
ALINEACIÓN DE ONTOLOGÍAS USANDO EL …levashkin.com/files/Roberto Eswart Zagal Flores.pdf ·...
154
INSTITUTO POLITÉCNICO NACIONAL CENTRO DE INVESTIGACIÓN EN COMPUTACIÓN ALINEACIÓN DE ONTOLOGÍAS USANDO EL MÉTODO BOOSTING TESIS QUE PARA OBTENER EL GRADO DE MAESTRO EN CIENCIAS DE LA COMPUTACIÓN PRESENTA: ING. ROBERTO E. ZAGAL FLORES DIRECTOR DE TESIS: DR. SERGUEI LEVACHKINE Diciembre 2008
Transcript of ALINEACIÓN DE ONTOLOGÍAS USANDO EL …levashkin.com/files/Roberto Eswart Zagal Flores.pdf ·...

INSTITUTO POLITÉCNICO NACIONAL CENTRO DE INVESTIGACIÓN EN COMPUTACIÓN
ALINEACIÓN DE ONTOLOGÍAS USANDO EL MÉTODO
BOOSTING
TESIS QUE PARA OBTENER EL GRADO DE
MAESTRO EN CIENCIAS DE LA COMPUTACIÓN
PRESENTA:
ING. ROBERTO E. ZAGAL FLORES
DIRECTOR DE TESIS:
DR. SERGUEI LEVACHKINE
Diciembre 2008



Agradecimientos
A mi madre, ese ser maravilloso que me dio la vida, a quien le dedico todo mi cariño, esfuerzo y logros, todo lo bueno en mí es por ti. Sin tu apoyo incondicional yo sería nada.
A mis hermanos: Mauricio, Jairo y Yadira. A mi padre. Gracias, a todos, por no dejarme solo.
A mis queridas sobrinas también. A Dios por darme una vida tan maravillosa.
Dr. Serguei, gracias por su paciencia y apoyo. Gracias sobre todo, por hacerme entender que una idea simple y concreta, vale mucho.
A mis queridos amigos: Gerardo y Jony, gracias por su lealtad durante este tiempo. A los amigos se
les conoce en los tiempos buenos y malos, ustedes han estado conmigo (sobre todo jerguita). Child gracias por tu confianza y arrebatos, ahora somos interoperables.
Al grupo Bonobo, por ser un ejemplo de unidad y hermandad: Miguel, Marco, Giovanni, Rolando. Gracias por todos sus comentarios que ayudaron a mejorar este trabajo.
A mis amigos: Marco gracias por tu confianza, Miguel por tu entusiasmo y al Tío Chomin.
A mi querido amigo Hugo Jiménez, sin tus opiniones y aportaciones, las ideas no hubieran tenido forma. Gracias por compartir tu conocimiento.
A los amigos de hoy y para siempre: Miguel, Chino, Alex y Jariz. Gracias por ser las personas
quienes han confiando en mí y que siempre me han apoyado en todas mis aventuras.
Maestro Apolinar C. L. Siempre intento escuchar y aprender de sus enseñanzas. Le agradezco su tiempo y atención.
Amiguito Felix, gracias por tu amistad, por compartir tus conocimientos y pasión a la ciencia.
Gracias Pao por tu frescura y alegría.
Al Politécnico por darme una identidad, y a CONACYT por todo el patrocinio.
Gracias a esa niña francesa por ser mi inspiración en momentos amargos

Alineación de ontologías usando el método Boosting I
Contenido Índice de Figuras .............................................................................................................................. V Índice de Tablas ............................................................................................................................... VI Resumen ......................................................................................................................................... VII Abstract ......................................................................................................................................... VIII CAPÍTULO 1 : INTRODUCCIÓN ................................................................................................. 1
1.1 Generalidades ............................................................................................................................ 1 1.2 Motivación ................................................................................................................................ 2 1.3 Planteamiento del problema ...................................................................................................... 6 1.4 Objetivo ..................................................................................................................................... 8
1.4.1 Objetivos particulares ......................................................................................................... 8
1.5 Alcances y limitaciones ............................................................................................................. 8 1.6 Justificación ............................................................................................................................. 10 1.7 Hipótesis .................................................................................................................................. 11 1.8 Organización del documento de tesis ...................................................................................... 11
CAPÍTULO 2 ESTADO DEL ARTE ............................................................................................ 12 2.1 Sistemas de alineación de ontologías ...................................................................................... 12
2.1.1 Alineación de ontologías con Falcon-AO (Jian, et al., 2005) .......................................... 12
2.1.1.1 Proceso de correspondencia Lingüística LMO (Linguistic Matching Ontology) ..... 13 2.1.1.2 Proceso de correspondencia basada en Grafos GMO (Graph Matching Ontology) .. 14 2.1.1.3 Evaluación de resultados .......................................................................................... 14 2.1.1.4 Prueba de referencia sistemática ............................................................................... 15 2.1.1.5 Comentarios .............................................................................................................. 16
2.1.2 Métodos basados en estructuras para mejorar la Alineación de Ontologías Geoespaciales (Sunna, et al., 2007) .................................................................................................................. 17
2.1.2.1 Comentarios .............................................................................................................. 19 2.1.3 Estado del arte de alineación de ontologías: Knowledge Web (Euzenat, et al., 2004b) .. 19
2.1.3.1 Comentarios .............................................................................................................. 20 2.1.4 RiMON (Li, et al., 2008) .................................................................................................. 20
2.1.4.1 Comentarios .............................................................................................................. 21 2.1.5 Similarity flooding (Melnik, et al., 2001) ........................................................................ 21
2.1.6 OLA alineación de ontologías (Euzenat, et al., 2004b) .................................................... 22
2.2 Aplicaciones de aprendizaje automático en integración de información ................................ 22 2.2.1 AdaRank: Un algoritmo Boosting para Recuperación de Información (Xu, et al., 2007) 23
2.2.1.1 Comentarios .............................................................................................................. 24

Alineación de ontologías usando el método Boosting II
2.2.2 Integración de Taxonomías Web a través de Co-Bootstrapping (Zhang, et al., 2004) .... 24
2.2.2.1 Planteamiento general del problema ......................................................................... 25 2.2.2.2 Formulación del problema de clasificación ............................................................... 25 2.2.2.3 Co-Bootstrapping y el análisis de taxonomías .......................................................... 26 2.2.2.4 Comentarios .............................................................................................................. 28
2.2.3 Un nuevo método para medir similitud semántica en integración de esquemas XML (Jeong, et al., 2008) ................................................................................................................... 29
2.2.3.1 Síntesis de similitud basada en NNPLS .................................................................... 32 2.2.3.2 Comentarios .............................................................................................................. 33
2.3 Tópicos relacionados ............................................................................................................... 33 2.3.1 Web Semántica (W3C, 2008) ........................................................................................... 33
2.3.2 Web Semántica Geoespacial (Egenhofer, 2002) .............................................................. 34
2.3.3 Turismo electrónico .......................................................................................................... 37
2.3.4 Turismo electrónico en el dominio geoespacial ............................................................... 38
2.3.4.1 Aplicación de ontologías geográficas en sistemas turísticos ..................................... 39 2.4 Comentarios finales ................................................................................................................. 40
CAPÍTULO 3 . MARCO TEÓRICO ........................................................................................... 41 3.1 Conceptos generales ................................................................................................................ 41 3.2 Ontologías ............................................................................................................................... 42
3.2.1 Clasificación de ontologías .............................................................................................. 43
3.2.2 Criterios generales de diseño ............................................................................................ 45
3.3 Integración de información ..................................................................................................... 45 3.3.1 Correspondencia Semántica ............................................................................................. 46
3.3.2 Alineación de ontologías .................................................................................................. 47
3.3.3 Aplicaciones de la alineación ........................................................................................... 47
3.4 Aprendizaje automático ........................................................................................................... 51 3.4.1 Estructuras computacionales para aprendizaje automático .............................................. 53
3.4.2 Tipos de aprendizaje ......................................................................................................... 55
3.4.3 Elementos de entrada ....................................................................................................... 55
3.4.4 Elementos de salida .......................................................................................................... 56
3.4.5 Combinación de clasificadores: métodos de ensamble .................................................... 56
3.4.6 Boosting ........................................................................................................................... 58
3.5 Comentarios finales ................................................................................................................. 60 CAPÍTULO 4 : METODOLOGÍA ................................................................................................ 61
4.1 Introducción ............................................................................................................................ 61

Alineación de ontologías usando el método Boosting III
4.2 Descripción general de la metodología .................................................................................. 62 4.3 Metodología de alineación de ontologías ................................................................................ 66
4.3.1 Algoritmo general de alineación de ontologías usando el método Boosting ................... 68
4.3.2 Adquisición y validación de ontologías ........................................................................... 69
4.3.3 Detección de correspondencias semánticas ..................................................................... 70
4.3.3.1 Definición del conjunto de medidas de similitud ...................................................... 71 4.3.3.1.1 Similitud léxica .................................................................................................. 72 4.3.3.1.2 Similitud entre propiedades ................................................................................ 73 4.3.3.1.3 Similitud entre superclases ................................................................................. 74
4.3.3.2 Estructura de la matriz de similitud ........................................................................... 76 4.3.3.3 Algoritmo para clasificar los valores de similitud ..................................................... 77
4.3.3.3.1 Algoritmo K-Vecinos (k-NN) ............................................................................ 77 4.3.3.3.2 Algoritmo AdaBoost+K-Vecinos ....................................................................... 81
4.3.3.4 Criterios para decidir correspondencias semánticas .................................................. 83 4.3.4 Archivo final de Alineación ............................................................................................. 86
4.3.5 Caso de aplicación en el dominio geoespacial: Turismo electrónico .............................. 87
4.3.5.1 Alineación de ontologías turísticas ............................................................................ 87 4.3.5.2 Arquitectura del sistema web: OntoMashup ............................................................. 89
4.3.5.2.1 Cliente web ......................................................................................................... 90 4.3.5.2.2 Aplicación web central ....................................................................................... 90 4.3.5.2.3 Motor de consultas ............................................................................................. 91
4.4 Comentarios finales ................................................................................................................. 94 CAPÍTULO 5 . PRUEBAS Y RESULTADOS ............................................................................. 95
5.1 Resultados para MatchBoost ................................................................................................... 95 5.1.1 Resultados de la medida de similitud léxica .................................................................... 95
5.1.2 Resultados de la medida de similitud entre propiedades .................................................. 98
5.1.3 Resultados de la medida de similitud entre superclases ................................................. 100
5.1.4 Proceso de integración y optimización: AdaBoost+K-Vecinos ..................................... 103
5.1.5 Aplicación de criterios para establecer correspondencias finales .................................. 108
5.1.6 Archivo XML de correspondencias ............................................................................... 109
5.2 Resultados para OntoMashup ................................................................................................ 110 5.2.1 Consultas relacionadas a las ontología de Cancún y Acapulco ...................................... 110
5.3 Comentarios finales ............................................................................................................... 112 CAPÍTULO 6 : CONCLUSIONES Y TRABAJO A FUTURO ................................................ 113
6.1.1 Contribuciones ............................................................................................................... 114

Alineación de ontologías usando el método Boosting IV
6.1.2 Limitaciones ................................................................................................................... 114
6.1.3 Trabajo a futuro .............................................................................................................. 115
REFERENCIAS ............................................................................................................................ 116 Anexos ............................................................................................................................................ 121

Alineación de ontologías usando el método Boosting V
Índice de Figuras Figura 1.1. Integración de información geográfica. La alineación de ontologías permitiría extraer información desde servicios web semánticos, por medio de la detección de correspondencias semánticas. .......................................................................................................................................... 4 Figura 1.2. Ontologías del proyecto SWEET y sus interrelaciones; ejemplo de correspondencias semánticas entre ontologías ................................................................................................................. 5 Figura 1.3. : Posibles correspondencias entre dos ontologías, la primera (obtenida de SWEET- NASA) describe objetos espaciales, y la segunda describe el dominio de la hidrósfera (The Florida International University Geo-Spatial Database) ................................................................................ 7 Figura 2.1. Arquitectura básica de la primera versión de Falcon-AO .............................................. 13 Figura 2.2. Arquitectura del sistema AgreementMaker ..................................................................... 17 Figura 2.3. Ejemplo de integración de taxonomías (adaptado de una presentación de Dell Zhang). 25 Figura 2.4. Técnica co-Boostrappings para integración de taxonomías combinada con AdaBoost.MH ................................................................................................................................... 28 Figura 2.5. Marco conceptual para “Schema Matching” ................................................................... 30 Figura 2.6. Síntesis de similitud en el modelo NNPLS ..................................................................... 32 Figura 3.1. Clasificación de ontologías según sus niveles de dependencia ....................................... 44 Figura 3.2. Integración de catálogos electrónicos ............................................................................. 49 Figura 3.3. Esquema de un buscador inteligente de estaciones de radio web ................................... 50 Figura 3.4. Esquema general de aprendizaje automático (adaptado desde (Mitchell, 1997)) ........... 54 Figura 4.1. Componentes de alineación ............................................................................................ 61 Figura 4.2. Propuesta de alineación de ontologías, la entrada son dos ontologías y la salida es un conjunto de correspondencias ........................................................................................................... 63 Figura 4.3. ¿Puede existir una correspondencia entre “hotel” y “botel”? La diferencia radica en que “botel” es un hotel establecido en un barco. ..................................................................................... 64 Figura 4.4. Metodologia para el sistema MatchBoost ....................................................................... 67 Figura 4.5. Conjunto de medidas de similitud y los elementos de ontologías a los que se enfocan . 72 Figura 4.6. Un patrón X clasificado por K-Vecinos .......................................................................... 78 Figura 4.7. Salida del algoritmo AdaBoost+K-vecinos .................................................................... 83 Figura 4.8. Integración de correspondencias parciales ...................................................................... 83 Figura 4.9. Extracto de la ontología turística para Acapulco ............................................................ 88 Figura 4.10. Ontología turística para Cancún.................................................................................... 89 Figura 4.11. Arquitectura web propuesta .......................................................................................... 90 Figura 5.1. Histograma para los resultados de la similitud léxica ..................................................... 97 Figura 5.2. Histograma para los resultados de la similitud entre propiedades ................................ 100 Figura 5.3. Histograma para los resultados de la similitud entre superclases ................................. 103 Figura 5.4. Clasificación de la matriz de similitud léxica, el eje vertical representa las 5 clases encontradas y el eje horizontal el número de elementos que pertenecen a la clase. ....................... 106 Figura 5.5. Clasificación para la matriz entre propiedades el eje vertical representa la clase o categoría .......................................................................................................................................... 107 Figura 5.6. Interfaz de consulta de OntoMashup ............................................................................ 111 Figura 5.7. Resultados para la búsqueda por nombre de hotel ........................................................ 111

Alineación de ontologías usando el método Boosting VI
Índice de Tablas Tabla 3.1. Algoritmo AdaBoost ........................................................................................................ 59 Tabla 4.1. Algoritmo general de alineación de ontologías usando el método Boosting ................... 68 Tabla 4.2. Descripción de la estructura Clase-OWL ......................................................................... 69 Tabla 4.3. Descripción principal de la adquisición y validación de Ontologías ............................... 70 Tabla 4.4. Descripción de la adquisición y validación de ontologías ............................................... 70 Tabla 4.5. Algoritmo general de la distancia Levenshtein ................................................................ 73 Tabla 4.6. Algoritmo general de la similitud de propiedades ........................................................... 74 Tabla 4.7. Algoritmo general de la similitud de concepto ascendente ............................................. 75 Tabla 4.8. Estructura general de las matriz de similitud ................................................................... 76 Tabla 4.9. Ejemplo de matriz de similitud léxica con valores reales ................................................ 76 Tabla 4.10. Algoritmo K-Vecinos para AdaBoost ............................................................................ 79 Tabla 4.11. Algoritmo AdaBoost+K-Vecinos ................................................................................... 81 Tabla 4.12. Tabla de criterios para determinar correspondencias semánticas fuertes ....................... 84 Tabla 4.13. Archivo de alineación final ............................................................................................ 86 Tabla 4.14. Ejemplo de una consulta SPARQL para búsqueda de hoteles en Acapulco por nombre ............ 91 Tabla 4.15. Ejemplo de una consulta SPARQL para búsqueda de hoteles por costo en Cancún ..... 92 Tabla 4.16. Ejemplo del archivo XML de correspondencias a usar en la aplicación web ................ 92 Tabla 5.1. Matriz de similitud léxica ................................................................................................. 96 Tabla 5.2. Matriz de similitud entre propiedades .............................................................................. 99 Tabla 5.3. Matriz de similitud entre superclases ............................................................................. 102 Tabla 5.4. Lista de las parejas (id, de pareja) de clases asignada por OntoMashup ....................... 104 Tabla 5.5. Resultados finales sobre “correspondencias parciales fuertes” obtenidas desde AdaBoost+K-Vecinos ..................................................................................................................... 109

Alineación de ontologías usando el método Boosting VII
Resumen En este trabajo, se presenta un sistema de alineación de ontologías que integra un conjunto de medidas de similitud por medio de Boosting, un método de aprendizaje automático. El objetivo es encontrar correspondencias semánticas entre dos ontologías. La alineación de ontologías busca solucionar problemas relacionados a la integración de información. Es importante porque establece la interoperabilidad semántica entre ontologías lo que permite realizar diversas aplicaciones, principalmente compartir información entre dos ontologías de forma simple y directa. En esta tesis, se propone una arquitectura de alineación de ontologías llamada MatchBoost, que como entrada recibe dos ontologías escritas en OWL, y a la salida obtiene un archivo XML con las posibles correspondencias semánticas entre los conceptos de las ontologías de entrada. MatchBoost utiliza AdaBoost (un algoritmo tipo Boosting), el cual combina diferentes “weak learners” (clasificadores simples o reglas de clasificación simples) a fin de obtener resultados precisos después de combinar cada “weak learner”. En MatchBoost, la idea consiste en integrar por medio de AdaBoost, los resultados obtenidos desde tres diferentes mediciones de similitud entre entidades de ontologías: similitud entre cadenas de caracteres, similitud entre propiedades y similitud entre superclases. A su vez, AdaBoost emplea el clasificador K-Vecinos (algoritmo de clasificación). K-Vecinos por medio de valores de similitud clasifica pares de conceptos, en dos grupos o clases, los cuales se interpretarán como: “correspondencias fuertes” y “correspondencias débiles”. También AdaBoost obtiene empleando K-Vecinos diversos “weak learners”, los cuales intentan categorizar parejas de conceptos que son difíciles de clasificar. De esta manera se optimiza el proceso de alineación al intentar clasificar todas las parejas de conceptos. MatchBoost considera esta clasificación, y determina los conceptos que tienen entre sí una “correspondencia semántica fuerte” ó una “correspondencia semántica débil”. Para probar esta arquitectura de alineación, se eligieron dos ontologías turísticas. Finalmente, para ilustrar la utilidad de la alineación de ontologías en el dominio Geoespacial, se definió un caso de aplicación turístico para validar el enfoque propuesto en esta tesis. Usando MatchBoost se alinearon dos ontologías turísticas de Cancún y Acapulco, los resultados contendrían correspondencias semánticas como <Cancún.hoteles> y <Acapulco.hoteles>. Estas correspondencias son utilizadas por una aplicación Web nombrada OntoMashup, para extraer simultáneamente información sobre hoteles contenida en ambas ontologías.

