if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo]['tipo_dato']== 'PROX_MODO')).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, "PROX_MODO",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir #FILA ALG_BAT if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo]['tipo_dato']== 'ALG_BAT')).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, "ALG_BAT",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir #FILA ALG_PICO if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo]['tipo_dato']== 'ALG_PICO')).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, "ALG_PICO",est_ano,dia_sem]

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 107
for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir #FILA CPU if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo]['tipo_dato']== "CPU")).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, "CPU",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir # LPM if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]["dia"]==d_dia) &(self.nodos_df[indice_nodo]["tipo_dato"]== "LPM")).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, "LPM",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir # TX if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo]['tipo_dato']== "TX")).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, "TX",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir # RX if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo]['tipo_dato']== "RX")).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, "RX",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir # PERIODO if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="periodo")).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, "periodo",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len(

Anexo 1
ETSII UPM 108
self.nodos_df[indice_nodo])] = fila_anadir # I_media if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo]['tipo_dato'] =="I_MEDIA")).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, "I_MEDIA",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir # CAPACIDAD if((self.nodos_df[indice_nodo]['ano']==d_ano) &(self.nodos_df[indice_nodo]['mes']==d_mes) &(self.nodos_df[indice_nodo]['dia']==d_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="C_bateria")).any() == False: print("No existe la fila") fila_anadir=[d_ano, d_mes, d_dia, "C_bateria",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir d_medida = "" self.text="d,ok" sock.sendto(self.text, (address, port_send)) logging.info("Thread "+str(name) +", mensaje enviado: "+self.text) elif message[0]=='b': b_j = 0 b_ano = "" b_mes = "" b_dia = "" b_hora = "" b_CPU = "" b_LPM = "" b_TX = "" b_RX = "" for b_i in range(2,len(message)): if (message[b_i]==','): b_j += 1 else: if b_j==0: _ano+=message[b_i] elif b_j==1: b_mes += message[b_i] elif b_j==2: b_dia += message[b_i] elif b_j==3: b_hora += message[b_i] elif b_j==4: b_CPU += message[b_i] elif b_j==5: b_LPM += message[b_i] elif b_j==6: b_TX += message[b_i] elif b_j==7: b_RX += message[b_i] print("CPU: "+b_CPU+" LPM: "+b_LPM+" TX: "+b_TX+" RX: "+b_RX) b_ano = int(b_ano) b_mes = int(b_mes)

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 109
b_dia = int(b_dia) b_hora = int(b_hora) b_CPU = int(b_CPU) b_LPM = int(b_LPM) b_TX = int(b_TX) b_RX = int(b_RX) print("ultima --> CPU: "+ str(self.nodos_dic[indice_nodo]['ult_CPU']) + " LPM: "+str(self.nodos_dic[indice_nodo]['ult_LPM'])+ " TX: "+str(self.nodos_dic[indice_nodo]['ult_TX'])+ " RX: "+str(self.nodos_dic[indice_nodo]['ult_RX'])) # POR SI HA FALLADO LA RECEPCION DE LA MEDICION #FILA MEDICION if((self.nodos_df[indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]["mes"]==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo]['tipo_dato']==( str(self.nodos_dic[indice_nodo][ 'sensor'])))).any() == False: print("No existe la fila") fila_anadir=[b_ano, b_mes, b_dia, (str(self.nodos_dic[indice_nodo] ['sensor'])),est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[ len(self.nodos_df[indice_nodo])] = fila_anadir #FILA IC if((self.nodos_df[indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]["mes"]==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo]['tipo_dato']== ("IC_"+str(self.nodos_dic[indice_nodo][ 'sensor'])))).any() == False: print("No existe la fila") fila_anadir=[b_ano, b_mes, b_dia, ("IC_"+str(self.nodos_dic[indice_nodo] ['sensor'])),est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir #FILA PROX_MODO if((self.nodos_df[indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=='PROX_MODO')).any() == False: print("No existe la fila") fila_anadir=[b_ano, b_mes, b_dia, "PROX_MODO",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir #FILA ALG_BAT if((self.nodos_df[indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo]['tipo_dato']== 'ALG_BAT')).any() == False: print("No existe la fila") fila_anadir=[b_ano, b_mes, b_dia, "ALG_BAT",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len(self.nodos_df[

