
Análisis de las prestaciones de distintas técnicas de preprocesado en audio fingerprinting
91
ANÁLISIS DE LAS PRESTACIONES DE ANÁLISIS DE LAS PRESTACIONES DE ANÁLISIS DE LAS PRESTACIONES DE ANÁLISIS DE LAS PRESTACIONES DE DISTINTAS TÉCNICAS DE PREPROCESADO DISTINTAS TÉCNICAS DE PREPROCESADO DISTINTAS TÉCNICAS DE PREPROCESADO DISTINTAS TÉCNICAS DE PREPROCESADO EN AUDIO FINGERPRINTING EN AUDIO FINGERPRINTING EN AUDIO FINGERPRINTING EN AUDIO FINGERPRINTING Tutor: Dr. José Ramón Cerquides. Departamento de Teoría de la Señal y Comunicaciones. Universidad de Sevilla José Serradilla Arellano Universidad de Sevilla Enero-Mayo 2007
-
Upload
jose-ramon-cerquides-bueno -
Category
Documents
-
view
40 -
download
1
Transcript of Análisis de las prestaciones de distintas técnicas de preprocesado en audio fingerprinting

ANÁLISIS DE LAS PRESTACIONES DE ANÁLISIS DE LAS PRESTACIONES DE ANÁLISIS DE LAS PRESTACIONES DE ANÁLISIS DE LAS PRESTACIONES DE
DISTINTAS TÉCNICAS DE PREPROCESADO DISTINTAS TÉCNICAS DE PREPROCESADO DISTINTAS TÉCNICAS DE PREPROCESADO DISTINTAS TÉCNICAS DE PREPROCESADO
EN AUDIO FINGERPRINTINGEN AUDIO FINGERPRINTINGEN AUDIO FINGERPRINTINGEN AUDIO FINGERPRINTING
Tutor: Dr. José Ramón Cerquides. Departamento de Teoría de la Señal y Comunicaciones. Universidad de Sevilla
José Serradilla Arellano Universidad de Sevilla
Enero-Mayo 2007

Índice
1. Audio Fingerprinting: Generalidades………………………………3
1.1- Introducción………………………………………………………………………………….3 1.2- Fundamentos…………………………………………………………………………………3 1.3- Propiedades……………………………………………………………………………………4 1.4- Modos de Uso…………………………………………………………………………………6 1.4.1- Identificación……………………………………………………………………6
1.4.2- Verificación de la Integridad……………………………………………7 1.4.3- Apoyo al Watermarking…………………………………………………..7
1.4.4- Recuperación y procesamiento de audio basados en el contenido…………………………………………………………………………………… 8
1.5- Escenarios de Aplicación……………………………………………………………….8 1.5.1- Monitorización y Seguimiento del Contenido de Audio….8 1.5.2- Servicios de Valor Añadido……………………………………………10 1.5.3- Sistemas de Verificación de Integridad………………………..11 1.6- Alternativas: Audio Watermarking……………………………………………. 11 1.6.1- Semejanzas y diferencias con Audio Fingerprinting…….13 2. Uso de Audio Fingerprinting para Identificación…………… 16 2.1- Repaso de los diversos métodos propuestos…………………………… 16 2.1.1- Extracción de Huellas…………………………………………………...16
2.1.1.1- Front-End……………………………………………… 18 2.1.1.2- Modelado de Huellas……………………………. 21 2.1.2- Distancias y Métodos de Búsqueda……………………………..23 2.1.2.1- Distancias………………………………………………23 2.1.2.2- Métodos de Búsqueda…………………………..23 2.1.3- Comprobación de Hipótesis………………………………………… 25 3. El Sistema de Philips……………………………………………….....26 3.1- Algoritmo…………………………………………………………………………………….27 3.1.1- Algoritmo de extracción…………………………………………………27 3.1.2- Algoritmo de Búsqueda…………………………………………………29 3.2- Análisis Prácticos a Realizar……………………………………………………… 33 3.2.1- Análisis de Falso Positivo………………………………………………34 3.2.2- Análisis Experimental de Robustez……………………………….39 4. Mejoras Propuestas en Preprocesado……………………………45 4.1- Filtrado Paso-bajo……………………………………………………………………… 45 4.1.1- Introducción Teórica……………………………………………………. 45 4.1.2- Resultados Experimentales…………………………………………..46 4.2- Distortion Discriminant Análisis………………………………………………… 51 4.2.1- Introducción Teórica……………………………………………………..51 4.2.2- Primer Paso de Preprocesado……………………………………… 52 4.2.2.1- Análisis de Falso Positivo…………………………………55

4.2.2.2- Análisis Experimental de Robustez…………………56 4.2.3- Segundo Paso de Preprocesado……………………………………59 4.2.3.1- Análisis de Falso Positivo………………………………..59 4.2.3.2- Análisis Experimental de Robustez…………………61 5. Referencias……………………………………………………………… 65 Anexo 1: Funciones usadas para el algoritmo de Philips……..68 Anexo 2: Funciones usadas para el preprocesado de filtrado 78 Anexo 3: Funciones usadas en el preprocesado de DDA………80

1. Audio Fingerprinting: Generalidades
1.1 Introducción Los sistemas de huellas dactilares tienen más de 100 años de antigüedad. En 1893, Sir Francis Galton fue el primero en probar que no hay dos huellas iguales de dos seres humanos distintos. Aproximadamente 19 años después Scotland Yard aceptó un sistema diseñado por Sir Edward Henry para identificar huellas de gente. El sistema se basa en el modelo de surcos dérmicos en las yemas de los dedos y todavía es la base de todas las técnicas de huellas dactilares humanas de hoy en día. Este tipo de sistema de huellas forense ha existido sin embargo durante más de un siglo, ya que hace 2000 años, los emperadores chinos ya usaban las firmas con el pulgar para documentos importantes. La implicación es que ya esos emperadores (o, al menos, sus sirvientes administrativos) se dieron cuenta que cada huella era única. Conceptualmente, una huella puede ser como un resumen o firma “humana” que es única para cada ser humano. Es importante hacer notar que una huella dactilar humana difiere de un resumen textual en que no permite la reconstrucción de otros aspectos del original. Por ejemplo, una huella humana no da ninguna información sobre el color de los ojos o del pelo de la persona. Los últimos años han visto un creciente interés científico e industrial en computar huellas de objetos multimedia. El creciente interés industrial es mostrado entre otros por un gran número de compañías (Auditude, Relatable, Audible Magic, Shazam…) y la reciente demanda de información basada en tecnologías de “audio fingerprinting” por parte de la Federación Internacional de la Industria Fonográfica (IFPI) y de la Asociación de la Industria de Grabación de América (RIAA).
1.2 Fundamentos
La tecnología de “Audio fingerprinting” (o “Huella Dactilar de Audio”) es una firma compacta basada en el contenido que resume una grabación de audio [1]. “Audio fingerprinting” y, en general, todas las tecnologías CBID (“Content-Based Identification” o “Identificación basada en el contenido”) extraen características acústicas relevantes de la señal acústica. Dichas características son únicas para cada señal de audio y, por analogía con las huellas dactilares humanas, son llamadas también huellas dactilares. Una grabación de música o un anuncio solo pueden ser reconocidos si esas características fueron previamente grabadas e introducidas en una base de datos especial.
. Después de la adquisición de estas características ya no es necesario
ningún procesamiento más de la señal. Cuando se implementa la tecnología de “audio fingerprinting”, la señal de audio en sí no es modificada, en particular no se le añade ninguna información adicional. El reconocimiento del título se realiza basándose exclusivamente en el contenido, es decir, basándose sólo en características derivadas de la pista de audio.

Este enfoque difiere de otra solución alternativa existente para
monitorizar contenido de audio, llamada “Audio Watermarking” (literalmente Marca de Agua de Audio). En ella, se realiza una investigación psicoacústica para que un mensaje arbitrario, la marca de agua, pueda ser incrustado en la grabación sin alterar la percepción del sonido.
Usando “fingerprints” y un algoritmo eficiente para buscar
coincidencias en la base de datos, pueden identificarse como el mismo título versiones modificadas o distorsionadas de la misma canción. Dichas modificaciones incluyen, por ejemplo, distorsiones lineales tales como cambios de nivel o limitación de ancho de banda, como pueden darse en el caso de emisiones de radio. Otras modificaciones incluyen distorsiones no lineales, como, por ejemplo, codificación en formato MP3. También pueden reconocerse trozos de material de audio que están incompletos o, incluso, entre varias versiones de una grabación particular, si está grabada en estudio o en directo, y entre varias grabaciones en directo de la misma pieza.
El factor decisivo para la implementación de un proceso de “Audio Fingerprinting” es la selección de las características a investigar. Ser capaces de discernir entre un número elevado de títulos solo es posible si se seleccionan las características adecuadas. Eso sí, al mismo tiempo hay que tener en cuenta que la selección de las características influye directamente en el tamaño de la huella, y, por tanto en el tiempo necesario para identificar un título.
1.3 Propiedades
Los requisitos dependen fuertemente de la aplicación pero son útiles para evaluar y comparar diferentes tecnologías de “audio fingerprinting”.
Una enumeración detallada de los requisitos que pueden ayudarnos a
distinguir entre los distintos enfoques incluye:
• Precisión: El número de identificaciones correctas, identificaciones falsas (falsos positivos) e identificaciones que se pasan por alto.
• Fiabilidad: En la generación de “playlists” o listas de reproducción
para organizaciones de control de copyright es de una importancia capital tener métodos para valorar si un elemento está presente o no en el conjunto de elementos a identificar. En esos casos, si una canción no ha sido emitida, no debería ser identificada como una coincidencia, incluso a costa de obviar verdaderas coincidencias. En otras aplicaciones, como el etiquetado automático de archivos .MP3, evitar falsos positivos no es una necesidad tan perentoria.
• Robustez: Habilidad para identificar con precisión un elemento, sin
importar su nivel de compresión y distorsión o de interferencia en el canal de transmisión. Es también la habilidad de identificar títulos completos a partir de extractos de unos pocos segundos, lo cual requiere métodos para tratar con la falta de sincronización. Otras

fuentes de degradación son la ecualización, ruido de fondo, conversiones A/D y D/A, codificadores de audio (tales como GSM y MP3), etc.
• Seguridad: Vulnerabilidad de una solución a manipulaciones
intencionadas. En contraste con el requerimiento de robustez, las manipulaciones con las que hay que tratar están diseñadas específicamente para engañar al algoritmo de identificación de “fingerprint”.
• Versatilidad: Habilidad para identificar sea cual sea su formato.
Habilidad para usar la misma base de datos para distintas aplicaciones.
• Escalabilidad: Actuación con bases de datos de títulos muy largas o
con un gran número de identificaciones concurrentes. Esto afecta a la precisión y a la complejidad del sistema.
• Complejidad: Se refiere al coste computacional de la extracción de la
huella, al tamaño de la misma, a la complejidad de la comparación, al coste de añadir nuevos elementos a la base de datos, etc.
• Fragilidad: Algunas aplicaciones, tales como sistemas de verificación
de la integridad del contenido, pueden requerir la detección de cambios en el contenido. Esto es contrario al requerimiento de robustez, ya que la huella debería ser robusta a transformaciones en las que se preserva el contenido, pero no a otras distorsiones.
Mejorar un determinado requerimiento implica empeorar cualquier otro.
Generalmente, la huella debería ser:
• Un resumen perceptual de la grabación. La huella debe retener el máximo de información acústicamente relevante. Este resumen debería permitir la discriminación entre un número elevado de huellas. Esto puede entrar en conflicto con otros requerimientos tales como la complejidad o la robustez.
• Invariante a las distorsiones. Esto deriva del requisito de robustez.
Sin embargo, las aplicaciones que vigilan la integridad del contenido relajan esta restricción para las distorsiones que preservan el contenido, con la intención de detectar manipulaciones deliberadas.
• Compacto. Para la complejidad es interesante una representación de
pequeño tamaño, ya que necesitamos almacenar y comparar un gran número de huellas (puede que millones, depende de la aplicación). Sin embargo, un tamaño de representación excesivamente corto puede no ser suficiente para discriminar entre grabaciones, afectando a la precisión, fiabilidad y robustez.
• Fácilmente computable. Por razones de complejidad, la extracción de
la huella no debería consumir demasiado tiempo.

1.4 Modos de uso 1.4.1 Identificación Independientemente del enfoque específico para extraer la firma compacta basada en el contenido, se puede observar una arquitectura común para describir la funcionalidad del “fingerprinting” cuando se usa para identificación. El funcionamiento general mimetiza la manera en la que los humanos realizan la tarea. Como se ve en la fig. 1, se realiza en dos niveles, creación de la base de datos e identificación en si misma:
-Creación de la base de datos: La colección de trabajos que se pretende reconocer es presentada al sistema para la extracción de su huella. Las huellas son almacenadas en la base de datos y pueden ser enlazadas a una etiqueta o a otros metadatos relevantes para cada grabación. -Identificación: El audio sin etiquetar es procesado para extraer la huella. Ésta es comparada con las huellas de la base de datos. Si se encuentra una coincidencia, se obtiene la etiqueta asociada al trabajo que estaba en la base de datos. También se puede realizar una medida de la fiabilidad de dicha coincidencia. La diferencia entre unos y otros enfoques del problema se encuentra en las características de audio que se observan, además de en los algoritmos de búsqueda e indexado que se usan. Entre las características a estudiar podemos nombrar: energía, volumen, centroide espectral, tasa de cruces por cero, tono, armonicidad, monotonía espectral, coeficientes Mel-Cepstrum, etc. Los algoritmos pueden ir desde la comparación directa, extrayendo un “hash” del archivo binario y usando alguna representación compacta como el CRC (código de redundancia cíclico) para almacenarlo en la base hasta otros algoritmos más complejos y robustos (a veces basados también en “hash”) que estudiaremos más detalladamente más adelante.

1.4.2 Verificación de la integridad La verificación de la integridad pretende detector la alteración de los datos. El funcionamiento general es similar al de identificación (ver fig.2). Primero, se extrae la huella del audio original. En la fase de verificación, la huella extraída de la señal de prueba es comparada con la huella de la original. Como resultado, se da como salida un informe indicando si la señal ha sido manipulada o no. Opcionalmente el sistema puede indicar el tipo de manipulación y donde ha ocurrido dentro del audio. Los datos de verificación, que deberían ser significativamente más pequeños que los datos de audio, pueden ser enviados junto a los anteriores (por ejemplo, en una cabecera) o almacenados en una base de datos. Una técnica, conocida como “auto-incrustación” evita la necesidad de una base de datos o una cabecera especialmente dedicada incrustando la firma basada en el contenido en los datos de audio usando “watermarking” [2].
1.4.3 Apoyo al “Watermarking” La técnica de “Audio Fingerprinting” puede asistir a la de “watermarking”. La huella de audio puede ser usada para obtener claves secretas a partir del contenido presente. Como se describe en [3], usar la misma clave secreta para una serie de elementos de audio distintos puede comprometer la seguridad, ya que cada elemento puede filtrar información parcial sobre la clave. La codificación “hash” perceptual puede ayudar a generar claves dependientes de la entrada para cada pieza de audio. Un ámbito donde puede ser usado el “audio fingerprinting” para mejorar la seguridad de las marcas de agua es en el intento de hacer copias ilegales [4]. En estos casos se intenta estimar una marca de un contenido “marcado” y transplantarla a un contenido “no marcado”. Además puede usarse “fingerprinting” para combatir intentos de inserción o borrado de contenido que causan una desincronización de la detección: usando la huella, el detector es capaz de encontrar “puntos ancla” en el flujo de audio y resincronizarse en ellos [3].

1.4.4 Recuperación y procesamiento de audio basados en el contenido Obtener firmas compactas a partir de objetos multimedia complejos e índices potentes para buscar contenidos es un asunto esencial en Recuperación de Información Multimedia. La técnica de “fingerprinting” puede extraer información de la señal de audio en diferentes niveles de abstracción, desde descriptores de bajo nivel hasta descriptores de alto nivel. Especialmente las abstracciones de alto nivel para modelar audio nos dan la posibilidad de extender los modos de uso de dicha técnica a la navegación basada en el contenido, la búsqueda por similaridad, procesamiento basado en el contenido y otras aplicaciones de Recuperación de Información de Música. Adaptar los eficientes sistemas actuales de la identificación a la búsqueda de similaridad puede tener un significativo impacto en la industria musical. Antes, los proveedores de música on-line ofrecen una búsqueda por datos editoriales (artista, título, etc.). Con “fingerprinting” podría usarse la huella de una canción para encontrar no solo la versión original de dicha canción, sino otras versiones similares de la misma.
1.5 Escenarios de aplicación Aquí vamos a presentar algunos usos particulares de la tecnología de “fingerprinting”, la mayoría de ellos son casos particulares del modo de uso de identificación ya descrito. Se basan en la habilidad del “audio fingerprinting” de unir audio sin etiquetar a sus correspondientes meta-datos, sea cual sea el formato del audio. 1.5.1 Monitorización y Seguimiento del contenido de audio Un sistema de monitorización a gran escala basado en huellas consiste en varios puntos de monitorización y en un lugar central de monitorización donde se encuentra el servidor de huellas. En los puntos de monitorización, se extraen las huellas de todos los canales de emisión (locales). El sitio central recoge las huellas de los puntos de monitorización. Posteriormente, el servidor, que contiene una enorme base de datos de huellas, produce las listas de reproducción de todos los canales de emisión. En el lado del distribuidor Los distribuidores de contenido pueden necesitar saber si tienen los derechos o no para difundir el contenido a los consumidores. La huella puede ayudar a identificar audio sin etiquetar en los archivos de canales de TV y radio. También puede identificar contenido sacado de CDs de fábrica y distribuidores en investigaciones anti-piratería (por ejemplo, avances de grabaciones sin masterizar en plantas de fabricación de CDs).

En el canal de transmisión En muchos países, las emisoras de radio deben pagar derechos de autor por la música que emiten. Los poseedores de los derechos necesitan monitorizar las transmisiones para verificar si dichos derechos están siendo pagados apropiadamente o no. Incluso en los países donde las emisoras pueden emitir música gratuitamente, los poseedores están interesados en monitorizarlas con objetivos estadísticos. Los anunciadores también necesitan monitorizar las transmisiones de radio y TV para verificar si sus anuncios están siendo difundidos según lo acordado. Lo mismo se puede aplicar a emisoras web. Otros usos incluyen compilaciones para análisis estadístico o refuerzo de “leyes culturales” (por ejemplo, las canciones francesas en Francia). Para todos estos propósitos actualmente se están usando sistemas de monitorización basados en el “fingerprinting”. El sistema “escucha” la radio y continuamente actualiza una lista de reproducción de canciones o anuncios emitidos por cada emisora. Por supuesto, debe estar disponible para el sistema una base de datos que contenga las huellas de todas las canciones y anuncios que se pretenden identificar, y dicha base de datos debe ser actualizada con las nuevas canciones que salgan. Ejemplos de proveedores comerciales de este servicio son: Broadcast Data System, Music Reporter, Audible Magic o Yacast. Napster y otras comunidades parecidas, donde los usuarios intercambian música, han sido excelentes canales para la piratería musical. Después de una batalla judicial con la industria musical, a Napster se le prohibió facilitar la transferencia de música con copyright. La primera medida que se tomó conforme al mandato judicial fue la introducción de un sistema de filtrado basado en el análisis del nombre de los archivos, de acuerdo con listas de grabaciones de música con copyright aportadas por las compañías discográficas. Pero este simple sistema no solucionó el problema, ya que los usuarios demostraros ser extremadamente creativos para escoger títulos de canciones que “torearan” el sistema, pero permitiendo a los otros usuarios una identificación fácil. Además, el elevado número de canciones con títulos idénticos fue un factor adicional que redujo la eficiencia de dichos filtros. Los sistemas de monitorización basada en las huellas constituyen una solución bastante apropiada al problema. De hecho, Napster adoptó una nueva tecnología de “fingerprinting” y un nuevo sistema de filtrado de archivos basados en ella. Además, se puede encontrar contenido de audio en páginas web ordinarias. El “audio fingerprinting” combinado con un “web crawler” (“araña de la web”, que inspecciona las páginas del World Wide Web de forma sistemática y automatizada) puede identificar este contenido e informar a los correspondientes poseedores de los derechos. En el extremo del consumidor En aplicaciones de monitorización de la política de uso, el objetivo es evitar un mal uso de las señales de audio por parte del consumidor. Podemos concebir un sistema donde una pieza de música es identificada por medio de una huella, y se mira en una base de datos para obtener información sobre sus derechos. La información dicta el comportamiento del dispositivo en el que se va a reproducir (por ejemplo, lectores y grabadores