Alineación de ontologías usando el método Boosting VIII
Abstract In this work, we present a aligning ontologies system, which integrates a set of similarity measures by using Boosting (a machine learning method). The goal is to obtain semantic matching between two ontologies. We propose MatchBoost as alignment ontology architecture, the input data is two OWL ontologies, and the output is a XML file that contains the possible semantic matching between concepts of the input ontologies. Ontology alignment seeks to troubleshoot the information integration. It is important because it allows semantic interoperability between ontologies, which allows multiple applications, mainly to share information between two ontologies in a simple and direct way. MatchBoost uses Adaboost (a Boosting algorithm), which combines different “weak learners” (simple classifiers or rules of classification), in order to obtain accuracy results. The main idea in MatchBoost is to integrate through AdaBoost, the results that are obtained from different similarity measurements between ontology entities: string similarity, properties similarity and superclasses similarity On the other hand, AdaBoost uses the K-Nearest classifier (a classification algorithm), to clusters pair of concepts in two categories: “strong correspondence” and “weak correspondence”. Thus AdaBoost obtains “weak learners” from K-Nearest, they attempt to categorize pairs of concepts, which are difficult to classify. Therefore, AdaBoost can optimize the aligning process when it tries to classify all pair of concepts. MatchBoost considers this classification, and then it recognizes the concepts that have each other a “strong semantic correspondence” or “weak semantic correspondence”. Finally, we present the use of aligning ontologies in geospatial domain, a tourism application case is defined for validating the approach proposed in this dissertation. MatchBoost is used to align two tourism ontologies about Cáncun and Acapulco Mexico, the results contains semantic correspondences, for instance <Cancun.hotels> and <Acapulco.hotels>. The correspondences are use by a Web application called OntoMashup, it exploits hotels information stored in both ontologies.

Capítulo 1. Introducción
Alineación de ontologías usando el método Boosting 1
CAPÍTULO 1 : INTRODUCCIÓN
1.1 Generalidades Las personas expresan de diferentes formas una misma idea. Mientras que alguien puede etiquetar un concepto de cierta manera, otra persona etiqueta el mismo concepto de forma distinta. Por ejemplo, una persona puede nombrar el concepto “ciudad”, como “metrópoli” mientras que otra como “área urbana”, este fenómeno también se extiende en la definición de bases de datos geográficas. En el ejemplo anterior ambos términos son distintos pero hacen referencia al mismo objeto geográfico. A esto se le conoce como heterogeneidad. En Ciencias de la Información Geoespaciales, la heterogeneidad es un problema en el estudio de la integración de información geográfica y existe en dos formas: la heterogeneidad sintáctica y semántica (Worboys, et al., 2004). La heterogeneidad sintáctica se refiere a cuando las fuentes de información, emplean codificaciones incompatibles de formatos de archivos para almacenar la información. Por ejemplo, las diferencias entre la estructura de archivos de texto plano y archivos construidos con el formato XML. La heterogeneidad semántica suscita cuando las fuentes de información usan términos diferentes para representar el significado de los mismos datos. Estos términos son difíciles de conciliar. Por ejemplo, los términos “ZONA GEOGRÁFICA” y “GEO-ZONA” tienen el mismo significado (zona geográfica) pero son expresiones distintas. Es necesario el uso de estructuras computacionales que almacenen la semántica (significado) de los datos, a fin de buscar soluciones para la heterogeneidad y facilitar el intercambio información. En este sentido, las ontologías representan una alternativa para captar la semántica involucrada en la información de un dominio. Gruber las define como especificaciones formales y específicas de los términos y relaciones entre ellos (Gruber, 1993). Es importante mencionar que recientemente las ontologías han ganado mucha importancia. Expertos en diferentes áreas están involucrados en su diseño y aplicación. Por ejemplo, en los laboratorios de IBM se estudia la aplicación de ontologías en sistemas de cómputo

Capítulo 1. Introducción
Alineación de ontologías usando el método Boosting 2
autónomos (autonomic computing systems) (Stojanovic, et al., 2004), la idea es que los sistemas usen ontologías y sean capaces de auto-configurarse y auto-repararse. Para las Ciencias de la Información Geoespacial, las ontologías geográficas (Geo-ontologías) se han aplicado en tópicos avanzados, como la recuperación de información geográfica (Varelas, et al., 2005), interoperabilidad entre Sistemas de Información Geográfica (Fonseca, et al., 2002), Geoservicios Web Semánticos, y en la representación de información geoespacial como en el proyecto de la NASA “Semantic Web for Earth and Environmental Terminology” (NASA, 2008). Sin embargo, las ontologías han crecido en tamaño y en número. Por esta razón, surge la necesidad de diseñar mecanismos que permitan rehusar la información que almacenan. Aunque las ontologías estén relacionadas con un mismo tema, estructuralmente pueden ser diferentes, esto impide compartir información de forma simple y automática. La alineación de ontologías, es el proceso que establece correspondencias (conciliación) entre conceptos de dos ontologías y permite rehusar su información desde una hacia otra. La alineación se desarrolla cuando las ontologías cubren dominios (áreas de conocimiento) complementarios entre sí (i.e. tienen un conjunto de entidades en común). Por ejemplo el dominio de hidrología e hidrósfera pueden compartir el concepto “cuerpos de agua”. Muchos métodos de alineación han sido propuestos, al igual que diversas técnicas para medir la similitud semántica entre conceptos de dos ontologías. Hasta el momento, han surgido los primeros esfuerzos para evaluar propuestas de mecanismos de alineación como la “Ontology Alignment Evaluation Initiative” (OAEI, 2004).
1.2 Motivación
Permitir la reutilización de conocimiento de un dominio, fue una de las principales razones que motivaron la investigación en ontologías (Noy, et al., 2005). Es este aspecto, la integración de información permite compartir conocimiento, esto significa la transferencia de conocimiento desde una persona a otra, de una organización a otra, o de un grupo de personas a otro, y en general, entre un agente a otro. La alineación permite el intercambio de información entre ontologías y extiende el uso de las mismas. Por ejemplo, supongamos dos ontologías que describen servicios turísticos que se ubican en dos playas diferentes. Ambas ontologías pueden coincidir en la clase “hotel”, por tanto, un software podría detectar esta coincidencia y obtener información de todos los hoteles (instancias de la clase “hotel”) almacenados.

Capítulo 1. Introducción
Alineación de ontologías usando el método Boosting 3
Internet es el medio que ha facilitado el acceso y distribución de la información geográfica, a través de diversas tecnologías Web como: servidores de mapas, acceso a imágenes satelitales, sitios para generar rutas, los emergentes servicios web orientados al dominio Geoespacial (OGC, 2007), etc. Sin embargo, muchas de estas aplicaciones utilizan fuentes heterogéneas de información geográfica, por tanto, para un intercambio de datos es necesario un mecanismo para integrar estas fuentes. En este sentido, los servicios web (SW) son una poderosa herramienta que permite la interoperabilidad sintáctica entre sistemas de cómputo. Múltiples sistemas pueden intercambiar datos utilizando servicios web, sin importar la plataforma tecnológica con la que fueron construidos. Los SW hacen posible la mezcla de fuentes de información, gracias a que establecen una interfaz de acceso a datos y procesos por medio de mecanismos estándar. Los servicios web semánticos (McIlraith, et al., 2001), son un tema de investigación actual para universidades como Stanford, en donde se estudian mecanismos para agregar el significado a los datos y procedimientos que proporcionan los SW a través de ontologías. Esto facilitaría la integración automática de servicios web en Internet. En el dominio geoespacial existen servicios web descritos semánticamente como Geonames.org (Geonames, 2006), el cual proporciona la localización y la descripción semántica de topónimos (nombres de lugares geográficos (e.g. Xochimilco)). Geonames.org utiliza una ontología geográfica (Geonames-ontology, 2006) para definir la semántica de la información geográfica relacionada a los topónimos almacenados. La capacidad de integrar dinámicamente servicios web semánticos orientados a proporcionar información geográfica y descriptiva, es una motivación muy fuerte para estudiar el problema de la alineación de ontologías (McIlraith, et al., 2001). Esto permitiría desarrollar aplicaciones muy útiles en diversas áreas como el turismo (ver Figura 1.1). Por ejemplo, un turista desea viajar a Nueva York y necesita cubrir diferentes necesidades como: hospedaje, alimentación, transporte, compra de productos, etc. Es posible que también necesite diferentes mapas de los sitios que visitará, e incluso información sobre pronósticos del clima a fin de considerar las precauciones adecuadas.

Capítulo 1. Introducción
Alineación de ontologías usando el método Boosting 4
Figura 1.1. Integración de información geográfica. La alineación de ontologías permitiría extraer información desde
servicios web semánticos, por medio de la detección de correspondencias semánticas.
A fin de obtener información que le permita satisfacer sus necesidades básicas, un turista requiere consultar diversas fuentes de información (ver Figura 1.1). De existir servicios web semánticos y mecanismos para integrarlos dinámicamente, sería posible construir sistemas Web avanzados que encuentren toda la información que un turista necesite con solo definir una consulta. Otra motivación relevante es encontrar coincidencias de manera automática entre ontologías, para que sean reutilizadas o como apoyo para elaborar diseños nuevos. Por ejemplo, combinar ontologías de los proyectos SWEET-NASA (ver Figura 1.2) y de Protégé-Stanford (Protégé, 2006), evitando el arduo y tedioso trabajo que implicaría desarrollar el proceso de forma manual. El proceso de alineación no se ha desarrollado de forma totalmente automática (Noy, et al., 1999) y (Euzenat, et al., 2004b), pero hacerlo de manera manual implica un gran trabajo. Es por eso que se necesitan mecanismos semiautomáticos que dependan menos de la intervención de un usuario.

Capítulo 1. Introducción
Alineación de ontologías usando el método Boosting 5
Figura 1.2. Ontologías del proyecto SWEET y sus interrelaciones; ejemplo de correspondencias
semánticas entre ontologías
Actualmente los mecanismos para encontrar correspondencias entre entidades de ontologías se basan en el cómputo de similitud semántica. Existen diferentes métodos para medir similitud diseñados en el contexto de análisis de datos, estadística, machine learning, language engineering, etc (Rahm, et al., 2001). Su condición de uso depende de los objetos a comparar, el contexto y la semántica explicita e implícita de estos objetos. En este aspecto, el consorcio KnowledgeWeb (KnowledgeWeb Consortium) desarrolló el estado del arte en alineación de ontologías (state of the art on ontology alignment) (Euzenat, et al., 2004b) y el foro International Workshop on Ontology Matching (Caracciolo, et al., 2008), en el cual se describen los avances actuales en alineación y resultados sobre pruebas realizadas a sistemas de alineación. En el state of the art on ontology alignment, se resalta una clasificación de métodos para medir similitud semántica y estructural. También se exponen los métodos de similitud con base en los objetos que se comparan: a nivel de nombre de elementos (etiquetas), y a nivel estructural (jerarquías). En esta tesis se propone una estrategia de alineación basada en la combinación de medidas de similitud, mediante el método Boosting (un algoritmo de aprendizaje automático) para

Capítulo 1. Introducción
Alineación de ontologías usando el método Boosting 6
optimización e integración. Específicamente se usó AdaBoost (algoritmo Boosting general). La confiabilidad de los resultados finales son validados por un usuario.
1.3 Planteamiento del problema
La heterogeneidad entre estructuras de datos como ontologías, se debe al uso de diferentes descripciones para definir la misma información. Por lo tanto, es necesario distinguir aquellas entidades entre estructuras de datos que estén relacionadas (igualdad o diferencia). Precisamente, el principal problema en alineación de ontologías consiste en encontrar a qué entidad en una ontología, corresponde a otra entidad en otra ontología (Euzenat, et al., 2004b) Existen diversos enfoques propuestos en algoritmos de alineación, algunos basados en reglas, en arquitectura de capas, en métodos formales o heurísticos. También se han propuesto muchos métodos para medir la similitud semántica entre objetos (Rahm, et al., 2001), sin embargo, es necesario integrar características de estos métodos, a fin de definir una estrategia que combine sus ventajas y mejore la precisión de los resultados de la alineación. Por otro lado, resulta complicado definir e integrar “efectivamente” un conjunto de criterios que ayuden a decidir si dos entidades tienen alguna correspondencia. Por ejemplo, dados los nombres de las entidades (ver Figura 1.3): “BodyOfWater” y “WaterBodies”, inicialmente podemos calcular su similitud léxica comparando letra por letra, estrictamente, debido al orden de las palabras, el valor de similitud puede ser muy bajo. En este ejemplo, aunque observamos que ambos conceptos significan lo mismo, la construcción léxica de estos nombres no permite que un software detecte su correspondencia fácilmente, más difícil sin un tratamiento previo a los términos. Aunque sabemos que semánticamente ambas entidades son equivalentes, para encontrar una correspondencia, es necesario analizar otros elementos que son parte de la semántica de las entidades. Podemos decir que en un procedimiento para medir la similitud, los componentes semánticos (e.g. propiedades y relaciones) entre dos entidades, pueden dar un mayor peso para determinar su grado de correspondencia. Por eso se necesita un proceso de alineación que contemple los criterios semánticos para encontrar las correspondencias semánticas entre las entidades de las ontologías.

Capítulo 1. Introducción
Alineación de ontologías usando el método Boosting 7
Figura 1.3. : Posibles correspondencias entre dos ontologías, la primera (obtenida de SWEET- NASA) describe
objetos espaciales, y la segunda describe el dominio de la hidrósfera (The Florida International University Geo-Spatial Database)
Otra dificultad, se presenta al aplicar técnicas de aprendizaje automático a fin de mejorar los resultados de los algoritmos de alineación. Algunos de estos algoritmos identifican alineaciones correctas e incorrectas. Sin embargo, con este enfoque un algoritmo de alineación puede aprender con varias parejas de ontologías, aunque no necesariamente el algoritmo funcionará correctamente para un nuevo par diferente de ontologías (Euzenat, et al., 2004b). Por otro lado, el turismo electrónico se ha convertido en un área creciente. No obstante, actualmente son requeridos mecanismos de interoperación entre sistemas (Missikoff, 2002), donde la alineación de ontologías representa una opción como mecanismo de interoperación. Muchos sistemas turísticos utilizan componentes espaciales (e.g. coordenadas geográficas) para la ubicación de sitios de interés (imagineit, 2006), por tanto están relacionados al dominio geoespacial. El software especializado en turismo puede utilizar ontologías como una base de datos conceptual (Programme, 2006) y (Cardoso, 2006). Sin embargo, la heterogeneidad semántica entre estas ontologías, no permite desarrollar aplicaciones que consulten integralmente los datos que contienen.

Capítulo 1. Introducción
Alineación de ontologías usando el método Boosting 8
En GIS1 uno de los retos es establecer interoperabilidad entre sistemas debido la heterogeneidad semántica entre las fuentes de información (Fonseca, et al., 2002). En este sentido la alineación de ontologías puede ser un mecanismo útil para establecer interoperabilidad semántica entre ontologías.
1.4 Objetivo
Desarrollar un algoritmo para alinear dos ontologías, mediante la identificación de correspondencias semánticas entre entidades de dos ontologías. El algoritmo se basará en medidas de similitud entre entidades de ontologías y el método Boosting.
También se definirá una aplicación de la alineación de ontologías en el dominio geoespacial. Particularmente al utilizar los resultados derivados de alinear dos ontologías geográfico-turísticas de recursos turísticos en la zona de Cancún y Acapulco.
1.4.1 Objetivos particulares
o Analizar los algoritmos de alineación de ontologías en el estado del arte actual. o Seleccionar los métodos de similitud léxica y semántica entre entidades de dos
ontologías. o Diseñar un algoritmo de alineación de ontologías, basado en medidas de similitud y
en el método AdaBoost. o Definir la arquitectura modular del sistema de alineación. o Seleccionar un algoritmo de clasificación para categorizar valores de similitud, y
como algoritmo de aprendizaje base para AdaBoost. o Definir un caso de aplicación de la alineación de ontologías. o Selección de ontologías turísticas para el caso de aplicación y para realizar pruebas
del sistema de alineación.
1.5 Alcances y limitaciones
De acuerdo con el trabajo de tesis desarrollado, los alcances de la misma están orientados a desarrollar un algoritmo de alineación de ontologías por medio de medidas de similitud, y el método Boosting. El caso de estudio es una aplicación turística. El trabajo es acotado bajo las siguientes ideas: Elementos de ontologías: Para nuestros fines, se define una ontología como una especificación formal de una conceptualización compartida (Gruber, 1993). Para esta tesis, 1 GIS - Sistemas de Información Geográfica

Capítulo 1. Introducción
Alineación de ontologías usando el método Boosting 9
los elementos de las ontologías que se consideraran son: clases individuales (conceptos), taxonomías de conceptos (jerarquía de clases) (Noy, et al., 2005), y propiedades de conceptos. Los axiomas en ontologías no serán abordados.
Idioma: Las ontologías deben estar definidas en el mismo vocabulario de un idioma.
Lenguaje de diseño: Las ontologías deben ser construidas bajo la misma especificación del lenguaje de marcado. En este caso se escogió OWL-DL, por ser uno de los formatos recomendados por la W3C. Además OWL es usado en las pruebas de la OAEI (Ontology Aligment Evaluation Initiative). Tamaño de las ontologías: Se consideran para la alineación solo ontologías cortas, no más de 50 conceptos en la jerarquía de clases.
Número de ontologías: Únicamente nos reservamos al uso de dos ontologías (alineación). La complejidad aumenta para más de dos ontologías (Multi-Alineación) (Euzenat, 2006b), por eso no se consideran más de dos ontologías.
Restricción de términos: Suponemos que los nombres de los conceptos a lo más pueden estar compuestos por tres palabras atómicas, y que un término solo se refiera a un concepto. Las recomendaciones para la definición de términos se aborda en la especificación ISO-704 (ISO, 2008).
Nivel de complejidad: Es difícil esperar que el proceso de alineación pueda ser desarrollado completamente de forma automática, aún se requiere la intervención del experto para solucionar los conflictos semánticos obtenidos en los resultados de dicho proceso.
Caso de aplicación turístico: Los resultados de la alineación, en los cuales se presentan las correspondencias semánticas entre conceptos, se agregan de forma manual en el código fuente de la aplicación web propuesta, así como las propiedades de las parejas de conceptos.

Capítulo 1. Introducción
Alineación de ontologías usando el método Boosting 10
1.6 Justificación
Las ontologías crecen en tamaño y en número, buscar una conciliación semántica entre ontologías de forma manual, es un trabajo arduo y propenso a errores humanos. Por tanto, la alineación debería ser un proceso que requiera la mínima intervención del usuario. El proceso de alineación de ontologías, es un tema importante para la Web Semántica, ya que las ontologías describen la semántica de los datos. En la Web Semántica se pretende obtener resultados más precisos a las consultas de los usuarios (Berners-Lee, et al., 2001), la alineación puede ser una herramienta útil para este propósito. Por otro lado, en esta tesis proponemos el uso de AdaBoost (algoritmo tipo Boosting), como un enfoque de integración y optimización. A continuación, se abordan algunos argumentos que justifican el uso de AdaBoost como parte de la solución propuesta:
• Desempeño: AdaBoost fue comparado con cuatro métodos de clasificación de textos: naive Bayes, probabilistic TF-IDF, Rocchio y sleeping experts. Los algoritmos fueron probados con dos corpus de textos “Reuter’s newswire articles” y “AP newswire headlines”. AdaBoost obtuvo el rango de error más bajo (Freund, et al., 1996).
• Uso de AdaBoost en alineación: AdaBoost no se ha usado como componente directo en alineación de acuerdo a (Euzenat, et al., 2004b) y (Euzenat, et al., 2006).
• AdaBoost ha sido probado en problemas semánticos: AdaBoost se ha aplicado a una variedad de problemas de clasificación, por experimentación demostró ser altamente competitivo en el contexto de categorización de textos. Recientemente en (Cai, et al., 2003), AdaBoost fue seleccionado como la solución principal para combinar eficientemente procesos basados en características de términos y extracción automática de características semánticas en colecciones de documentos.
• Por otro lado, Dell Zhang and Wee Sun Lee propusieron un marco de trabajo para integración de taxonomías web (Zhang, et al., 2004) usando AdaBoost. Estos investigadores, afirman que este enfoque puede ser usado como un componente básico de un sistema para mapeo entre ontologías, aspecto que podría apoyar en el proceso de alineación.
Podemos decir que la adecuada combinación de estrategias puede resultar en un proceso de alineación con resultados precisos, y útil en diferentes aplicaciones. En el marco teórico se mencionan algunas de estas aplicaciones.