Anexo 1
ETSII UPM 110
indice_nodo])] = fila_anadir #FILA ALG_PICO if((self.nodos_df[indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo]['tipo_dato']== 'ALG_PICO')).any() == False: print("No existe la fila") fila_anadir=[b_ano, b_mes, b_dia, "ALG_PICO", est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len(self.nodos_df[ indice_nodo])] = fila_anadir #FILA CPU if((self.nodos_df[indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo]['tipo_dato']== "CPU")).any() == False: print("No existe la fila") fila_anadir=[b_ano, b_mes, b_dia, "CPU",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir # LPM if((self.nodos_df[indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]["dia"]==b_dia) &(self.nodos_df[indice_nodo][ "tipo_dato"]=="LPM")).any() == False: print("No existe la fila") fila_anadir=[b_ano, b_mes, b_dia, "LPM",est_ano,dia_sem] for i in range(1,25): _anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir # TX if((self.nodos_df[indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="TX")).any() == False: print("No existe la fila") fila_anadir=[b_ano, b_mes, b_dia, "TX",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir # RX if((self.nodos_df[indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="RX")).any() == False: print("No existe la fila") fila_anadir=[b_ano, b_mes, b_dia, "RX",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir # PERIODO if((self.nodos_df[indice_nodo]['ano']==b_ano)

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 111
&(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="periodo")).any() == False: print("No existe la fila") fila_anadir=[b_ano, b_mes, b_dia, "periodo",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir # I_media if((self.nodos_df[indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="I_MEDIA")).any() == False: print("No existe la fila") fila_anadir=[b_ano, b_mes, b_dia, "I_MEDIA",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir # CAPACIDAD if((self.nodos_df[indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="C_bateria")).any() == False: print("No existe la fila") fila_anadir=[b_ano, b_mes, b_dia, "C_bateria",est_ano,dia_sem] for i in range(1,25): fila_anadir.append(-2) self.nodos_df[indice_nodo].loc[len( self.nodos_df[indice_nodo])] = fila_anadir # CPU df_CPU_i = self.nodos_df[indice_nodo][( self.nodos_df[indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]["dia"]==b_dia) &(self.nodos_df[indice_nodo][ "tipo_dato"]=="CPU")].index[-1] self.nodos_df[indice_nodo].loc[df_CPU_i,str(b_hora)] = b_CPU - self.nodos_dic[indice_nodo]['ult_CPU'] #LPM df_LPM_i = self.nodos_df[indice_nodo][(self.nodos_df[ indice_nodo]["ano"]==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="LPM")].index[-1] if self.nodos_dic[indice_nodo]['d_len']==1: self.nodos_df[indice_nodo].loc[df_LPM_i,str(b_hora)] = 3600 - (self.nodos_df[indice_nodo].loc[ df_CPU_i,str(b_hora)]) elif self.nodos_dic[indice_nodo]['d_len']==2: self.nodos_df[indice_nodo].loc[df_LPM_i,str(b_hora)] = 3600*2 - (self.nodos_df[indice_nodo].loc[ df_CPU_i,str(b_hora)]) elif self.nodos_dic[indice_nodo]['d_len']==3: self.nodos_df[indice_nodo].loc[df_LPM_i,str(b_hora)] = 3600*3 - (self.nodos_df[indice_nodo].loc[ df_CPU_i,str(b_hora)])