de CD y DVD, reproductores de MP3 o incluso ordenadores), de acuerdo con la política de uso. Dichos dispositivos necesitan estar conectados a una red para poder tener acceso a la base de datos. 1.5.2 Servicios de valor añadido La información del contenido se define como información sobre un extracto de audio que es relevante para el usuario o necesario para la aplicación pretendida. Dependiendo de la aplicación y del perfil del usuario, se pueden definir varios niveles de información de contenido. Estas son algunas de las situaciones que podemos imaginar:
• Información de contenido describiendo un extracto de audio, tales como descripciones rítmicas, armónicas y melódicas.
• Metadatos describiendo un trabajo musical, como fue compuesto y como fue grabado. Por ejemplo: compositor, año de composición, intérprete, fecha de la actuación, grabación en estudio/actuación en directo…
• Otras informaciones concernientes a un trabajo musical, tales como la imagen de la portada del álbum, precio del mismo, biografía del artista, información de los próximos conciertos, etc.
Se pueden definir distintos perfiles. Los usuarios normales estarían
interesados en informaciones generales sobre un trabajo musical, tales como el título, compositor, sello discográfico y año de edición; los músicos podrían estar interesados en qué instrumentos se han utilizado, los ingenieros de sonido podrían estar interesados en informaciones sobre el proceso de grabación. La información de contenido puede ser estructurada por medio de un esquema de descripción de música (MusicDS), que es una estructura de metadatos usada para describir y anotar datos de audio. El estándar MPEG-7 propone un esquema de descripción para contenido multimedia basado en el metalenguaje XML, aportando un intercambio de datos fácil entre distintos equipos.
Algunos sistemas almacenan información de contenido en una base de
datos que es accesible a través de Internet. La huella puede ser pues usada para identificar una grabación y obtener la correspondiente información de contenido, sin tener en cuenta el tipo de soporte, formato de archivo o cualquier otra particularidad de los datos de audio. Por ejemplo, MusicBrainz, Id3man o Moodlogic etiquetan automáticamente colecciones de archivos de audio; el usuario puede descargar un reproductor compatible que extrae las huellas y las manda a un servidor central desde donde se descargan los metadatos asociados a las grabaciones. Gracenote, quien ha estado proveyendo enlaces a metadatos de música basados en la tabla de contenidos (TOC) de un CD, empezó a ofrecer tecnología de “audio fingerprinting” para extender el enlace hasta el nivel de canción. Su método de identificación de audio se usa en combinación con clasificadores basados en texto para aumentar la precisión. Todo esto se puede usar para organizar una “biblioteca” musical dentro de cada ordenador. Hoy en día muchos usuarios de PCs tienen una biblioteca musical que contiene varios cientos, incluso miles de canciones. La música está almacenada

normalmente en formato comprimido (por ejemplo MP3) en sus discos duros. Cuando esas canciones se obtienen de otras fuentes, tales como “ripeadas” de un CD o descargadas de una red de intercambio de archivos, estas librerías habitualmente no están bien organizadas. Los metadatos son inconsistentes, incompletos y, a veces, incluso inexistentes. Asumiendo que la base de datos de huellas contiene metadatos correctos, la tecnología de “audio fingerprinting” puede hacer consistentes los metadatos de las canciones de la librería, permitiendo una fácil organización basada, por ejemplo en disco o artista.
Otro ejemplo es la identificación de una melodía mediante dispositivos
móviles, por ejemplo un teléfono móvil; es una de las situaciones más exigentes en términos de robustez, ya que la señal de audio viaja a través de distorsión de radio, conversiones A/D y D/A, ruido de fondo y codificación GSM, distorsión del canal de comunicación móvil y sólo están disponibles unos pocos segundos de audio.
Otro posible ejemplo podrían ser las radios de los coches que ofrecen un
botón de identificación.
1.5.3 Sistemas de verificación de Integridad En algunas aplicaciones, la integridad de las grabaciones de audio debe ser establecida antes de que la señal pueda ser de hecho usada, es decir, uno debe asegurar que la grabación no ha sido modificada o que no está demasiado distorsionada: Si la señal sufre compresión con pérdidas, conversiones A/D o D/A, u otras transformaciones que preservan el contenido en el canal de transmisión, la integridad no puede ser comprobada por medio de funciones de “hash” estándar, ya que el mínimo cambio en un solo bit es suficiente para que la salida de la función cambie. Los métodos basados en la marca de agua pueden ofrecer falsas alarmas en este contexto. Los sistemas basados en “audio fingerprinting”, a veces combinados con “watermarking” están siendo investigados para afrontar este problema [2]. Entre algunas posibles aplicaciones podemos nombrar: comprobar que los anuncios son emitidos con la calidad y longitud requeridas, verificar que una grabación supuestamente infractora es de hecho la misma que una cuyo dueño es conocido, etc.
1.6 Alternativas: Audio Watermarking
Durante siglos, el uso de documentos con marca de agua impresa para evitar falsificaciones ha sido una práctica habitual. Por analogía, el término “Watermarking” también es habitualmente usado para describir métodos que pretenden marcar imperceptiblemente documentos digitales (imágenes, audio o video) [5].
Las primeras investigaciones en “audio watermarking” datan de
mediados de los años 90 [6]. La idea básica consiste en añadir una señal, la marca de agua, a la señal original de audio. La señal resultante debe ser

percibida por el oyente como idéntica a la original. La marca de agua transporta datos que pueden ser recuperados por un detector y ser usados para una multitud de objetivos.
Al igual que los sistemas de “audio fingerprinting”, estos sistemas
deben cumplir una serie de propiedades, que frecuentemente dependen de la aplicación y entran en conflicto unas con otras. En general podemos nombrar: inaudibilidad, robustez, capacidad, fiabilidad y baja complejidad. Como ya hemos dicho, dichos requisitos dependen de la aplicación. Así, por ejemplo, algunas aplicaciones (como el audio en Internet, con baja tasa de bit) pueden admitir que la marca de agua añada una pequeña degradación de la calidad de la señal, mientras que otras (como audio con alta tasa de bit) deben ser extremadamente rigurosas con este asunto.
En general, podemos ver este sistema como un sistema de comunicaciones: la marca de agua es la señal de información y la señal de audio hace el papel de ruido del canal. En los sistemas de comunicación convencionales la señal útil es normalmente más fuerte que el ruido, que normalmente se asume que es blanco y gaussiano. Aquí este no es el caso. Para evitar la distorsión audible, la señal de marca de agua debe ser mucho más débil (decenas de decibelios) que la señal de audio. Además, la señal de audio generalmente no es estacionaria y es fuertemente coloreada. En la literatura han sido propuestos varios enfoques para “audio watermarking”:
- De Espectro Ensanchado: Como en los sistemas de comunicación de espectro ensanchado, la idea consiste en ensanchar la “marca de agua” para maximizar su potencia, consiguiendo mantenerla inaudible e incrementar su resistencia a ataques [6].
- “Echo-hiding”: Se explotan las propiedades de enmascaramiento
temporal para mantener la “marca de agua” inaudible. La marca es un “eco” de la señal original [7].
- En la Cadena de Bits: La marca es insertada directamente en el
flujo de bits generado por un codificador de audio. Se han propuesto muchas variantes de estos esquemas básicos. Por
ejemplo, en vez de añadir la marca en el dominio del tiempo, hacerlo en el de la frecuencia, reemplazando directamente componentes espectrales [8].
Para asegurar la inaudibilidad de la señal se usan modelos
psicoacústicos. Es bien sabido que cuando dos tonos están muy próximos en frecuencia, un tono, si es mucho más fuerte, puede enmascarar al otro. Los modelos se usan para generalizar el efecto de enmascaramiento en frecuencia a señales no tonales. A partir de una señal de audio, se calcula una curva llamada umbral de enmascaramiento, homogénea a una densidad espectral de potencia. La marca se construye modificando en frecuencia una señal aproximadamente blanca según el umbral de audición. Después de esta operación, el PSD de la marca siempre estará por debajo del umbral de audición y no se oirá en presencia de la señal de audio. Se puede conseguir esto con una diferencia de potencia entre la señal y la marca de unos 20 dB.

1.6.1 Semejanzas y diferencias con “audio fingerprinting”
• El “Audio Watermarking” modifica la señal de audio original
incrustando una marca en ella, mientras que el “Audio Fingerprinting” no la cambia en absoluto, sino que la analiza y obtiene un “hash” (la huella) unívocamente asociada a la señal. En “watermarking” hay un compromiso entre la potencia de la “marca” (y su audibilidad) y su capacidad de detección. En “fingerprinting” no existe tal compromiso: el sistema “escucha” el audio, construye una descripción y busca en la base de datos una descripción que coincida.
• Necesidad de un catálogo de huellas: Un oyente humano sólo puede identificar una pieza de música si la ha oído antes, salvo que tenga acceso a algo más que a la señal de audio. Similarmente, los sistemas de “fingerprinting” requieren un conocimiento previo de las señales de audio para poder identificarlas, ya que no hay disponible ninguna información además de la señal en si misma durante la fase de identificación. Por tanto, debe construirse una base de datos, que contenga todas las canciones que se supone que debe identificar el sistema. Mientras más grande sea la base de datos, más requerimientos de memoria y coste computacional serán necesarios, aumentando, por tanto la complejidad del proceso de detección. En contraste a esto, para un sistema de “watermarking” no hace falta base de datos, ya que toda la información asociada a la señal está en la “marca” en sí misma. El detector comprueba la presencia de una marca y, si encuentra una, extrae los datos contenidos en ella. Además, tampoco hace falta ir actualizando el detector cuando aparecen nuevas canciones y la complejidad no cambia cuando llegan marcas nuevas.
• Para algunas aplicaciones, la necesidad de preprocesar las señales de audio es una gran desventaja de los sistemas de “watermarking”. Por ejemplo, los sistemas de monitorización de distribución basados en “watermarking” solo serían capaces de detectar infracciones de copyright si las señales con copyright habían sido previamente marcadas, lo que significa que todo el material antiguo no marcado no sería protegido en absoluto. Además, el nuevo material tendría que ser marcado en todos sus formatos de distribución, e incluso la disponibilidad de un pequeño grupo de copias no marcadas podría comprometer la seguridad del sistema. Esto no es ninguna preocupación para los sistemas de “fingerprinting”, ya que no hace falta ningún procesado previo.
• En la detección de la marca, la señal que contiene la información útil para la misma corresponde a una fracción muy pequeña de la potencia de entrada, ya que la marca es mucho más débil que la señal de audio original debido a la restricción de inaudibilidad. Además, el ruido que podría añadirse a la señal marcada (por compresión MP3 o transmisión analógica, por ejemplo), puede ser tan fuerte como la marca, o incluso más. En casos de perturbación severa de canal o de ataques de piratas, puede que la marca deje de ser detectable.

En contraste, la detección en sistemas de “fingerprinting” está directamente basada en la señal de audio en sí misma, la cual es suficientemente fuerte para resistir la mayoría de las perturbaciones de canal y es menos susceptible a ataques piratas. Estos sistemas son, por tanto, inherentemente más robustos. Mientras que el audio original en la base de datos suene “aproximadamente” igual que la pieza de música que el sistema está escuchando, sus huellas también serán similares. La definición de “aproximadamente” depende del proceso de extracción de la huella, y, por tanto, la robustez del sistema depende también de eso. La mayoría de sistemas usan un enfoque psicoacústico para sacar la huella. Haciendo esto, el audio a analizar puede sufrir una fuerte distorsión sin que ello provoque un decremento en la efectividad del sistema.
• La información contenida en la “marca de agua” puede no tener
relación directa con la portadora de la señal de audio. Por ejemplo, una emisora de radio podría incrustar las últimas noticias en las canciones que emite a través de una marca; en la recepción las noticias aparecerían en una pequeña pantalla mientras suenan las canciones. Por el contrario, una huella está correlada con la señal de audio a partir de la cual se obtuvo; cualquier cambio en la señal de audio que sea perceptible al oído humano debería provocar un cambio en la huella. Este hecho está detrás de la mayoría de diferencias en las aplicaciones de cada uno de los dos enfoques: mientras que las marcas pueden transportar cualquier tipo de información, las huellas siempre representan la señal de audio.
Esta independencia entre señal e información se deriva del hecho de que los sistemas de marcas solo tratan con información que ha sido previamente añadida, dado que no se provee la conexión a ninguna base de datos. Esta información pude estar relacionada o no con la señal de audio en la que se ha incrustado. Con “fingerprinting” se puede extraer información de la señal en diferentes niveles de abstracción, dependiendo de la aplicación y el escenario de uso. Las abstracciones de nivel más alto permiten extender las aplicaciones a navegación basada en el contenido, búsqueda por similaridad y otras aplicaciones de Recuperación de Información Musical.
En conclusión, ambas metodologías tienen muchas aplicaciones en
común y también muchas específicas de cada una. El “audio watermarking”, aunque en un principio estaba pensado para protección de copyright, también es útil para otros muchos propósitos, particularmente para transporte de información de propósito general. El “audio fingerprinting” se usa sobre todo para identificar señales de audio, no solo en aplicaciones de copyright, sino también en reconocimiento de anuncios, por ejemplo.
Se podría decir que el “watermarking” tiene un rango más amplio de
aplicaciones que “fingerprinting”. Sin embargo, éste último es inherentemente más robusto, lo cual significa que resistirá distorsiones más fuertes, lo que le hace particularmente atractivo en cuestiones de copyright. Y el hecho de pueda reconocer audio a partir de extractos hace que sea una solución flexible para estos temas. Eso sí, la protección absoluta contra la piratería no es más que una mera ilusión. Puesto que sus puntos fuertes

son normalmente complementarios, el uso de ambas técnicas combinadas da lugar a aplicaciones muy interesantes.
.

2. Uso de Audio Fingerprinting para Identificación De todas las posibles aplicaciones ya nombradas, nos vamos a centrar en el uso de huellas para identificar trozos de audio y, más concretamente, anuncios de radio. Para ello, primero se va a hacer un repaso de los diferentes algoritmos propuestos para realizar esta tarea [9], y posteriormente nos centraremos en el algoritmo de Haitsma y Kalker para Philips [10].
2.1 Repaso de los diversos métodos propuestos
A pesar de las distintas lógicas detrás de la tarea de identificación, los métodos comparten ciertos aspectos. Como se puede ver en la figura 3, hay dos procesos fundamentales: la extracción de la huella y el algoritmo de búsqueda de coincidencias.
Fig. 3: Estructura general de un sistema de identificación
2.1.1 Extracción de Huellas La extracción de la huella proporciona un conjunto de características
perceptuales relevantes de una grabación de una forma concisa y robusta. Los requerimientos de la huella, como ya hemos nombrado otras veces incluyen: capacidad de discriminación sobre un enorme número de otras huellas, invarianza a las distorsiones, compacidad y simplicidad computacional. Las soluciones propuestas para cumplir todos los requisitos arriba mencionados implican un compromiso entre reducción de la dimensionalidad y pérdida de información. La extracción de la huella consiste en un “front-end” y un bloque de modelado de huellas (ver figura 4). El “front-end” computa una serie de medidas tomadas de la señal, que explicaremos más adelante. El bloque de modelado de huellas define la representación final de la huella, por ejemplo, un vector, una traza de vectores, una secuencia de índices a clases de HMM (modelos ocultos de

Markov), una secuencia de palabras correctoras de errores o atributos musicalmente significativos de alto nivel.
_
Fig.4: Estructura general del proceso de extracción, con front-end (arriba) y modelado (abajo)
Dada una huella derivada de una grabación, el algoritmo de búsqueda busca en una base de datos de huellas para encontrar la mejor coincidencia. Se necesita, por tanto, una manera de comparar huellas, como puede ser la distancia. Puesto que el número de comparaciones es alto y la distancia puede ser costosa de computar, requerimos métodos que aceleren la búsqueda. Es habitual ver métodos que usan una distancia más simple para rápidamente descartar candidatos y una más correcta pero costosa distancia para un reducido conjunto de candidatos. Hay también métodos para computar distancias off-line (sin conexión) y construir una estructura de datos que permita reducir el número de cómputos a realizar on-line. Unos buenos métodos de búsqueda deberían ser: - Rápidos: El escaneo secuencial y el cálculo de la distancia pueden ser demasiado lentos para bases de datos enormes. - Correctos: Deberían devolver los objetos calificados con una nula (o, al menos, baja) Tasa de Falso Rechazo (FRR). - Uso de memoria eficiente: Deberían requerir poco espacio en memoria. - Fácilmente actualizable: Deberían permitir fácilmente insertar, borrar y actualizar objetos.

El último bloque del sistema – comprobación de hipótesis (ver fig.3) – computa una medida fiable indicando como de seguro está el sistema sobre una identificación realizada. 2.1.1.1 Front-End El “front-end” convierte una señal de audio en una secuencia de características relevantes para “alimentar” al bloque de modelado de huellas. En el diseño del “front-end” hay que tener en cuenta varias cosas fundamentales:
• Reducción de la dimensionalidad • Parámetros perceptualmente significativos (similares a los usados por
el HAS, sistema auditivo humano) • Invarianza o robustez (a distorsiones en el canal, ruido de fondo,
etc.) • Correlación temporal (sistemas que capturen la dinámica espectral)
Ahora vamos a ir detallando los distintos bloques que se observan en la fig.4. En algunas aplicaciones, donde el audio a identificar está codificado, por ejemplo en mp3, es posible saltarse algunos de estos bloques y extraer las características directamente de la representación codificada. A. Preprocesado En un primer paso, el audio es digitalizado (si es necesario) y convertido a un formato general: Frecuentemente a un formato de datos en bruto (16 bits PCM), en mono promediando los canales izquierdo y derecho, a una determinada frecuencia de muestreo (que puede ir desde los 5 a los 44,1 Khz.). Algunas veces el audio es preprocesado para simular el canal, por ejemplo: filtrado paso-banda en identificación telefónica. Otros tipos de procesado son un codificador/decodificador GSM en el sistema de identificación de un teléfono móvil, pre-énfasis, normalización de amplitud (limitando el rango dinámico entre (-1,1)). B. Framing & Overlap (Descomposición en tramas y solapamiento) Una asunción clave en la medida de características es que la señal puede ser considerada estacionaria en el intervalo de unos pocos milisegundos. Por tanto, la señal se divide en tramas de un tamaño comparable a la velocidad de variación de los eventos acústicos subyacentes. El número de tramas computadas por segundo se llama “frame rate”. Para minimizar las discontinuidades al principio y al final de cada bloque, se aplica una ventana. Para asegurar la robustez a la variación de los datos (y también cuando los datos de entrada no están bien alineados) es necesario usar solapamiento. Hay otra vez un compromiso al escoger los valores entre la tasa de cambio del espectro y la complejidad del sistema.