Capítulo 1. Introducción
Alineación de ontologías usando el método Boosting 11
1.7 Hipótesis
Motivada por las secciones anteriores, en esta sección se abordan algunas hipótesis. Sobre el planteamiento del problema mencionado, las siguientes suposiciones son consideradas:
• Si se combinan diferentes medidas de similitud en el proceso de alineación; es posible aprovechar las ventajas de cada medida y obtener resultados más precisos en el proceso.
• Si se considera que ciertas medidas de similitud son más importantes que otras (debido a los elementos de las ontologías que utilizan en la medición); es posible mejorar la precisión de los resultados.
• Al combinar diferentes medidas de similitud en un enfoque de alineación integral; es posible reducir la intervención del usuario para validar la confiabilidad de los resultados finales
• Al emplear AdaBoost como un método de integración y optimización en el proceso de alineación; es posible obtener resultados con mayor precisión.
1.8 Organización del documento de tesis
En el Capítulo 2 se presenta el estado de arte donde se ubica la presente tesis. Por otro lado, el Capítulo 3 describe los fundamentos sobre ontologías, alineación de ontologías, aprendizaje automático, web semántica y turismo electrónico. Para el Capítulo 4, se aborda la metodología propuesta. Este capítulo describe detalladamente cada componente utilizado en la propuesta de solución. Los resultados experimentales se discuten en el Capítulo 5. Finalmente en el Capítulo 6 se exponen las conclusiones y el trabajo futuro.

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 12
CAPÍTULO 2 : ESTADO DEL ARTE Una de las necesidades para usar ontologías es para describir la semántica de los datos (que normalmente son nombrados como metadatos). Las ontologías proporcionan una manera uniforme para compartir información entre distintos sistemas de cómputo. A continuación se listan algunos artículos revisados que sustentan la presente investigación.
2.1 Sistemas de alineación de ontologías
En esta sección, se estudian diversos sistemas de alineación de ontologías. Por su desempeño algunos trabajos son sugeridos por Ontology Aligment Evaluation Iniciative. Los trabajos que consideramos más influyentes en nuestra propuesta de solución son Falcon, el sistema AgreementMaker, RiMON y State of the Art on Ontology Aligment, entre otros. Adicionalmente, se realizan comentarios sobre estos trabajos en puntos relevantes que fundamentan esta tesis.
2.1.1 Alineación de ontologías con Falcon-AO (Jian, et al., 2005)
Falcon-AO es una herramienta para alineación de ontologías que consiste en la integración de dos matchers (en este caso, procesos para encontrar correspondencias semánticas entre ontologías): uno es llamado LMO y está basado en similitud lingüística (linguistic matching), el otro es un matcher basado en similitud de grafos (graph matching) y es nombrado GMO. En esta aplicación el matcher GMO toma como entrada alineaciones previas provenientes del matcher LMO y utiliza otras alineaciones de entrada provenientes del lenguaje de diseño de las ontologías, ver Figura 2.1. Las alineaciones confiables son obtenidas a través de LMO; así como de GMO. Falcon mide y valida la confiabilidad de sus resultados al analizar la comparabilidad estructural y lingüística de las dos ontologías que están siendo comparadas. El desempeño de Falcon fue medido a través de las pruebas provistas por la OAEI 2005 (Ontology Aligment Evaluation Initiative) organización que propone campañas de evaluación a los métodos de alineación y que pertenece a la ISWC (International Semantic Web Conference), uno de los foros más importantes en investigación de la Web Semántica.

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 13
Figura 2.1. Arquitectura básica de la primera versión de Falcon-AO
2.1.1.1 Proceso de correspondencia Lingüística LMO (Linguistic Matching Ontology)
La premisa en este trabajo es que la similitud lingüística es muy importante en el proceso de alineación:
De forma general la similitud lingüística entre dos entidades depende de los nombres, etiquetas, comentarios y otras descripciones.
Para obtener la similitud lingüística, LMO combina el enfoque basado en comparación léxica y un enfoque basado en análisis estadístico. Para la similitud lingüística nombrada SS, se utilizó la Distancia de Levenshtein (medida de similitud léxica) entre nombres de entidades y una función para capturar la similitud entre cadenas largas. Para el análisis estadístico se usó el modelo espacio vectorial (Vector Space Model). Este método es interesante, porque se usó para ponderar cada entidad (clases, propiedades, e instancias) de una ontología respecto al resto de los elementos de sí misma, para después realizar la comparación con otra ontología.

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 14
Una vez ponderada cada entidad, se construye una colección de documentos y sus vectores por cada ontología, finalmente se calcula la similitud (nombrada DS) entre documentos por medio del producto escalar entre vectores. Cabe destacar, que previo a la extracción de las entidades de los vectores, se ejecuta un proceso de preparación, que consiste en: separación de palabras, stemming (reducir una palabra a su raíz) y eliminación de “stop words” (preposiciones). Finalmente los dos métodos para medir similitud lingüística son combinados linealmente mediante la siguiente fórmula, donde los coeficientes son experimentales y se le ha otorgado mayor peso a los resultados a la similitud DS:
_ 0.8 0.2
2.1.1.2 Proceso de correspondencia basada en Grafos GMO (Graph Matching Ontology)
La idea principal es medir la similitud entre dos entidades (de dos ontologías), considerando la acumulación de similitudes de sentencias involucradas (tripletas), ambas entidades a comparar se consideran dentro de la misma estructura: sujeto, predicado y objeto. Por otro lado, GMO también toma en cuenta la acumulación de las similitudes de entidades vecinas respecto a las dos entidades que están siendo comparadas. Como entrada GMO, acepta un conjunto de pares de entidades relacionadas, que son encontradas previamente por otros algoritmos de similitud (matching). A la salida GMO proporciona parejas de entidades adicionales al comparar la similitud estructural. GMO puede ser integrado con otros algoritmos para encontrar correspondencias semánticas. Sin embargo, se necesita otro componente para evaluar la confiabilidad de los resultados de GMO, en este trabajo se usó un enfoque de comparabilidad que realiza una comparación entre las ontologías de forma global con base en la similitud lingüística y estructural de ambas ontologías. En otras palabras, el mecanismo de evaluación mide la similitud global, la cual es utilizada para validar la confiabilidad de los resultados de GMO.
2.1.1.3 Evaluación de resultados
Un enfoque para evaluar los resultados proporcionados por GMO es la comparabilidad lingüística y estructural. El enfoque de evaluación está basado en dos medidas: una de comparabilidad lingüística (LC) y otra de comparabilidad estructural (SC). LC se mide

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 15
por medio del número de elementos de pares de entidades que hayan rebasado un umbral de similitud (valor definido empíricamente) y del total de entidades en cada ontología. La comparabilidad estructural es determinada a través de las ocurrencias de las propiedades incorporadas usadas en las dos ontologías a ser alineadas, es decir, vocabulario para definir propiedades, el cual es incorporado y usados por los lenguajes OWL y RDF, en este caso se construyen tripletas para la comparabilidad estructural (e.g. rdf: datatype, rdf:subClassOf and owl:onProperty). Finalmente un modelo vectorial define esta comparabilidad con la frecuencia de propiedades usadas en ambas ontologías, y el número de ocurrencias. Es importante mostrar los criterios de validación generales basadas en la comparabilidad de similitud global que se ocuparon en este trabajo y que como referencia son útiles para construir las reglas de decisión en MatchBoost. Para decidir el nivel de relación que tienen un par de entidades comparadas, se utilizan los siguientes criterios:
• Se establece que la similitud lingüística es algo más confiable que la similitud estructural, entonces las alineaciones derivadas de similitud lingüística son aceptadas por Falcon-AO.
• Cuando la comparabilidad lingüística es alta y la comparabilidad estructural es baja. Solo las alineaciones con alta similitud estructural proporcionadas por GMO son aceptadas.
• Si la comparabilidad lingüística es baja, todas las alineaciones generadas por GMO son aceptadas por Falcon-AO. Ya que no existe suficiente información para decidir si las alineaciones son confiables.
2.1.1.4 Prueba de referencia sistemática
Para obtener los resultados experimentales se utilizaron el conjunto de pruebas sistemáticas definidas por la OAEI 2005 (OAEI, 2004), la cuales consisten en un conjunto de ontologías (escritas en OWL) de prueba para los algoritmos de alineación. Particularmente, se realizaron las siguientes pruebas:
• Prueba 101-104: Las ontologías fuente contienen clases y propiedades con el mismo nombre. Falcon tuvo un buen desempeño.
• Prueba 201-210: Esta prueba consiste en diez pares de ontologías que tienen una alta similitud estructural, es decir, cada par de ontologías a alinear son

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 16
estructuralmente muy similares. El sistema toma más tiempo para obtener resultados. Sin embargo, Falcon obtiene buenos resultados.
• Prueba 248-266: Compuesta por quince pruebas, son las más complicadas por que la similitud lingüística y estructural es baja. Si la similitud lingüística es muy baja, y Falcon no obtiene muy buenos resultados, ya que algunos casos son muy difíciles de resolver.
• Prueba 301-304: Prueba de ontologías reales, cada pareja de ontologías tiene alta similitud lingüística pero baja similitud estructural. Los resultados de Falcon provienen de LMO, por tanto las alineaciones con alta similitud encontradas por GMO son confiables.
2.1.1.5 Comentarios
Falcon-AO se desempeña bien cuando las estructuras de las ontologías son muy similares entre sí o existe mucha similitud léxica entre las mismas. También este sistema proporciona buenos resultados cuando las dos ontologías tienen poca similitud léxica pero alta similitud estructural. Sin embargo, cuando existe poco vocabulario común entre las ontologías y mientras sus estructuras son bastante diferentes, Falcon-AO difícilmente encuentra correspondencias. Es necesario usar diccionarios léxicos en alineación, ya que las personas expresan la misma entidad pero en palabras distintas, en esta versión Falcon-AO no soporta correspondencias con cardinalidad tipo muchos a muchos. Las medidas de comparabilidad deben ser mejoradas. Por lo tanto, la similitud lingüística juega un rol importante en alineación de ontologías. Los aspectos interesantes, que se pueden relacionar con esta tesis, es la comparabilidad lingüística y estructural como parámetros para validar los datos. También, la importancia que se le asigna a la similitud lingüística, ya que proporciona las primeras alineaciones correctas y de hipótesis, las cuales son usadas por el proceso de similitud estructural que obtendría resultados más precisos. Finalmente, la similitud lingüística ayuda a encontrar términos o palabras comunes en las ontologías, es decir, se compara en primer lugar aspectos “visibles” de las ontologías, como los nombres de las entidades.
Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 17
2.1.2 Métodos basados en estructuras para mejorar la Alineación de Ontologías Geoespaciales (Sunna, et al., 2007)
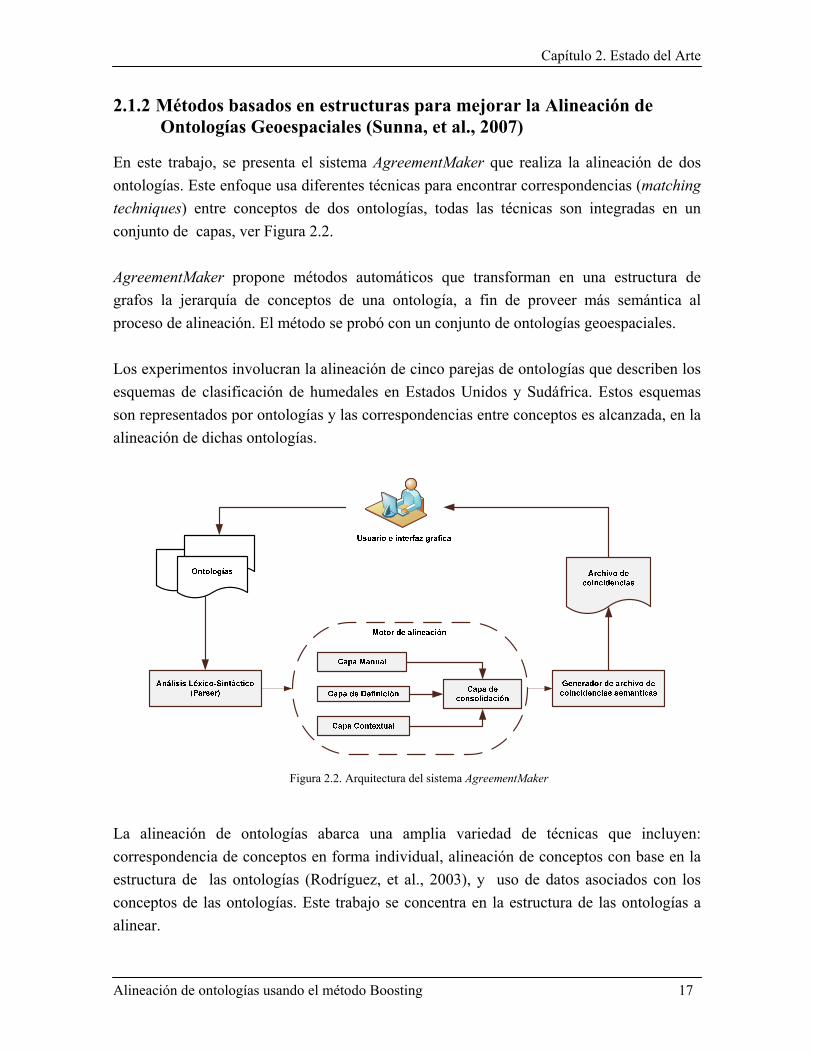
En este trabajo, se presenta el sistema AgreementMaker que realiza la alineación de dos ontologías. Este enfoque usa diferentes técnicas para encontrar correspondencias (matching techniques) entre conceptos de dos ontologías, todas las técnicas son integradas en un conjunto de capas, ver Figura 2.2. AgreementMaker propone métodos automáticos que transforman en una estructura de grafos la jerarquía de conceptos de una ontología, a fin de proveer más semántica al proceso de alineación. El método se probó con un conjunto de ontologías geoespaciales. Los experimentos involucran la alineación de cinco parejas de ontologías que describen los esquemas de clasificación de humedales en Estados Unidos y Sudáfrica. Estos esquemas son representados por ontologías y las correspondencias entre conceptos es alcanzada, en la alineación de dichas ontologías.
Figura 2.2. Arquitectura del sistema AgreementMaker
La alineación de ontologías abarca una amplia variedad de técnicas que incluyen: correspondencia de conceptos en forma individual, alineación de conceptos con base en la estructura de las ontologías (Rodríguez, et al., 2003), y uso de datos asociados con los conceptos de las ontologías. Este trabajo se concentra en la estructura de las ontologías a alinear.

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 18
El tipo de arquitectura utilizada es punto a punto (peer-to-peer architecture). Donde los mapeos son establecidos entre parejas de ontologías. La ontología desde la cual los mapeos son definidos es nombrada fuente (source) y la otra ontología se nombra objetivo (target). AgreementMaker maneja un enfoque multi-capa, que consiste de 4 capas: dos usan métodos automáticos, una usa un método semiautomático, y la otra es un método manual (Cruz, et al., 2007). La Figura 2.2 muestra la integración de las capas en la arquitectura de sistema. El proceso completo es supervisado por un experto del dominio. A continuación se describe cada capa usada:
• Primera capa, consiste en un proceso de mapeo automático, compara el significado de cada concepto en la primera ontología con cada concepto de la segunda ontología, según la definición de los conceptos. Esta capa es asistida por un diccionario. La medida de la similitud entre conceptos puede tomar un valor desde 0% (ninguna correspondencia) al 100% (correspondencia exacta). Si no existe un diccionario, el proceso es desarrollado únicamente comparando el nombre de los conceptos y cualquier descripción o conjunto de propiedades.
• La segunda capa, es un proceso manual de mapeo y es conducido por un experto de dominio. Las relaciones entre los conceptos mapeados, pueden ser de varios tipos: subconjunto, subconjunto completo, superconjunto, superconjunto completo e igualdad de conjuntos.
• Tercera capa, se ejecuta un proceso de mapeo semiautomático por contexto, en el cual los mapeos son deducidos al considerar mapeos establecidos previamente. Trabajando desde las hojas del árbol ontológico, se realiza ascendentemente un proceso semiautomático de deducción nivel por nivel.
• En la cuarta capa es desarrollado un proceso automático de consolidación de mapeos, en el cual son resueltos los posibles conflictos semánticos de las capas anteriores. En esta capa el experto del dominio determina la importancia de las capas al asignar un nivel de prioridad a cada una. Basándose en el nivel de prioridad, los actuales mapeos son determinados automáticamente, la información de mapeos que es considerara proviene desde la capa de más alto nivel de prioridad.
Para mejorar el proceso general de alineación, se utilizaron dos métodos de similitud automáticos basados en estructura: el método Descendants Similarity Inheritance (DSI),

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 19
que usa las relaciones entre los conceptos ancestros, y el método Sibling’s Similarity Contribution (SSC), que usa las relaciones entre los conceptos vecinos.
2.1.2.1 Comentarios
El enfoque semiautomático que se propone en AgreementMaker, destaca por involucrar la intervención del usuario experto durante el proceso de alineación, lo cual contribuye en precisión al detectar las correspondencias semánticas. Sin embargo, este enfoque podría no facilitar el proceso de alineación al usuario, cuando se procesan ontologías de escala mayor; aumentando el tiempo de procesamiento para encontrar correspondencias. En esta tesis, se propone un enfoque en donde la intervención del usuario es necesaria solamente para evaluar los resultados finales.
2.1.3 Estado del arte de alineación de ontologías: Knowledge Web (Euzenat, et al., 2004b)
El estado del arte en alineación de ontologías es un proyecto desarrollado por universidades como: Stanford, INR|IA de Francia, FU de Berlín, Universidad de Manchester, entre otras. Según los autores, algunos de los problemas de heterogeneidad en la web semántica pueden ser resueltos a través de la alineación de ontologías. Principalmente, este trabajo presenta las técnicas más recientes en alineación de ontologías; así como convenciones entre definiciones y tópicos relacionados, como la definición de alineación de ontologías, posibles aplicaciones, clasificación de técnicas para medir similitud, y análisis de los últimos sistemas de alineación. También el conocimiento sobre alineación se actualiza constantemente a través de la Ontology Alignment Evaluation Initiative (OAEI, 2004). Diversas estrategias de alineación han sido propuestas, muchas mezclan las técnicas mencionadas hacia un objetivo en particular, obtener un resultado optimizado. Estas técnicas se clasifican por medio de las características de las ontologías (etiquetas, estructuras, instancias, semántica, etc). Éstas utilizan diversas disciplinas como la estadística, aprendizaje automático o análisis de datos. También se propone una revisión de las técnicas de alineación, estableciendo una clasificación en dos niveles: Nivel de elemento y nivel de estructura:

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 20
• Nivel de elemento: Estas técnicas están basadas en cadenas, lenguaje, consideraciones lingüísticas, restricciones o re-usó de alineaciones. Las técnicas de nivel de elemento, consideran las etiquetas de los conceptos, sus definiciones, el lenguaje en el que las ontologías son expresadas, y cualquier posibilidad para reutilizar previos mapeos para derivar nuevos.
• Nivel de estructura: Estas técnicas están basadas en grafos, taxonomías, u otros
modelos. Las técnicas a nivel de estructura consideran la ubicación del concepto en la estructura de la ontología, y cómo las correspondencias entre los conceptos pueden contribuir a establecer otras correspondencias.
2.1.3.1 Comentarios
Existen muchas técnicas para realizar la alineación, muchos sistemas han sido desarrollados, pero existen pocas comparaciones entre técnicas. Serian útiles sistemas que mezclen diferentes técnicas. Este trabajo desarrollado por Knowledge Web2 tiene el fin de proporcionar una lista con los sistemas evaluados y propone diferentes pruebas de evaluación.
2.1.4 RiMON (Li, et al., 2008)
Esta aplicación combina diferentes estrategias para obtener resultados, se basa en una arquitectura peer to peer, es decir, encontrar comparar los elementos de una ontología contra los elementos de otra ontología. Las estrategias utilizadas en RiMON consisten en técnicas basadas en lingüística: Distancia de Levenshtein y statistical learning. También técnicas basadas en estructuras: propagación de similitud (similarity-propagation), propagación de propiedad a propiedad (property-to-property propagation), y propagación de concepto a propiedad (concept-to-property propagation). Inicialmente RiMON examina la estructura de las ontologías y la similitud léxica entre conceptos, para determinar qué estrategias se utilizan en el proceso de alineación. Si existe una alta similitud léxica entre los nombres, el sistema confiará más en técnicas basadas en lingüística para encontrar las correspondencias entre conceptos, después se aplican las estrategias de alineación seleccionadas por un experto. 2 http://knowledgeweb.semanticweb.org/