Anexo 1
ETSII UPM 112
elif self.nodos_dic[indice_nodo]['d_len']==4: self.nodos_df[indice_nodo].loc[df_LPM_i,str(b_hora)] = 3600*4 - (self.nodos_df[indice_nodo].loc[ df_CPU_i,str(b_hora)]) elif self.nodos_dic[indice_nodo]['d_len']==5: self.nodos_df[indice_nodo].loc[df_LPM_i,str(b_hora)] = 3600*5 - (self.nodos_df[indice_nodo].loc[ df_CPU_i,str(b_hora)]) elif self.nodos_dic[indice_nodo]['d_len']==6: self.nodos_df[indice_nodo].loc[df_LPM_i,str(b_hora)]= 3600*6 - (self.nodos_df[indice_nodo].loc[ df_CPU_i,str(b_hora)]) # TX df_TX_i = self.nodos_df[indice_nodo][(self.nodos_df[ indice_nodo]["ano"]==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="TX")].index[-1] self.nodos_df[indice_nodo].loc[df_TX_i,str(b_hora)] = b_TX - self.nodos_dic[indice_nodo]['ult_TX'] # RX df_RX_i = self.nodos_df[indice_nodo][(self.nodos_df[ indice_nodo]["ano"]==b_ano) &(self.nodos_df[indice_nodo]["mes"]==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="RX")].index[-1] self.nodos_df[indice_nodo].loc[df_RX_i,str(b_hora)] = b_RX - self.nodos_dic[indice_nodo]['ult_RX'] # PERIODO df_periodo_i = self.nodos_df[indice_nodo][(self.nodos_df[ indice_nodo]["ano"]==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="periodo")].index[-1] self.nodos_df[indice_nodo].loc[df_periodo_i,str(b_hora)] = self.nodos_df[indice_nodo].loc[df_CPU_i,str(b_hora)] + self.nodos_df[indice_nodo].loc[df_LPM_i,str(b_hora)] # I_MEDIA df_Imedia_i = self.nodos_df[indice_nodo][(self.nodos_df[ indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="I_MEDIA")].index[-1] I_media = (I_sky[0]*self.nodos_df[indice_nodo].loc[ df_CPU_i,str(b_hora)]+I_sky[1]*self.nodos_df[ indice_nodo].loc[df_LPM_i,str(b_hora)]+I_sky[2] *self.nodos_df[indice_nodo].loc[df_TX_i,str(b_hora)]+ I_sky[3]*self.nodos_df[indice_nodo].loc[df_RX_i, str(b_hora)])/self.nodos_df[indice_nodo].loc[ df_periodo_i,str(b_hora)] self.nodos_df[indice_nodo].loc[df_Imedia_i, str(b_hora)] = I_media # CAPACIDAD df_i = self.nodos_df[indice_nodo][(self.nodos_df[ indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="C_bateria")].index[-1]

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 113
self.nodos_df[indice_nodo].loc[df_i,str(b_hora)] = k_bateria * self.nodos_dic[indice_nodo]['ult_C']- I_media*self.nodos_df[indice_nodo].loc[ df_periodo_i,str(b_hora)]/(60*60) self.nodos_dic[indice_nodo]['ult_ano'] = b_ano self.nodos_dic[indice_nodo]['ult_mes'] = b_mes self.nodos_dic[indice_nodo]['ult_dia'] = b_dia self.nodos_dic[indice_nodo]['ult_hora'] = b_hora self.nodos_dic[indice_nodo]['ult_CPU'] = b_CPU self.nodos_dic[indice_nodo]['ult_LPM'] = b_LPM self.nodos_dic[indice_nodo]['ult_TX'] = b_TX self.nodos_dic[indice_nodo]['ult_RX'] = b_RX self.nodos_dic[indice_nodo]['ult_C'] = self.nodos_df[indice_nodo].loc[ df_i,str(b_hora)] # COMPROBACION ALG_BAT alg_bat = 1 for i in range(len(self.nodos_dic)): if self.nodos_dic[i]['ult_C'] < 0.5*C0 : alg_bat = 2 df_algbat_i = self.nodos_df[indice_nodo][(self.nodos_df[ indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="ALG_BAT")].index[-1] self.nodos_df[indice_nodo].loc[df_algbat_i, str(b_hora)] = alg_bat # COMPROBACION ALG_PICO AlgPico = 0 # No hay pico consumo de energia if len(self.nodos_df[indice_nodo][self.nodos_df[ indice_nodo]['tipo_dato']=="I_MEDIA"].index)>1: AlgPico_h1 = self.nodos_dic[indice_nodo]['ult_hora'] AlgPico_h2 = 24 AlgPico_I10h = [] AlgPico_T10h = [] AlgPico_horas = 0 for i in range(12): if AlgPico_horas>8: break if AlgPico_h1>0: num = self.nodos_df[indice_nodo].loc[ self.nodos_df[indice_nodo][self.nodos_df[ indice_nodo]['tipo_dato']== "I_MEDIA"].index[-1], str(AlgPico_h1)] if (num!=-2): AlgPico_I10h.insert(0,num) AlgPico_T10h.insert(0,int( self.nodos_df[indice_nodo].loc[ self.nodos_df[indice_nodo][ self.nodos_df[indice_nodo]['tipo_dato'] =="periodo"].index[-1], str(AlgPico_h1)])) AlgPico_horas += int(self.nodos_df[ indice_nodo].loc[self.nodos_df [indice_nodo][self.nodos_df[ ['tipo_dato']=="periodo"].index[-1], indice_nodo]str(AlgPico_h1)])/3600 AlgPico_h1 -= 1 else: if len(self.nodos_df[indice_nodo] [self.nodos_df[indice_nodo] ['tipo_dato']=="I_MEDIA"].index)>1: num=self.nodos_df[indice_nodo].loc[