C. Transformaciones lineales: Estimaciones espectrales La idea detrás de las transformaciones lineales es la transformación del conjunto de medidas en un nuevo conjunto de características. Si la transformada es escogida convenientemente, la redundancia se reduce significativamente. Hay transformaciones óptimas en el sentido de compactación de la información y propiedades de decorrelación, como la Transformada de Karhunen-Loève (KLT) o la Descomposición en Valores Simples (SVD). Estas transformadas, sin embargo, son dependientes del problema y computacionalmente complejas. Por esta razón son habituales transformadas de menor complejidad que usan bases de vectores fijadas. La mayoría de los métodos CBID (Identificación de Información basada en el contenido) por tanto usan transformaciones tiempo-frecuencia estándar para facilitar una compresión eficiente, eliminación de ruido y el subsiguiente procesado. Lourens [11] y Kurth et al. [12] han propuesto, en algunos casos (para secuencias altamente distorsionadas, donde el análisis tiempo-frecuencia también presenta distorsión) el uso de medidas de la potencia de la señal. La potencia también puede ser vista como una distribución tiempo-frecuencia simplificada, con solo una frecuencia. La transformación más común es la Transformada Rápida de Fourier (FFT). Han sido propuestas otra serie de transformadas, como por ejemplo la Transformada Discreta del Coseno (DCT), la Transformada de Haar o la Transformada de Walsh-Hadamard. Se han realizado estudios [13] que demuestran, por ejemplo que la DFT (Transformada Discreta de Fourier) es menos sensible generalmente al cambio de bits que la de Walsh-Hadamard y que la MCLT (Modulated Complex Transform) presenta propiedades de invarianza a esto [3]. D. Extracción de características Una vez que tenemos una representación tiempo-frecuencia, se aplican transformaciones adicionales para generar los vectores acústicos finales. En este paso encontramos una enorme diversidad de algoritmos. El objetivo es otra vez reducir la dimensionalidad y, al mismo tiempo, incrementar la invarianza a las distorsiones. Es muy común incluir el conocimiento de las etapas de transducción del sistema auditivo humano para extraer parámetros más significativos desde el punto de vista perceptual. Por tanto, muchos sistemas extraen diversas características realizando un análisis de las bandas críticas del espectro (ver fig.5). Así por ejemplo hay algoritmos que usan los Coeficientes Mel-Cepstrum en Frecuencia (MFCC, que son los coeficientes de la DCT del logaritmo de la energía de la señal de voz en cada banda perceptual, es decir, en cada banda la energía queda ponderada por el correspondiente filtro perceptual del oído). En el sistema de Allamanche et al. [14] la Medida de la Blancura Espectral (SFM, Spectral Flatness Measure), que es una estimación de la calidad de una banda en el espectro. Papaodysseus et al. [15] presentaron los “vectores representativos de las bandas”, que son una lista ordenada de los índices de las bandas con tonos prominentes (con picos con amplitud significativa). También se puede usar la energía de cada banda [16]. Por último, en el algoritmo de Philips [10] que presentaremos posteriormente con detalle, ya que es con el que vamos a trabajar, se usa la energía de 33

bandas logarítmicamente escaladas para obtener una cadena de “hash”, que es el signo de la diferencia de energía entre las bandas (tanto en el eje del tiempo como en el de la frecuencia). Las estimaciones espectrales y las características relacionadas son solo inadecuadas cuando se produce distorsión en el canal de audio. En este caso, para caracterizar el comportamiento variante en el tiempo de las señales de audio se puede utilizar un análisis de modulación en frecuencia. Las características corresponderían a la media geométrica de la estimación modulada en frecuencia de la energía de 19 filtros paso de banda separados logarítmicamente [17].
Fig.5 Ejemplos de extracción de características
Los enfoques que se usan en los sistemas de Recuperación de Información de Música incluyen características que han demostrado ser válidos para comparar sonidos: armonicidad, ancho de banda, volumen, ZCR, etc. Las características usadas más habitualmente son heurísticas, y, por tanto pueden no ser óptimas [18]. Por esa razón, se puede usar una Transformada de Karhunen-Loève Modificada, la Descomposición en Componentes Principales Orientada (OPCA), para encontrar las características óptimas de una forma “no supervisada”. Si la PCA (KLT) encuentra un conjunto de direcciones ortogonales que maximizan la varianza de la señal, la OPCA obtiene un conjunto de direcciones posiblemente no ortogonales que tienen en cuenta una serie de distorsiones predefinidas. E. Post-Procesado La mayoría de las características descritas hasta ahora son medidas absolutas. Con la intención de caracterizar mejor las variaciones temporales

de la señal, se añaden al modelo de la señal derivadas de más alto orden del tiempo. Por ejemplo, en un sistema propuesto por Cano y Batlle [19], el vector de características es la concatenación de MFCCs, su derivada (delta) y la aceleración (delta-delta), así como ambas derivadas de la energía. Otros sistemas solo usan la derivada de las características y no las características absolutas [12,14]. Usar las derivadas de las medidas de la señal tiende a amplificar ruido, pero, al mismo tiempo filtra las distorsiones producidas en canales lineales invariantes o lentamente variantes con el tiempo (como una ecualización). La Normalización Media Cepstrum (CNM) también se usa para reducir distorsiones en canales lineales lentamente variantes. Si se usa la distancia euclídea como método de búsqueda, son aconsejables la sustracción de la media y la normalización de la varianza teniendo en cuenta los componentes. Es relativamente habitual aplicar una cuantización de muy baja resolución a las características: ternaria [13] o binaria [10]. El objetivo de la cuantización es ganar robustez contra las distorsiones, normalizar, facilitar las implementaciones hardware, reducir los requerimientos de memoria y por conveniencia en partes subsiguientes del sistema. Las secuencias binarias hacen falta para extraer palabras correctoras de error en algunos sistemas que las utilizan, como el propuesto por Mihak y Venkatesan [3]. En este, la discretización se diseña para incrementar la aleatoriedad con la intención de minimizar la probabilidad de colisión de huellas. 2.1.1.2 Modelado de Huellas El bloque de modelado de huellas normalmente recibe una secuencia de vectores de características calculados teniendo en cuenta todas las tramas una por una. Explotar redundancias entre tramas vecinas en el tiempo, dentro de una grabación y a lo largo de toda la base de datos es útil para posteriormente reducir el tamaño de la huella. El tipo de modelo escogido condiciona la métrica de la distancia y también el diseño de algoritmos para una recuperación rápida de información. Una forma muy concisa de huella se consigue resumiendo las secuencias de vectores multidimensionales de una canción completa (o de una parte de ella) en un vector simple. Así por ejemplo, Etantrum calcula el vector a partir de las medias y varianzas de las 16 energías filtradas correspondientes a 30 segundos de audio, dando como resultado una firma de 512 bits. La firma, junto con la información en el formato original de audio es mandada a un servidor para su identificación. La firma TRM de MusicBrainz incluye en un vector: la tasa media de cruces por cero, la tasa estimada de “beats” por minuto (BPM), un espectro promediado y algunas características más para representar una pieza de audio (correspondiente a 26 segundos). Estos dos ejemplos aquí nombrados son computacionalmente eficientes y producen una huella muy compacta. Han sido diseñados para aplicaciones como asociar archivos mp3 a metadatos (título, artista, etc.) y pretenden conseguir sobre todo una baja complejidad (tanto en el lado del cliente como en el del servidor) más que una gran robustez.

Las huellas también pueden ser secuencias (trazas, trayectorias) de características. Así, encontramos sistemas que representan la huella como secuencias de vectores binarios. La huella en el sistema de Papaodysseus [15], que consiste en una secuencia de “vectores representativos de las bandas”, es codificada en binario por cuestiones de eficiencia de memoria. Algunos sistemas incluyen atributos de alto nivel musicalmente significativos, tales como el ritmo (BPM) o el tono predominante. Siguiendo el razonamiento que expusimos antes de la posible sub-optimalidad de las características heurísticas [18], se usan varias capas de OPCA para disminuir las redundancias estadísticas locales de los vectores de características respecto al tiempo. Además de reducir la dimensionalidad, se tienen en cuenta en esta transformación los requisitos extra de robustez ante el intercambio de bits. En el sistema de Allamanche et al. [14] se explotan las redundancias globales dentro de una canción. Si asumimos que las características de un elemento de audio dado son similares entre ellas, se puede generar una representación compacta agrupando los vectores de características. La secuencia de vectores es, pues, aproximada por un número mucho más bajo de vectores de código representativos, un libro de código. La evolución temporal del audio se pierde completamente con esta aproximación. Además, en este sistema se recogen estadísticas de cortos periodos de tiempo en distintas regiones temporales. Esto da como resultado tanto un mejor reconocimiento, ya que las dependencias temporales son tenidas en cuenta, como una búsqueda de coincidencias más rápida, ya que la longitud de cada secuencia también se reduce. El sistema de Cano y Batlle [19] usa un modelo que explota más la redundancia global. La base lógica está muy inspirada por la investigación del habla. En el habla, un alfabeto de clases de sonido, es decir los fonemas, pueden usarse para segmentar una colección de datos hablados en bruto en texto, logrando una gran reducción de la redundancia sin mucha pérdida de información. Análogamente, podemos ver un trozo de música como secuencias construidas concatenando clases de sonidos de un alfabeto finito. En un gran número de canciones pop aparecen sonidos de batería “perceptualmente equivalentes”. Esta aproximación nos conduce a una huella que consiste en secuencias de índices a un conjunto de clases de sonidos representativo de una colección de elementos de audio. Las clases de sonido son estimadas vía agrupamiento sin supervisión y modeladas con Modelos Ocultos de Markov (HMMs). El modelado estadístico del transcurso de la señal en tiempo permite una reducción de la redundancia local. La representación de la huella como secuencias de índices a clases de sonidos conserva la información de la evolución del audio a través del tiempo. En [3] las secuencias discretas son mapeadas a un diccionario de palabras correctoras de errores. En [12], el método de indexado está basado en los códigos correctores de errores.

2.1.2 Distancias y métodos de búsqueda 2.1.2.1. Distancias Las métricas de distancia están altamente relacionadas con el tipo de modelo escogido. Cuando se comparan secuencias de vectores es habitual usar una correlación. La distancia euclídea, o versiones ligeramente modificadas de la misma que tratan con secuencias de diferente longitud, se usa por ejemplo en [20]. En [17], la clasificación es el Vecino Más Cercano usando una estimación de la entropía cruzada. En los sistemas donde las secuencias de vectores de características están cuantizadas, se usa una distancia Manhattan (o Hamming cuando la cuantización es binaria). Mihak [3] sugiere que otra métrica de error, que llaman “Pseudo norma exponencial” (EPN), podría ser más apropiada para distinguir mejor entre valores cercanos y distantes con un énfasis más fuerte que el lineal. Hasta ahora hemos presentado una estructura de trabajo para la identificación que sigue un mismo paradigma para la búsqueda de coincidencias: tanto los patrones de referencia –las huellas almacenadas en la base de datos- como el patrón de prueba –la huella extraída a partir del audio desconocido- están en el mismo formato y son comparados según alguna métrica de distancia, por Ej.: distancia Hamming, una correlación, etc. En algunos sistemas, sólo los elementos de referencia son realmente “huellas” –modeladas compactamente como un libro de códigos o una secuencia de índices a HMMs. En estos casos, las distancias son computadas directamente entre la secuencia de características extraídas a partir del audio desconocido y las huellas del audio de referencia almacenadas en la base. En [14], la secuencia del vector de características es comparada con los distintos libros de código usando una métrica de distancia. Para cada libro, se acumulan los errores. El elemento desconocido es asignado a la clase que dé el menor número de errores acumulados. En [21], la secuencia de características es comparada con las huellas (una concatenación de índices apuntando a clases de sonidos HMM) usando el algoritmo de Viterbi. Se selecciona el recorrido más probable en la base de datos. 2.1.2.2- Métodos de Búsqueda Más allá de la definición de una métrica de distancia para la comparación de huellas, un asunto fundamental para la usabilidad de un sistema es cómo de eficientemente realiza las comparaciones entre el audio desconocido y posiblemente, millones de huellas. Un enfoque de fuerza bruta, que compute las similaridades entre la huella de la grabación desconocida y las que están almacenadas en la base de datos puede ser inviable. El tiempo para encontrar la mejor coincidencia en este método lineal o secuencial es proporcional a N*c(d())+E, donde N es el número de huellas almacenadas y c(d()) el tiempo que se necesita para encontrar una sola similaridad y E tiene en cuenta algún tiempo extra de CPU. En general los métodos dependen de la representación de la huella, pero vamos a hacer una clasificación más o menos general de los enfoques propuestos en la literatura.

- Pre-computar distancias offline: Uno no puede calcular similaridades offline con la huella candidata, puesto que ésta no ha sido presentada previamente al sistema. Sin embargo uno pude computar distancias entre las huellas ya almacenadas y construir una estructura de datos para reducir el número de evaluaciones de similaridad una vez que se presenta la huella. Es posible construir offline conjuntos de clases de equivalencia, calcular algunas similaridades online para descartar algunas clases y buscar exhaustivamente entre el resto. Si la medida de similaridad es una métrica, por ejemplo, la medida es una función que cumple las siguientes propiedades: positividad, simetría, reflexividad y la desigualdad triangular, hay métodos para reducir el número de evaluaciones y garantizar que no hay falsos rechazos. Los espacios vectoriales permiten el uso de eficientes métodos de acceso espacial ya existentes. - Filtrado de candidatos improbables con una medida de similaridad simple: Otra posibilidad es usar una medida de similaridad más simple para eliminar rápidamente muchos candidatos y la más precisa y compleja en el resto. Como se demuestra en [22], para garantizar que no se produzcan falsos rechazos, la medida simple utilizada para descartar hipótesis poco prometedoras debe limitar por debajo a la medida más cara (fina). - Indexado de archivos inverso: Un método de búsqueda muy eficiente es el uso de indexado de archivos inverso. Haitsma et al. propusieron un índice de posibles trozos de una huella que apuntan a posiciones en las canciones. Dado que un trozo de la huella candidata está libre de errores (coincidencia exacta), se puede obtener eficientemente una lista de canciones candidatas para buscar exhaustivamente en ella. En [19], se usan indexados y heurísticas similares a las usadas en biología computacional para la comparación del ADN para acelerar la búsqueda en un sistema donde las huellas son secuencias de símbolos. Kurth et al. [12] presentan un índice que usan palabras de código extraídas de secuencias binarias que representan el audio. A veces estos enfoques, aunque son muy rápidos hacen suposiciones sobre los errores permitidos en las palabras usadas para construir el índice, lo que podría resultar en falsos rechazos. - Reducción de candidatos: Una optimización simple para acelerar la búsqueda es mantener el mejor resultado obtenido hasta el momento. Podemos abandonar el cálculo de una medida de similaridad si llegados a un cierto punto sabemos que ya no vamos a mejorar el mejor resultado obtenido hasta el momento. Algunas medidas pueden aprovecharse de algunas estructuras como árboles de sufijos para evitar cálculos duplicados [23]. Millar et al. [24] proponen un árbol para evitar redundancias en el cálculo de la mejor coincidencia en una estructura de trabajo construida con la representación de huellas de [10]. Combinando la estructura de árbol con una heurística del “mejor hasta ahora” se evita no sólo la computación de similaridad de la huella actual sino que también la de todas las huellas que tengan un inicio común. - Otros enfoques: En [25], el almacén de las huellas se separa en dos bases de datos. La primera y más pequeña guarda las huellas con mayor probabilidad de aparición, por ejemplo las canciones más populares del momento y la otra guarda el resto. Las huellas candidatas son confrontadas

primero con la más pequeña y más probable y sólo cuando no se encuentra ninguna coincidencia el sistema examina la segunda base de datos. Los sistemas de producción de hecho usan varios de los métodos de aceleración descritos más arriba. El de Wang y Smith [25], por ejemplo, además de buscar primero en el almacén de canciones más populares, usa un indexado de archivos inverso para acceder rápidamente a las huellas junto con una heurística para filtrar candidatos poco prometedores antes de buscar exhaustivamente con la medida de similaridad más precisa. 2.1.3 Comprobación de Hipótesis Este último paso pretende responder si el elemento en cuestión está o no en el almacén de datos a identificar. Durante la comparación de la huella extraída con la base de datos de huellas, se obtienen resultados (a partir de las distancias). Para poder decidir si hay una identificación correcta, el resultado debe estar por encima de un determinado umbral. No es fácil de escoger dicho umbral ya que depende de: el modelo usado para la huella, la información del elemento, la similaridad de las huellas de la base y el tamaño de la misma. Mientras más grande sea la base, mayor es la probabilidad de indicar una coincidencia erróneamente, lo que es un falso positivo. La tasa de falso positivo se llama también tasa de falsa aceptación (FAR) o probabilidad de falsa alarma. La tasa de falso negativo también es llamada tasa de falso rechazo (FRR). La nomenclatura está relacionada con las medidas de evaluación del comportamiento del sistema de Recuperación de Información: Precisión y Memoria.

3. El Sistema de Philips El proyecto se va a centrar en el estudio del sistema propuesto por los ingenieros de Philips Jaap Haitsma y Ton Kalker en su artículo “A Highly Robust Audio Fingerprinting System” [10]. En primer lugar presentaremos detalladamente el algoritmo para pasar posteriormente a comentar los resultados obtenidos en la simulación del mismo (principalmente en términos de probabilidad de falso positivo y probabilidad de detección). Antes de empezar el diseño e implementación del sistema hay que hacerse unas cuantas preguntas. La primera y más importante es qué tipo de características son las que se van a usar. Ya hemos expuesto exhaustivamente en el capítulo anterior un gran número de posibles características usadas en la literatura. Estas podían dividirse en dos grandes clases: características semánticas y características no semánticas. Las primeras serían, por ejemplo, el género o el ritmo (BPM). Este tipo suelen tener una interpretación directa y se usan de hecho para clasificar música, generar listas de reproducción, etc. El segundo tipo consiste en características que tienen una naturaleza más matemática y son más difíciles de obtener directamente a partir de la música para una mente humana. Un elemento típico de este grupo es lo que se llama “Audio Flatness”, usado en MPEG-7. Para este algoritmo se decidió explícitamente trabajar con características no semánticas por una serie de razones que nombramos a continuación: - Las características semánticas no siempre un significado claro y no ambiguo, es decir, las opiniones personales difieren sobre dichas clasificaciones. Es más, incluso pueden cambiar con el tiempo: por ejemplo, lo que se clasificaba como hard rock hace 25 años hoy podría considerarse bastante más suave. Esto hace que el análisis matemático sea dificilísimo. - Las características semánticas son, en general, más difíciles de computar que las no semánticas. - Las características semánticas no son aplicables universalmente. Por ejemplo, el ritmo (BPM) no se suele aplicar a la música clásica. Una segunda cuestión a tener en cuenta es la representación de las huellas. Una opción evidente es representarla como un vector de números reales, donde cada componente exprese el peso de una cierta característica espectral básica. Una segunda opción es mantener el espíritu de las funciones criptográficas de “hash” y representar las huellas como cadenas de bits. Por razones de reducida complejidad en la búsqueda se decidió trabajar con la segunda opción. La primera implicaría una medida de similaridad involucrando sumas/sustracciones reales y dependiendo de la medida de similaridad, puede que incluso multiplicaciones reales. Las huellas basadas en representaciones de bits pueden ser comparadas solo contando bits. Dados los escenarios de aplicación esperados, no esperamos una alta robustez para todos y cada uno de los bits en una huella como esta. Por tanto, en contraste con los “hash” criptográficos que tienen como mucho varios centenares de bits, permitiremos huellas que tengan unos

pocos miles de bits. Las huellas que contienen un gran número de bits permiten una identificación fiable incluso si el porcentaje de bits que no coinciden es relativamente alto. Una última cuestión se refiere a la granularidad de las huellas. En las aplicaciones que se prevén no hay ninguna garantía de que los archivos de audio estén completos. Por ejemplo, en la monitorización de emisiones, cualquier intervalo de 5 segundos es una unidad que tiene valor comercial, y por tanto debe ser identificado y reconocido. O, por ejemplo, en aplicaciones de seguridad tales como el filtrado de archivos en una red peer-to-peer, uno no desearía que el borrado de los primeros segundos de un archivo pudiera evitar la identificación. Aquí se adopta la postura de flujos de huellas, asignando sub-huellas a intervalos suficientemente pequeños (llamados tramas). Estas sub-huellas pueden no ser suficientemente grandes para identificar las tramas en sí mismas, pero un intervalo más grande, que contenga suficientes tramas permitirá una identificación robusta y fiable. 3.1 Algoritmo 3.1.1 Algoritmo de extracción Como ya hemos comentado, la mayoría de los algoritmos de extracción están basados en el siguiente enfoque. Primero la señal de audio es segmentada en tramas. Para cada trama se computa un conjunto de características, escogidas de tal forma que sean invariantes (al menos hasta cierto punto) a las degradaciones de la señal. A la representación compacta de una trama individual se le llama sub-huella. El procedimiento global convierte un flujo de audio en un flujo de sub-huellas. Una sub-huella normalmente no tendrá información suficiente para identificar un archivo de audio. A la unidad básica que contiene suficiente información para identificar un archivo de audio (y, por tanto determinar la granularidad) le llamaremos bloque de huellas. El esquema de extracción de huellas propuesto está basado en este enfoque general. Extrae sub-huellas de 32 bits por cada intervalo de 11,6 milisegundos. Un bloque consiste en 256 sub-huellas consecutivas, correspondiendo a una granularidad de tan solo 3 segundos. Una vista general del esquema se muestra en la siguiente figura:
Fig.6: Vista general del esquema de extracción

La señal es primero segmentada en tramas solapadas. Dichas tramas tienen una longitud de 0,37 segundos y son ponderadas por una ventana de Hanning, con un factor de solapamiento de 31/32. Esta estrategia resulta en la extracción de una sub-huella cada 11,6 milisegundos. En el peor caso posible, los límites de la trama usados durante la identificación están 5,8 milisegundos desplazadas con respecto a los límites usados en la base de datos de huellas previamente computadas. Debido a la gran superposición, dos sub-huellas consecutivas tienen una gran similaridad y varían lentamente con el tiempo.
Ya sabemos que las características perceptuales más importantes
están en el dominio de la frecuencia. Por tanto, se computa una representación espectral, realizando una transformada de Fourier a cada trama. Debido a la sensibilidad de la fase de la transformada de Fourier a diferentes límites de trama y al hecho de que el sistema auditivo humano (HAS) es relativamente insensible a la fase, solo nos quedamos con la información de módulo.
Para poder extraer un valor de sub-huella de 32 bits para cada
trama, se seleccionan 33 bandas de frecuencias no solapadas. Estas bandas están entre los 300 y los 2000 Hz (el rango espectral más relevante para el HAS) y están logarítmicamente espaciadas. El espaciamiento logarítmico se escoge porque es bien sabido que el HAS opera en bandas aproximadamente logarítmicas (la llamada Escala Bark). Está verificado experimentalmente que el signo de la diferencia de energías (simultáneamente en el eje del tiempo y en el de la frecuencia) es una propiedad que es muy robusta a distintos tipos de procesado. Si denotamos la energía de la banda n de la trama n por E(n,m) y el m-ésimo bit de la sub-huella de la trama n por F(n,m), los bits de la sub-huella son formalmente definidos como:
( ) ( ) ( )( )( ) ( ) ( )( )
≤+−−−−+−>+−−−−+−
=01,1,1)1,(,,0
01,1,1)1,(,,1),(
mnEmnEmnEmnE
mnEmnEmnEmnEmnF (1)
En la siguiente figura se muestra un ejemplo de un bloque de 256
sub-huellas de 32 bits, extraídos con este esquema a partir de un trozo de “O Fortuna” de Carl Orff. Un bit a ‘1’ corresponde a un píxel blanco y uno a ‘0’, a un píxel negro. La fig. 7a corresponde al bloque obtenido a partir de la versión en calidad CD, mientras que el 7b ha sido obtenido a partir de la versión comprimida en MP3 (32kbps). Aunque idealmente ambas figuras deberían ser idénticas, no lo son, algunos de los bits cambian. Estos bits erróneos, que aparecen en negro en la figura 7c, se usan como medida de similaridad en el esquema.