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 21
Cada estrategia obtiene su propio resultado independiente, después los resultados son integrados usando un método de interpolación lineal. También se emplean múltiples técnicas de similitud a fin de determinar cuál de las técnicas tendrán un rol más importante en cada correspondencia obtenida. Cuando diferentes procesos intervienen en determinar los vínculos de los conceptos entre dos ontologías, pueden existir conflictos. Para solucionarlos, se usan técnicas de negociación, donde las entidades establecen un consenso entre ellas. Diferentes capas establecen mapeos y son conciliadas por un experto, quién especifica la prioridad de cada capa, para establecer un acuerdo entre las mismas.
2.1.4.1 Comentarios
Al igual que RiMON, nuestra arquitectura de alineación también se basa en la combinación de diversas estrategias para encontrar correspondencias semánticas entre ontologías, y en el uso de la distancia edit como una medida de similitud léxica confiable, esto fortalece los fundamentos de nuestra propuesta de solución. Finalmente, RiMON coincide con Falcon-AO sobre la importancia que se le asigna a la similitud lingüística.
2.1.5 Similarity flooding (Melnik, et al., 2001)
Técnica basada en modelos estructurales, este algoritmo es usado para establecer correspondencias en varios modelos o estructuras de datos, como entrada recibe dos modelos de datos que después serán convertidos a grafos. Similarity flooding funciona bajo el principio: “si dos grafos son similares entonces, también sus conceptos adyacentes (en los grafos) en cierto grado también son similares”. El algoritmo comienza al obtener las correspondencias iníciales entre los elementos (de los dos grafos creados), utilizando una función de similitud basada en cadenas de texto, después se retornan las similitudes iníciales entre los elementos que corresponden. Con las correspondencias iníciales, el algoritmo procede a establecer más correspondencias entre otros elementos, basándose en la suposición que si dos elementos corresponden satisfactoriamente con alguna medida de similitud, también sus elementos vecinos son similares. Las iteraciones continúan incrementando las similitudes de los conceptos en los grafos, hasta un punto fijo en que todas las medidas de similitud para todos los conceptos se han

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 22
estabilizado, este algoritmo corresponde a la categoría de técnica basado en el nivel estructural de los modelos.
2.1.6 OLA alineación de ontologías (Euzenat, et al., 2004b)
OWL Lite Alignment (OLA) está diseñado para alinear ontologías OWL-Lite. Principalmente emplea técnicas lingüísticas basadas a nivel de elemento y estructuras, las técnicas a emplear pueden ser escogidas por el usuario, y soporta mapeos manuales y automáticos. Inicialmente OLA, solicita parámetros mínimos al usuario para obtener la mayor cantidad de resultados correctos y poder iniciar el proceso de alineación. OLA transforma las ontologías OWL en estructuras basadas en grafos encontrando todas las relaciones entre entidades (e.g., clase, propiedad) y considera todas las características de las entidades (e.g., superclases, propiedades). Estos grafos establecen las restricciones para calcular la similitud entre entidades de ontologías usando diversas medidas de similitud ponderadas, las cuales son combinadas de forma lineal. Se consideran conjuntos de relaciones entre parejas de entidades, que dependen de correspondencias locales (entidad-relación-entidad). OLA ejecuta un algoritmo iterativo que computa una primera aproximación de la similitud entre entidades, después establece relaciones entre entidades y vuelve a iterar. El cálculo de la similitud es más preciso en cada iteración. Las correspondencias finales se establecen por medio un umbral o por la optimización en las selecciones de parejas de clases.
2.2 Aplicaciones de aprendizaje automático en integración de información
En las secciones posteriores, se ilustran algunas aplicaciones de algoritmos de aprendizaje automático aplicados a integración de información. Algunos de los algoritmos que han influenciado en esta tesis, están relacionados con integración de taxonomías Web con base en Boosting, y un método para integrar esquemas de datos utilizando redes neuronales. Podemos decir que en el estado del arte, Boosting es visto como un proceso de optimización. En esta tesis también se pretende mostrar que Boosting es útil en el proceso para integrar valores de medidas de similitud y encontrar correspondencias semánticas.

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 23
2.2.1 AdaRank: Un algoritmo Boosting para Recuperación de Información (Xu, et al., 2007)
En este artículo, se propone desarrollar un algoritmo de aprendizaje que directamente optimice cualquier medida de desempeño para recuperación de documentos (en inglés, information retrieval (IR)). La optimización se basa en el algoritmo AdaBoost. Este trabajo propone desarrollar un algoritmo Boosting para la recuperación de información (IR) llamado AdaRank. Este algoritmo utiliza una combinación lineal que integra ponderadores débiles (weak rankers). Durante el aprendizaje, itera el proceso de re-ponderación sobre el conjunto de entrenamiento (training sample), creando un ponderador débil (weak ranker) y calculando un peso para cada ponderador creado. Un límite inferior sobre el desempeño de los datos de entrenamiento es dado, este límite indica la precisión de la ponderación (ranking) en términos del desempeño de las medidas. El algoritmo AdaRank puede iterativamente optimizar una función de pérdida exponencial (exponential loss function) basada en cualquier medida de desempeño de recuperación de información. Varios métodos de aprendizaje en ponderación han sido desarrollados y aplicados a recuperación de documentos. Por ejemplo, Herbrich (Herbrich, et al., 2000) propone un algoritmo de aprendizaje para ponderación basado en Support Vector Machines llamado Ranking SVM. Freund tomó un enfoque similar y desarrolló RankBoost (Freund, et al., 2003). Los métodos usados para recuperación de documentos han sido diseñados para optimizar funciones de pérdida débilmente relacionadas al desempeño de las funciones de medida de IR (IR measures), y no a las funciones de pérdida (loss functions) directamente basadas en las medidas; es decir, Ranking SVM y RankBoost entrenan modelos de ponderación para minimizar los errores de clasificaciones en parejas de instancias (una muestra y su clasificación). Los resultados experimentales indican que AdaRank puede superar los métodos de Ranking SVM y RankBoost usando cuatro conjuntos de datos de referencia en común (OHSUMED, WSJ, AP, and .Gov). AdaRank puede ser visto como un método Boosting desarrollado para ponderación, particularmente ponderación en IR (Information retrieval).

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 24
El principal problema en IR es cómo crear un modelo de ponderación que pueda ordenar documentos basados en su relevancia para una consulta dada. Es una práctica común en IR ajustar los parámetros de un modelo de ponderación usando algunos datos etiquetados y una medida de desempeño. AdaRank intenta directamente optimizar diversas medidas de desempeño, pero usa una función de pérdida exponencial basada en el desempeño de las métricas de IR y Boosting. Actualmente, existen tres tópicos de aprendizaje automático aplicados en IR: “learning to ran”, “Boosting” y “direct optimization of performance measures”.
2.2.1.1 Comentarios
AdaRank puede ser visto como un método para la optimización directa del desempeño de las métricas de IR. Podemos concluir que éste enfoque se destaca por usar el método Boosting como un proceso de optimización de medidas de desempeño, de forma similar, esa misma idea ha motivado la presente tesis.
2.2.2 Integración de Taxonomías Web a través de Co-Bootstrapping (Zhang, et al., 2004)
El problema de integración entre una taxonomía fuente y una taxonomía maestra es un problema constante en la Web, pero también importante para la emergente Web Semántica. Una taxonomía, directorio o catálogo, es la división de un conjunto de objetos (documentos, imágenes, productos, bienes, servicios, etc.) en un conjunto de categorías. Existe la necesidad frecuente de integrar objetos desde una taxonomía fuente a una taxonomía maestra. Por ejemplo, sería deseable combinar o agregar productos de diferentes vendedores al catálogo de productos de Amazon.com (un sitio de comercio electrónico). La Figura 2.3 ilustra este problema, los objetos (a, b, c y d) de la taxonomía fuente N se agregan a las categorías (L1 y L3) de la taxonomía maestra M. Previamente, se debe identificar el grado de relación entre la semántica de las categorías en M y N. Encontrar las correspondencias entre dos taxonomías de forma manual es difícil y confuso. Por ejemplo, considere las taxonomías de dos portales web Google y Yahoo!: “Arts/Music/Styles/” y “Entertainment/Music/Genres/”, respectivamente.

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 25
Figura 2.3. Ejemplo de integración de taxonomías (adaptado de una presentación de Dell Zhang)
El problema de integración de taxonomías puede ser formulado como un problema de clasificación. Normalmente, un clasificador podría ser construido usando objetos de la taxonomía maestra como ejemplos de entrenamiento. También si se considera la información de la taxonomía fuente se pueden plantear mejores clasificadores. En este trabajo se propone un enfoque nombrado co-bootstrapping para optimizar la clasificación al explotar el conocimiento implícito en las taxonomías.
2.2.2.1 Planteamiento general del problema
Las taxonomías están frecuentemente organizadas como jerarquías. Dadas dos taxonomías:
• Una taxonomía maestra M con un conjunto de categorías C1, C2,…,CM cada una contiene un conjunto de objetos.
• Una taxonomía maestra N con un conjunto de categorías S1, S2,…, SN cada una contiene un conjunto de objetos.
• El problema consiste en encontrar las categorías en M para cada objeto en N.
2.2.2.2 Formulación del problema de clasificación
Inicialmente se plantea un clasificador basado en los objetos de la taxonomía maestra M y en sus características. Después ese clasificador se prueba al clasificar en M los objetos que pertenecen a la categoría fuente N. En detalle la clasificación se plantea a continuación.

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 26
Se toma las clases C1,C2,…,CM, los objetos en M como ejemplos de entrenamiento. Los objetos en N como ejemplos de prueba, tal que la integración de taxonomías pueda ser completada al predecir las clases de pertenencia para cada ejemplo de prueba.
Siendo un problema de multi-clases y multi-clasificación (clases difusas), en el sentido que existen usualmente más de dos clases y un objeto podría pertenecer a mas de una clase, se requirió usar un método “uno vs el resto” para crear un ensamble de clasificadores binarios (SI/NO), uno por cada categoría C en M. El enfoque usa Boosting un poderoso método de aprendizaje automático, para construir clasificadores. La principal idea de Boosting es combinar muchas hipótesis débiles (reglas de clasificación simples y con precisión moderada) en un clasificador de alta precisión. Una hipótesis es una función h de valores reales : Y R. Dado un objeto x y una clase l, la magnitud de h(x,l) es interpretada como una medida de confianza en la predicción que determina si x pertenece a la clase Y, donde Y es un conjunto de clases y el dominio de objetos de una taxonomía. Las hipótesis débiles se basan simples árboles de decisión (Decision Stump):
, 1 0 ,
Este trabajo está basado en AdaBoost.MH (versión multi-clase), el cual obtiene una hipótesis final H(x,l) que es la combinación lineal de todas las hipótesis débiles.
2.2.2.3 Co-Bootstrapping y el análisis de taxonomías
Principalmente dos rasgos fueron considerados para explotar el conocimiento en las taxonomías, los rasgos basados en palabras y categorías; es decir, se da un tratamiento a las taxonomías como documentos de texto, el cual es representado por un conjunto de funciones que miden los rasgos basados en los términos (term-features) que componen un documento. Una función f basada en términos de un documento X, es una función binaria que indica la ausencia o presencia de wh (la h-ésima palabra distinta en la colección de documentos) en X. La función f permite construir mejores clasificadores.
1 0

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 27
Si se tuvieran funciones que describan cada categoría en N, es posible tomar esas funciones como rasgos para entrenar el clasificador para M. Esto permitiría explotar las relaciones semánticas entre las categorías de M y N. Para cada objeto en M, a los rasgos de términos (term-features) se agrega un conjunto de rasgos de categorías (category-feature) FN ={f N1,f N2...,f NJ}, derivados de N. Una función f basada en categorías fNj (1≤j≤N) de un objeto X, es una función binaria que indica si un objeto x pertenece a una categoría Sj (la j-ésima categoría de N); es decir, una función por cada categoría en la taxonomía que reconocen los objetos que le pertenecen:
1 0
De la misma forma, se puede definir un conjunto de categorías y características (category-features) FT {fM1,f M2...,f MM} derivadas de M. El problema restante es obtener esas funciones, que inicialmente se desconocen. Por eso las hipótesis débiles están basadas en estas funciones, y la idea es que se generen dinámicamente. Aunque las taxonomías M y N no son usualmente idénticas, sus categorizaciones frecuentemente tienen alguna superposición semántica. Por tanto, la categorización de N contiene valioso conocimiento implícito acerca de la categorización de M. De esta manera se propone el algoritmo co-bootstrapping, a fin de mejorar la clasificación al explotar este conocimiento implícito. De forma general, inicialmente el algoritmo utiliza dos clasificadores BM y BN, el primero categoriza los objetos de la taxonomía M hacia la taxonomía en N, de forma inversa el segundo clasificador, categoriza los objetos en N hacia la taxonomía de M. Después, en la siguiente iteración se crean dos nuevos clasificadores con base en los resultados de los clasificadores anteriores. Usando los nuevos resultados, en la siguiente interacción dos nuevos clasificadores son creados, así sucesivamente hasta alcanzar cierto número de iteraciones. La técnica co-bootstrapping puede ser ejecutada iterativamente en forma de pin pong, tal que dos clasificadores colaboren entre sí para construir nuevos clasificadores. AdaBoost se complementa con un algoritmo de aprendizaje diseñado con árboles de decisión, para después combinar las hipótesis débiles heterogéneas.
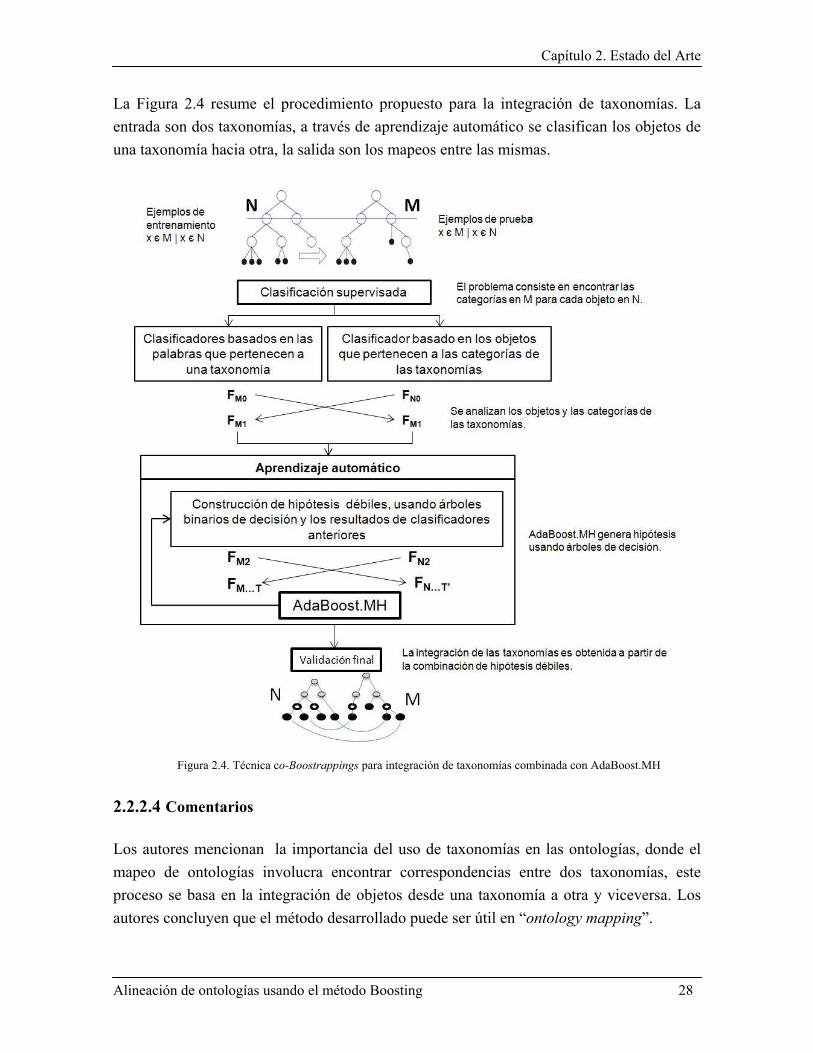
Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 28
La Figura 2.4 resume el procedimiento propuesto para la integración de taxonomías. La entrada son dos taxonomías, a través de aprendizaje automático se clasifican los objetos de una taxonomía hacia otra, la salida son los mapeos entre las mismas.
Figura 2.4. Técnica co-Boostrappings para integración de taxonomías combinada con AdaBoost.MH
2.2.2.4 Comentarios
Los autores mencionan la importancia del uso de taxonomías en las ontologías, donde el mapeo de ontologías involucra encontrar correspondencias entre dos taxonomías, este proceso se basa en la integración de objetos desde una taxonomía a otra y viceversa. Los autores concluyen que el método desarrollado puede ser útil en “ontology mapping”.