Anexo 1
ETSII UPM 114
self.nodos_df[indice_nodo][ self.nodos_df[indice_nodo]['tipo_dato'] =="I_MEDIA"].index[-2],str(AlgPico_h2)] if num!=-2: AlgPico_I10h.insert(0,num) AlgPico_T10h.insert(0,int( self.nodos_df[indice_nodo].loc[ self.nodos_df[indice_nodo][ self.nodos_df[indice_nodo][ 'tipo_dato']=="periodo"].index[ -2], str(AlgPico_h2)])) AlgPico_horas += int(self.nodos_df[indice_nodo].loc[ self.nodos_df[indice_nodo][ self.nodos_df[indice_nodo][ 'tipo_dato']=="periodo"].index[ -2], str(AlgPico_h2)])/3600 AlgPico_h2 -= 1 else: break # Imedia de mínimo 8 horas de simulacion AlgPico_Imedia = 0 for i in range(len(AlgPico_I10h)): AlgPico_Imedia += AlgPico_I10h[i] *AlgPico_T10h[i]/3600 AlgPico_Imedia = AlgPico_Imedia/AlgPico_horas # ¿Pico consumo? if AlgPico_Imedia>4: self.nodos_dic[indice_nodo]['pico_consumo'] = 1 else: self.nodos_dic[indice_nodo]['pico_consumo'] = 0 # Comprobacion de si hay algun nodo con un pico de consumo for i in range(len(self.nodos_dic)): if self.nodos_dic[i]==1: AlgPico = 1 df_algpico_i = self.nodos_df[indice_nodo][(self.nodos_df[ indice_nodo]['ano']==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo]['tipo_dato']== "ALG_PICO")].index[-1] self.nodos_df[indice_nodo].loc[ df_algpico_i,str(b_hora)] = AlgPico # LISTA CON ULTIMOS 10 ICs hora_IC=self.nodos_dic[indice_nodo]['ult_hora'] hora2_IC=24 ult_ICs=[] for i in range(10): if hora_IC>0: ult_ICs.insert(0,int(IC_red.loc[ IC_red[IC_red['tipo_dato']== "IC"].index[-1], str(hora_IC)])) hora_IC-=1 else: if len(IC_red[IC_red['tipo_dato']=="IC"].index)>1: ult_ICs.insert(0,int(IC_red.loc[IC_red[ IC_red['tipo_dato']=="IC"].index[-2], str(hora2_IC)])) hora2_IC-=1 else: break print("ULTIMOS 10 ICs") print(ult_ICs)