Fig.7: (a)Bloque de huellas de la versión original, (b)de la versión comprimida en mp3, (c) diferencia de ambas
(BER= 0.078)
Los recursos de computación requeridos para el algoritmo propuesto son limitados. Puesto que el algoritmo solo tiene en cuenta frecuencias por debajo de 2KHz, el archivo de audio es primero submuestreado a un flujo de audio mono con una tasa de muestreo de 5 KHz (en realidad, 44100/8=5512,5 Hz). Las sub-huellas han sido diseñadas de tal forma que sean robustas contra degradaciones de la señal. Por tanto se pueden usar filtros de submuestreo muy sencillos sin introducir ninguna degradación en el comportamiento del sistema. Se usan 16 filtros FIR. La operación que más requiere computacionalmente es la transformada de Fourier de todas las tramas de audio. En la señal de audio submuestreada, la trama tiene una longitud de 2048 muestras. Si la transformada se implementa con una FFT, el algoritmo ha demostrado poder ejecutarse eficientemente en aparatos portátiles tales como una PDA o un teléfono móvil. 3.1.2 Algoritmo de Búsqueda Aunque no será objeto de este proyecto (nos centraremos en analizar y proponer mejoras al algoritmo de extracción), vamos a presentar también, más brevemente, el algoritmo de búsqueda en la base de datos, una vez que ya se ha extraído la huella. La tarea no es trivial. En vez de buscar por una huella con todos los bits exactamente iguales, lo que hay que encontrar es la huella más similar. Pongamos por ejemplo una base de datos de tamaño moderado, con 10.000 canciones de una duración media de 5 minutos. Esto corresponde a unos 250 millones de sub-huellas. Para identificar un bloque originado a partir de un trozo de audio desconocido hay que encontrar cual entre 250 millones da

la tasa de error mínima. Esto es realizable por fuerza bruta, en un ordenador con una capacidad de análisis de 200.000 bloques por segundo tardaría unos 20 minutos, lo cual no es viable en la práctica. Se propone un algoritmo más eficiente. Se calcula la BER sólo para una serie de “candidatos”, que contienen una alta probabilidad de ser la mejor posición en la base de datos. En una versión simple del algoritmo se hace la suposición de que es muy probable que, por lo menos una sub-huella (32 bits, recordemos) tenga una coincidencia exacta en la posición óptima de la base de datos. Si esto es válido, sólo hay que comprobar las posiciones en las que una de las 256 sub-huellas del bloque a identificar coincida. Como ejemplo, en la fig.8 se muestra el número de errores por sub-huella para la huella mostrada en la fig.7. Se observa que de hecho hay 17 sub-huellas de las 256 que no tienen errores.
Fig.8: Bits erróneos por sub-huella para el caso de O Fortuna de Orff
Si asumimos que la huella original de la fig. 7a está en la base de datos, su posición estará entre las candidatas seleccionadas cuando el audio a identificar sea la versión mp3 de la fig. 7b. Las posiciones de una base de datos donde se encuentra una sub-huella de 32 bits específica se obtienen usando la arquitectura de base de datos de la fig.8.

Fig.9: Esquema de la base de datos
La base de datos contiene una “Lookup Table” (LUT) con todas las posibles sub-huellas de 32 bits como entrada. Cada entrada apunta a una lista con punteros a las posiciones en la base de datos real donde se encuentran las respectivas huellas de 32 bits. En sistemas prácticos con memorias limitadas una tabla que contenga 232 entradas no es factible o no es práctica. Además, la LUT estará rellena de una forma dispersa, porque solo un número limitado de canciones pueden almacenarse en memoria. Por tanto, en la práctica, se usa una tabla de “hash” en vez de una LUT.
Si volvemos a hacer cuentas, para una base de datos de 10.000
elementos, tendremos unos 250 millones de sub-huellas. Por tanto, el número medio de posiciones en una lista será 0,058 (=256*106/232). Si suponemos que todas las sub-huellas son igualmente probables, el número medio de comparaciones por identificación sería 15 (=0,058*256). En la práctica se observa que la distribución de las sub-huellas es no uniforme, lo que hace aumentar el número de comparaciones en un factor de 20 más o menos. Aun así, en un buen ordenador, 300 comparaciones se pueden hacer en 1,5 milisegundos. Por lo tanto este algoritmo es unas 800.000 veces más rápido que la búsqueda simple.
Se había supuesto que una de las sub-huellas estaba libre de errores,
lo cual es casi siempre cierto para señales con degradación más o menos suave. Para señales fuertemente degradadas la suposición no es siempre válida. Si esto no ocurre, se mira si hay sub-huellas con un solo error y, en vez de buscar en la base de datos posiciones donde ocurra una de las 256 huellas buscamos posiciones con una distancia de Hamming de 1 (es decir, un bit cambiado) con respecto a todas las 256 sub-huellas. Esto incrementará el número de búsquedas en un factor de 33, lo que todavía es asumible. Pero, si el número mínimo de bits erróneos en una sub-huella es 3, el tiempo de búsqueda se incrementa en un factor de 5489, lo que ya no es asumible. Es interesante observar que el factor de no-uniformidad de 20 va disminuyendo al ir aumentando el número de bits a conmutar.

Puesto que este método lleva muy rápido a tiempos de búsqueda
inaceptables se propone otro enfoque que usa decodificación suave. Es decir, se propone estimar y usar la probabilidad de que un bit de una huella sea recibido correctamente. Las sub-huellas se obtienen comparando y umbralizando diferencias de energía. Si la diferencia de energía está muy cerca del umbral es razonablemente probable que el bit sea erróneo y viceversa. Derivando la información de fiabilidad de cada bit de la sub-huella a es posible expandir una huella dada en una lista de probables sub-huellas. Asumiendo que una de las más probables tiene una coincidencia exacta en la posición óptima de la base de datos, la identificación se hace como antes. Lo que se hace es ordenar los 32 bits de menos a más fiables y se va haciendo la lista de sub-huellas probables conmutando solo los menos fiables. Más concretamente, la lista consiste en todas las sub-huellas con los N bits más fiables fijados y el resto variables. Por ejemplo, si la información de fiabilidad es perfecta y el número mínimo de errores por sub-huella es 3, puede identificarse el bloque con sólo 8 (=23) búsquedas, que, comparado con 5489 es una gran mejora. Por supuesto, la información de fiabilidad no es perfecta y la mejora es menos, pero aun así sigue siendo sustancial. Lo podemos ver en la siguiente figura:
Fig. 10: Bits erróneos por sub-huella (en gris) y fiabilidad del bit erróneo más fiable (en negro) de la versión
mp3@32kbps de O Fortuna de Orff.
Por ejemplo, la primera sub-huella tiene 8 errores. Estos 8 bits erróneos no son los 8 más débiles, porque uno de ellos tiene una fiabilidad de 27. Sin embargo, la sub-huella tiene sólo un error, que resulta ser el tercero menos fiable. Por tanto, este bloque habría sido apuntado al lugar correcto cuando se conmutaran los 3 bits más débiles. La canción se habría identificado bien. Acabamos dando un ejemplo de como funciona el esquema de la fig.8. La última sub-huella extraída del bloque de la figura es 0x00000001. Primero el bloque es comparado con las posiciones en la base de datos

donde se encuentra dicha sub-huella. La LUT sólo apunta a una posición para dicha huella, una cierta posición p de la canción 1. Ahora se calcula la BER entre el bloque y los valores entre la posición p-255 y p de la canción almacenada. Si la BER está por debajo de 0,35, la probabilidad de que corresponda a esa canción es alta, si no, o bien la canción no está en la base de datos o la sub-huella tiene un error. Asumimos que el menos fiable es el ‘1’ del final y la sub-huella más probables es 0x00000000. Ésta tiene dos candidatos, en la canción 1 en la 2. Si el bloque tiene una BER por debajo del umbral al comparar con alguna de las dos, se dirá que hay coincidencia. Si no, bien se usan otras sub-huellas probables o se coge alguna de las otras 254 sub-huellas, donde se repite el proceso. Si todas las 256 sub-huellas y sus sub-huellas más probables han generado posiciones candidatas y ninguna ha dado una BER por debajo del umbral, el algoritmo decide que no puede identificar la canción. Como conclusión, podemos resumir el sistema según los parámetros de diseño de este tipo de sistemas: - Tamaño de huella: Se extrae una huella de 32 bits cada 11,8 milisegundos, lo que da una tasa de 2,6 kbps. - Granularidad: Un bloque consistente en 256 sub-huellas y correspondiente a 3 segundos de audio es la unidad básica de identificación. - Velocidad de búsqueda y escalabilidad: Usando un algoritmo en dos fases una base de datos de huellas que contenga 20.000 canciones y maneje docenas de peticiones por segundo puede ser ejecutada en un ordenador moderno.
3.2 Análisis prácticos a realizar
Una vez expuesto el algoritmo usado por Philips, el primer objetivo del presente proyecto es realizar una serie de análisis prácticos del mismo, sobre todo de dos parámetros fundamentales para describir la actuación de todo sistema: La Probabilidad de Falso Positivo y la Robustez ante degradaciones de la señal.
Para ello, se ha programado en Matlab el algoritmo de extracción de
huellas, junto con una serie de funciones de comprobación de la BER entre dos huellas dadas. Todos estos códigos se incluyen en el Anexo 1 del proyecto.
Una vez demostrada la idoneidad o no del sistema, se propondrán
una serie de opciones de preprocesado de la señal de audio antes de ser introducida en el sistema y se realizarán los mismos análisis para comprobar si dichas opciones suponen una mejora en las prestaciones o no. Para esto se usarán las funciones anteriormente mencionadas junto con otras que serán necesarias para programar los distintos algoritmos de preprocesado.

3.2.1 Probabilidad de falso positivo Diremos que dos señales de audio de 3 segundos son iguales si la distancia Hamming (es decir, el número de bits erróneos) entre las huellas derivadas de ambos bloques está por debajo de un cierto umbral T. El valor T de dicho umbral condiciona directamente la probabilidad de falso positivo, P, es decir, la probabilidad de que dos señales de audio distintas sean consideradas iguales. Mientras más pequeño sea dicho umbral, evidentemente menor será la probabilidad de que esto pase. Pero, por otro lado, mientras más pequeño sea T, mayor será la probabilidad de que dos señales iguales sean consideradas diferentes (Probabilidad de Falso Negativo). Si empezamos con un análisis teórico del problema, para analizar la elección de dicho umbral T, asumimos que el proceso de extracción de huellas da como resultado unos bits aleatorios e i.i.d. (independientes e idénticamente distribuidos). El número de bits erróneos tendrá una distribución binomial (n,p), donde n es el número de bits extraídos y p (=0,5) es la probabilidad de extraer un ‘1’ o un ‘0’. Puesto que n (=32*256) es grande en nuestra aplicación, la distribución binomial puede aproximarse por una distribución normal de media m=n*p y desviación estándar σ= )1( pnp − . Dado un bloque de huellas F1, la probabilidad de que un
bloque seleccionado aleatoriamente F2 tenga menos de T=a*n errores con respecto a F1 viene dada por:
Pf (α )=( )
( )
−=Π ∫
∞
−
−nerfcdxe
n
x
2
21
2
12
121
22 α
α
(2)
Donde α denota la probabilidad de error, la BER. Sin embargo, en la práctica las sub-huellas tienen una alta correlación a lo largo del eje temporal. Esta correlación es debida no sólo a la inherente correlación temporal existente en el audio, sino también al gran solapamiento de las tramas usadas en la extracción de huellas. Una correlación más alta implica una desviación estándar más grande. Esto se demuestra en la siguiente discusión. Asumamos una fuente binaria simétrica con alfabeto {-1,1}, tal que la probabilidad del símbolo xi y del símbolo xi+1 sean iguales es q. Entonces se podría demostrar que
E[xixi+k]=a|k| (3)
donde a=2*q-1. Si la fuente Z es el XOR de dos secuencias como esa X e Y, entonces Z es simétrica y
E[zizi+k]=a2|k| (4)
Para N grande, la desviación estándar de la media Z N sobre N muestras consecutivas de Z puede ser descrita aproximadamente por una distribución normal de media 0 y de desviación estándar igual a

( )2
2
1
1
aN
a
−+
(5)
Trasladando este razonamiento al caso de bits de las huellas, un factor de correlación a entre bits de huellas consecutivas implica un incremento en la desviación estándar en un factor
( )2
2
1
1
a
a
−+
(6)
En [10], para determinar la distribución de la BER con bloques reales lo que se hizo fue generar una base de datos de 10.000 canciones. Después se determinó la BER de 100.000 pares de bloques seleccionados aleatoriamente. La desviación estándar de la distribución resultante se midió en 0,0148, aproximadamente 3 veces mayor de los 0,0055 que se esperarían de bits aleatorios i.i.d. En la figura 10 se muestra la función densidad de probabilidad de la distribución de la BER medida y de una distribución normal de media 0,5 y desviación estándar 0,0148. La PDF de la BER es una aproximación bastante cercana a la distribución normal. Para BERs por debajo de 0,45 se observan algunos valores atípicos debido a un número insuficiente de valores.
Fig. 11: Comparación de la PDF de la BER dibujada con + y la distribución normal
Para incorporar la mayor desviación estándar de la distribución de la BER la fórmula () es modificada incluyendo un factor 3.
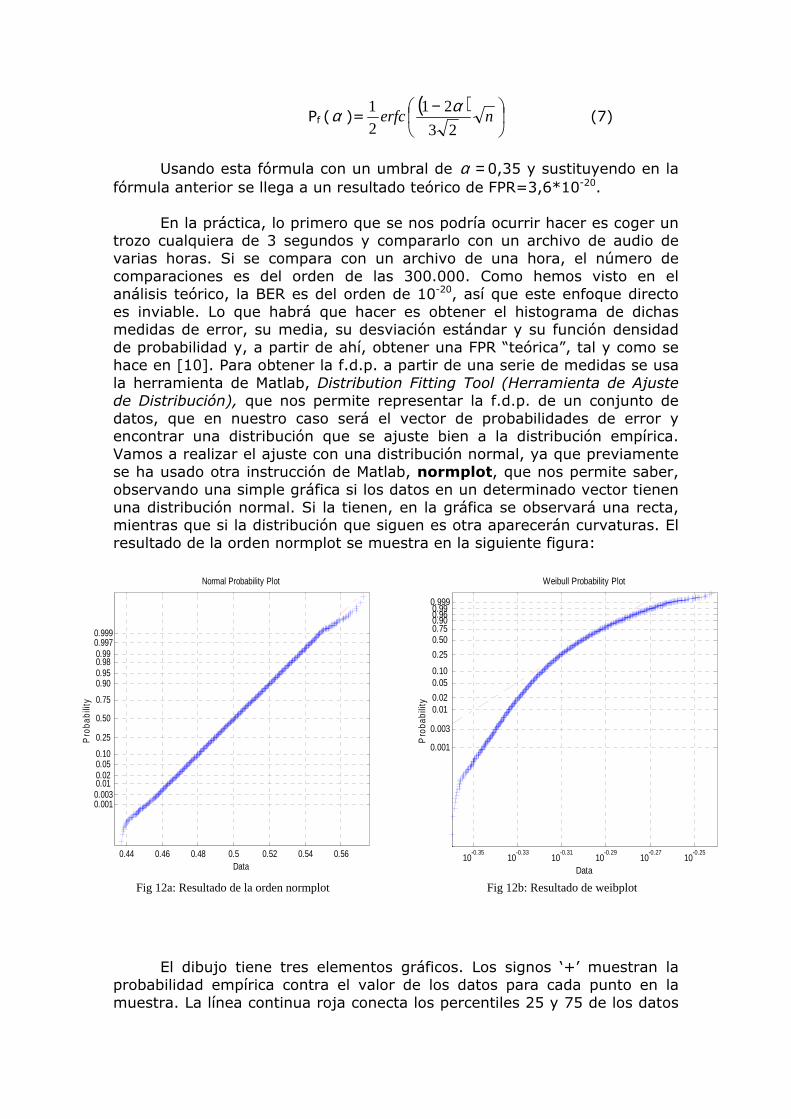
Pf (α )=( )
−nerfc
23
21
2
1 α (7)
Usando esta fórmula con un umbral de =α 0,35 y sustituyendo en la fórmula anterior se llega a un resultado teórico de FPR=3,6*10-20. En la práctica, lo primero que se nos podría ocurrir hacer es coger un trozo cualquiera de 3 segundos y compararlo con un archivo de audio de varias horas. Si se compara con un archivo de una hora, el número de comparaciones es del orden de las 300.000. Como hemos visto en el análisis teórico, la BER es del orden de 10-20, así que este enfoque directo es inviable. Lo que habrá que hacer es obtener el histograma de dichas medidas de error, su media, su desviación estándar y su función densidad de probabilidad y, a partir de ahí, obtener una FPR “teórica”, tal y como se hace en [10]. Para obtener la f.d.p. a partir de una serie de medidas se usa la herramienta de Matlab, Distribution Fitting Tool (Herramienta de Ajuste de Distribución), que nos permite representar la f.d.p. de un conjunto de datos, que en nuestro caso será el vector de probabilidades de error y encontrar una distribución que se ajuste bien a la distribución empírica. Vamos a realizar el ajuste con una distribución normal, ya que previamente se ha usado otra instrucción de Matlab, normplot, que nos permite saber, observando una simple gráfica si los datos en un determinado vector tienen una distribución normal. Si la tienen, en la gráfica se observará una recta, mientras que si la distribución que siguen es otra aparecerán curvaturas. El resultado de la orden normplot se muestra en la siguiente figura:
0.44 0.46 0.48 0.5 0.52 0.54 0.56
0.0010.0030.01 0.02 0.05 0.10
0.25
0.50
0.75
0.90 0.95 0.98 0.99 0.9970.999
Data
Pro
babi
lity
Normal Probability Plot
10-0.35
10-0.33
10-0.31
10-0.29
10-0.27
10-0.25
0.001
0.003
0.01 0.02
0.05 0.10
0.25
0.50 0.75 0.90 0.96 0.99 0.999
Data
Pro
babi
lity
Weibull Probability Plot
Fig 12a: Resultado de la orden normplot Fig 12b: Resultado de weibplot
El dibujo tiene tres elementos gráficos. Los signos ‘+’ muestran la probabilidad empírica contra el valor de los datos para cada punto en la muestra. La línea continua roja conecta los percentiles 25 y 75 de los datos

y representa un ajuste lineal robusto (es decir, insensible a los extremos de la muestra). La línea punteada extiende la línea continua hasta los extremos de la muestra. Si todos los datos caen cerca de la línea la asunción de normalidad es razonable, y en este caso podemos observar que solo en los casos muy extremos, es decir, para probabilidades por debajo de 0.001 o por encima de 0.999 se aleja de la recta. Como comparación, si usamos weibplot, que hace lo mismo pero suponiendo que la distribución es una distribución de Weibull el resultado se observa en la fig. 11b. Comparando ambas, se puede observar fácilmente por qué vamos a trabajar con la suposición de que la distribución del error es normal. Sin embargo, por definición, la BER no puede ser negativa, así que trabajaremos con una f.d.p. lognormal Una vez hecho esto ejecutamos dfittool, para cargar la herramienta de ajuste y definimos un ajuste lognormal. El resultado del ajuste se presenta en la siguiente figura y la siguiente tabla: Distribution: Lognormal Log likelihood: 281939 Domain: 0 < y < Inf Mean: 0.500153 Variance: 0.000247017 Parameter Estimate Std. Err. mu -0.693335 9.78455e-005 sigma 0.0314162 6.91877e-005 Estimated covariance of parameter estimates: mu sigma mu 9.57374e-009 1.48481e-020 sigma 1.48481e-020 4.78694e-009

Fig 13: Comparación de la f.d.p. de la BER y de una f.d.p lognormal El último paso que nos queda es obtener la FPR en sí misma, que será simplemente la probabilidad de que una distribución lognormal de media -0.693335 y desviación típica 0.0314162 esté por debajo de 0.35. Una posible manera de hacerlo es integrando la f.d.p de una lognormal entre 0 y 0.35, pero dicha integración resulta complicada, por lo que finalmente se ha optado por hacerlo en matlab. Si observamos la fig. 12, arriba de la gráfica tenemos la opción evaluate, que evalúa varios parámetros de la f.d.p estimada. La probabilidad de falso positivo será simplemente el valor de la función de cuantía (c.d.f., cumulative density function) para x=0.35. Lo podemos ver en la siguiente figura:

Fig. 14: Evaluación de la FPR
FPR= 3.82612e-30
Comparado con el resultado teórico de Haitsma [10], se ve que hay una diferencia apreciable en los órdenes de magnitud. Esto se debe a que nosotros hemos usado una distribución lognormal, que calcula la probabilidad acumulada entre 0 y 0.35 y en el de Haitsma se usa una normal, que lo hace entre -∞ y 0.35. De hecho, si nosotros realizamos este mismo análisis con una distribución normal el resultado que se obtiene es del orden de 10-22. En realidad, si se piensa bien, esta diferencia de los órdenes de magnitud no tiene una gran importancia, el hecho importante era demostrar que la probabilidad de que se produzca un falso positivo en una aplicación normal es prácticamente despreciable, lo cual, a la vista del resultado, se puede afirmar sin miedo a equivocarse mucho.
3.2.2 Análisis experimental de robustez Con este análisis pretendemos demostrar la robustez del esquema propuesto. Es decir, tratamos de responder la cuestión de si la BER entre la versión original y la versión degradada de un clip de audio está por debajo o no del umbral α , que sigue siendo igual a 0.35. Para ello vamos a coger cuatro extractos cortos (estéreo, 44100 Hz, 16 bps) de diferentes archivos de audio de diferentes géneros musicales: el ya mencionado anteriormente “The Dream Of Unreality” de Pictures Of Shorelines, un fragmento hablado de “A Day in the Life” de The Beatles,

“Drugs or Me” de Jimmy Eat World y un fragmento de “Chariots Of Fire” de Vangelis. A cada uno de los extractos se les ha sometido a una serie de degradaciones de la señal, usando para ello el programa Adobe Audition. En la siguiente figura se muestra la apariencia general del programa:
Fig. 15: Apariencia general de Adobe Audition
Los procesos a los que han sido sometidos los fragmentos de audio son los siguientes:
• Codificación/decodificación MP3 a 128 kbps y 32 kbps. • Compresión de Amplitud con las siguientes tasas de compresión:
8.94:1 para |A|≥ -28.6 dB; 1.73:1 para -46.4 dB<|A|<-28.6 dB; 1:1.61 para |A|≤ -46.4 dB.
Fig 16: Compresión en Audition
• Ecualización Un ecualizador típico de 10 bandas con los siguientes parámetros:
Fig.17: Ecualizador utilizado
• Adición de eco • Filtrado paso de banda usando un filtro Butterworth de segundo
orden con frecuencias de corte de 100 Hz y 6000 Hz.
Fig.18: Filtro Butterworth en Audition
• Modificación de la escala temporal en un +4% y -4%. Solo cambia el tempo, el tono permanece inalterado.