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 29
El enfoque presentado puede ser útil en la alineación, al agregar procedimientos para medir la similitud de los conceptos en las ontologías. La contribución de este trabajo, fue un método que explota el conocimiento implícito en una taxonomía fuente para mejorar la integración de taxonomías web.
2.2.3 Un nuevo método para medir similitud semántica en integración de esquemas XML (Jeong, et al., 2008)
En el contexto de integración de esquemas de datos, los esquemas construidos en XML han sido usados como el medio estándar para expresar e intercambiar información entre aplicaciones empresariales. Sin embargo, la diversidad de esquemas construidos en XML dificulta a las empresas la integración e interoperación entre sistemas. Por ello, es importante integrar correctamente esquemas XML. El proceso de integración, es llamado “semantic matchmaking” o “schema matching” (vinculación semántica o integración de esquemas). En este trabajo se presenta una arquitectura para un proceso que integra esquemas XML, basado en la similitud semántica entre estos esquemas. Específicamente, primero se presenta un métrica integral de similitud entre documentos estructurados (e.g. esquemas XML) al incorporar un prominente método de aprendizaje supervisado (Redes Neuronales Parciales basadas en el método de Mínimos Cuadrados (Neural Network-based Partial Least Squares, NNPLS) que considera las relaciones entre varias medidas de similitud. De forma sustancial, se presenta un enfoque nuevo basado en clasificación semi-supervisada para aumentar la confiabilidad del conjunto de datos necesario para entrenar al clasificador NNPLS, con datos hechos a medida y provenientes de la industria. Respecto a las métricas de similitud empleadas, las métricas de similitud para esquemas XML fallan en determinar la similitud léxica, estructural o lógica. La similitud léxica cuantifica la semejanza entre las etiquetas de los esquemas XML usando únicamente información léxica. Comúnmente las medidas de similitud léxica son también dividas en medidas de similitud basadas en la forma léxica (e.g., affix, n-gram, edit distance). Algunas medidas basadas en información semántica son: word sense, sinónimos ponderados, e información basada en contenido de nodos. Que junto con las medidas de similitud estructural como: path matching y tree edit distance, cuantifican la semejanza

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 30
entre esquemas XML tomando en cuenta la similitud léxica y estructural de subelementos/atributos de los términos en los esquemas XML. Cuando no se sabe cuál es la mejor medida para cuantificar la verdadera similitud, una manera natural y segura es agregar una serie de medida. Usar una sola métrica o un conjunto de métricas en una categoría, puede fallar al obtener resultados óptimos, por ejemplo cuando dos documentos no coinciden aunque su similitud léxica es alta (coincidencia en nombre de etiquetas), pero su similitud estructural es baja (sus estructuras son diferentes) por tener diferentes significados. De forma similar, cuando los documentos tienen una alta similitud estructural y una baja similitud léxica. La arquitectura propuesta consiste de dos fases (ver 0), la primera se ejecuta en tiempo real e invoca el proceso de integración “online matching”. La segunda fase es de entrenamiento “offline preparation”, en esta se obtiene un conjunto de datos de entrenamiento confiable (a través de clasificación semi-supervisada).
Construccion del modeloPropapagacionMuestreo inicial
& SupervisiónPreprocesamiento
Normalizacion de terminos
Computo de similitud
Síntesis de similitud Interpretación Esquema
IntegradoRepositorio de
esquemas
Par esquemas XML
Selección de conjunto de entramiento
Preparación fuera de línea (off-line)
Matching en línea (on-line matching)
Figura 2.5. Marco conceptual para “Schema Matching”
Clasificar manualmente los datos, a fin de construir un conjunto de entrenamiento, requiere un enorme esfuerzo. Por esa razón, se planteó una estrategia semi-supervisada que permite clasificar automáticamente datos no etiquetados desde una pequeña muestra previamente clasificada, esto quiere decir que se incrementa el número de ejemplos correctos e incorrectos para el entrenamiento, los cuales representan el conocimiento del problema. Posteriormente se construye un modelo de predicción (prediction model) basado en un robusto clasificador supervisado, el cual predice la similitud semántica usando varias métricas. La fase “online matching” es el procedimiento de “schema matching” que mide la

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 31
similitud entre esquemas y después selecciona los esquemas más confiables que coincidan con base en su similitud. En esta fase cuatro operaciones resaltan, la primera (“Feature engineering”) es el tratamiento léxico de los nombres de los elementos y la extracción de información. Inicialmente, se extraen características como la estructura de una etiqueta o el nombre de su etiqueta raíz, representando esta información en una estructura interna para el cálculo de la similitud. Por otro lado, el tratamiento de “tokenizing” consiste en separar palabras concatenadas en términos compuestos (e.g. PurcharseOrder), lematización que consiste en obtener los lemas de una palabra dada o su forma base (e.g. cars → car) y eliminación de “stop words” (preposiciones en ingles). La segunda operación es el cálculo de similitud (“similarity computation”), un operador experto selecciona un subconjunto de métricas de similitud (a fin de reducir el tiempo de cómputo) desde un conjunto de métricas ya disponibles. Con el subconjunto de medidas definido se calcula la similitud. La operación de síntesis de similitud (“Similarity synthesis”) sintetiza o combina distintas medidas de similitud usando un clasificador supervisado (“NNPLS”). Esta síntesis se puede ver como un clasificador de combinación y predicción. Finalmente un proceso de interpretación e iteración determina a través de un umbral, si los esquemas coinciden o no. En la fase de preparación fuera de línea, principalmente consiste en el incremento de los datos de entrenamiento y en la construcción del clasificador, esta fase consiste de cuatro procedimientos. Resalta la estrategia del incremento del conjunto de prueba usando aprendizaje semi-supervisado (debido al gran esfuerzo manual requerido para determinar si dos esquemas son similares o no). Inicialmente se selecciona un número aleatorio de pares de esquemas. Después en el “Preprocesamiento”, se representan los esquemas en matrices numéricas. Para el “Muestreo y supervisión” donde los expertos seleccionan una parte de la muestra. En la “Propagación” se aplican técnicas semi-supervisadas, se entrena un clasificador (e.g. ANN, clustering) , o es decir, se propaga la muestra inicial al clasificar el resto de los elementos que no habían sido etiquetados, los cuales servirán para un posterior

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 32
entrenamiento, si el clasificador no proporciona resultados adecuados otra estrategia es utilizada. Finalmente en la “Construcción del modelo”, con el nuevo conjunto de datos de entrenamiento obtenido en los pasos anteriores, se construye un clasificador supervisado basado en NNPLS.
2.2.3.1 Síntesis de similitud basada en NNPLS
Para sintetizar varias medidas de similitud, se propuso usar un clasificador supervisado que predice la similitud semántica entre esquemas XML: NNPLS (neural network-based partial least squares), donde múltiples variables de entrada (en este caso métricas de similitud) son mutuamente colineares ( i.e. están relacionadas) y el procesar una dimensión de variables grande requiere de mucho tiempo de computación. La Figura 2.6 muestra el modelo NNPLS para sintetizar un número de medidas de similitud. El vector de entrada consiste de m diferentes medidas de similitud usadas y el vector de salida consiste de un valor simple, es decir la similitud semántica, donde 1(0) significa que dos documentos XML son iguales (o totalmente diferentes). Si un valor de similitud entre dos esquemas comparados esta cerca de 0.5, puede ocurrir alguno de estos tres casos: los esquemas coinciden, están relacionados, o no están relacionados.
Figura 2.6. Síntesis de similitud en el modelo NNPLS
Finalmente para realizar las pruebas fueron usados dos conjuntos de datos: el primero es para extender el conjunto de datos de prueba, el segundo es una fuente datos que muestra el desempeño de la arquitectura propuesta en aplicaciones reales. En este último, se emplearon 200 parejas de esquemas XML, clasificados por cuatro expertos en tres

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 33
categorías: 0 sin relación, 1 débilmente relacionados, y 2 fuertemente relacionados. Se emplearon 18 medidas de similitud de tipo léxica y estructural.
2.2.3.2 Comentarios
En este trabajo se propone un esquema de integración de esquemas XML, usando un clasificador semi-supervisado NNPLS que sintetiza diversas medidas de similitud léxica, semántica y estructural. Los resultados en lo experimentos destacan que este método es confiable y eficiente. Destaca la integración de las medidas de similitud, así como los valores de umbrales para definir el grado de relación entre los esquemas comparados, si dichos umbrales no se definen adecuadamente puede perderse precisión. Respecto a la solución propuesta en esta tesis, se coincide en la idea de integración de medidas y en la categorización del grado de relación entre esquemas (sin relación, débilmente relacionados, fuertemente relacionados).
2.3 Tópicos relacionados
En esta sección se abordan algunos temas relacionados con el desarrollo de tesis.
2.3.1 Web Semántica (W3C, 2008)
En la actual Web el acceso a la información puede convertirse en una tarea difícil y frustrante debido a diversos problemas habituales en la búsqueda de información. La Web Semántica es una Web extendida basada en el significado, en donde cualquier usuario en Internet podrá encontrar respuestas a sus consultas de forma más rápida y sencilla. Si a la Web se le dotará de más semántica, mediante una infraestructura común compartir sería posible procesar y transferir información de forma sencilla. Esta Web extendida emplearía lenguajes universales que resuelven los problemas ocasionados por una Web carente de significado. El objetivo de la Web Semántica es permitir que las máquinas comprendan el significado de los documentos y datos, pero no el significado del habla ó la escritura natural en tiempo real de los humanos (Berners-Lee, et al., 2001). A continuación se citan los principales componentes de la Web Semántica que son los metalenguajes y los estándares de representación XML:

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 34
• XML: Proporciona la sintaxis para documentos estructurados, sin dar ninguna especificación para el significado.
• XML Schema: Lenguaje para definir la estructura de los documentos XML.
• Ontologías: Su función es definir los términos utilizados para describir y representar un área de conocimiento. Son utilizadas por los usuarios, bases de datos y las aplicaciones que necesitan compartir información específica. Las ontologías incluyen definiciones de conceptos básicos en un campo determinado y la relación entre ellos.
• RDF: Modelo de datos que aporta una semántica que puede representarse mediante XML. Proporciona información descriptiva simple sobre los recursos que se encuentran en la Web, ejemplo: catálogos de libros, directorios, fotos, calendarios, etc.
• RDF Schema: Es un vocabulario para describir las propiedades y las clases de los recursos RDF, con una semántica para establecer jerarquías de generalización entre dichas propiedades y clases
• SPARQL: Es lenguaje de consulta sobre RDF, que permite hacer búsquedas sobre los recursos de la Web Semántica utilizando distintas fuentes de datos.
• OWL: es un lenguaje para definir ontologías estructuradas a través de vocabulario para describir propiedades y clases; tales como relaciones entre clases, igualdad, caracterización de propiedades, entre otras.
En resumen la Web Semántica no consiste de mecanismos mágicos para que las computadoras comprendan el significado de las palabras. Es la capacidad para que las computadoras resuelvan problemas bien definidos, usando operaciones bien definidas, que se ejecutan sobre datos bien definidos (Berners-Lee, et al., 2001).
2.3.2 Web Semántica Geoespacial (Egenhofer, 2002)
La información geoespacial (información geográfica o espacial) se refiere a los datos espaciales georeferenciados requeridos para un cierto fin. Estos geodatos poseen una posición implícita (un lugar geográfico) o explícita (basado en un sistema de coordenadas). Se estima que el 80% de los datos corporativos existentes en todo el mundo poseen esta componente geográfica.

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 35
Dentro de las Ciencias de Información Geoespacial, la semántica de la información geoespacial ha ganado una gran relevancia. Debido a que la enorme variedad de codificaciones de la semántica geoespacial hace que sea un reto procesar peticiones para información Geoespacial. Los trabajos realizados en interoperabilidad para Sistemas de Información Geográfica y en el Open GIS Consortium se dirigen a tópicos básicos (Open Geospatial Consortium, 2006). En relación, el lenguaje GML proporciona un enfoque sintáctico para codificar información geoespacial. Mientras el enfoque de la Web Semántica proporciona un marco de trabajo genérico para describir ontologías y capturar la semántica; sin embargo, este marco de trabajo no relaciona explícitamente algunos de las propiedades geoespaciales más básicas (requerimientos de los usuarios web), como las entidades y relaciones que son las más útiles en tareas específicas de procesamiento de información. La carencia de métodos apropiados para recuperación y procesamiento de información geoespacial muestra la forma en que actualmente funcionan grandes recursos de información, por ejemplo, es difícil que un usuario pueda encontrar un conjunto de datos relaciona a una tarea específica. La Web Semántica Geoespacial será un importante avance en el uso de la información espacial. Con la incorporación de la semántica geoespacial en la Web, la recuperación de información geoespacial será precisa al nivel en que los resultados sean inmediatamente útiles. Los motores de búsqueda actuales únicamente examinan el contenido web para palabras clave relevantes pero no procesan significados. Para capturar el significado de la información, consideramos cuatro representaciones de semántica geoespacial para la Web:
• Lenguaje natural (uso de lenguaje de marcas mínimo (XML)).
• Metadatos simples (etiquetas para describir el acceso de documentos).
• Modelos de Datos que doten a documentos u otros recursos Web una estructura conceptual identificable (la importancia de esta estructura conceptual radica en que se construye con base en entidades, relaciones y atributos).

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 36
• Lógica semántica que proporciona correspondencia entre términos y entidades del mundo real, la cual permite un razonamiento automático. La lógica semántica es soportada por interfaces, documentos y sistemas de búsqueda.
En estas representaciones de la semántica geoespacial en la Web, las personas y las maquinas necesitan interactuar cooperativamente. La semántica en la Web y las tareas basadas en la naturaleza de datos espaciales, están convergiendo. Las consultas geoespaciales deben involucrar diferentes elementos, los cuales proveerán mucho más significado a una consulta. En este trabajo se proponen tres elementos semánticos, donde dos términos son relacionados por un comparador geoespacial: “<término geoespacial>”, “<comparador geoespacial >“, “<término geoespacial>“, por lo tanto un consulta puede ser planteada con base en esta tripleta es: <término geoespacial> = “hoteles de cinco estrellas”, <comparador geoespacial > = “en”, <término geoespacial> = “Acapulco, México”. La semántica de los comparadores espaciales está relacionada en ontologías geoespaciales, y los términos geoespaciales se pueden referir a cualquier clase geoespacial (hoteles, restaurantes, etc.) o el nombre de un lugar geográfico (“Acapulco”). El problema central en GIS es desarrollar métodos que describan la semántica de clases geoespaciales utilizadas en diferentes temas de carácter geoespacial (e.g. “hidrología”, “turismo”, etc) y los nombres de elementos relacionados al dominio geoespacial. Las fuentes para obtener estos elementos, pueden provenir desde diferentes ontologías. Por ejemplo, pueden provenir de dos ontologías geoespaciales: una ontología característica que capture las propiedades de definición de clases, y una ontología de topónimos como la que proporciona Geonames.org, inclusive puede utilizarse un diccionario geográfico. El problema anterior de alguna manera involucra diferentes elementos, que están contenidos en dos ontologías distintas, pero que se complementan para plantear una solución. En este sentido, la Alineación de Ontologías Geoespaciales, es una herramienta importante para encontrar estas relaciones de una manera computacional y no manual. La alineación es relevante porque puede integrar información geográfica (como se muestra en OntoMashup) en la emergente Web Semántica Geoespacial.

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 37
2.3.3 Turismo electrónico
Como ya se mencionó OntoMashup es nuestra aplicación de la alineación de ontologías en el dominio geoespacial, sin embargo, también pertenece al área de turismo electrónico. Por tanto, es necesario dedicar un apartado especial sobre dicha área, en el que se destaque su potencial y las relaciones con otros tópicos como ontologías y la Web Semántica Geoespacial. Actualmente, realizar un viaje involucra múltiples necesidades como hospedaje, alimentación, transporte, etc. Debido a la diversidad de opciones para satisfacer estas necesidades, un turista necesita tener acceso a diferentes fuentes de información que proporcionen diversas opciones para elaborar un plan de viaje de acuerdo con sus requerimientos. Por lo tanto, es importante definir mecanismos eficientes para proveer de información útil a turistas potenciales. El turismo es una industria altamente competitiva internacionalmente. Según la Organización Mundial del Turismo, las llegadas de turistas a diferentes puntos del planeta aumentarán en un 200% para el año 2020 (WTO, 2006). Las tecnologías Web son muy importantes para la difusión de servicios turísticos, ya que han facilitado el desarrollo de portales turísticos, por ejemplo, para reservar hospedaje, adquirir servicios de transporte, contratación de servicios adicionales, etc. Esto ha motivado el crecimiento de áreas de estudio como el Turismo Electrónico (también nombrado e-Tourism) que consiste en aplicar las tecnologías de información en la industria turística (Sheldon, 1998) y (Cardoso, 2006). En Turismo Electrónico, existe la necesidad de crear sistemas que combinen en tiempo real, diferentes fuentes de información para realizar planeación de viajes, de tal manera que sean capaces de resolver peticiones de consumidores o de agentes de viajes como un componente integral. Un ejemplo es el portal Web Kayak.com (Kayak, 2008), donde se integra información de diversos recursos turísticos como: hoteles, restaurantes, transporte, sitios de recreación, etc. En este aspecto, los Mashups consisten en aplicaciones Web que combinan el contenido de más de una fuente de datos en un conjunto integrado (Yee, 2005), Los Mashups son parte de la nueva Web 2.0 que permita la integración de información entre fuentes de datos heterogéneas, pero de forma manual y con un enfoque léxico-sintáctico. El contenido usado en los Mashups proviene desde una interface de programación. Actualmente, muchos

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 38
usuarios están creando Mashups a partir de mezclar los servicios de Google maps, Amazon, YouTube, Yahoo!, eBay, entre otros (programmableweb, 2008). Para diseñar este tipo de sistemas integrales es posible utilizar tecnologías como servicios web, ontologías, e-Bussiness, entre otras (Cardoso, 2006). En este contexto los Mashups pueden ser ampliamente aplicados.
2.3.4 Turismo electrónico en el dominio geoespacial
Una componente necesaria en el turismo electrónico es la ubicación geográfica, que por medio de coordenadas geográficas (latitud-longitud) es posible localizar hoteles, restaurantes, zonas arqueológicas, etc. Esto facilitaría al usuario final su arribo a un determinado sitio al realizar un viaje. La Web ha permitido el acceso a los servicios que resuelven tareas de carácter geográfico (Tsou, et al., 2003), como el servicio de localización geográfica que brinda Geonames.org (Geonames, 2006) y el servicio de obtención de mapas de Google maps. La actividad turística es diversa y compleja. De ahí la dificultad de delimitar su ámbito especifico. Por eso son necesarias alternativas como las ontologías, que permiten diseñar un modelo de datos conceptual con una rica descripción semántica de la información turística. La información turística-geográfica, puede ser almacenada y recuperada desde una ontología turística, que incorpore conceptos esenciales que representan el dominio turístico y geográfico en una cierta área geográfica. Una ontología puede describir el significado de diversos servicios turísticos, lo cual permitiría explotar ampliamente esta información (Cardoso, 2006). Sin embargo, en Turismo Electrónico también existe el problema de la interoperación entre sistemas de información, el propósito es permitir el intercambio de información entre diferentes organizaciones de turismo. Al respecto la European Commission (Programme, 2006) ha iniciado varios proyectos en el campo de tecnología de la web semántica aplicada en la industria turística, a fin de alcanzar de soluciones para la interoperabilidad semántica. Un ejemplo es el proyecto Harmonise (Missikoff, 2002), el cual propone combinar diferentes tecnologías como ontologías, procesos de mediación, procesos de anotación semántica (descripciones basadas en etiquetas) de fuentes de datos y reconciliación semántica (solución de conflictos semánticos). La idea de Harmonise es permitir la

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 39
cooperación entre organizaciones turísticas, sin cambiar su formato de datos propio e intercambiando información. La Web Semántica en el ámbito del e-Tourism, será más real al considerar la descripción semántica en función de la naturaleza de recursos turísticos y la descripción de la información turística (Hepp, et al., 2006); a lo cual los avances en Web Semántica Geoespacial pueden fortalecer la idea de una Web especializada y estructurada conceptualmente. Sin embargo, ¿cómo se relacionan el Turismo Electrónico con la Web Semántica Geoespacial? Cuando al recuperar información turística, cuando es necesario emplear conceptos que describan la ubicación geográfica de recursos turísticos. También estas áreas se relacionan al emplear ontologías turísticas que permitan el uso de comparadores espaciales para relacionar elementos turísticos y geoespaciales en consultas como “hoteles en Acapulco”, donde la semántica del comparador “en” involucra un lugar geográfico determinado. En este sentido OntoMashup acepta consultas geoespaciales e involucra ontologías turísticas, alineación, acceso a servicios de localización geográfica y mapas, por tanto lo consideramos como una aplicación para la Web Semántica Geoespacial, para más detalles ver capítulo 4.
2.3.4.1 Aplicación de ontologías geográficas en sistemas turísticos
Internet ha revolucionado la difusión del turismo, muchas compañías pueden ofrecer información y después la opción para contratar algún producto turístico. Según la “6th EU Framework Programme for Research and Technological Development” (Programme, 2006) en la Unión Europea, se han desarrollado cerca de 30 diferentes tipos de proyectos relacionados al turismo electrónico usando ontologías y tecnologías Web. En esta sección mencionamos algunos de estos proyectos como Harmonise y Hi-Touch. Proyect Harmonise (Missikoff, et al., 2003) es una iniciativa europea cuyo objetivo es construir un sistema basado en una ontología compartida que mejore la cooperación de empresas turísticas europeas. El propósito fue establecer un consorcio internacional Tourism Harmonisation Network (THN) conformado por los principales actores turísticos, expertos y profesionales en tecnologías de la información.