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 115
df_proxmodo_i = self.nodos_df[indice_nodo][(self.nodos_df[ indice_nodo]["ano"]==b_ano) &(self.nodos_df[indice_nodo]['mes']==b_mes) &(self.nodos_df[indice_nodo]['dia']==b_dia) &(self.nodos_df[indice_nodo][ 'tipo_dato']=="PROX_MODO")].index[-1] if (alg_bat==1)&(AlgPico==0): IC_bajo_5=0 IC_bajo_10=0 _alto_5=0 IC_alto_10=0 AlgAux_alto=0 AlgAux_bajo=0 for i in ult_ICs: if ((i<4)&(i!=-2)): IC_bajo_10+=1 if AlgAux_bajo<5: IC_bajo_5+=1 AlgAux_bajo+=1 elif ((i>3)&(i!=-2)): IC_alto_10+=1 if AlgAux_alto<5: IC_alto_5+=1 AlgAux_alto+=1 print("IC_bajo_5: "+str(IC_bajo_5)) print("IC_bajo_10: "+str(IC_bajo_10)) print("IC_alto_5: "+str(IC_alto_5)) print("IC_alto_10: "+str(IC_alto_10)) prox_modo = self.nodos_dic[indice_nodo]['modo'] if (len(ult_ICs)<5): prox_modo = 2 elif ((self.nodos_dic[indice_nodo]['modo']==2)& (IC_alto_5>4)): condicion1 = (self.nodos_dic[indice_nodo]['sensor']=='O3') & ((self.nodos_df[indice_nodo].iloc[-1,4]==0)| (self.nodos_df[indice_nodo].iloc[-1,4]==3)) condicion2 = (self.nodos_dic[indice_nodo]['sensor']=='NO2')& ((self.nodos_df[indice_nodo].iloc[-1,4]==1)| (self.nodos_df[indice_nodo].iloc[-1,4]==2))& (self.nodos_dic[indice_nodo]['ult_hora']<12)& (self.nodos_dic[indice_nodo]['ult_hora']>2) condicion3 = (self.nodos_dic[indice_nodo]['sensor']=='NO2')& ((self.nodos_df[indice_nodo].iloc[-1,5]== 'Saturday') |( self.nodos_df[indice_nodo].iloc [-1,5]=='Sunday')) condicion4 = (self.nodos_dic[indice_nodo]['sensor']=='SO2') if (condicion1|condicion2|condicion3|condicion4): prox_modo = 4 else: prox_modo = 3 elif ((self.nodos_dic[indice_nodo]['modo']==3)): if IC_bajo_10>=2: prox_modo = 2 elif IC_alto_10==10: prox_modo = 4 elif (self.nodos_dic[indice_nodo]['modo']==4): if (IC_bajo_10>=2): prox_modo = 2 elif (IC_bajo_5>=1): prox_modo = 3 elif (alg_bat==2)|(AlgPico==1): IC_bajo_6 = 0

Anexo 1
ETSII UPM 116
IC_alto_6 = 0 for i in ult_ICs[:6]: if (i>3)&(i!=-2): IC_alto_6 += 1 if (i<4)&(i!=-2): IC_bajo_6 += 1 if (len(ult_ICs)<6): prox_modo = 2 # PASO DEL 2 al 4 elif ((self.nodos_dic[indice_nodo]['modo']==2) &(IC_alto_6>3)): # 4/6 bien o mejor prox_modo = 4 # PASO DEL 4 al 3 elif ((self.nodos_dic[indice_nodo]['modo']==4) &(IC_bajo_6>2)): # 3/6 regular o peor prox_modo = 3 # PASO DEL 3 al 2 elif ((self.nodos_dic[indice_nodo]['modo']==3) &(IC_bajo_6>3)): # 4/6 regular o peor prox_modo = 2 # PASO DEL 3 al 4 elif ((self.nodos_dic[indice_nodo]['modo']==3) &(IC_alto_6>3)): # 4/6 regular o peor prox_modo = 4 else: # ICs muy bueno o bueno prox_modo = self.nodos_dic[indice_nodo]['modo'] self.nodos_df[indice_nodo].loc[df_proxmodo_i,str(b_hora)] = prox_modo self.nodos_dic[indice_nodo]['modo'] = prox_modo logging.info("PROX MODO:"+str(prox_modo)) self.text = "b,"+str(prox_modo) sock.sendto(self.text, (address, port_send)) logging.info("Thread "+str(name) +", mensaje enviado: " +self.text) for i in range(len(self.nodos_dic)): print("\n NODO "+str(i)+" con direccion " +str(self.nodos_dic[i]['direccion'])) print(self.nodos_df[i]) self.nodos_df[i].to_csv( 'simulacion_nodo_'+str(i)+'.csv', header=True, index=False) print("\n IC DE LA RED") print(IC_red) IC_red.to_csv("IC_red.csv", header=True, index=False) print("\n") for i in range(len(self.nodos_dic)): print("NODO: "+str(i)+" MODO: "+ str(self.nodos_dic[i]['modo'])) logging.info("Thread %s: finishing", name) if __name__ == "__main__": format = "%(asctime)s: %(message)s" logging.basicConfig(format=format, level=logging.INFO, datefmt="%H:%M:%S") database = Database_Class() logging.info("El valor inicial de la temperatura es: %s", database.msg) logging.info("Main : before creating thread") x = threading.Thread(target=database.thread_communication, args=(1,)) y = threading.Thread(target=database.thread_task, args=(2,)) logging.info("Main : before running thread") x.start() y.start() logging.info("Main : wait for the thread to finish") # x.join() logging.info("Main : all done")