Fig. 19: Expansión de un -4% en Audition
• Cambio lineal de la velocidad del +1%, -1%, +4%, -4%. Cambian tanto el tono como el tempo. No incluimos imagen ya que el menú es el mismo que en la anterior transformación, señalando en modo de expansión la opción “Volver a muestrear”.
• Adición de Ruido blanco uniforme.
Fig.20: Generación de ruido blanco
• Resampling consistente en submuestreo y posterior sobremuestreo
a 22050 Hz y otra vez a 44100 Hz.
Después de realizar dichas transformaciones (por separado, a ningún clip de audio se le hacen dos transformaciones distintas), se mide la BER entre el fragmento original y el fragmento degradado para cada una de las cuatro canciones originales. Los resultados se muestran en la siguiente tabla:
Procesado Pictures Beatles Jimmy Eat World
Vangelis
MP3@128 kbps 0.0851 0.0379 0.0666 0.0796
MP3@32 kbps 0.2313 0.0961 0.0984 0.1406
Comp. Amplitud 0.1430 0.0522 0.0722 0.1308
Ecualización 0.0343 0.0161 0.0142 0.0134
Adición de Eco 0.1707 0.0904 0.1216 0.1423
Filtrado paso banda 0.0357 0.0078 0.0106 0.0099
Esc. Tiempo +4% 0.1571 0.2208 0.1488 0.1819
Esc. Tiempo -4% 0.1980 0.1925 0.2259 0.2260
Veloc. Lineal +1% 0.1590 0.1622 0.1254 0.1057
Veloc. Lineal -1% 0.1795 0.1403 0.2695 0.2303
Veloc. Lineal +4% 0.4312 0.4437 0.3571 0.3260
Veloc. Lineal -4% 0.5288 0.4343 0.5435 0.5592
Adición Ruido 0.0809 0.0611 0.0487 0.0541
Resampling 0.000 0.000 0.000 0.000
Tabla 1: BER para los distintos tipos de degradación de señal
Vemos que sólo en los casos señalados en rojo se supera el umbral de error de 0.35. Corresponden con el caso de los cambios lineales de velocidad del 4%, tanto en un sentido como en el contrario. Esto es debido a la desviación del tramado (desalineamiento temporal) y al escalado espectral (desalineamiento frecuencial).
.


4. Mejoras Propuestas en Preprocesado En el esquema teórico de un sistema de audio fingerprinting usado para identificación se incluía la posibilidad de hacer un preprocesado de la señal de audio, pero hasta ahora no se ha usado ningún preprocesado en los análisis realizados. Gráficamente, lo que se está haciendo es lo siguiente:
Fig. 21: Esquema general de preprocesado
Lo que vemos en la gráfica es que el preprocesado debe ser considerado como el primer paso dentro del método o algoritmo que se utilice para obtener la huella. En nuestro caso vamos a seguir utilizando el algoritmo de Philips, con varias opciones de preprocesado, viendo en qué medida mejoran lo que teníamos previamente. La primera opción será un filtrado paso bajo [26], mientras que la segunda será un análisis llamado DDA (Distortion Discrminant Analysis) [27].
4.1 Filtrado Paso Bajo 4.1.1 Introducción teórica Las técnicas para tratar con una distorsión conocida son sencillas pero la distorsión real causada por la difusión es normalmente desconocida. Podemos asumir el canal como una posible combinación de todas las posibles distorsiones tales como ecualizaciones, fuentes de ruido e incluso manipulaciones de DJ’s. Para eliminar algunos efectos de dichas distorsiones, podemos asumir que son causadas por un canal LTI, lineal e invariante en el tiempo (o lentamente variante) que puede ser aproximado por un filtro lineal C(ω) que cambia lentamente con el tiempo. En el dominio logarítmico de Fourier podemos escribir que
|)(|ln|)(|ln|)(|ln ωωω XCY += (8)
Donde X(ω) e Y(ω) son las señales transmitidas y recibidas respectivamente. Si el canal que distorsiona H(ω) es lentamente variante podemos diseñar un filtro que aplicado a la secuencia temporal es capaz de minimizar los efectos del canal. El filtro con el que trabajaremos será

1
1
98.01
199.0)( −
−
−−=
z
zzH (9)
Vemos que dicho filtro presenta un polo en z=0.98 y un cero en z=1. Su respuesta en frecuencia puede observarse en la siguiente gráfica:
-0.5 -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Fig.22: Función de Transferencia de H(z)
Vemos que sólo se va a filtrar la continua. 4.1.2 Resultados prácticos En la práctica el filtrado sólo supondrá una orden de Matlab, que se incluye justo antes de llamar a la función que calcula la huella. Es decir, las huellas que comparamos serán distintas puesto que trabajarán con las señales filtradas en lugar de las originales. Por lo demás, los análisis realizados serán los mismos, el análisis de falso positivo y el análisis de robustez. Respecto al falso positivo, se sigue al pie de la letra el proceso del apartado anterior. Con dfittool se saca la curva que mejor se adapta a la distribución empírica de la BER, que en este caso vuelve a ser una lognormal con la media y varianza que se observan en el siguiente cuadro: Distribution: Lognormal Log likelihood: 281946
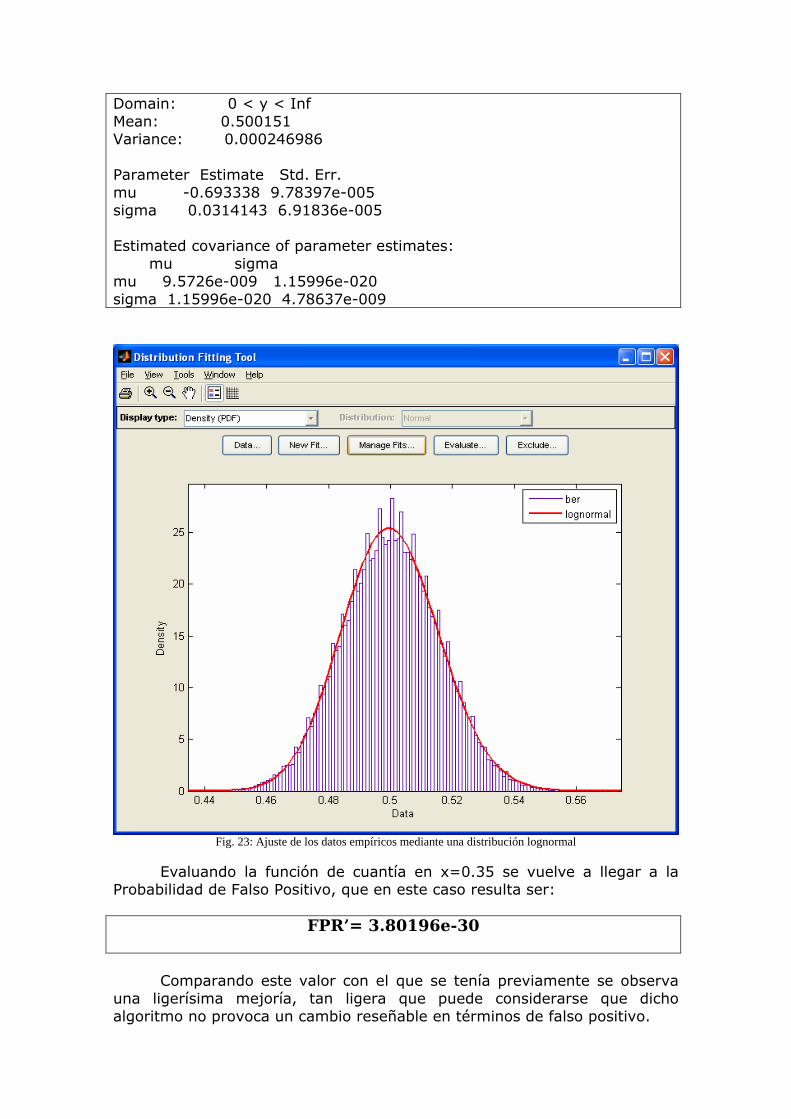
Domain: 0 < y < Inf Mean: 0.500151 Variance: 0.000246986 Parameter Estimate Std. Err. mu -0.693338 9.78397e-005 sigma 0.0314143 6.91836e-005 Estimated covariance of parameter estimates: mu sigma mu 9.5726e-009 1.15996e-020 sigma 1.15996e-020 4.78637e-009
Fig. 23: Ajuste de los datos empíricos mediante una distribución lognormal
Evaluando la función de cuantía en x=0.35 se vuelve a llegar a la Probabilidad de Falso Positivo, que en este caso resulta ser:
FPR’= 3.80196e-30
Comparando este valor con el que se tenía previamente se observa una ligerísima mejoría, tan ligera que puede considerarse que dicho algoritmo no provoca un cambio reseñable en términos de falso positivo.

El siguiente análisis a realizar es el análisis de robustez. Se usarán los mismos archivos y se realizarán los mismos análisis que en el caso de Philips sin preprocesado. Los resultados se recogen en la siguiente tabla:
Procesado Pictures Beatles Jimmy Eat World
Vangelis
MP3@128 kbps 0.0851 0.0380 0.0668 0.0796
MP3@32 kbps 0.2314 0.0960 0.0986 0.1406
Comp. Amplitud 0.1430 0.0522 0.0792 0.1308
Ecualización 0.0343 0.0161 0.0140 0.0134
Adición de Eco 0.1707 0.0904 0.1216 0.1423
Filtrado paso banda 0.0357 0.0078 0.0106 0.0099
Esc. Tiempo +4% 0.1570 0.2208 0.1488 0.1819
Esc. Tiempo -4% 0.1980 0.1923 0.2259 0.2260
Veloc. Lineal +1% 0.1590 0.1623 0.1254 0.1056
Veloc. Lineal -1% 0.1794 0.1403 0.2694 0.2305
Veloc. Lineal +4% 0.4312 0.4438 0.3574 0.3260
Veloc. Lineal -4% 0.5288 0.4342 0.5438 0.5592
Adición Ruido 0.0809 0.0611 0.0487 0.0540
Resampling 0.0000 0.0000 0.0000 0.0000 Tabla 2: BER para distintas degradaciones filtradas
En la siguiente tabla se muestra una comparación de la mejora obtenida en probabilidad de error. En verde se representa una disminución de la BER y en rojo, un aumento.
Procesado Pictures Beatles Jimmy Eat World
Vangelis
MP3@128 kbps 0 0.0001 0.0002 0 MP3@32 kbps 0.0001 0.0001 0.0002 0 Comp. Amplitud 0 0 0 0 Ecualización 0 0 0.0002 0
Adición de Eco 0 0 0 0 Filtrado paso banda 0 0 0 0 Esc. Tiempo +4% 0.0001 0 0 0 Esc. Tiempo -4% 0 0,0002 0 0 Veloc. Lineal +1% 0 0.0001 0 0.0001 Veloc. Lineal -1% 0.0001 0 0.0001 0.0002 Veloc. Lineal +4% 0 0.0001 0.0003 0 Veloc. Lineal -4% 0 0,0001 0.0003 0 Adición Ruido 0 0 0 0.0001 Resampling 0 0 0 0
Tabla 3: Mejora por el uso del filtrado
La misma información expresada en la tabla la vamos a representar gráficamente en cuatro gráficas, una para cada archivo. En cada una de

ellas representaremos dos curvas de errores, una sin preprocesar y otra después de preprocesar. En el eje X los números del 1-14 se corresponden a las 14 medidas realizadas de la siguiente forma:
1 MP3@128 kbps 8 Esc. Tiempo -4% 2 MP3@32 kbps 9 Veloc. Lineal +1% 3 Comp. Amplitud 10 Veloc. Lineal -1% 4 Ecualización 11 Veloc. Lineal +4% 5 Adición de Eco 12 Veloc. Lineal -4% 6 Filtrado paso banda 13 Adición Ruido 7 Esc. Tiempo +4% 14 Resampling
Pictures
0
0,1
0,2
0,3
0,4
0,5
0,6
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Sin preproc
Con preproc.
Fig.24: Comparación de la BER con y sin preprocesado para el primer archivo
Beatles
00,050,1
0,150,2
0,250,3
0,350,4
0,450,5
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Sin preproc
Con preproc.
Fig.25: Comparación de la BER para el segundo archivo
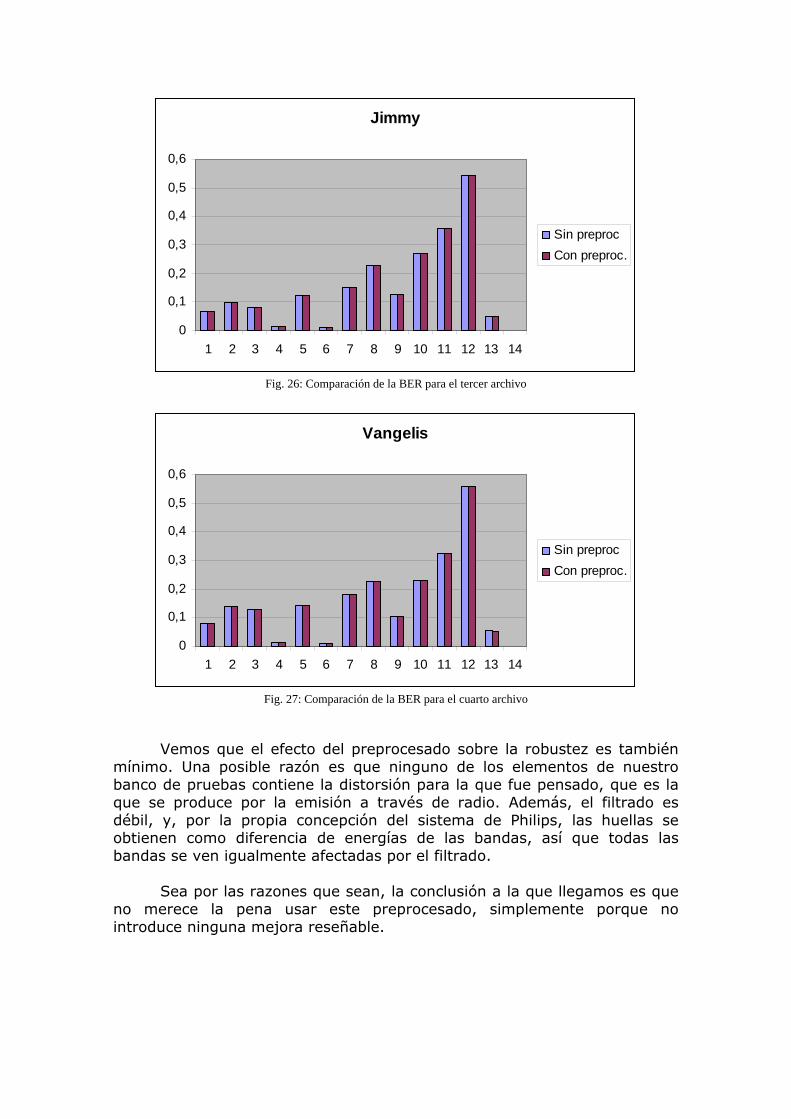
Jimmy
0
0,1
0,2
0,3
0,4
0,5
0,6
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Sin preproc
Con preproc.
Fig. 26: Comparación de la BER para el tercer archivo
Vangelis
0
0,1
0,2
0,3
0,4
0,5
0,6
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Sin preproc
Con preproc.
Fig. 27: Comparación de la BER para el cuarto archivo
Vemos que el efecto del preprocesado sobre la robustez es también mínimo. Una posible razón es que ninguno de los elementos de nuestro banco de pruebas contiene la distorsión para la que fue pensado, que es la que se produce por la emisión a través de radio. Además, el filtrado es débil, y, por la propia concepción del sistema de Philips, las huellas se obtienen como diferencia de energías de las bandas, así que todas las bandas se ven igualmente afectadas por el filtrado. Sea por las razones que sean, la conclusión a la que llegamos es que no merece la pena usar este preprocesado, simplemente porque no introduce ninguna mejora reseñable.