Capítulo 2. Estado del Arte
Alineación de ontologías usando el método Boosting 40
El proyecto Hi-Touch (Euzénat, et al., 2003), tiene como objetivo, incrementar las ventas de agencias de viajes, a través de herramientas de software, que brinden propuestas turísticas con la mejor oferta adaptada a las necesidades del usuario; es decir, software que le permita a un cliente potencial seleccionar rápida y eficientemente un conjunto de productos y servicios que correspondan con sus necesidades. Estas herramientas son construidas con tecnologías como Java, XML, bases de datos ontológicas, tesauros multilenguaje y bases de datos de recursos turísticos. En esta sección, se exponen los argumentos que justifican el planteamiento del caso de aplicación en el dominio geoespacial. El capítulo 4 se aborda este caso de aplicación, el cual se basa en la combinación de características presentes en los proyectos ya mencionados.
2.4 Comentarios finales
El estado del arte concentra tres tópicos: técnicas recientes en alineación de ontologías, algoritmos de aprendizaje automático aplicados en integración de información y recuperación de información, y finalmente una síntesis de la Web Semántica. La combinación de estos tópicos fundamenta la propuesta de solución propuesta en esta tesis. Principalmente, podemos concluir la importancia de las medidas de similitud semántica cómo un componente esencial en los sistemas de alineación de ontologías. El estado del arte demuestra que los procesos de medición semántica son inexcusables, sin embargo, los algoritmos presentados buscan establecer una combinación adecuada de las medidas de similitud, así como criterios que ayuden a definir con certeza el grado de relación entre dos conceptos. En este sentido, con base en la información proporcionada por la OAEI, Boosting no ha sido utilizado como una forma de combinar y sintetizar medidas de similitud. Las medidas de similitud estructural juegan un rol primordial, sin embargo, deben ser complementadas con la medición de similitud lingüística. Implícita o explícitamente los algoritmos de alineación consideran la importancia de cada medida de similitud usada, ya sea de forma numérica (pesos) o usando criterios (reglas). Con base en este argumento, la propuesta de solución también considera esta importancia desde un enfoque más cercano a la interpretación humana. Sin embargo, previamente es necesario abordar el siguiente capítulo, el cual explica los diferentes temas necesarios para comprender la presente tesis.

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 41
CAPÍTULO 3 : MARCO TEÓRICO Recientemente las ontologías se han vuelto cada vez más comunes en la Web, donde proveen la semántica de descripciones en las páginas web. Su múltiple desarrollo ha provocado que existan un gran número de diferentes ontologías que cubren los mismos o complementarios dominios. A fin que dos partes se entiendan una a otra deben usar la misma representación formal, en otras palabras, tener la misma ontología para compartir información. Desafortunadamente, no es fácil hacer que todos acuerden usar una misma ontología para un dominio. La alineación de ontologías posibilita la interoperabilidad en la Web Semántica, al tomar ontologías como entrada y obtener como salida las correspondencias entre las entidades semánticamente relacionadas. Esas correspondencias pueden ser utilizadas para varias tareas: fusión de ontologías, query answering (procesamiento de consultas en diversas fuentes de información), o para navegación en la Web Semántica (Euzenat, et al., 2007) . El propósito de esta sección, es estructurar y relacionar definiciones que sustentan este trabajo, se explican algunos conceptos de forma breve y concreta a fin de utilizarlos en secciones posteriores.
3.1 Conceptos generales
Información: Es un conjunto organizado de datos, que constituyen un mensaje sobre un determinado ente o fenómeno. Los datos se perciben mediante los sentidos, éstos los integran y generan la información necesaria para producir el conocimiento, que es el que finalmente permite tomar decisiones. El dato no tiene valor semántico en sí mismo, hasta que se procesa y se puede utilizar para realizar cálculos o toma de decisiones (Floridi, 2005). Básicamente podemos definir al conocimiento como el conjunto organizado de datos e información, destinados a resolver un determinado problema. Sin embargo, el conocimiento radica en un conjunto sobre hechos, verdades o de información almacenada a través de la experiencia o del aprendizaje (experiencia de los sentidos), o a través de introspección (a priori). Semántica: El término semántica, se refiere a los aspectos del significado (el contenido mental asignado a un objeto) o la interpretación de un determinado código simbólico, lenguaje o representación formal (Liddell, et al., 1996). En principio, cualquier medio de expresión (código, lenguas, etc.) admite una correspondencia entre: palabras o expresiones

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 42
simbólicas y situaciones o entes (ya sean físicos o abstractos), esta correspondencia semántica permite describir a dicho medio de expresión. El propósito de la semántica, es precisamente entender un concepto en su sentido. En este aspecto, entender es saber qué se quiere decir. Actualmente la definición de los sentidos de las palabras existe en forma de diccionarios. Es importante mencionar que las ontologías definen un concepto base su dominio, la semántica radica en las relaciones entre los conceptos. De acuerdo con (Miller, et al., 1993), las relaciones semánticas más importantes son: hiperónimia, hiponimia, meronimia, holonimia, sinonimia y antonimia. En resumen podemos ubicar las relaciones semánticas de la siguiente forma:
• Meronimia: A es parte de B, i.e. B tiene a A como parte de sí mismo.
• Holonimia : B es parte de A, i.e. A tiene B como parte de sí mismo.
• Hiponimia (o troponomia): A es subordinado de B; A es un tipo de B.
• Hipernomia: A es superior de B.
• Sinonimia : A denota lo mismo que B.
• Antinomia : A denota lo opuesto a B.
3.2 Ontologías
Thomas Gruber (Gruber, 1993) define a las ontologías, como “una especificación explicita de una conceptualización”. Una conceptualización es una abstracción, una vista simplificada del mundo que deseamos representar para un cierto propósito. Una conceptualización según Gruber, puede estar definida como una estructura <D, R>, donde D es un dominio y R es un conjunto de relaciones relevantes en D.
También, una conceptualización para D puede ser definida como la tripleta ordenada C = <D, W, ℜ >. Donde D es el dominio, W es un conjunto de estados de las relaciones del dominio (o mundos posibles), y ℜ es el conjunto de relaciones conceptuales en el espacio de dominio <D, W>. En otras palabras, una conceptualización puede ser un sistema de relaciones conceptuales definidas sobre un espacio de dominio.
Por otro lado Guarino, argumenta que una ontología es una “teoría lógica que explica el significado previsto de un vocabulario formal”. Guarino contribuye al agregar el

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 43
compromiso ontológico para una conceptualización en particular (Guarino, 1995). Los compromisos ontológicos son acuerdos para utilizar un vocabulario compartido en forma coherente y consistente. Borst (W.N. Borst, 1997) coincide con Gruber, pero modifica su definición y establece que las ontologías son definidas como “una especificación formal de una conceptualización compartida”. En este sentido, Cocchiarella establece el término “Ontología Formal” (Cocchiarella, 1991) como el desarrollo sistemático, formal y axiomático de la lógica de todas las formas y modelos del ser. Una “Ontología Formal” puede ser diseñada para ser independiente del estado del mundo. La comunidad ontológica distingue ontologías que son principalmente taxonomías de ontologías que modelan el dominio de una manera más profunda y proporcionan más restricciones en la semántica del dominio. Por lo tanto, existen ontologías ligeras que incluyen conceptos, taxonomía de conceptos, relaciones entre conceptos y propiedades. Por otro lado, las ontologías pesadas agregan axiomas y restricciones a las ontologías ligeras (Corcho, et al., 2003). Para esta tesis, utilizamos la definición de Gruber. Los elementos de las ontologías que se considerarán son: clases individuales (conceptos) y jerarquías de clases (Noy, et al., 2005), y propiedades de conceptos.
3.2.1 Clasificación de ontologías
Las ontologías pueden ser clasificadas de acuerdo con su generalidad y su expresividad. Como generalidad entendemos a la amplitud de la ontología, algunas ontologías intentan capturar todos los términos en lenguaje natural, mientras otras son muy específicas en ciertos dominios o términos. La expresividad relaciona el grado de explicación del conocimiento que es capturado en la ontología. Cuando más relaciones y más restricciones son capturadas en la ontología, la ontología comienza a ser más expresiva, desde capturar el conocimiento del dominio a un nivel más detallado. De acuerdo con (Guarino, 1998), las ontologías se clasifican de la siguiente forma (ver Figura 3.1):

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 44
• Ontología de alto nivel (Top-level Ontology). Aborda conceptos generales (e.g. entidad, objeto, idea, artefacto, etc.) los cuales son independientes de un dominio. Ejemplo Ontología CyC y WordNet.
• Ontología de Dominio (Domain ontology). Enfocadas a cubrir alguna terminología sobre un dominio genérico como matemáticas, medicina. Ejemplo, la ontología de Ontolingua para modelado matemático.
• Ontología de Tarea (Task ontology). Se enfoca en describir el vocabulario sobre una tarea en específico, por ejemplo comercialización, reparación, etc.
• Ontología de Aplicación (Application ontology). ste tipo de ontología describe conceptos de un dominio y de tareas particulares, comúnmente especializaciones de ambos. En nuestro caso un ejemplo de este tipo es una ontología sobre turismo en una zona geográfica específica.
Figura 3.1. Clasificación de ontologías según sus niveles de dependencia
Las ontologías tienen el potencial de permitir una auténtico intercambio y reutilización de conocimiento entre agentes de software heterogéneos, y entre la computadora y el humano.

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 45
3.2.2 Criterios generales de diseño
Fueron propuestos por Gruber (Gruber, 1995), y son:
• Claridad. La ontología debe comunicar con eficacia el significado de los términos definidos. Cada concepto debe estar definido objetivamente. La definición tiene que ser independiente del contexto.
• Coherencia. Una ontología debe aprobar las inferencias que sean consistentes con las definiciones. Los axiomas deben ser definidos lógicamente consistentes. Si una sentencia inferida por los axiomas contradice una definición o ejemplo entonces la ontología es incoherente.
• Extensibilidad. Una ontología debe tolerar cambios en el vocabulario compartido. Si de definen nuevos términos basados en el vocabulario existente, no debe ser necesario revisar definiciones existentes.
• Minimizar tendencias en la codificación. La conceptualización no debe depender de una codificación, la conceptualización se define a nivel del conocimiento no de una codificación a nivel de símbolo en particular. Las tendencias de codificación deben ser reducidas al mínimo.
• Minimizar el compromiso ontológico. Es deseable que la ontología requiera un mínimo de compromiso ontológico, suficiente para soportar las actividades relacionadas con compartir el conocimiento. El compromiso ontológico puede depender solamente de los términos que sean esenciales para la comunicación de conocimiento.
3.3 Integración de información
La ubicación es cada vez es más importante. La tendencia actual en los Sistemas de Información Geográfica (SIG, Geographic Information System (GIS)) es la integración e intercambio de información. El dato geográfico es una referencia espacial para integrar información geográfica desde diversas fuentes. En este sentido, recientemente los GIS emplean arquitecturas más abiertas, las cuales incrementan las posibilidades de integración. Integrar información típicamente involucra fuentes de datos de diferentes plataformas y con diferentes esquemas de datos. Para determinar las diferencias entre estos esquemas de datos, no solo se necesita crear una simple traducción (por sintaxis) de un esquema a otro, también un mapeo semántico, que vincule las entidades en los distintos esquemas basado en la correspondencia de los significados de estas entidades (Alexiev, et al., 2004).

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 46
Similarmente, para rehusar la información proveniente de las ontologías construidas por expertos en un dominio, también se requiere determinar las correspondencias semánticas entre las mismas. Existen dos paradigmas en la integración de información (Alexiev, et al., 2004): La fusión de modelos de datos en un modelo central y la alineación y mapeo de modelos. En integración de ontologías estos enfoques se conocen como fusión y alineación de ontologías. Esta tesis se centra en el segundo enfoque.
3.3.1 Correspondencia Semántica
Comúnmente match se asocia como un operador que toma dos estructuras de tipo gráfica (e.g. esquemas en XML) y establece correspondencias entre los nodos que corresponden semánticamente entre ambas estructuras. En la literatura sobre integración de esquemas de datos ó Schema Matching (Rahm, et al., 2001), se intenta proporcionar procesos automatizados para encontrar correspondencias semánticas entre dos esquemas de datos. La integración de esquemas de datos, radica en las siguientes ideas:
• Descubrir mapeos por medio del cómputo de las relaciones semánticas (e.g. equivalencia, relación de dependencia).
• Determinar las relaciones semánticas por el análisis de significado (conceptos, no etiquetas) que son codificados en los elementos y las estructuras.
Existen diferentes dificultades para establecer correspondencias en ontologías. La heterogeneidad entre estructuras de datos, como ontologías, se debe al uso de diferentes representaciones o definiciones para representar la misma información (conflictos entre esquemas), o diferentes expresiones, unidades, precisión entran en conflicto en la representación de los mismos datos (conflicto entre datos). Diseñar métodos para establecer estas correspondencias se complican en los siguientes niveles (Worboys, et al., 2004):
• Heterogeneidad sintáctica: Diferencias en el lenguaje usado para la representación de modelos.
• Heterogeneidad estructural: Diferencias en los tipos, y estructura de los elementos. • Heterogeneidad semántica: Donde las mismas entidades del mundo real son
representadas usando diferentes términos o viceversa. • Heterogeneidad en modelos o representación de la información: diferencias en los
modelos subyacentes (bases de datos, ontologías) o su representación (modelo relacional, orientado a objetos, lenguajes de ontologías RDF, OWL).

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 47
3.3.2 Alineación de ontologías
Las ontologías en sí mismas pueden ser heterogéneas, por tanto es necesario procesos capaces que permitan la interoperabilidad entre ellas. Sin embargo, a pesar de la emergente web semántica y los estándares semánticos, las ontologías interdisciplinarias pueden ser creadas desde diferentes ontologías de dominio específico. Nuevas ontologías podrían ser construidas a partir de la mezcla de bases de datos heterogéneas y otras fuentes de información. Por tanto, la semántica en estas ontologías tiene que ser conciliada. La interoperabilidad semántica puede ser tratada como una reconciliación ontológica, es decir: encontrando relaciones entre entidades que pertenecen a diferentes ontologías. A este proceso se le conoce como alineación de ontologías, los resultados pueden ser usados para visualizar correspondencias, transformar una fuente en otra, para crear un conjunto de relaciones o reglas entre las ontologías, o generar consultas para extraer información hacia las dos ontologías (Euzenat, et al., 2007). El problema de alineación puede ser descrito en una sentencia, dado dos ontologías que describen un conjunto de entidades discretas (que pueden ser clases, propiedades, reglas predicados, etc.), encontrar las relaciones existentes entre esas entidades.
3.3.3 Aplicaciones de la alineación
La alineación de ontologías, tiene diversas aplicaciones en áreas como la Web Semántica, integración de información, interoperabilidad semántica, bases datos, entre otras disciplinas (Euzenat, et al., 2004b): Semántica emergente (Emergent Semantics): En este enfoque la interoperabilidad semántica es vista como un fenómeno emergente construido incrementalmente, y que su resolución depende de los acuerdos en interpretaciones comunes dentro de un dominio específico. Por tanto, para la resolución de conflictos semánticos se plantean el uso de agentes, la diferencia en este enfoque es obtener tal interoperabilidad en una forma más descentralizada y escalable, sin usar necesariamente ontologías. Sin embargo, se requieren procedimientos para resolver conflictos semánticos entre esquemas de datos y establecer acuerdos.

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 48
Integración de datos basada en ontologías (Ontology-driven data integration): En este caso de estudio, la integración de la información radica en los datos de múltiples bases de datos relacionadas, las cuales contienen los datos a integrar, en donde para ello una ontología será poblada con instancias extraídas desde las bases. Un mapeo entre un esquema de bases datos y una ontología puede ser definido como un conjunto básico de expresiones mapeadas, o elementos mapeados entre componentes en ambos modelos. Correspondencias semánticas entre catálogos electrónicos (Catalog matching): Muchas aplicaciones de comercio electrónico están basadas en la publicación de catálogos electrónicos que describen la organización de productos. Cuando existen diferentes catálogos relacionados a los mismos productos, es difícil crear aplicaciones de comercio electrónico que permitan la interoperación entre estas estructuras, por tanto para que distintas y nuevas aplicaciones de comercio electrónico, puedan compartir información necesitan establecer acuerdos entre catálogos de productos, como requiere e1 comercio electrónico entre empresas (B2B). Al respecto la UNSPSC (“United Nations Standard Products and Services Code”) ha realizado esfuerzos para integrar dichos catálogos a través del uso de estándares, sin embargo, cuando una compañía quiere usar alguno de estos estándares, tendría que migrar sus catálogos actuales lo que implicaría un gran esfuerzo y costo. | La Figura 3.2 muestra algunas correspondencias entre los catálogos de productos de eBay y Amazon, por ejemplo es posible agregar libros desde eBay al catálogo de Amazon y viceversa. Las correspondencias semánticas también permitirían a los sistemas de comercio electrónico, buscar simultáneamente productos (e.g. libros ofertados en eBay y Amazon) a fin de comparar su oferta y demanda desde múltiples sitios de comercio electrónico.

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 49
Figura 3.2. Integración de catálogos electrónicos
Transferencia de información personalizada (Personnal information delivery): Hasta el momento, la radio por Internet no es realmente tan diferente respecto a la radio convencional en relación con la capacidad limitada de influir en el contenido del programa de radio. Actualmente, la idea inteligente de la radio por Internet se ubica en explotar las tecnologías de la Web Semántica, con el fin de poder relacionar los gustos e intereses de los usuarios con las descripciones de diferentes estaciones de radio, y seleccionar automáticamente la estación más adecuada de acuerdo al perfil del usuario. Sin embargo, a pesar de problemas más técnicos, como los diferentes tipos de formatos de audio, hay algunos problemas conceptuales que deben abordarse, los cuales se originan en la necesidad de comparar los intereses de los usuarios con los metadatos que describen las estaciones de radio. Además la información acerca de artistas y canciones es normalmente asignada a diferentes géneros musicales. El problema específico de un género radica en el hecho de que no hay un acuerdo sobre la categorización de los artistas, e incluso en el género de las canciones, ya que esta clasificación puede ser diferente de persona a persona. Por otro lado, los enfoques lingüísticos para comparar categorías están condenados al fracaso debido a la naturaleza artificial de los nombres de género que no tienen una

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 50
conexión con la semántica en lenguaje natural (Euzenat, et al., 2004b). Es claro que un proceso de Alineación, podría figurar como una forma de conciliar y detectar conflictos semánticos entre las clasificaciones de canciones, como en el proceso de relacionar el perfil del usuario con la descripción de las estaciones de radio. La Figura 3.3 ilustra un esquema la búsqueda de estaciones de radio por internet. Los usuarios tienen diferentes gustos que definen un perfil diferente entre sí. Este perfil puede ser descrito semánticamente, y utilizando un buscador para encontrar las estaciones de radio que coincidan con el perfil del usuario. Si el perfil del usuario se describe semánticamente, es posible proyectar la perspectiva del usuario hacia sus necesidades en el mundo real, y permitir que los algoritmos de búsqueda personalicen los resultados obtenidos. Un perfil conceptual proveerá extensibilidad, flexibilidad, interoperabilidad y reusabilidad de la información en un dominio dado.
Figura 3.3. Esquema de un buscador inteligente de estaciones de radio web
Integración de GeoServicios Web Semánticos (Web service integration): Se refiere a la capacidad de buscar servicios web a través de consultas que son optimizadas al agregarles una descripción semántica. Usando esta tipo de consulta se buscan coincidencias entre la descripción semántica y los servicios web disponibles (descripción contenida en una ontología). Ambas descripciones pueden usar diferentes terminologías y modelos conceptuales, por ejemplo al usar en una un concepto que en otra es utilizado como propiedad. Por tanto las ontologías deben ser conciliadas.

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 51
El lenguaje OWL (Ontology Web Language) para Servicios Web (Semantic Markup for Web Services) (W3C, 2004) se trata de un "conjunto básico de instrucciones de lenguaje de marcas para describir las propiedades y capacidades de Servicios Web en una forma no ambigua e interpretable por ordenador". En otras características, OWL-S ofrece descubrimiento dinámico de servicios basado en consultas descritas ontológicamente. Esta característica es una oportunidad de aplicación para la alineación que permitiría determinar si existe correspondencia entre la consulta y el servicio. Actualmente, existen servicios web semánticos orientados al dominio Geoespacial para almacenar mapas como Geonames (Geonames-ontology, 2006). Integración de Ontologías Geográficas para la conservación de humedales: La alineación de ontologías es importante para integrar información con el objetivo de proteger áreas naturales. Distintas organizaciones monitorean y registran zonas de humedales, estas organizaciones están interesadas en compartir información. Sin embargo, la falta de estándares de clasificación de humedales ha impedido implementar y monitorear estrategias de conservación entre organizaciones internacionales y regionales. Los Estados Unidos de Norteamérica utilizan el sistema de clasificación de humedales “Cowardin Wetland Classification System”, mientras que la Unión Europea utiliza la “International Ramsar Convention Definition” y en Sudáfrica se usa la “National Wetland Classification Inventory”. En muchas clasificaciones se tiene que considerar las variaciones de cada región en clima, geología, suelo, fauna, y las diferencias en tipos de vegetación y fauna entre las regiones. En conclusión, es extremadamente difícil tener un sistema de clasificación estandarizado entre naciones y también entre regiones de un país con amplias aéreas geográficas. Es por eso que la alineación puede establecer elementos comunes entre clasificaciones y explotar la información que contienen.
3.4 Aprendizaje automático
El aprendizaje automático es la rama de la Inteligencia Artificial cuyo objetivo es desarrollar técnicas que permitan a las computadoras aprender de forma más concreta, es decir construyendo programas que mejoren su desempeño automáticamente con la experiencia. Estos programas son capaces de generalizar comportamientos a partir de una información no estructurada suministrada en forma de ejemplos (Nilsson, 1996).