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 117
Anexo 1.5: Código en C con el que se programan los nodos enlace #include "contiki.h" #include "net/routing/routing.h" #include "random.h" #include "net/netstack.h" #include "net/ipv6/simple-udp.h" #include "sys/log.h" #define LOG_MODULE "App" #define LOG_LEVEL LOG_LEVEL_INFO #define WITH_SERVER_REPLY 1 #define UDP_CLIENT_PORT 8765 #define UDP_SERVER_PORT 5678 #define SEND_INTERVAL (60 *20* CLOCK_SECOND) static struct simple_udp_connection udp_conn; /*------------------------------------------------------------------*/ PROCESS(udp_client_process, "UDP client"); AUTOSTART_PROCESSES(&udp_client_process); /*------------------------------------------------------------------*/ static void udp_rx_callback(struct simple_udp_connection *c, const uip_ipaddr_t *sender_addr, uint16_t sender_port, const uip_ipaddr_t *receiver_addr, uint16_t receiver_port, const uint8_t *data, uint16_t datalen) { #if LLSEC802154_CONF_ENABLED LOG_INFO_(" LLSEC LV:%d", uipbuf_get_attr(UIPBUF_ATTR_LLSEC_LEVEL)); #endif LOG_INFO_("\n"); } /*------------------------------------------------------------------*/ PROCESS_THREAD(udp_client_process, ev, data) { static struct etimer periodic_timer; PROCESS_BEGIN(); /* Initialize UDP connection */ simple_udp_register(&udp_conn, UDP_CLIENT_PORT, NULL, UDP_SERVER_PORT, udp_rx_callback); etimer_set(&periodic_timer, random_rand() % SEND_INTERVAL); while(1) { PROCESS_WAIT_EVENT_UNTIL(etimer_expired(&periodic_timer)); etimer_set(&periodic_timer, SEND_INTERVAL); } PROCESS_END(); }

Anexo 1
ETSII UPM 118

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 119
Anexo 2 Anexo 2.1: Código Python para el preprocesado de las mediciones de
contaminación atmosférica aportadas por el Ayuntamiento de Madrid # Importación de librerías import pandas as pd import os # DATOS AIRE 2019 aire_19 = pd.read_csv('2019/dic_mo19.csv', header = 0, delimiter=';') meses=["ene", "feb", "mar", "abr", "may", "jun", "jul", "ago", "sep", "oct", "nov", "dic"] for mes in meses[0:11]: nombre="2019/"+str(mes)+"_mo19.csv" df1 = pd.read_csv(nombre, header = 0, delimiter=';') aire_19=pd.concat([aire_19, df1], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True) aire_19.drop(['PUNTO_MUESTREO'], axis='columns', inplace=True) aire_19.to_csv("Años Agrupados/aire_19.csv", index=False) # DATOS AIRE 2018 aire_18=pd.DataFrame() for valor in os.listdir("2018"): if valor[-3:]=="txt": nombre = "2018/" + valor df1 = pd.read_csv(nombre, header=None) df1.drop([4,5], axis='columns', inplace=True) df1.columns=aire_19.columns aire_18=pd.concat([aire_18, df1], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True) aire_18.to_csv("Años Agrupados/aire_18.csv", index=False) # DATOS AIRE 2017 aire_17=pd.DataFrame() widths=[2, 3, 3, 2, 2, 2, 2, 2, 2, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1] for valor in os.listdir("2017"): if valor[-3:]=="txt": nombre = "2017/" + valor df1 = pd.read_csv(nombre, names=['importada']) df2=pd.DataFrame(columns=aire_18.columns) for j in range(len(df1)): prueba=[] prueba.append(df1['importada'][j][sum(widths[0:0]):sum(widths[0:1])]) prueba.append(df1['importada'][j][sum(widths[0:1]):sum(widths[0:2])]) prueba.append(df1['importada'][j][sum(widths[0:2]):sum(widths[0:3])]) prueba.append(df1['importada'][j][sum(widths[0:3]):sum(widths[0:4])]) for i in range(6,len(widths)): prueba.append(df1['importada'][j][sum(widths[0:i]):sum(widths[0:i+1])]) df2.loc[j]=prueba aire_17=pd.concat([aire_17, df2], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True) for valor in os.listdir("2017/txt_coma_17"): if valor[-3:]=="txt": nombre = "2017/txt_coma_17/" + valor df1 = pd.read_csv(nombre, header=None) df1.drop([4,5], axis='columns', inplace=True)