4.2 Distortion Discriminant Analysis 4.2.1 Introducción teórica En [27] se describe un nuevo algoritmo, llamado DDA (Distortion Discriminant Analysis) para extraer automáticamente a partir del audio características robustas frente al ruido. Las características son computadas por una red neuronal lineal, convolucional donde cada capa realiza una versión de la reducción dimensional mediante el Análisis del Componente Principal orientado (OPCA). Para datos de grandes dimensiones tales como el audio, OPCA puede ser aplicado en capas. Consideremos, por ejemplo, la extracción de una huella de dimensión 64 a partir de 6 segundos de audio. Si primero convertimos la señal de audio a mono y submuestreamos a 11025 Hz, la extracción de características debe mapear un vector de dimensión 66150 a un vector de dimensión 64. Resolver directamente el problema de autovalores generalizados es en este caso irrealizable. En vez de esto, OPCA puede ser aplicado en dos capas, donde la primera capa opera con un espectro logarítmico computado en una ventana pequeña y la segunda opera con vectores que se construyen agregando los vectores producidos por la primera capa. Es a este enfoque a lo que se le llama DDA. DDA es un método lineal; las proyecciones que ocurren en una capa dada pueden ser vistas como una convolución. Por tanto DDA puede ser vista como una red neuronal lineal y convolucional donde los pesos se escogen usando OPCA. El sistema con el que se va a trabajar en primer lugar convierte la señal de audio estéreo a mono y luego submuestrea a 11025 Hz. La señal es a continuación dividida en tramas de longitud fija de 372 ms que se solapan por la mitad. A cada trama se le aplica una MCLT (Modulated Complex Lapped Transform, una Transformada de Fourier enventanada) [28]. Tomando el logaritmo del módulo de cada coeficiente MCLT se obtiene un espectro logarítmico. La MCLT se considera una extensión de la MLT, pero haciendo uso de la información de fase al ser compleja. En MCLT se definen las funciones base de análisis (transformada directa) y síntesis (transformada inversa) pa(n,k) y ps(n,k) como modulación en coseno y en seno de las ventanas de análisis y síntesis, ha(n) y hs(n):
Π
+−==M
nnhnh sa 22
1sin)()( (10)
( ) ),(),(, knjpknpknp sa
caa −= (11)
Π
+
++=M
kM
nM
nhknp aca 2
1
2
1cos
2)(),( (12)
Π
+
++=M
kM
nM
nhknp asa 2
1
2
1sin
2)(),( (13)

( ) [ ]),(),(2
1, knjpknpknp s
scss += (14)
Π
+
++=M
kM
nM
nhknp scs 2
1
2
1cos
2)(),( (15)
Π
+
++=M
kM
nM
nhknp asa 2
1
2
1sin
2)(),( (16)
Donde el índice de tiempo n varía de 0 a 2M-1 y el eje de frecuencias
k varía de 0 a M-1 siendo M el tamaño del bloque de entrada. Los coeficientes MCLT X(k) se computan a partir del bloque de entrada x(n) como
∑−
=
=12
0
),()()(M
na knpnxkX (17)
Por cada M muestras reales de la señal de entrada se obtienen M
coeficientes en frecuencia complejos [29]. Una vez que se tiene el flujo de audio transformado, se El flujo de
audio realizan dos pasos de preprocesado en cada trama que suprimen las distorsiones específicas y fácilmente identificables. Ambos pasos se realizan por separado, es decir, primero haremos todos los estudios para la señal resultante de aplicar el primer paso y luego los haremos para la señal resultante de aplicar sólo el segundo. La posibilidad de combinarlos ambos o combinarlos con otros posibles preprocesados queda fuera del objetivo de este proyecto.
4.2.2- Primer Paso de Preprocesado El primer paso de preprocesado elimina distorsiones causadas por ecualización en frecuencia y ajuste de volumen. Este paso aplica un filtro paso-bajo al espectro logarítmico tomando la DCT (Transformada del Coseno) del espectro, multiplicando cada coeficiente DCT por un valor que va linealmente desde 1 para el primer coeficiente a 0 para el sexto y superiores y entonces realizando la DCT inversa. Esto da como resultado una suave aproximación A al espectro logarítmico. A es a continuación bajado 6 dB y cortado en -70 dB. El vector de salida de este primer paso de preprocesado es la diferencia componente a componente entre el espectro logarítmico y A si la diferencia es positiva y cero en caso contrario. Esta señal está en el dominio MCLT, por lo que antes de introducirla en el algoritmo de Philips hay que hacer la MCLT inversa. Análogamente a

como se definió la transformada directa en (17), a partir de una señal transformada Y(k) (que puede ser igual a X(k) o no), se define la señal en el dominio del tiempo y(n) como:
∑−
=
=1
0
),()()(M
ks knpkYny (18)
Lo que no queda claro en [28] es como realizar la superposición de
las diversas y(n). Si se observa bien, por cada M muestras de Y(k), la fórmula indicada anteriormente obtiene 2M muestras, que deben superponerse, ya que, como hemos indicado anteriormente, por cada M nuevas muestras de x(n) se obtienen M nuevas muestras transformadas. Para inferir el funcionamiento de la transformada, se ha propuesto un ejemplo concreto, con un vector de longitud 16 y tamaño de trama M=4:
x(n)=[1 1 1 1 1 2 3 4 1 0 1 0 1 1 1 1]
Al ser M=4, se divide x(n) en 4 tramas de tamaño=2M=8. A cada una de estas tramas se le hace la transformada aplicando las ecuaciones (10)-(13) y (17), dando como resultado:
x1(n)=[1 1 1 1 1 2 3 4]
X1(k)=[3.6913+ j1.7315
1.0614 – j0.5158 0.3573 – j0.2452 0.0381 + j0.1501]
x2(n)=[1 2 3 4 1 0 1 0]
X2(k)=[2.6173+ j5.2301
-2.9375 – j1.0898 0.8656 – j1.6310 0.9239 + j0.1585]
x3(n)=[1 0 1 0 1 1 1 1]
X3(k)=[1.6913+ j1.0381
0.4619 + j0.1913 0.1913 + j0.4619 -0.9619 - j0.3087]
x4(n)=[1 1 1 1 1 1 1 1]
X4(k)=[2+ j2 0 + j0 0+ j0 0 + j0]
Una vez realizado este paso, lo que hacemos a continuación es hacer aplicar las ecuaciones (14)-(16) y (18) para realizar la transformada inversa. Así, se obtienen como resultado:
y1(n)
y2(n)
y3(n)
y4(n)
0.0381 - j0.3098 0.3087 - j0.6290 0.6913 – j0.7807 0.9619 – j0.4862 0.9619 – j0.4967 1.3827 – j0.1416 0.9260 +j0.5513 0.1522 +j0.3330
0.0381 - j0.3487 0.6173 – j1.0655 2.0740 – j1.5274 3.8478 +j0.8742 0.9619 +j2.8086 0.0000 – j0.8361 0.3087 +j0.7568 0.0000 +j0.2791
0.0381 - j0.0688 0.0000 - j0.4619 0.6913 – j0.2310 0.0000 – j0.1913 0.9619 – j0.5845 0.6913 +j0.4619 0.3087 +j0.2310 0.0381 +j0.1913
0.0381 - j0.1913 0.3087 - j0.4619 0.6913 – j0.4619 0.9619 – j0.1913 0.9619 +j0.1913 0.6913 +j0.4619 0.3087 +j0.4619 0.0381 +j0.1913
Lo siguiente que hay que saber es cómo recuperar la señal original
x(n) (de longitud 16 y real) a partir de estos 32 elementos complejos. Lo primero que observamos es que si sumamos las partes reales de los últimos cuatro elementos de cada una de las listas con las partes reales de los cuatro primeros de la lista siguiente se obtiene lo siguiente:
0.9619 0.6913 + 0.3087 0.0381
0.0381 0.3087 = 0.6913 0.9619
1 1 1 1
0.9619 1.3827 + 0.9260 0.1522
0.0381 0.6173 = 2.0740 3.8478
1 2 3 4
0.9619 0.0000+ 0.3087 0.0000
0.0381 0.0000 = 0.6913 0.0000
1 0 1 0
0.9619 0.6913+ 0.3087 0.0381
0.0381 0.3087 = 0.6913 0.9619
1 1 1 1
Vemos que dichos valores coinciden con los valores de x(n). Y no es fruto de la casualidad para este ejemplo concreto, para otras señales x(n), de la misma longitud o más largas se comprueba lo mismo. El hecho de enlazar la primera con la última es porque al hacer la MCLT también lo hemos enlazado. En [28] ese aspecto no queda claro, podría haberse hecho también rellenando con ceros media trama al inicio y media trama al final, pero hemos optado por esta posibilidad. Evidentemente, este es el algoritmo que simularemos en Matlab (ver anexo). Por último, lo que falta antes de introducir la señal resultante de la transformada inversa en el algoritmo de Philips es volver a submuestrear, de 11025 Hz a los 5512,5 Hz a los que trabaja dicho algoritmo. Una vez hecho esto ya podemos realizar los análisis de falso positivo y de robustez.

4.2.2.1- Análisis de falso positivo El análisis vuelve a ser análogo a los anteriores y se utilizan los mismos archivos, el extracto de 3 segundos de “Pictures” y el trozo de 20 minutos sacado de la radio comercial. Utilizando dfittool, la distribución que mejor se asemeja al error vuelve a ser una lognormal, con los siguientes parámetros: Distribution: Lognormal Log likelihood: 33842.2 Domain: 0 < y < Inf Mean: 0.499933 Variance: 0.000279045 Parameter Estimate Std. Err. mu -0.69384 0.000296932 sigma 0.0334045 0.000209975 Estimated covariance of parameter estimates: mu sigma mu 8.81684e-008 -3.61613e-021 sigma -3.61613e-021 4.40894e-008
Fig. 28: Distribución de la BER comparada con una distribución lognormal
Evaluando la función de cuantía para x=0.35 se llega a la siguiente Probabilidad de Falso Positivo (marcada en rojo):

Fig. 29: Probabilidad de falso positivo
Comparando este valor, se ve que es mayor que el obtenido en los dos análisis anteriores, sin embargo podemos aplicar aquí el mismo razonamiento que aplicamos la primera vez. Un cambio en el valor del orden de 10-30 a 10-27 no es grave, podemos seguir considerándolo despreciable. El principal problema que observamos es que aumenta mucho la complejidad computacional del análisis, que dura del orden de 10-15 veces más que sin el preprocesado. Una posible solución sería haber utilizado un algoritmo rápido para la MCLT, descrito en [28], que obtiene la transformada a partir de una DCT-IV y una DST-IV, pero dada la complejidad y la dificultad para programarlo se ha optado por no utilizarlo y quedarnos con el primer algoritmo.
4.2.2.2- Análisis de Robustez
El análisis realizado es exactamente el mismo de los apartados anteriores, con los mismos archivos de tres segundos de música. En la siguiente tabla se recogen los resultados obtenidos para la BER:
Procesado Pictures Beatles Jimmy Eat World
Vangelis
MP3@128 kbps 0.1411 0.0964 0.0960 0.1393
MP3@32 kbps 0.2232 0.1544 0.1481 0.2026
Comp. Amplitud 0.0803 0.0950 0.0539 0.0643
Ecualización 0.0367 0.0294 0.0281 0.0388
Adición de Eco 0.1356 0.2107 0.1160 0.1144
Filtrado paso banda 0.0106 0.0053 0.0053 0.0085
Esc. Tiempo +4% 0.1304 0.2010 0.1365 0.1413
Esc. Tiempo -4% 0.1482 0.1431 0.1135 0.1272
Veloc. Lineal +1% 0.1718 0.1596 0.1297 0.1576
Veloc. Lineal -1% 0.1896 0.1615 0.2602 0.2775
Veloc. Lineal +4% 0.3907 0.4196 0.3824 0.3185
Veloc. Lineal -4% 0.4705 0.4315 0.4542 0.4080
Adición Ruido 0.0922 0.1863 0.0565 0.0681
Resampling 0.0000 0.0000 0.0000 0.0000 Tabla 4: BER para las distintas degradaciones preprocesadas
Al igual que en el apartado anterior, en la siguiente tabla se recoge la
comparación de la BER obtenida con la BER que se obtuvo sin realizar ningún preprocesado. Los valores en rojo indican un incremento de la BER respecto a la original y los valores en verde, una disminución del error:
Procesado Pictures Beatles Jimmy Eat World
Vangelis
MP3@128 kbps 0,056 0,0585 0,0294 0,0597
MP3@32 kbps 0,0081 0,0583 0,0497 0,062
Comp. Amplitud 0,0627 0,0428 0,0253 0,0665
Ecualización 0,0024 0,0133 0,0139 0,0254
Adición de Eco 0,0351 0,1203 0,0056 0,0279
Filtrado paso banda 0,0251 0,0025 0,0053 0,0014
Esc. Tiempo +4% 0,0267 0,0198 0,0123 0,0406
Esc. Tiempo -4% 0,0498 0,0494 0,1124 0,0988
Veloc. Lineal +1% 0,0128 0,0026 0,0043 0,0519
Veloc. Lineal -1% 0,0101 0,0212 0,0093 0,0472
Veloc. Lineal +4% 0,0405 0,0241 0,0253 0,0075
Veloc. Lineal -4% 0,0583 0,0028 0,0893 0,1512
Adición Ruido 0,0113 0,1252 0,0078 0,014
Resampling 0 0 0 0 Tabla 5: Comparación de las BER con y sin preprocesado
A continuación volveremos a representar en gráficas independientes
los resultados para cada uno de los cuatro archivos. En este apartado resultarán más interesantes que en el anterior, donde el preprocesado prácticamente no introducía ningún cambio en las probabilidades de error. La correspondencia entre los números en el eje de abscisas y las distorsiones de la señal es la misma del apartado anterior:
1 MP3@128 kbps 8 Esc. Tiempo -4% 2 MP3@32 kbps 9 Veloc. Lineal +1% 3 Comp. Amplitud 10 Veloc. Lineal -1% 4 Ecualización 11 Veloc. Lineal +4% 5 Adición de Eco 12 Veloc. Lineal -4% 6 Filtrado paso banda 13 Adición Ruido 7 Esc. Tiempo +4% 14 Resampling
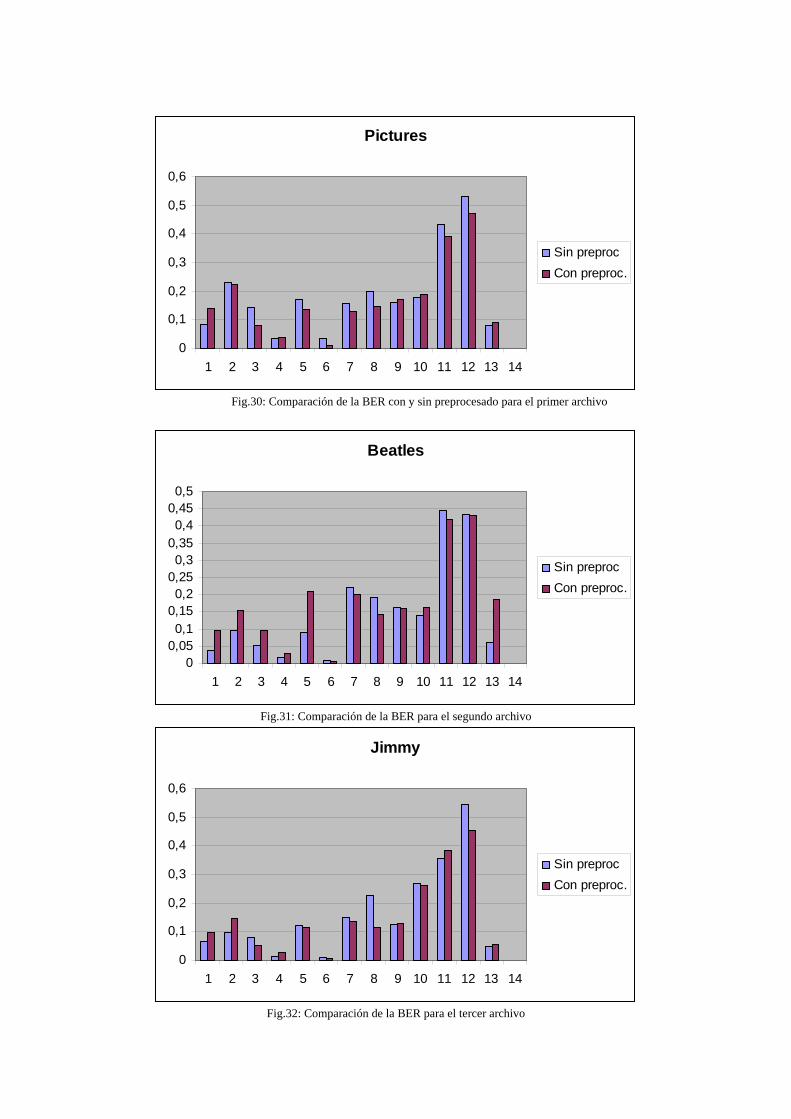
Pictures
0
0,1
0,2
0,3
0,4
0,5
0,6
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Sin preproc
Con preproc.
Fig.30: Comparación de la BER con y sin preprocesado para el primer archivo
Beatles
00,050,1
0,150,2
0,250,3
0,350,4
0,450,5
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Sin preproc
Con preproc.
Fig.31: Comparación de la BER para el segundo archivo
Jimmy
0
0,1
0,2
0,3
0,4
0,5
0,6
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Sin preproc
Con preproc.
Fig.32: Comparación de la BER para el tercer archivo
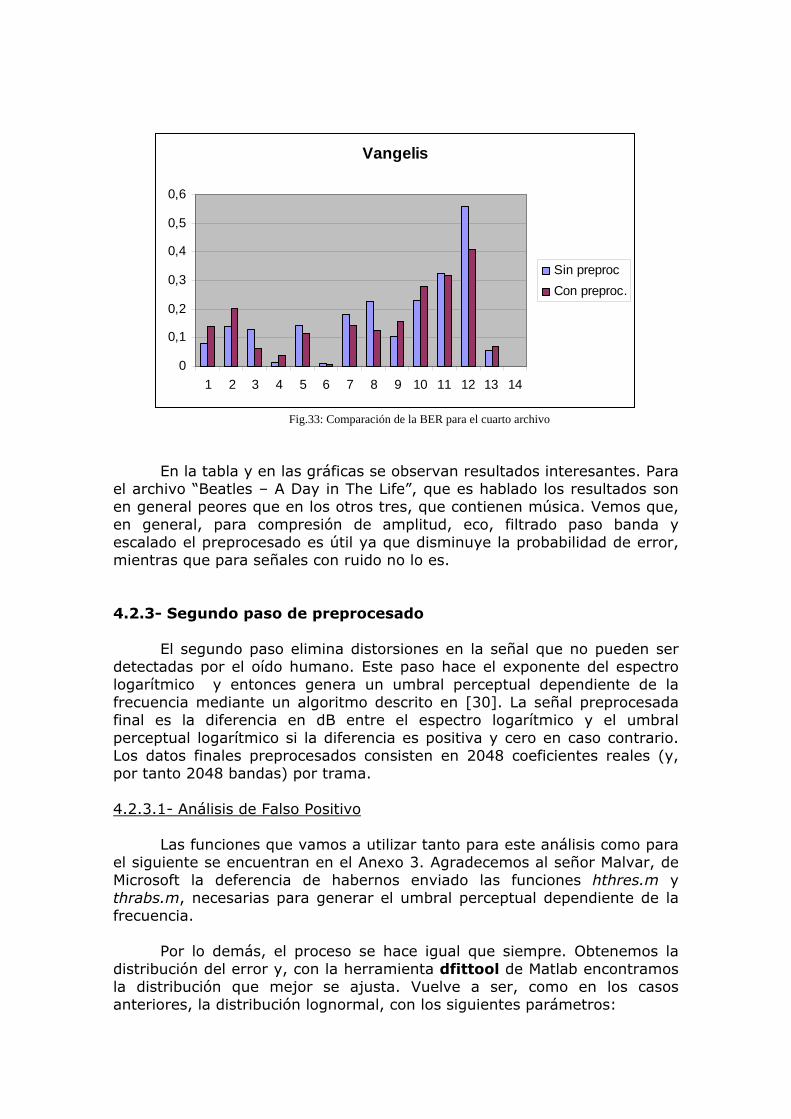
Vangelis
0
0,1
0,2
0,3
0,4
0,5
0,6
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Sin preproc
Con preproc.
Fig.33: Comparación de la BER para el cuarto archivo
En la tabla y en las gráficas se observan resultados interesantes. Para
el archivo “Beatles – A Day in The Life”, que es hablado los resultados son en general peores que en los otros tres, que contienen música. Vemos que, en general, para compresión de amplitud, eco, filtrado paso banda y escalado el preprocesado es útil ya que disminuye la probabilidad de error, mientras que para señales con ruido no lo es.
4.2.3- Segundo paso de preprocesado
El segundo paso elimina distorsiones en la señal que no pueden ser detectadas por el oído humano. Este paso hace el exponente del espectro logarítmico y entonces genera un umbral perceptual dependiente de la frecuencia mediante un algoritmo descrito en [30]. La señal preprocesada final es la diferencia en dB entre el espectro logarítmico y el umbral perceptual logarítmico si la diferencia es positiva y cero en caso contrario. Los datos finales preprocesados consisten en 2048 coeficientes reales (y, por tanto 2048 bandas) por trama.
4.2.3.1- Análisis de Falso Positivo Las funciones que vamos a utilizar tanto para este análisis como para el siguiente se encuentran en el Anexo 3. Agradecemos al señor Malvar, de Microsoft la deferencia de habernos enviado las funciones hthres.m y thrabs.m, necesarias para generar el umbral perceptual dependiente de la frecuencia. Por lo demás, el proceso se hace igual que siempre. Obtenemos la distribución del error y, con la herramienta dfittool de Matlab encontramos la distribución que mejor se ajusta. Vuelve a ser, como en los casos anteriores, la distribución lognormal, con los siguientes parámetros:

Distribution: Lognormal
Log likelihood: 34354.3 Domain: 0 < y < Inf Mean: 0.500182 Variance: 0.00025732 Parameter Estimate Std. Err. mu -0.693297 0.000285003 sigma 0.0320625 0.000201539 Estimated covariance of parameter estimates: mu sigma mu 8.12265e-008 -7.30711e-021 sigma -7.30711e-021 4.06181e-008
En la siguiente gráfica se muestra la distribución del error y la distribución lognormal, superpuestas
Fig. 34: Distribución de la BER y distribución lognormal
Finalmente, el valor de probabilidad de falso positivo que se obtiene se muestra en la siguiente gráfica:

Fig.35: Probabilidad de Falso Positivo
Podemos observar que es ligeramente peor que el original, pero ligeramente mejor que el que se obtenía en el análisis anterior. De todas formas, lo importante es que podemos seguir diciendo que la probabilidad de falso positivo sigue siendo prácticamente despreciable. 4.2.3.2- Análisis de robustez El proceso vuelve a ser el mismo, con los mismos archivos de los anteriores análisis así que pasamos directamente a los resultados, que se muestran en la siguiente tabla:
Procesado Pictures Beatles Jimmy Eat World
Vangelis
MP3@128 kbps 0.1353 0.1083 0.1050 0.1067
MP3@32 kbps 0.2050 0.1668 0.1489 0.1749
Comp. Amplitud 0.0924 0.1249 0.0587 0.0606
Ecualización 0.0496 0.0353 0.0335 0.0329
Adición de Eco 0.1231 0.2124 0.1369 0.1339
Filtrado paso banda 0.0032 0.0005 0.0005 0.0006
Esc. Tiempo +4% 0.1501 0.2125 0.1600 0.1709
Esc. Tiempo -4% 0.1731 0.1536 0.1303 0.1499
Veloc. Lineal +1% 0.1844 0.1838 0.1610 0.1613
Veloc. Lineal -1% 0.2071 0.1836 0.2860 0.2810
Veloc. Lineal +4% 0.3892 0.4582 0.3572 0.3175
Veloc. Lineal -4% 0.4688 0.4420 0.4317 0.3964
Adición Ruido 0.0719 0.1825 0.0442 0.0376
Resampling 0 0 0 0.0000 Tabla 6: BER para los distintos tipos de degradación