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 52
Podríamos decir que los programas aprenden si los cambios en su estructura o sus datos basados en las entradas o en respuesta a información externa de tal manera que su desempeño mejore. Aprendizaje automático es también una forma de aplicación de las estadísticas y/o probabilidad, una forma de optimización, teoría de control o un proceso de clasificación (Mitchell, 1997). ¿Por qué usar aprendizaje automático para resolver problemas?, de forma general se presentan los siguientes puntos:
• En ocasiones, las tareas no pueden ser bien definidas, excepto usando ejemplos, es decir que pudiéramos especificar las entradas y salidas pero no una relación concisa entre las entradas y las salidas deseadas, puesto que sería deseado que las máquinas sean capaces de ajustar su estructura interna para encontrar esta relación y producir salidas correctas para un gran número de muestras de entrada, y por tanto, limitar adecuadamente la entrada/salida de las funciones para aproximar su relación implícita en los ejemplos.
• El aprendizaje automático, es un método que puede encontrar importantes relaciones y correlaciones ocultas entre cantidades grandes de datos (data mining).
• Los sistemas en ocasiones no trabajan tan bien como se desea en ambientes en los que son usados, de hecho, ciertas características del ambiente no pueden ser descubiertas en tiempo de diseño. “Machine learning” puede ser usado para mejorar el diseño de los sistemas existentes.
• El ambiente cambia con el tiempo. Las máquinas pueden adaptarse en tiempo real, reduciendo la necesidad constante de rediseño.
• La cantidad de conocimiento disponible sobre ciertas tareas, puede ser muy amplia. Las máquinas que aprenden este conocimiento gradualmente podrían capturar más de lo que las personas pudieran retener.
Algunas de las principales disciplinas de aprendizaje automático (Mitchell, 1997), son:
• Estadística (statistics): Un problema amplio en esta disciplina es mejorar el uso de ejemplos extraídos desde distribuciones de probabilidad desconocida para ayudar a decidir de cual distribución puede extraerse algún ejemplo nuevo y correcto. También los problemas relacionados con la decisión y estimación de reglas que dependan de un corpus de muestras de ejemplos (samples) extraídos desde el contexto del problema, para más detalles ver (Anderson, 1958).

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 53
• Modelos cerebrales (brain models): Elementos no lineales con entradas con pesos han sido sugeridas como modelos simples de neuronas biológicas. Los Brain Models están interesados en como aproximarse al aprendizaje de fenómenos en el cerebro humano.
• Teoría de control adaptable (adaptive control theory): En esta rama se estudia el problema de cómo controlar un proceso donde se desconocen ciertos parámetros que deben ser estimados durante su operación en tiempo real. Frecuentemente los parámetros cambian durante la operación, por tanto los procesos deben considerar esos cambios. Por ejemplo, aspectos de control de robots basado en la percepción de sensores.
• Modelos mentales (psychological models): Esta área está relacionada con árboles de decisión (decision tree), y redes semánticas (semantic networks). Recientemente trabajos de este tipo han sido influenciados por actividades en inteligencia artificial.
• Modelos evolutivos (evolutionary models): La diferencia entre evolución y aprendizaje puede resultar confuso en sistemas de cómputo. Las técnicas que modelan ciertos aspectos de evolución biológica han sido propuestas como métodos de aprendizaje para mejorar el desempeño de programas de computadora. Tópicos como algoritmos genéticos y programación genética son algunas de las técnicas más prominentes de modelos de evolución.
3.4.1 Estructuras computacionales para aprendizaje automático
Se debe tomar en cuenta que en aprendizaje automático, lo que captará el aprendizaje es una estructura computacional de algún tipo, por ejemplo alguna de las siguientes:
• Funciones.
• Programación lógica y conjunto de reglas.
• Máquinas de estado finito.
• Gramáticas.
• Sistemas de solución a problemas. (Cuando un sistema de inteligencia artificial, no sabe cómo proceder a partir de un estado dado llegar a una meta deseada (problem-solving systems)).
En este trabajo se usarán funciones principalmente para medir la similitud entre los elementos de las ontologías. Es la estructura computacional que ocuparemos como entrada para el algoritmo AdaBoost. Por eso, es necesario describir los conceptos usados en aprendizaje automático.

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 54
Apoyándonos en la Figura 3.4, se establece que la principal tarea de un algoritmo de aprendizaje es hacer una predicción sobre una función f(x), a través de combinar hipótesis débiles (posibles soluciones correctas a problema), la función que será adquirida durante el aprendizaje es denotada como h. Cómo se muestra en la Figura 3.4, h es implementada por un mecanismo que tiene X como entrada y h(X) como salida, por tanto, f(x) se define en la siguiente expresión:
∑ , es la importancia de El coeficiente , normalmente depende del grado de error , la definición de depende del algoritmo de aprendizaje seleccionado, para el caso de Boosting se define en la sección 3.4.6. Ambos f y h son funciones para un vector evaluado de entrada X={x1, x2, x3... xn, } con N componentes. La función f puede ser un clasificador final de alta precisión, obtenido desde la combinación de varias hipótesis débiles.
Figura 3.4. Esquema general de aprendizaje automático (adaptado desde (Mitchell, 1997))
A priori se asume que la función hipotética h, es seleccionada desde una clase o conjunto de funciones H proporcionada por un algoritmo de aprendizaje previamente definido (en esta tesis es el algoritmo K-Vecinos, ver Capítulo 4). Es prioritario mencionar que h (una hipótesis) también es seleccionada con base en un conjunto de entrenamiento S (o una muestra (sampling)). Muchos detalles importantes dependerán de los supuestos acerca de todas las entidades ya mencionadas en esta sección (Mitchell, 1997).

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 55
3.4.2 Tipos de aprendizaje
Existen principalmente dos formas en que una función puede ser entrenada. La primera es usando aprendizaje supervisado, sabemos (en la mayoría de las veces) que los valores de f para m muestras del conjunto de entrenamiento S son conocidos. Asumimos que si podemos encontrar una hipótesis h, que coincide estrechamente con f para los miembros de S, luego esta hipótesis será una buena conjetura para f, especialmente si S es grande. En aprendizaje no supervisado, se simplifica a un conjunto de prueba de vectores sin valores de funciones para ellos. El problema en este caso es típicamente particionar el conjunto de prueba en subconjuntos S1… Sn, en alguna manera apropiada.
3.4.3 Elementos de entrada
La terminología en aprendizaje puede tener diferentes sinónimos para los términos de entrada y sus valores, así como las salidas. A continuación definimos los términos que se pueden emplear:
• El vector de entrada puede ser nombrado como: vector de entrada, vector de patrón, vector característico, instancia, muestra y ejemplo, los últimos dos términos son usados por el método Boosting.
• Los componentes xi del vector de entrada, son: características, atributos, variables de entrada, y componentes.
• Los valores de los componentes pueden ser de tres tipos: números reales, valores discretos, o valores nominales.
Por ejemplo un estudiante podría ser representado por los valores de los atributos (nombre, grado, tesis, sexo, asesor), un estudiante en particular se representa con el vector (Jonathan, ‘segundo semestre’, ‘recuperación de geoinformación’, ‘masculino’, ‘Marco Moreno’). Adicionalmente, los valores nominales pueden ser ordenados {pequeño, mediano, largo} o desordenados como el ejemplo dado. Por supuesto, cualquier mezcla puede ser posible. En todos los casos es posible representar la información de entrada de manera desordenada al listar los nombres de los atributos junto a sus valores. Un ejemplo de una representación atributo-valor, podría ser: (nombre: ‘Jonathan’, grado: ‘2do. Semestre’, tesis: ‘recuperación de geoinformación’, sexo: ‘masculino’, asesor: ‘Marco Moreno’). En todos los casos es posible representar la salida en forma desordenada, listando los nombres de los atributos junto sus valores.

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 56
3.4.4 Elementos de salida
La salida puede ser un número real en cuyo caso representa a la función h, es nombrada una función de estimación (function estimator), y la salida es llamada un valor de salida o estimación. Alternativamente, la salida puede ser un valor nominal, en cuyo caso el proceso representa h que es variablemente nombrado un clasificador, un reconocedor, u otro proceso que pueda categorizar, y la salida en si misma pueda ser una etiqueta, clase, una categoría o una decisión. Los clasificadores han sido utilizados en la solución a problemas de reconocimiento (e.g. reconocimiento óptico de textos impresos, al mapear un texto a la representación de caracteres en formato digital). Las salidas tipo vector evaluado también son posibles con componentes siendo números reales o valores nominales. Un caso especial importante es el uso de valores booleanos. En cuyo caso, un patrón de entrenamiento tiene el valor 1 que es nombrado una instancia positiva, cuando su valor es 0 se nombra instancia negativa. Cuando la entrada es booleana, el clasificador implementa una función booleana. En aprendizaje automático, una función booleana es en ocasiones llamada aprendizaje conceptual y la función es llamada concepto. En ocasiones los vectores del conjunto de entrenamiento son corrompidos por ruido. Existen dos tipos de ruido, ruido de clase que aleatoriamente altera el valor de la función. El ruido de atributos que aleatoriamente altera los valores de los componentes del vector de entrada. En cualquier caso, podría ser inapropiado insistir que la función hipotética agregue precisión con los valores de los ejemplos que pertenecen al conjunto de entrenamiento.
3.4.5 Combinación de clasificadores: métodos de ensamble
La combinación de clasificadores es ciertamente similar a buscar la solución a un problema. Comúnmente buscamos la opinión de varios expertos en las áreas que involucra el problema. Recopilada la información podemos analizar, valorar y ordenar las ideas de cada experto. Finalmente podemos construir una solución que combine cada idea (Morales-Manzanares, 2008). En los métodos de aprendizaje automático, un clasificador puede ser el equivalente a un “experto”, es posible suponer que se pueden producir predicciones (o estimaciones) más

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 57
confiables si se combinan las predicciones de varios clasificadores. Con este enfoque integral, podemos decir, que dado un conjunto de elementos, cada elemento puede ser clasificado con más precisión si se integran varios clasificadores. En general dado un vector de entrada, puede decirse que los clasificadores son mejores:
• Si los clasificadores difieren entre sí. Las características de cada clasificador son distintas.
• Si sus tazas de error es menor al 50%. El número de veces que se clasifica bien sea mayor a 50%.
• Si los errores son independientes entre sí.
Actualmente existen técnicas para construir conjuntos de clasificadores y combinarlos para clasificar nuevos ejemplos. Algunas técnicas de clasificación por votación, existen algoritmos que cambian la distribución de los ejemplos (pesos asignados a los ejemplos) de entrenamiento, como Boosting, AdaBoost y demás algoritmos de su clase (Bishop, 2007). También existen técnicas que no cambian la distribución de los ejemplos y otras combinan diferentes clasificadores, como las técnicas de Bagging (algoritmo para mejorar el aprendizaje automático en clasificación) y Stacking (algoritmo de aprendizaje automático para ensamble de clasificadores). Para combinar clasificadores, la idea básica es correr algoritmos de aprendizaje varias veces y combinar los resultados de alguna forma para obtener un mejor resultado final. El proceso de combinación se puede hacer de diferentes formas, la más simple es usar un voto mayoritario (e.g. Bagging), realizar un voto pesado como lo realiza Boosting, o usar un nuevo clasificador que decida como combinar esos resultados (e.g., Stacking). En este trabajo, se usa Boosting para integrar aspectos de similitud léxica y semántica, también la idea es combinar diferentes medidas de similitud para optimizar el proceso de búsqueda de correspondencias en la alineación de ontologías. Además como el estado del arte indica, Boosting ha mostrado un buen desempeño en la solución de diferentes problemas.

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 58
3.4.6 Boosting
Boosting es un poderoso método de Machine Learning para construir clasificadores. La principal idea es combinar distintas hipótesis débiles (reglas o criterios de clasificación) en un clasificador de alta precisión. Dentro de sus funciones, está la de ponderar de forma dinámica reglas ó criterios de clasificación. Boosting es ideal para diseñar clasificadores precisos (Freund, et al., 1999). En (Boosting.org, 2002) se pueden consultar aplicaciones y software relacionado con este método. Boosting es una técnica general para mejorar la precisión de los algoritmos de aprendizaje automático (machine learning algorithms). En Boosting, la idea básica es construir repetidamente “clasificadores débiles” (weak learners) mediante la reponderación iterativa de los datos de entrenamiento y formar un ensamble o integración de los clasificadores débiles, de tal manera que el desempeño del ensamble sea mejorado. Freund y Schapire propusieron el primer algoritmo Boosting llamado AdaBoost (Adaptive Boosting), que está diseñado para resolver problemas de clasificación binaria en donde solo existen dos clases. Más tarde, Schapire y Singer (Schapire, 1999) desarrollaron una versión generalizada de AdaBoost, en la cual los clasificadores débiles pueden proporcionar resultados más precisos en clasificaciones no binarias o problemas de multiclasificación. AdaBoost es un algoritmo que ingeniosamente construye un modelo linear al minimizar una “función de pérdida exponencial” con respecto a los datos de entrenamiento. Existen diversos algoritmos Boosting, como AdaBoost que unifica las hipótesis débiles, adaptándose a los rangos de error de clasificación de cada una. Una variante de esto algoritmo es AdaBoost.MH, esta versión se utiliza para procesos de multiclasificación. En este algoritmo un conjunto de problemas binarios es creado para cada objeto X y cada posible clase Y. Uno de los principales elementos es un conjunto de distribución de pesos D que representa a los objetos bien o mal clasificados, también el algoritmo determina el parámetro αt que es un valor dinámico de importancia asignado a las hipótesis débiles. Una hipótesis es una función de valores reales : . Donde el signo de h(x,l) es una predicción de Y para x, es decir si en un objeto x es contenido en una clase l. La magnitud de h(x,l) es interpretada como una medida de confiabilidad en la predicción.

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 59
Boosting se basa en las siguientes ideas o principios básicos:
• Es posible tomar un conjunto de hipótesis y crear una buena hipótesis única.
• Las hipótesis simples no son perfectas.
• Uso de un algoritmo para generar diferentes hipótesis débiles en tiempo de ejecución.
• Medición del nivel de importancia de cada mejor hipótesis.
• Combinación de las hipótesis de forma inteligente.
La Tabla 3.1 muestra el algoritmo AdaBoost:
Tabla 3.1. Algoritmo AdaBoost
AdaBoost Entrada:
N: Conjunto de entrenamiento, ejemplos {(x1, y1), . . . , (xN, yN)}, L: Un algoritmo de aprendizaje generador de hipótesis ht(x) T: Número máximo de iteraciones
Inicialización de parámetros: , peso para el ejemplo n (d es una distribución con 1=∑ ) 1/ , para cada n=1,…,N Mientras t=1,…,N
1. Entrenar un algoritmo base de aprendizaje acorde a la distribución de ejemplos y obtener la hipótesis: ht: 1 2. Calcular el peso del error: ∑ I( ) 3. Calcular el peso de la hipótesis:
4. Actualizar la distribución de los ejemplos: es un factor de normalización
Salida:
Hipótesis final ∑