Anexo 2
ETSII UPM 120
df1.columns=aire_19.columns aire_17=pd.concat([aire_17, df1], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True) # Exporto como CSV el dataframe ya que tarda en procesarse aire_17.to_csv("Años Agrupados/aire_17.csv", index=False) # DATOS AIRE 2016 aire_16 = pd.DataFrame() widths=[2, 3, 3, 2, 2, 2, 2, 2, 2, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1] for valor in os.listdir("2016"): if valor[-3:]=="txt": nombre = "2016/" + valor df1 = pd.read_csv(nombre, names=['importada']) df2=pd.DataFrame(columns=aire_18.columns) for j in range(len(df1)): prueba=[] prueba.append(df1['importada'][j][sum(widths[0:0]):sum(widths[0:1])]) prueba.append(df1['importada'][j][sum(widths[0:1]):sum(widths[0:2])]) prueba.append(df1['importada'][j][sum(widths[0:2]):sum(widths[0:3])]) prueba.append(df1['importada'][j][sum(widths[0:3]):sum(widths[0:4])]) for i in range(6,len(widths)): prueba.append(df1['importada'][j][sum(widths[0:i]):sum(widths[0:i+1])]) df2.loc[j]=prueba aire_16=pd.concat([aire_16, df2], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True) aire_16.to_csv("Años Agrupados/aire_16.csv", index=False) # DATOS AIRE 2015 aire_15 = pd.DataFrame() widths=[2, 3, 3, 2, 2, 2, 2, 2, 2, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1] for valor in os.listdir("2015"): if valor[-3:]=="txt": nombre = "2015/" + valor df1 = pd.read_csv(nombre, names=['importada']) df2=pd.DataFrame(columns=aire_18.columns) for j in range(len(df1)): prueba=[] prueba.append(df1['importada'][j][sum(widths[0:0]):sum(widths[0:1])]) prueba.append(df1['importada'][j][sum(widths[0:1]):sum(widths[0:2])]) prueba.append(df1['importada'][j][sum(widths[0:2]):sum(widths[0:3])]) prueba.append(df1['importada'][j][sum(widths[0:3]):sum(widths[0:4])]) for i in range(6,len(widths)): prueba.append(df1['importada'][j][sum(widths[0:i]):sum(widths[0:i+1])]) df2.loc[j]=prueba aire_15=pd.concat([aire_15, df2], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True) aire_15.to_csv("Años Agrupados/aire_15.csv", index=False) # DATOS AIRE 2014 aire_14 = pd.DataFrame()