En la siguiente tabla se muestra la comparación entre los resultados obtenidos en este análisis y los resultados sin ningún preprocesado. Los números indican la diferencia entre ambos (en rojo implica que en este análisis es mayor y en verde, que es menor).
Procesado Pictures Beatles Jimmy Eat World
Vangelis
MP3@128 kbps 0,0502 0,0704 0,0384 0,0271
MP3@32 kbps 0,0263 0,0707 0,0505 0,0343
Comp. Amplitud 0,0506 0,0727 0,0205 0,0702
Ecualización 0,0153 0,0192 0,0193 0,0195
Adición de Eco 0,0476 0,122 0,0153 0,0084
Filtrado paso banda 0,0325 0,0073 0,0101 0,0093
Esc. Tiempo +4% 0,007 0,0083 0,0112 0,011
Esc. Tiempo -4% 0,0249 0,0389 0,0956 0,0761
Veloc. Lineal +1% 0,0254 0,0216 0,0356 0,0556
Veloc. Lineal -1% 0,0276 0,0433 0,0165 0,0507
Veloc. Lineal +4% 0,042 0,0145 0,0001 0,0085
Veloc. Lineal -4% 0,06 0,0077 0,1118 0,1628
Adición Ruido 0,009 0,1214 0,0045 0,0165
Resampling 0 0 0 0 Tabla 7: Comparación de la BER con este preprocesado y con ninguno
De la tabla podemos extraer varias conclusiones. Primero, parece que el algoritmo funciona mejor para el primer y el cuarto archivo, funciona regular para el archivo de Jimmy y, al igual que en el paso anterior, bastante mal para el archivo de los Beatles. Si lo analizamos por distorsiones, funciona bien para señales filtradas paso-banda, señales con escala de tiempo modificada y con cambio lineal de la velocidad y para señales con ruido.
Para representar los resultados gráficamente se ha considerado interesante incluir en las gráficas también los resultados del análisis anterior, el del primer paso. Así, se obtienen las siguientes gráficas, donde los números en el eje de abscisas se corresponden con las siguientes distorsiones:
1 MP3@128 kbps 8 Esc. Tiempo -4% 2 MP3@32 kbps 9 Veloc. Lineal +1% 3 Comp. Amplitud 10 Veloc. Lineal -1% 4 Ecualización 11 Veloc. Lineal +4% 5 Adición de Eco 12 Veloc. Lineal -4% 6 Filtrado paso banda 13 Adición Ruido 7 Esc. Tiempo +4% 14 Resampling

Pictures
0
0,1
0,2
0,3
0,4
0,5
0,6
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Sin preproc
Con preproc.1
Con preproc.2
Fig.36: Comparación de la BER sin preprocesado y con preprocesados para el primer archivo
Beatles
00,050,1
0,150,2
0,250,3
0,350,4
0,450,5
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Sin preproc
Con preproc.1
Con preproc.2
Fig.37: Comparación de la BER sin preprocesado y con preprocesados para el segundo archivo
Jimmy
0
0,1
0,2
0,3
0,4
0,5
0,6
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Sin preproc
Con preproc.1
Con preproc.2
Fig.38: Comparación de la BER sin preprocesado y con preprocesados para el tercer archivo
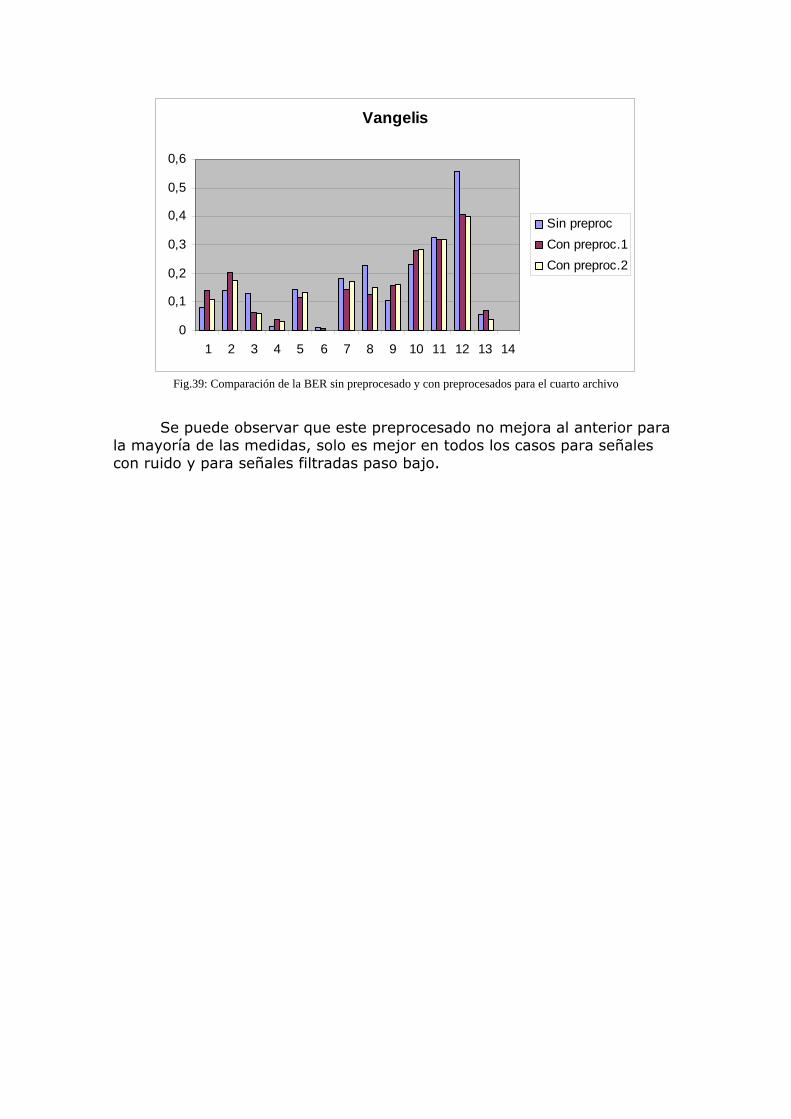
Vangelis
0
0,1
0,2
0,3
0,4
0,5
0,6
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Sin preproc
Con preproc.1
Con preproc.2
Fig.39: Comparación de la BER sin preprocesado y con preprocesados para el cuarto archivo
Se puede observar que este preprocesado no mejora al anterior para la mayoría de las medidas, solo es mejor en todos los casos para señales con ruido y para señales filtradas paso bajo.

5. Referencias
[1]. “Audio Fingerprinting: Concepts And Applications”, Pedro Cano, Eloi Batlle, Emilia Gomez, Leandro de C.T.Gomes, and Madeleine Bonnet ; Studies in Computational Intelligence (SCI) 2, 233–245, 2005.
[2]. “Mixed watermarking fingerprinting approach for integrity
verification of audio recordings”. Gómez E, Cano P, Gomes L de C T, Batlle E, Bonnet M (2002) Proc. of the Int. Telecommunications Symposium, Natal, Brazil.
[3]. “A perceptual audio hashing algorithm: a tool for robust audio
identification and information hiding”, M. Mihak y R. Venkatesan, in 4th Int. Information Hiding Workshop, Pittsburg, PA, April 2001.
[4]. “Robust audio hashing for content identification” Haitsma J, Kalker T, Oostveen J. Proc. of the Content-Based Multimedia Indexing, Firenze, Italy (2001)
[5]. “Audio Watermarking and Fingerprinting: For Which
Applications?”, Pedro Cano, Eloi Batlle, Emilia Gomez, Leandro de C.T.Gomes, and Madeleine Bonnet, Journal of New Music Research 32(1) pps. 65–82, 2003.
[6]. “Digital watermarks for audio signals” Boney, L., Tewfik, A., & Hamdy, K. (1996). IEEE Proceedings Multimedia.
[7]. “Techniques for data hiding”. Bender, W., Gruhl, D., Morimoto, N., & Lu, A., (1996). IBM System Journal vol. 35, pp. 313-336.
[8]. “Digital watermarking of audio signals using a psychoacoustic
auditory model and spread-spectrum theory”. Garcia, R. A. (1999). 107th AES Convention.
[9]. “A review of audio fingerprinting”, Cano, P., E. Batlle, T. Kalker,
and J. Haitsma Journal of VLSI Signal Processing 41, 271–284, 2005
[10]. “A Highly Robust Audio Fingerprinting System”, Jaap Haitsma, Ton Kalker, in Proceedings of the International Symposium on Music Information Retrieval, Paris, France, 2002.
[11]. “Detection and Logging Advertisements Using its Sound”, J. Lourens, in Proc. of the COMSIG, Johannesburg, 1990.
[12]. “Identification of highly distorted audio material for querying
large scale databases”, F. Kurth, A. Ribbrock, and M. Clausen, in Proc.
AES 112th Int. Conv., Munich, Germany, May 2002.
[13]. “Short-Term Sound Stream Characterisation for Reliable, Real-
Time Occurrence Monitoring of Given Sound-Prints”, G. Richly, L. Varga, F. Kovàs, and G. Hosszú, in Proc.10th Mediterranean Electrotechnical Conference, MEleCon, 2000.

[14]. “Content-based identification of audio material using mpeg-7
low level description”, E. Allamanche, J. Herre, O. Helmuth, B. Fröba, T. Kasten, and M. Cremer in Proc. of the Int. Symp. Of Music Information Retrieval, Indiana, USA, Oct. 2001.
[15]. “A new approach to the automatic recognition of musical
recordings”, C. Papaodysseus, G. Roussopoulos, D. Fragoulis, T. Panagopoulos, and C. Alexiou, J. Audio Eng. Soc., vol. 49, no. 1/2, 2001, pp. 23–35.
[16]. “Very Quick Audio Searching: Introducing Global Pruning to the
Time-Series Active Search”, A. Kimura, K. Kashino, T. Kurozumi, and H. Murase, in Proc. of Int. Conf. on Computational Intelligence and Multimedia Applications, Salt Lake City, Utah, May 2001.
[17]. “Modulation frequency features for audio fingerprinting”, S. Sukittanon and L. Atlas in Proc. of the ICASSP, May 2002.
[18]. “Extracting Noise-Robust Features from Audio Data,” C. Burges, J. Platt, and S. Jana, in Proc. of the ICASSP, Florida, USA, May 2002.
[19]. “Robust Sound Modelling for Song Detection in Broadcast
Audio”, P. Cano, E. Batlle, H. Mayer, and H. Neuschmied, in Proc. AES 112th Int. Conv., Munich, Germany, May 2002.
[20]. “Method and article of manufacture for content-based analysis,
storage, retrieval and segmentation of audio information”, T. Blum, D. Keislar, J. Wheaton, and E. Wold, U.S. Patent 5,918,223, June 1999.
[21]. “Automatic Song Identification in Noisy Broadcast Audio,” E. Batlle, J. Masip, and E. Guaus, in Proc. of the SIP, Aug. 2002.
[22]. “Fast Subsequence Matching in Time-Series Databases”, C. Faloutsos, M. Ranganathan, and Y. Manolopoulos in Proc. On the ACM
SIGMOD, Minneapolis, MN, 1994, pp. 419–429.
[23]. Modern Information Retrieval, R. Baeza-Yates and B. Ribeiro-Neto Addison Wesley, 1999.
[24]. “Audio Fingerprinting: Nearest Neighbour Search in High
Dimensional Binary Spaces,” M. Miller, M. Rodriguez, and I. Cox in 5th IEEE Int. Workshop on Multimedia Signal Processing: Special session on Media Recognition, US Virgin Islands, USA, Dec. 2002.
[25]. “System and Methods for Recognizing Sound and Music
Signals in High Noise and Distortion”, A.L.-C.Wang and J. Smith II, U.S. Patent Application Publication US 2002/0083060 A1, 2002.
[26]. “System Analysis and Performance Tuning for Broadcast Audio
Fingerprinting”, E. Battle, J. Masip, P. Cano, Proc. of the 6th Int. Conference on Digital Audio Effects, London, 6-11 September 2003
[27]. “Distortion Discriminant Analysis for Audio Fingerprinting”, Christopher J.C. Burges, John C. Platt and Soumya Jana, IEEE Transactions on Speech and Audio Processing, Vol. XX, NO. Y, Month ZZ

[28]. “A Modulated Complex Lapped Transform and its Applications
to Audio Processing” H. Malvar IEEE Transactions on Speech and Audio Processing 1999 pag. 1421-1424
[29]. “The Modulated Lapped Transform, Its Time-Varying Forms and
Its Applications to Audio Coding Standards” Seymour Shlien IEEE Transactions on Speech and Audio Processing Vol.5 No4 July 1997
[30]. “Auditory masking in audio compression,” H. Malvar, in Audio
Anecdotes, K. Greenebaum, Ed. A. K. Peters Ltd., 2001.

Anexo 1: Funciones usadas para el algoritmo de Philips Función principal para el cálculo de la huella % archivo: fingerprint_princ.m % % Función que, dado un archivo de audio, calcula su huella. % function F=fingerprint(audio) Fs=44100/8; %frecuencia de muestreo de la señal de audio N=2048; %numero de muestras por frame overlap=31/32; %factor de overlap desplaz=floor(N-N*overlap); %desplazamiento de la ventana para cumplir con el factor de overlap num_band=33; %numero de bandas en que dividimos cada frame f_inferior=300; %frecuencia inferior para la division en bandas f_superior=2000; %frecuencia superior para la division en bandas ventana=hanning(N); %Para solventar el problema de que el numero de mue stras no es %múltiplo de N, nos quedarnos con el numero entero de muestras de la %señal mas alto posible que sea multiplo de 'desplaz' numero_fingers=floor((length(audio)-N)/desplaz); %numero de huellas sin contar la primera audio=audio(1:(N+numero_fingers*desplaz)); Eperanterior=zeros(num_band,1); %energía de las bandas del frame anterior m=1; %índices para guardar los bits de los fingerprints %Calculo del vector para la división en 33 bandas s eparadas %logarítmicamente entre 300 Hz y 2000 Hz indice=logspace(log10(f_inferior),log10(f_superior) ,num_band+1); indice=round(indice*N/Fs); %Bucle que divide la señal en tramas y las procesa for k=0:desplaz:length(audio)-N frame=audio(k+1:k+N,1); frame=ventana.*frame; FRAME=abs(fft(frame)); % Se divide la trama en bandas bandaSup=FRAME(indice(num_band):indice(num_band +1),1);

for k=num_band:-1:2 banda=FRAME(indice(k-1):indice(k),1); % Se llama a la función que calcula la energía de l as bandas Eactual=calc_energia(banda); Esuperior=calc_energia(bandaSup); %Se obtiene el bit F(m,k-1) de la huella F(m,k-1)=bit_derivation(Eactual,Esuperior,E peranterior(k-1,1),Eperanterior(k,1)); %actualizamos variables bandaSup=banda; Eperanterior(k,1)=Esuperior; %Para evitar coger un valor equivocado al llamar a "bit_derivation" if k==2 Eperanterior(k-1,1)=Eactual; end end m=m+1; end

Función que calcula la energía de las bandas % archivo: calc_energia.m % % Función que calcula la energía de una banda, % empleada para el calculo del fingerprints function E=calc_energ(x) [M,N]=size(x); if M>=N E=x'*x; else E=x*x'; end Función que calcula cada bit de la huella % Archivo: bit_derivation.m % % Función que calcula un bit de la fingerprint % % Parámetros: % e: energía de la banda % e_banterior: energía de la banda anterior % e_tanterior: energía de la banda en el periodo anterior % e_tb: energía de la banda posterior en el perio do anterior function F=bit_derivation(e,e_banterior,e_tanterior,e_tb) ED=e-e_banterior-(e_tanterior-e_tb); if ED>0 F=1; else F=0; end

Script del análisis de falso positivo % archivo: falsopositivo.m % % Script con todo el proceso del análisis de falso positivo % clear all ; %Proceso completo del análisis de falso positivo Fs=44100/8; %frecuencia de muestreo alpha=0.35; %umbral % cargamos el bloque de 3 segundos y obtenemos su h uella audio1=readwav( 'pictures5512_3sg.wav' ); f1=fingerprint_princ(audio1); [m,n]=size(f1); % cargamos el archivo con el que vamos a comparar, entero audio2=readwav( '1123075521_5512_20min.wav' ); f2=fingerprint_princ(audio2); %se comparan ambas huellas d=busqueda(f1,f2); d=d./(m*n); %BER de cada comparación % sacamos la media y la desviación estándar y llama mos a la herramienta % dfittool media=mean(d) desv=std(d) dfittool

Función para leer archivos de audio Esta función debió ser utilizada por una incompatibilidad entre los archivos tratados con Adobe Audition y la orden ‘wavread’ de Matlab. La presente función hace lo mismo que ‘wavread’. function [y,fs,wmode,fidx]=readwav(filename,mode,nmax,nskip ) %READWAV Read a .WAV format sound file [Y,FS,WMODE,FIDX]=(FILENAME,MODE,NMAX,NSKIP) % % Input Parameters: % % FILENAME gives the name of the file (with optio nal .WAV extension) or alternatively % can be the FIDX output from a pre vious call to READWAV % MODE specifies the following (*=default) : % % Scaling: 's' Auto scale to make data peak = +-1 % 'r' Raw unscaled data (integer val ues) % 'q' Scaled to make 0dBm0 be unity mean square % 'p' * Scaled to make +-1 equal full scale % 'o' Scale to bin centre rather tha n bin edge (e.g. 127 rather than 127.5 for 8 bit values) % (can be combined with n+p,r,s modes) % 'n' Scale to negative peak rather than positive peak (e.g. 128.5 rather than 127.5 for 8 bit values) % (can be combined with o+p,r,s modes) % Offset: 'y' * Correct for offset in <=8 bit PCM data % 'z' No offset correction % File I/O: 'f' Do not close file on exit % 'd' Look in data directory: voiceb ox('dir_data') % % NMAX maximum number of samples to read (or -1 for unlimited [default]) % NSKIP number of samples to skip from start o f file % (or -1 to continue from previous re ad when FIDX is given instead of FILENAME [default]) % % Output Parameters: % % Y data matrix of dimension (samples,chan nels) % FS sample frequency in Hz % WMODE mode string needed for WRITEWAV to rec reate the data file % FIDX Information row vector containing the element listed below. % % (1) file id % (2) current position in file % (3) dataoff byte offset in file to start of data % (4) nsamp number of samples % (5) nchan number of channels % (6) nbyte bytes per data value % (7) bits number of bits of precision % (8) code Data format: 1=PCM, 2=ADPCM , 6=A-law, 7=Mu-law % (9) fs sample frequency % % If no output parameters are specified, header i nformation will be printed. %

% For stereo data, y(:,1) is the left channel and y(:,2) the right % % See also WRITEWAV. % *** Note on scaling *** % If we want to scale signal values in the range +-1 to an integer in the % range [-128,127] then we have four plausible ch oices corresponding to % scale factors of (a) 127, (b) 127.5, (c) 128 or (d) 128.5 but each choice % has disadvantages. % For forward scaling: (c) and (d) cause clipping on inputs of +1. % For reverse scaling: (a) and (b) can generate o utput values < -1. % Any of these scalings can be selected via the m ode input: (a) 'o', (b) default, (c) 'on', (d) 'n' % Copyright (C) Mike Brookes 1998-2003 % Version: $Id: readwav.m,v 1.5 2006/11/06 08: 16:02 dmb Exp $ % % VOICEBOX is a MATLAB toolbox for speech process ing. % Home page: http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voiceb ox.html % %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % This program is free software; you can redistri bute it and/or modify % it under the terms of the GNU General Public Li cense as published by % the Free Software Foundation; either version 2 of the License, or % (at your option) any later version. % % This program is distributed in the hope that it will be useful, % but WITHOUT ANY WARRANTY; without even the impl ied warranty of % MERCHANTABILITY or FITNESS FOR A PARTICULAR PUR POSE. See the % GNU General Public License for more details. % % You can obtain a copy of the GNU General Public License from % ftp://prep.ai.mit.edu/pub/gnu/COPYING-2.0 or by writing to % Free Software Foundation, Inc.,675 Mass Ave, Ca mbridge, MA 02139, USA. %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% if nargin<1 error( 'Usage: [y,fs,wmode,fidx]=READWAV(filename,mode,nmax,nskip) ' ); end if nargin<2 mode= 'p' ; else mode = [mode(:).' 'p' ]; end k=find((mode>= 'p' ) & (mode<= 's' )); mno=all(mode~= 'o' ); % scale to input limits not output limits sc=mode(k(1)); z=128*all(mode~= 'z' ); info=zeros(1,9); if ischar(filename) if any(mode== 'd' )

filename=fullfile(voicebox( 'dir_data' ),filename); end fid=fopen(filename, 'rb' , 'l' ); if fid == -1 fn=[filename, '.wav' ]; fid=fopen(fn, 'rb' , 'l' ); if fid ~= -1 filename=fn; end end if fid == -1 error(sprintf( 'Can't open %s for input' ,filename)); end info(1)=fid; else info=filename; fid=info(1); end if ~info(3) fseek(fid,8,-1); % read riff chunk header=fread(fid,4, 'uchar' ); if header' ~= 'WAVE' fclose(fid); error(sprintf( 'File does not begin with a WAVE chunck' )); end fmt=0; data=0; while ~data % loop until FMT and DATA chuncks both found header=fread(fid,4, 'char' ); len=fread(fid,1, 'ulong' ); if header' == 'fmt ' % ******* found FMT chunk ********* fmt=1; info(8)=fread(fid,1, 'ushort' ); % format: 1=PCM, 6=A-law, 7-Mu-law info(5)=fread(fid,1, 'ushort' ); % number of channels fs=fread(fid,1, 'ulong' ); % sample rate in Hz info(9)=fs; % sample rate in Hz rate=fread(fid,1, 'ulong' ); % average bytes per second (ignore) align=fread(fid,1, 'ushort' ); % block alignment in bytes (ignore) info(7)=fread(fid,1, 'ushort' ); % bits per sample fseek(fid,len-16,0); % skip to end of header if any([1 6 7]==info(8)) info(6)=ceil(info(7)/8); else info(6)=1; sc= 'r' ; end elseif header' == 'data' % ******* found DATA chunk ********* if ~fmt fclose(fid); error(sprintf( 'File %s does not contain a FMT chunck' ,filename)); end info(4) = fix(len/(info(6)*info(5))); info(3)=ftell(fid); data=1; else % ******* found unwanted chunk ********* fseek(fid,len,0); end end else fs=info(9); end

if nargin<4 nskip=info(2); elseif nskip<0 nskip=info(2); end ksamples=info(4)-nskip; if nargin>2 if nmax>=0 ksamples=min(nmax,ksamples); end elseif ~nargout ksamples=min(5,ksamples); end if ksamples>0 info(2)=nskip+ksamples; pk=pow2(0.5,8*info(6))*(1+(mno/2-all(mode~= 'n' ))/pow2(0.5,info(7))); % use modes o and n to determine effective peak fseek(fid,info(3)+info(6)*info(5)*nskip,-1); nsamples=info(5)*ksamples; if info(6)<3 if info(6)<2 y=fread(fid,nsamples, 'uchar' ); if info(8)==1 y=y-z; elseif info(8)==6 y=pcma2lin(y,213,1); pk=4032+mno*64; pkp=pk; elseif info(8)==7 y=pcmu2lin(y,1); pk=8031+mno*128; pkp=pk; end else y=fread(fid,nsamples, 'short' ); end else % 3 or 4 byte values if info(6)<4 y=fread(fid,3*nsamples, 'uchar' ); y=reshape(y,3,nsamples); y=([1 256 65536]*y-pow2(fix(pow2(y(3,:),-7 )),24)).'; else y=fread(fid,nsamples, 'long' ); end end if sc ~= 'r' if sc== 's' sf=1/max(max(abs(y)),1); elseif sc== 'p' sf=1/pk; else if info(8)==7 sf=2.03761563/pk; else sf=2.03033976/pk; end end y=sf*y; else % mode = 'r' - output raw values if info(8)==1 y=y*pow2(1,info(7)-8*info(6)); end % shift to get

the bits correct end if info(5)>1 y = reshape(y,info(5),ksamples).'; end else y=[]; end if all(mode~= 'f' ) fclose(fid); end if nargout>2 wmode=setstr([sc 'z' -z/128]); if info(8)==1 % PCM modes if ~mno wmode=[wmode 'o' ]; end if any(mode== 'n' ) wmode=[wmode 'n' ]; end wmode=[wmode num2str(info(7))]; elseif info(8)==6 wmode = [wmode 'a' ]; elseif info(8)==7 wmode = [wmode 'u' ]; end fidx=info; elseif ~nargout codes= ' ' *ones(9,6); codes(1+[1 2 6 7],:)=[ 'PCM ' ; 'ADPCM ' ; 'A-law ' ; 'Mu-law' ]; fprintf(1, '\n%d Hz sample rate\n%d channel x %d samples = %.3 g seconds\ndata type %d: %d bit %s\n' ,info([9 5 4]),info(4)/info(9), info([8 7]),char(codes(1+max(0,min(8,info(8))),:))) ; end Función que calcula el error entre dos trozos de audio % archivo: busqueda.m % % Función que va comparando dos huellas y obteniend o el error % En las matrices entrada van los fingerprints corr espondientes a los 3 % segundos de detección de la señal de audio (matri z de dimensión 256x32) y los fingerprints del anuncio % (matriz de dimensión ¿x32) function d=busqueda(detectado,anuncio) [m1,n1]=size(detectado); [m2,n2]=size(anuncio); for k=1:m2-m1 d(k)=sum(sum(abs(anuncio(k:k+m1-1,:)-detectado) )); end

Script del análisis de robustez % Archivo: robustez.m % % Script para calcular la BER entre dos trozos de a udio % clear all ; Fs=44100/8; %frecuencia de muestreo % cargamos el bloque de 3 segundos original y obten emos su huella audio1=readwav( 'jimmy_3sg_5512.wav' ); f1=fingerprint_princ(audio1); [m1,n1]=size(f1); % cargamos el bloque modificado con el que vamos a comparar audio2=readwav( 'jimmy_3sg_comp_5512.wav' ); f2=fingerprint_princ(audio2); [m2,n2]=size(f2); % para tener en cuenta el hecho de que por la disto rsión % puede que los dos trozos sean de distinta duració n if m1<m2 d=busqueda(f1,f2); d=d./(m1*n1); BER=min(d) else if m1==m2 BER=sum(sum(abs(f2-f1)))/(m1*n1) else d=busqueda(f2,f1); d=d./(m2*n2); BER=min(d) end end

Anexo 2: Funciones usadas para el preprocesado de filtrado Script del análisis de falso positivo % Archivo: falsopositivo_filt.m % % Script que realiza el análisis de falso positivo, se diferencia del % anterior en la inclusión de la orden filter, que filtra el audio % antes de calcular la huella clear all ; %Proceso completo del análisis de falso positivo Fs=44100/8; %frecuencia de muestreo alpha=0.35; %umbral % cargamos el bloque de 3 segundos y obtenemos su h uella audio1=readwav( 'pictures5512_3sg.wav' ); audio1filt=filter([0.99 -0.99],[1 -0.98],audio1); f1=fingerprint_princ(audio1filt); [m,n]=size(f1); % cargamos el archivo con el que vamos a comparar, entero audio2=readwav( '1123075521_20min.wav' ); audio2filt=filter([0.99 -0.99],[1 -0.98],audio2); f2=fingerprint_princ(audio2filt) %se comparan ambas huellas d=busqueda(f1,f2); d=d./(m*n); %BER de cada comparación % sacamos la media y la desviación estándar media=mean(d) desv=std(d) dfittool

Script del análisis de robustez % Archivo: robustez_filt.m % % Script para calcular la BER entre dos trozos de a udio, también se % diferencia del anterior en la inclusión de la ord en filter % clear all ; Fs=44100/8; %frecuencia de muestreo % cargamos el bloque de 3 segundos original y obten emos su huella audio1=readwav( 'vangelis_3sg_5512.wav' ); audio1filt=filter([0.99; -0.99],[1; -0.98],audio1); f1=fingerprint_princ(audio1filt); [m1,n1]=size(f1); % cargamos el bloque modificado con el que vamos a comparar audio2=readwav( 'vangelis_3sg_lsc-1_5512.wav' ); audio2filt=filter([0.99; -0.99],[1; -0.98],audio2); f2=fingerprint_princ(audio2filt); [m2,n2]=size(f2); if m1<m2 d=busqueda(f1,f2); d=d./(m1*n1); BER=min(d) else if m1==m2 BER=sum(sum(abs(f2-f1)))/(m1*n1) else d=busqueda(f2,f1); d=d./(m2*n2); BER=min(d) end end

Anexo 3: Funciones usadas en el preprocesado de DDA Script del análisis de falso positivo % Archivo: falsopositivo_dda.m % % Script para el análisis de falso positivo. Se dif erencia de % los anteriores en que se llama a la función prepr ocdda, que es la que % hace el preprocesado en sí mismo y en que se trab aja a 44100 Hz clear all ; %Proceso completo del análisis de falso positivo Fs=44100; %frecuencia de muestreo alpha=0.35; %umbral % cargamos el bloque de 3 segundos y obtenemos su h uella audio11=readwav( 'pictures44100_3sg.wav' ); preproc1=preprocdda(audio11); audio1=decimate(preproc1,2); %de 11025 Hz a 5512,5 f1=fingerprint_princ(audio1); [m,n]=size(f1); % cargamos el archivo con el que vamos a comparar, entero audio21=readwav( '1123075521_5512_20min.wav' ); preproc2=preprocdda(audio21.'); audio2=decimate(preproc2,2); % de 11025 Hz a 5512,5 f2=fingerprint_princ(audio2); %se comparan ambas huellas d=busqueda(f1,f2); d=d./(m*n); %BER de cada comparación % sacamos la media y la desviación estándar media=mean(d) desv=std(d)

Script del análisis de robustez % Archivo: robustez_dda.m % % Script para calcular la BER entre dos trozos de a udio con preprocesado % DDA. Se diferencia de los anteriores en que se ca rgan los archivos a % 44100 Hz % clear all ; % cargamos el bloque de 3 segundos original y obten emos su huella audio11=readwav( 'vangelis44100_3sg.wav' ); preproc1=preprocdda(audio11); audio1=decimate(preproc1,2); %se pasa de 11025 Hz a 5512 Hz f1=fingerprint_princ(audio1); [m1,n1]=size(f1); % cargamos el bloque modificado con el que vamos a comparar audio21=readwav( 'vangelis44100_3sg_lsc-4.wav' ); preproc2=preprocdda(audio21); audio2=decimate(preproc2,2); %se pasa de 11025 Hz a 5512 Hz f2=fingerprint_princ(audio2); [m2,n2]=size(f2); if m1<m2 d=busqueda(f1,f2); d=d./(m1*n1); BER=min(d) else if m1==m2 BER=sum(sum(abs(f2-f1)))/(m1*n1) else d=busqueda(f2,f1); d=d./(m2*n2); BER=min(d) end end

Función que hace el primer paso de preprocesado % Archivo: preprocdda.m % % Función que realiza el primer paso de preprocesad o del algoritmo DDA % function x=preprocdda(audio) Fs=11025; %frecuencia de muestreo N=4096; %numero de muestras por frame overlap=1/2; %factor de solapamiento desplaz=floor(N-N*overlap); %desplazamiento para comenzar cada trama %antes de nada se submuestrea el audio a Fs audio11025=decimate(audio,4); % para calcular el numero de tramas numtramas=floor((length(audio11025)-N)/desplaz); %numero de tramas sin contar la primera audio11025=audio11025(1:(N+numtramas*desplaz)); %Generamos el espectro logarítmico transf=mclt(audio11025,desplaz); spect=10*log10(abs(transf)); %ya tenemos el espectro logarítmico, ahora hay que realizar el primer paso %propiamente dicho %Primero hay que realizar la DCT for k=0:desplaz:length(spect)-desplaz transdct(k+1:k+desplaz)=dct(spect(k+1:k+desplaz )); %se filtra paso-bajo, cogiendo solo los componentes principales ramp=[1 0.8 0.6 0.4 0.2 zeros(1,desplaz-5)]; transdct(k+1:k+desplaz)=transdct(k+1:k+desplaz) .*ramp; %y se hace la transformada inversa A(k+1:k+desplaz)=idct(transdct(k+1:k+desplaz)); for i=1:desplaz A(k+i)=A(k+i)-6; %se bajan 6 dB if A(k+i)<=-70 A(k+i)=-70; end if spect(k+i)-A(k+i)>0 xt(k+i)=spect(k+i)-A(k+i); %xt todavía en el dominio mclt, ahora hay que antitransformar

else xt(k+i)=0; end end end % se vuelve a pasar a dominio del tiempo x=imclt(xt,desplaz); Función que hace la transformada MCLT % Archivo: mclt.m % % Función que calcula la transformada MCLT de las d istintas tramas % de una señal de audio, de longitud M function trans=mclt(x,M) N=2*M; j=sqrt(-1); n=0; k=0; m=0; %Ventana de análisis ha=zeros(2*M,1); pa=zeros(2*M,M); mclt=zeros(length(x),1); %Ahora se computa la transformada n=1:2*M; ha=-sin(((n-1)+1/2)*pi/(2*M)); % creamos la matriz de análisis, pa(n,k) for k=1:M for n=1:2*M pa(n,k)=ha(n)*sqrt(2/M)*cos(((n-1)+(M+1)/2 )*((k-1)+1/2)*pi/M)-j*ha(n)*sqrt(2/M)*sin(((n-1)+(M+1)/2) *((k-1)+1/2)*pi/M); end end %dividimos la señal en tramas de longitud 2M y mult iplicamos por %la matriz pa, dando lugar a transformadas de longi tud M for m=0:M:length(x)-N frame=x(m+1:m+N); trans(m+1:m+M)=pa.'*frame.'; if m==length(x)-N % para mandar la última

trama frame=[x(m+M+1:m+N) x(1:M)]; trans(m+M+1:m+N)=pa.'*frame.'; end end Función que realiza la transformada MCLT inversa % Archivo: imclt.m % % Función que realiza la transformada MCLT inversa, con tramas de % longitud M function y=imclt(x,M) j=sqrt(-1); n=0; k=0; m=0; y=zeros(length(x),1); yp=zeros(2*M,1); % transformadas parciales ypant=zeros(M,1); hs=zeros(2*M,1); %Ventana de análisis ps=zeros(2*M,M); %Ahora se computa la transformada n=1:2*M; hs=-sin(((n-1)+1/2)*pi/(2*M)); % se genera la matriz de síntesis, ps(n,k) for k=1:M for n=1:2*M ps(n,k)=1/2*hs(n)*sqrt(2/M)*[cos(((n-1)+(M +1)/2)*((k-1)+1/2)*pi/M)+j*sin(((n-1)+(M+1)/2)*((k-1)+1/2)*pi/ M)]; end end % En el algoritmo, para sacar la primera trama hace falta la última % transformada parcial ypant=ps*x(length(x)-M+1:length(x)).'; % se van sacando todas las tramas a partir de la tr ansformada parcial de % dicha trama y de la anterior

for m=0:M:length(x)-M yp=ps*x(m+1:m+M).'; %resultado parcial y(m+1:m+M)=real(yp(1:M))+real(ypant(M+1:2*M)); ypant=yp; end Función que hace el segundo paso de preprocesado % Archivo: preprocdda2.m % % Función que realiza el segundo paso de preprocesa do del algoritmo DDA % function x=preprocdda2(audio) Fs=11025; %frecuencia de muestreo N=4096; %numero de muestras por frame overlap=1/2; %factor de solapamiento desplaz=floor(N-N*overlap); %desplazamiento para comenzar cada trama %antes de nada se submuestrea el audio a Fs audio11025=decimate(audio,4); % para calcular el numero de tramas numtramas=floor((length(audio11025)-N)/desplaz); %numero de tramas sin contar la primera audio11025=audio11025(1:(N+numtramas*desplaz)); %Generamos el espectro logarítmico transf=mclt(audio11025,desplaz); spect=10*log10(abs(transf)); %segundo paso spectexp=10.^(spect/10); % se eleva el espectro logarítmico for k=0:desplaz:length(spect)-desplaz Ht(k+1:k+desplaz)=hthres(spectexp(k+1:k+desplaz ),Fs); %umbral auditivo en u.n. HtdB(k+1:k+desplaz)=10*log10(Ht(k+1:k+desplaz)) ; for i=1:desplaz if spect(k+i)-HtdB(k+i)>=0 xt(k+i)=spect(k+i)-HtdB(k+i); else xt(k+i)=0; end end

end % se vuelve a pasar a dominio del tiempo x=imclt(xt,desplaz); Funciones para obtener el umbral de audición % HTHRES Hearing threshold % % H. S. Malvar - Nov'00, (c) H. S. Malvar % % Syntax: Ht = hthres(X,fs) % % X = vector of frequency magnitude components % fs = sampling frequency, in Hz % Ht = vector of thresholds, in rms function Ht = hthres(X,fs) Dabs = 60; % in dB, how much to bring down Fletcher-Munson cur ves; % it depends on the assumed playback level Thmin = -60; % in dB, how far down can any threshold go Thmax = 60; % in dB, how far up can any threshold go Rfac = 8; % Power reduction factor in dB for masking within t he % same bark frequency band % Bark subbands upper limits Bh = [100 200 300 400 510 630 770 920 1080 1270 148 0 1720 2000 2320 2700 3150 3700 4400 5300 6400 7700 9500 12000 15500 22050]; P = X.*X; % power spectrum TdB = 0*P; % Threshold in dB Nbands = length(X); f=[0:Nbands-1]'*fs/(2*(Nbands-1)); % subband center frequencies, in Hz % Loop to generate Bark power spectrum and Bark cen ter thresholds dindx = Nbands*2/fs; % # of coefficients per Hz stop = 0; i1 = 1; il=[]; iu=[]; for i = 1:25 % scan all 25 Bark bands % i-th Bark subband covers original subbands i1 to i2

i2 = round(Bh(i)*dindx); if i2 > Nbands i2 = Nbands; stop = 1; % stop loop if signal bandwidth is reached end il = [il;i1]; iu = [iu;i2]; % Average RMS signal amplitude over Bark band [i1,i 2] Arms = sqrt(mean(P(i1:i2))); % average signal amplitude over Bark band [i1,i2], in dB Adb = 20*log10(Arms+eps); % Tr = relative threshold given power level within i-th band Tr = Adb - Rfac; % center threshold Sbu(i) = Tr; i1 = i2+1; if stop break ; end ; end Lsb = i; % number of Barks covered for the given fs % Cross-Bark spreading Sbu = Sbu'; Sb = Sbu; pl = -100; pr = -100; pli = Sbu(1); for i = 1:Lsb if i < Lsb; pr = Sbu(i+1)-25; else pr = -100; end if pli > pl; pl = pli; end pl = pl - 10; if pl > Sb(i); Sb(i) = pl; end if pr > Sb(i); Sb(i) = pr; end pli = Sbu(i); end % Adjust thresholds considering absolute masking

for i = 1:Lsb i1 = il(i); i2 = iu(i); Tr = Sb(i); % Ta = Fletcher-Munson absolute threshold Ta = mean(thrabs(f(i1:i2)))-Dabs; if Tr < Ta; Tr = Ta; end % Clip at minimum and maximum levels if Tr < Thmin; Tr = Thmin; end if Tr > Thmax; Tr = Thmax; end Sb(i) = Tr; % save dB thresholds in vector Sb TdB(i1:i2) = Tr; % same threshold for all bands within Bark band end Ht = 10.^(TdB/20); % convert from power to rms levels %THRABS Absolute hearing threshold (Fletcher-Muns on) % % H. S. Malvar - Nov'00, (c) H. S. Malvar % % Syntax: T = thrabs(f) % % f = frequency, in Hz (or a vector of frequencie s) % T = corresponding absolute threshold of hearing , in dB SPL function T=thrabs(f) fk = f/1000; % Approximation to the F&M curves T = 3.64*(fk.^(-.8))-6.5*exp(-.6*(fk-3.3).^2)+1e-3* fk.^4;

Agradecimientos Antes de dar por acabada esta memoria, es el momento de dedicar algunas palabras a todos aquellos que han formado parte del (largo) proceso que culmina con el presente proyecto.
A veces parece que estos años se han pasado volando, que no ha sido tanto el tiempo transcurrido, pero han sido muchas las mañanas, muchas las tardes, que se han hecho llevaderas gracias a la buena compañía y a los buenos amigos con los que he tenido la suerte de coincidir. Algunos podrán venir a la presentación, otros ya son personas de provecho y tendrán que trabajar, pero sea como sea se merecen todo mi agradecimiento por todos estos años. Y a todos los que, fuera de la escuela, se interesan por lo que hago, por como me va y confían en mí, aquí incluyo a los amigos de toda la vida (desde el instituto juntos, ¡ya son años!) y en general a todos los que han estado pendientes desde la distancia, incluso desde fuera de nuestras fronteras.
También me gustaría agradecer al tutor Dr. José Ramón Cerquides
por su ayuda para sacar adelante el proyecto en momentos en los que parecía que se iba a atascar por carecer de algún material necesario para su realización (buen momento para agradecer también al señor Malvar de Microsoft, gran detalle el suyo) y a los miembros del tribunal.
Debo agradecer también su ayuda a mi compañero Alejandro Alvárez,
que ha estado trabajando en un proyecto similar al mío y ha compartido conmigo su trabajo.
Y, por último y más importante a la familia, toda entera. Empezando
por mi hermano, siempre a mi lado y ahora marcándome el camino a seguir, por supuesto mis padres, que me han aportado todo el apoyo y la confianza necesarios para poder afrontar esto tranquilamente, sin otras preocupaciones, sin presión y apoyándome también en todo lo que han considerado mejor para mí aunque ello les cueste tenerme lejos. Y a todos los demás, por estar siempre atentos y, aunque muchas veces no sepan exactamente en qué estoy trabajando, interesarse por saber como me va.


