Computation Offloading en IoT para aplicaciones medioambientales
BENJAMÍN SÁNCHEZ LLORÉNS 121
widths=[2, 3, 3, 2, 2, 2, 2, 2, 2, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1] for valor in os.listdir("2014"): if valor[-3:]=="txt": nombre = "2014/" + valor df1 = pd.read_csv(nombre, names=['importada']) df2=pd.DataFrame(columns=aire_18.columns) for j in range(len(df1)): prueba=[] prueba.append(df1['importada'][j][sum(widths[0:0]):sum(widths[0:1])]) prueba.append(df1['importada'][j][sum(widths[0:1]):sum(widths[0:2])]) prueba.append(df1['importada'][j][sum(widths[0:2]):sum(widths[0:3])]) prueba.append(df1['importada'][j][sum(widths[0:3]):sum(widths[0:4])]) for i in range(6,len(widths)): prueba.append(df1['importada'][j][sum(widths[0:i]):sum(widths[0:i+1])]) df2.loc[j]=prueba aire_14=pd.concat([aire_14, df2], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True) aire_14.to_csv("Años Agrupados/aire_14.csv", index=False) # DATOS AIRE 2013 aire_13 = pd.DataFrame() widths=[2, 3, 3, 2, 2, 2, 2, 2, 2, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1] for valor in os.listdir("2013"): if valor[-3:]=="txt": nombre = "2013/" + valor df1 = pd.read_csv(nombre, names=['importada']) df2=pd.DataFrame(columns=aire_18.columns) for j in range(len(df1)): prueba=[] prueba.append(df1['importada'][j][sum(widths[0:0]):sum(widths[0:1])]) prueba.append(df1['importada'][j][sum(widths[0:1]):sum(widths[0:2])]) prueba.append(df1['importada'][j][sum(widths[0:2]):sum(widths[0:3])]) prueba.append(df1['importada'][j][sum(widths[0:3]):sum(widths[0:4])]) for i in range(6,len(widths)): prueba.append(df1['importada'][j][sum(widths[0:i]):sum(widths[0:i+1])]) df2.loc[j]=prueba aire_13=pd.concat([aire_13, df2], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True) aire_13.to_csv("Años Agrupados/aire_13.csv", index=False) # DATOS AIRE 2012 aire_12 = pd.DataFrame() widths=[2, 3, 3, 2, 2, 2, 2, 2, 2, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1] for valor in os.listdir("2012"): if valor[-3:]=="txt": nombre = "2012/" + valor df1 = pd.read_csv(nombre, names=['importada']) df2=pd.DataFrame(columns=aire_18.columns) for j in range(len(df1)): prueba=[]

Anexo 2
ETSII UPM 122
prueba.append(df1['importada'][j][sum(widths[0:0]):sum(widths[0:1])]) prueba.append(df1['importada'][j][sum(widths[0:1]):sum(widths[0:2])]) prueba.append(df1['importada'][j][sum(widths[0:2]):sum(widths[0:3])]) prueba.append(df1['importada'][j][sum(widths[0:3]):sum(widths[0:4])]) for i in range(6,len(widths)): prueba.append(df1['importada'][j][sum(widths[0:i]):sum(widths[0:i+1])]) df2.loc[j]=prueba aire_12=pd.concat([aire_12, df2], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True) aire_12.to_csv("Años Agrupados/aire_12.csv", index=False) # DATOS AIRE 2011 aire_11 = pd.DataFrame() widths=[2, 3, 3, 2, 2, 2, 2, 2, 2, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1] for valor in os.listdir("2011"): if valor[-3:]=="txt": nombre = "2011/" + valor df1 = pd.read_csv(nombre, names=['importada']) df2 = pd.DataFrame(columns=aire_18.columns) for j in range(len(df1)): prueba=[] prueba.append(df1['importada'][j][sum(widths[0:0]):sum(widths[0:1])]) prueba.append(df1['importada'][j][sum(widths[0:1]):sum(widths[0:2])]) prueba.append(df1['importada'][j][sum(widths[0:2]):sum(widths[0:3])]) prueba.append(df1['importada'][j][sum(widths[0:3]):sum(widths[0:4])]) for i in range(6,len(widths)): prueba.append(df1['importada'][j][sum(widths[0:i]):sum(widths[0:i+1])]) df2.loc[j]=prueba aire_11=pd.concat([aire_11, df2], axis=0, join='outer', ignore_index=True, keys=None, levels=None, names=None, verify_integrity=False, copy=True) aire_11.to_csv("Años Agrupados/aire_11.csv", index=False)


