Capítulo 3. Marco Teórico
Alineación de ontologías usando el método Boosting 60
Este algoritmo emplea diferentes elementos para su desarrollo:
• Un conjunto de datos de entrenamiento {(x1,y1),(xi,yi)…( xn,yn)} (etiquetados con su respectiva clasificación), donde cada x es un ejemplo de dicho conjunto con una etiqueta y.
• Distribución (d1,..,dN ) para cada elemento del conjunto de datos de entrenamiento, el cual almacena valores que indican si los ejemplos fueron bien o mal clasificados.
• Algoritmo para generar hipótesis débiles (usando los ejemplos de entrenamiento ya ponderados (x1, y1, d1), . . . , (xn, yn, dn)).
• Combinar las hipótesis linealmente.
• Numero de iteraciones T definido a priori.
3.5 Comentarios finales
En este capítulo se presentaron lo temas involucrados en esta tesis, destacan: el conocimiento sobre alineación de ontologías y sus posibles aplicaciones, el formalismo del aprendizaje automático, así como el algoritmo Boosting. La alineación de ontologías, se ha convertido en un problema muy importante, por sus amplias aplicaciones para la Web Semántica. Es difícil que todos usemos un estándar universal para representar la información, es mucho más difícil definirlo. Por eso, son necesarios mecanismos de reconciliación de datos. Por otro lado, existen diversos algoritmos para clasificación de datos que pueden formar parte de una estrategia de solución. Dependiendo del enfoque, se pueden utilizar algoritmos supervisados y no supervisados. En este sentido, los principios que definen la esencia de Boosting permiten aplicarlo en la solución de diversos problemas. El siguiente capítulo es el más importante, ya que se fusiona el conocimiento abordado en los capítulos anteriores con la propuesta de solución para la alineación de ontologías. Al final de dicho capítulo se presenta y se discute el caso de aplicación de la alineación.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 61
CAPÍTULO 4 : METODOLOGÍA En este capítulo presentamos la metodología desarrollad, también se propone un caso de aplicación de la alineación de ontologías en el dominio geoespacial.
4.1 Introducción
Nuestra metodología de alineación se concentra en obtener como resultado un conjunto de correspondencias semánticas (equivalencias semánticas), entre pares de clases de dos ontologías diferentes. Este proceso es optimizado por el método Boosting, un algoritmo de aprendizaje automático. Al final, el resultado es revisado por un usuario quien valida las correspondencias encontradas y realiza las correcciones pertinentes, si así lo considera. Con base en (Euzenat, 2005) el proceso de alineación de ontologías, puede estar compuesto de forma general por los siguientes elementos: dos ontologías O1 y O2, un conjunto p de parámetros, un conjunto r de recursos para la alineación, y una función de alineación, que retorna un conjunto de correspondencias A’ (ver Figura 4.1).
′ , , ,
Figura 4.1. Componentes de alineación
• La función f es un proceso que integra diversos recursos para encontrar correspondencias entre dos conceptos.
• En cada O1 y O2 se analizan parte de sus elementos como: conceptos, propiedades de conceptos y jerarquía de conceptos.
• El conjunto p representa los requisitos para realizar la alineación; p = {lenguaje de diseño OWL, número de elementos, vocabulario del idioma, no inferencias}.
• En nuestro caso, el conjunto de recursos se refiere a los elementos empleados para obtener el conjunto de correspondencias: r = {conjunto medidas de similitud, algoritmo AdaBoost, algoritmo de clasificación K-Vecinos}, ver Figura 4.2.
• El conjunto simboliza todas las correspondencias semánticas.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 62
En las siguientes secciones se describe con detalle la estrategia de solución desarrollada y los recursos utilizados en la solución. Durante este capítulo, con el único fin de ilustrar la explicación de la metodología, se usaran como ejemplos algunos conceptos que son parte de dos ontologías turísticas.
4.2 Descripción general de la metodología
Propongamos el siguiente escenario: supongamos que en México, la Secretaria de Turismo del Estado de Quintana Roo desarrolla una ontología que describe servicios turísticos como hoteles, hostales, moteles, restaurantes, etc. El objetivo es registrar la información descriptiva y de ubicación geográfica de estos servicios en las zonas turísticas de Cancún. Por su lado la Secretaria de Turismo del Estado de Guerrero, también desarrolla una ontología turística para describir los mismos servicios, pero en el puerto de Acapulco según sus propias características turísticas. Supongamos que el INEGI (Instituto Nacional de Estadística Geografía e Informática) desarrollará un sistema que accede e integre información oficial de las playas más importantes en México, incluidas Cancún y Acapulco. La idea es usar las ontologías mencionadas. Es posible que en ambas ontologías tengan aspectos en común, encontrarlos de forma manual puede ser complicado. En este sentido nuestro método de alineación de ontologías, puede ser útil para detectar estas coincidencias entre las ontologías turísticas de Acapulco y Cancún. La propuesta de solución se presenta en la Figura 4.2. La idea subyacente en esta tesis, radica en integrar “óptimamente” un conjunto de medidas de similitud, a fin de poder encontrar correspondencias semánticas entre dos ontologías. El propósito es determinar si dos conceptos tienen entre sí una “correspondencia semántica fuerte” (equivalencia semántica), o una “correspondencia semántica débil” (relación débil ó nula). ¿Por qué es necesario utilizar más de una medida de similitud? Por ejemplo, dados los conceptos turísticos “hotel y “botel”: La similitud léxica entre ambos es de 0.8 (usando Distancia de Levenshtein3). Con este valor de medición, podemos decir que por su alta
3 La Distancia de Levenshtein o distancia de edición se le conoce al número mínimo de operaciones requeridas para transformar una cadena de caracteres en otra, dichas operaciones son: inserción, eliminación o la substitución de un carácter.
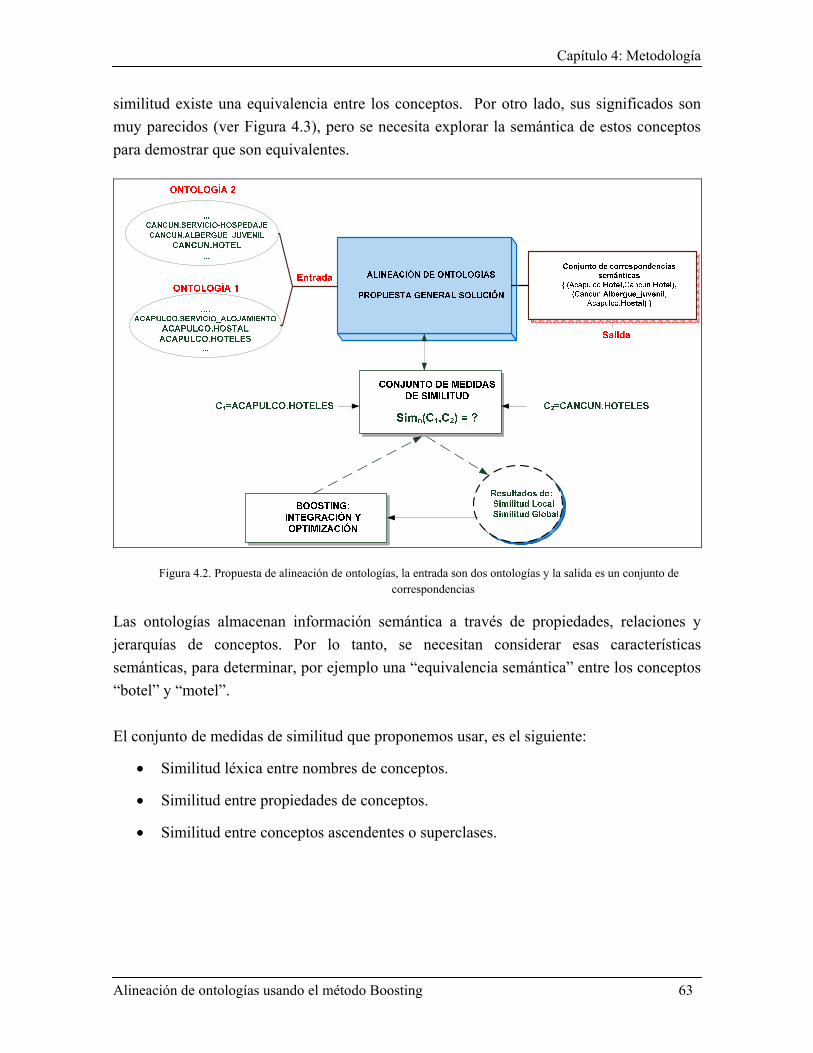
Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 63
similitud existe una equivalencia entre los conceptos. Por otro lado, sus significados son muy parecidos (ver Figura 4.3), pero se necesita explorar la semántica de estos conceptos para demostrar que son equivalentes.
Figura 4.2. Propuesta de alineación de ontologías, la entrada son dos ontologías y la salida es un conjunto de correspondencias
Las ontologías almacenan información semántica a través de propiedades, relaciones y jerarquías de conceptos. Por lo tanto, se necesitan considerar esas características semánticas, para determinar, por ejemplo una “equivalencia semántica” entre los conceptos “botel” y “motel”. El conjunto de medidas de similitud que proponemos usar, es el siguiente:
• Similitud léxica entre nombres de conceptos.
• Similitud entre propiedades de conceptos.
• Similitud entre conceptos ascendentes o superclases.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 64
Figura 4.3. ¿Puede existir una correspondencia entre “hotel” y “botel”? La diferencia radica en que “botel” es un
hotel establecido en un barco.
Cada medida tiene un rango numérico real de 0 a 1. Cuando el resultado de una medida de similitud alcanza el máximo valor de 1, significa que los dos objetos comparados son iguales, cuando el resultado es 0 los objetos son totalmente diferentes. Medir únicamente la similitud léxica no es suficiente. Es necesario considerar la similitud de otros componentes que son parte de la semántica de los conceptos en las ontologías. Por ejemplo, los conceptos “hostal” (e.g. en la ontología de Acapulco) y “albergue_juvenil” (e.g. en la ontología de Cancún). Ambos se refieren a un servicio de hospedaje; un establecimiento de menor categoría que un hotel, en donde se proporciona alojamiento y comida a cambio de dinero. Sin embargo, calculando la similitud léxica usando la distancia de Levenshtein (ver sección 4.3.3.1.1) entre los nombres de las clases “hostal” y “albergue_juvenil”, el valor es muy bajo:
_ “ ”, “ _ ” 0.0625 Es claro observar que no es suficiente medir similitud léxica, aunque ambos términos son lexicalmente diferentes se refieren al mismo significado. Por otro lado, podemos emplear otras estrategias para encontrar una similitud más relacionada al significado de los términos. Por ejemplo medir la similitud entre las propiedades de ambos conceptos:
Con el valor de similitud entre propiedades, calculado por medio del procedimiento descrito en la sección 4.3.3.1.2, se puede esperar una posible correspondencia semántica entre “hostal” y “albergue_juvenil”.
_ “ ”, “ _ ” 0.60
Propiedades de “hostal”: “habitaciones”, “literas”, “”, “precio”, “baño”. Propiedades de “albergue_juvenil”: “habitaciones”, “precio”, “servicio_cocina”, “baño”, “literas”.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 65
Por otro lado, podemos considerar la jerarquía de conceptos de cada ontología; es decir, considerar la similitud de los conceptos ascendentes, con respecto a los conceptos en comparación. Esta relación puede ayudar a definir una posible correspondencia semántica:
Conceptos padre de “hostal” puede ser: “servicio_alojamiento”, “servicios_turismo”, “Acapulco”
Conceptos padre de “albergue_juvenil” puede ser: “servicio-hospedaje”, “zona_turistica”, “Cancún” En este caso, la pareja de conceptos ascendentes “servicio_alojamiento” y “servicio-hospedaje”, es la que tiene la mayor similitud entre el resto de parejas de conceptos ascendentes. La siguiente medida de similitud se obtiene al combinar la similitud léxica y de propiedades ya calculadas, como se menciona en el procedimiento de la sección 4.3.3.1.3, por tanto:
_ “ ”, “ _ ” 0.81 La similitud entre propiedades y entre superclases, representan una componente semántica, ya que es más importante que la similitud léxica. Aunque los valores de similitud no sean igual a 1 (máxima similitud), estos valores pueden interpretarse como una aproximación para decidir si existe una correspondencia semántica entre los conceptos comparados. Combinando las diferentes medidas de similitud, es posible obtener un valor de semejanza más aproximado a la similitud semántica real. Por otro lado, se asume que al combinar estas tres medidas, obtenemos:
_ “ ”, “ _ ” 0.20 _ “ ”, “ _ ” 0.50 _ “ ”, “ _ ”
0.30 _ “ ”, “ _ ” 0.55
Los coeficientes para calcular la similitud global (0.20, 0.50 y 0.30) representan los pesos que miden la importancia asignada a cada medida de similitud, dichos coeficientes fueron definidos de forma empírica. En este trabajo la similitud global es solo un valor informativo, es decir, no es considerada como un criterio para tomar decisiones durante el proceso de alineación, debido a que es difícil definir los pesos adecuados para cada medida usada. La sección 4.3.3.3 aborda la estrategia de combinación utilizada en esta tesis.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 66
En el sentido de combinar el conjunto de medidas de similitud, se propone emplear el algoritmo Boosting. La motivación para usar dicho algoritmo es optimizar el proceso de alineación y clasificar todos los valores de similitud calculados de cada medida. La idea es hacer tres clasificaciones con Boosting sobre los tres conjuntos de valores calculados de similitud léxica, similitud entre propiedades y similitud entre conceptos ascendentes. Boosting clasificará un valor de similitud en dos posibles clases “correspondencias parciales fuertes” y “correspondencias parciales débiles” (ver sección 4.3.3.3). Los resultados de las tres clasificaciones se integran de acuerdo a ciertos criterios que proporcionan el grado de importancia a las correspondencias parciales (encontradas por Boosting) desde un enfoque más cercano a la interpretación humana. Finalmente una pareja de conceptos puede ser categorizada en dos posibles grupos: “correspondencias fuertes parciales” y “correspondencias débiles parciales”. Estos criterios proporcionan el grado de importancia de las medidas de similitud. La sección 4.3.3.4 aborda la descripción de los criterios de integración. Finalmente en la sección 4.3.4, se construye el archivo XML con estos resultados. El escenario de heterogeneidad entre estas ontologías, es un caso real presente en diferentes proyectos relacionados con ontologías turísticas creadas en diferentes naciones europeas. En (Programme, 2006) se han propuesto diferentes soluciones para establecer estándares e interoperación entre ontologías del dominio turístico, para más información consultar (Missikoff, et al., 2003). El caso de aplicación de la alineación de ontologías en el dominio geoespacial propuesto está relacionado con el dominio turístico.
4.3 Metodología de alineación de ontologías
Nuestra estrategia de alineación fue diseñada para encontrar un conjunto de correspondencias semánticas entre dos ontologías. Como se describió en el estado del arte, la similitud entre elementos de ontologías es un componente importante en los sistemas de alineación. En esta sección explicaremos la propuesta de arquitectura de software del sistema de alineación llamado MatchBoost, ver ¡Error! No se encuentra el origen de la referencia. En lo subsecuente los “conceptos” en una ontología los denominamos como “clases”. La idea en MatchBoost es comparar cada clase de una ontología con cada clase de otra ontología (arquitectura punto a punto) a fin de obtener su similitud.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 67
Posteriormente, se obtiene una matriz M x N de similitud (M clases en una ontología y N clases en otra ontología) por cada medida usada. Cada elemento de dicha matriz, representa el valor de similitud entre una pareja de clases comparada (e.g. FilamColumnan=similitud_léxica(“hotel”, “motel”)).
Figura 4.4. Metodología para el sistema MatchBoost
Las matrices de similitud, son los elementos de entrada de un proceso clasificador, el cual intenta clasificar la similitud de cada pareja de clases, en dos posibles categorías “correspondencias fuertes parciales” o “correspondencias débiles parciales”. La primera categoría representa las parejas de clases que tienen una alta similitud entre sí (e.g “hotel” y “hotel”). La segunda categoría representa las parejas de clases que tienen una similitud muy baja (e.g. “hotel” y “restaurante”). Sin embargo, debido a la distribución y la naturaleza de los datos de entrada (almacenados en las matrices), el proceso de clasificación mencionado puede presentar fallas, al no poder clasificar las parejas de clases (a través de su valor de similitud) en alguna de las categorías mencionadas. Por esta razón, proponemos usar el algoritmo AdaBoost, versión generalizada de Boosting y su variante más usada. El objetivo de AdaBoost es optimizar el proceso de clasificación reduciendo la cantidad de elementos no categorizados (o categorizados incorrectamente). AdaBoost es un método de aprendizaje automático, que combina diferentes “weak learners” (reglas simples de clasificación) en un clasificador más eficiente. En este sentido,

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 68
cada “weak learner” es un experto que produce una predicción sobre la categoría a la que pertenecen dos clases. Finalmente, es posible mejorar la precisión de la clasificación, si se combinan las predicciones de varios “weak learners”. A través de un proceso para detectar las posibles correspondencias semánticas, se genera el archivo XML con los resultados finales, es decir, parejas de conceptos que tienen correspondencias entre sí, una correspondencia semántica fuerte o débil. La metodología propuesta está basada fundamentalmente en tres módulos funcionales: Adquisición y validación de ontologías, detección de correspondencias semánticas, y el módulo generador del archivo de correspondencias. La ¡Error! No se encuentra el origen de la referencia. presenta la arquitectura del sistema MatchBoost.
4.3.1 Algoritmo general de alineación de ontologías usando el método 4.3.1 Algoritmo general de alineación de ontologías usando el método Boosting
De acuerdo con la descripción general de la metodología. La 4 muestra el algoritmo general de alineación propuesto en esta tesis.
Tabla 4.1. Algoritmo general de alineación de ontologías usando el método Boosting
Proceso_alineación(ontologia1, ontolgia2){ Ejecutar Adquisición y validación de ontologías de entrada (ontología1, ontolgía2) Si (Validación es correcta){ Invocar la detección de correspondencias semánticas Invocar funciones de medidas de similitud léxica y semántica Calcular una matriz de similitud por cada medida Ejecutar función Boosting_K-Vecinos(matrices globales de similitud) Ejecutar del clasificador K-vecinos (matrices globales de similitud) Si (existen elementos sin clasificar o hasta cumplir condición de paro){ Ejecutar Optimización invocando Boosting (Elementos no clasificados) Calcular errores; } Mantener en memoria el conjunto de correspondencias parciales Ejecutar identificación del conjunto final de clases de correspondencias fuertes y débiles } Ejecutar Generador del archivo XML de Alineación } En las secciones posteriores se abordarán detalles de cada uno de los componentes de la arquitectura de solución.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 69
4.3.2 Adquisición y validación de ontologías
De forma general este módulo, recibe como entrada dos ontologías y valida si se pueden utilizar en el proceso de alineación, y también adquiere información sobre las clases y sus respectivas jerarquías. Las actividades que desarrolla este módulo son las siguientes:
• Verificar el lenguaje de diseño de las dos ontologías de entrada.
• Obtener la jerarquía de clases de ambas ontologías.
• Extraer información de cada clase.
• Verificar si el número de clases es el adecuado para realizar el proceso de alineación.
Una ontología es expresada en un lenguaje de ontologías y los métodos de alineación deben trabajar en función de esos lenguajes y sus características. Existe una larga variedad de lenguajes para expresar ontologías (Staab, et al., 2004). Por esa razón, este módulo verifica que las ontologías de entrada estén diseñadas en el lenguaje OWL, en alguna de sus dos variables OWL-Lite u OWL-DL. Posteriormente, se define una estructura denominada Clase-OWL que almacena la información de cada clase de las ontologías (ver Tabla 4.2). Esta información es utilizada en: el proceso de detección de correspondencias y generación del archivo final de alineación.
Tabla 4.2. Descripción de la estructura Clase-OWL
Class datosClase_OWL{ int id_clase; String URI; String Nombre_clase; Array Lista_propiedades; String URI_clase_superior; String Nombre_clase_superior; Array id_clases_ascendentes; }
Nombre Descripción
id_clase Identificador de clase
URI URI de la clase en el archivo OWL
Nombre_clase Nombre de la clase
Lista_propiedades Conjunto de propiedades de la clase
URI_clase_superior URI de la clase superior inmediata
Nombre_clase_superior Nombre de la clase superior inmediata
id_clases_ascendentes Arreglo con los índices de las clases ascendentes+
Otra de las funciones de este modulo, es obtener la jerarquía de clases de las ontologías de entrada, donde cada nodo de la lista es una instancia de la estructura Clase-OWL. El

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 70
algoritmo para obtener la jerarquía de clases, está basado en la API JENA4 y se resume en los siguientes pasos que se ilustran en la Tabla 4.3.
Tabla 4.3. Descripción principal de la adquisición y validación de Ontologías
explora(Clase concepto_raíz){ Obtener la lista L de subclases del concepto_raíz usando la API Jena Mientras(existan elementos en la lista de subclases L) {
Obtener una clase llamada C de la lista de subclases L Extraer información de C y almacenarla en una instancia llamada S de Clase_OWL Agregar S a una lista que contiene el orden de la jerarquía de clases Llamar recursivamente a explora(C) como parámetro de entrada C
} }
Después de obtener las jerarquías de clase de las ontologías de entrada, podemos determinar si es factible continuar con el proceso de alineación de acuerdo con la siguiente premisa definida empíricamente:
• Si el número de clases en ambas ontologías supera cinco clases como mínimo; el proceso puede continuar. Sino el proceso es finalizado, ya que se considera que no existen elementos suficientes para realizar la alineación.
La Tabla 4.4 resume los procedimientos de este módulo:
Tabla 4.4. Descripción de la adquisición y validación de ontologías
Adquisición_Valida(ontologia1, ontolgia2){ Si(ontologia1.lengauge==OWL && ontologia1.lengauge==OWL){ Obtener Jerarquia1=Explora(ontologia1.Raiz) Obtener Jerarquia2=Explora(ontologia2.Raiz) Si(existe numero de clases adecuados) {
Retorna VERDADERO } Retorna FALSO }
4.3.3 Detección de correspondencias semánticas
Este módulo es el más importante en nuestra metodología, porque determina las correspondencias semánticas entre las dos ontologías de entrada. Inicialmente se define el
4 Jena es un framework en Java que permite construir aplicaciones para la Web Semántica. Proporciona un entorno de programación en los lenguajes: RDF, RDFS, SPARQL y OWL. http://jena.sourceforge.net/

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 71
conjunto de medidas de similitud a usar, después se describe el resultado obtenido en el cómputo de la similitud y se finaliza con la explicación de la clasificación y optimización.
4.3.3.1 Definición del conjunto de medidas de similitud
A continuación se describen las medidas de similitud seleccionadas para el proceso de alineación. Se dividen en dos grupos:
• Similitud con base en términos: Se enfoca en el nombre de las entidades en las ontologías, principalmente en el nombre de las clases y propiedades.
• Similitud semántica: Su alcance va más allá de los nombres de las entidades, se enfoca en los componentes que definen la semántica de una clase:
o Similitud entre propiedades de clases: Considera las coincidencias existentes entre las propiedades de dos clases.
o Similitud entre superclases: Se refiere al par de superclases con mayor similitud respecto a dos clases comparadas.
La Figura 4.5 resume el ámbito de aplicación del conjunto de medidas de similitud. La idea es pasar de una medición de similitud local a una global. Por esta razón, se utilizan la similitud léxica y similitud entre propiedades como un enfoque local, las cuales se combinan con la similitud entre clases ascendentes (que considera las estructuras de las ontologías). Una medición global es alcanzada al integrar los resultados de las tres medidas de similitud. Otras medidas pueden ser agregadas ó substituidas como los algoritmos usados para medir similitud estructural; como “Similarity Flooding” y “Graph Matching Ontology”, mencionados en el estado del arte. Por otro lado, la implementación de las medidas de similitud léxica y la similitud entre propiedades usadas, están basadas en la Ontology Aligment API (Euzenat, 2006a), una biblioteca libre de funciones para alinear ontologías y utilizada por la Ontology Aligment Evaluation Ontology Initiative.
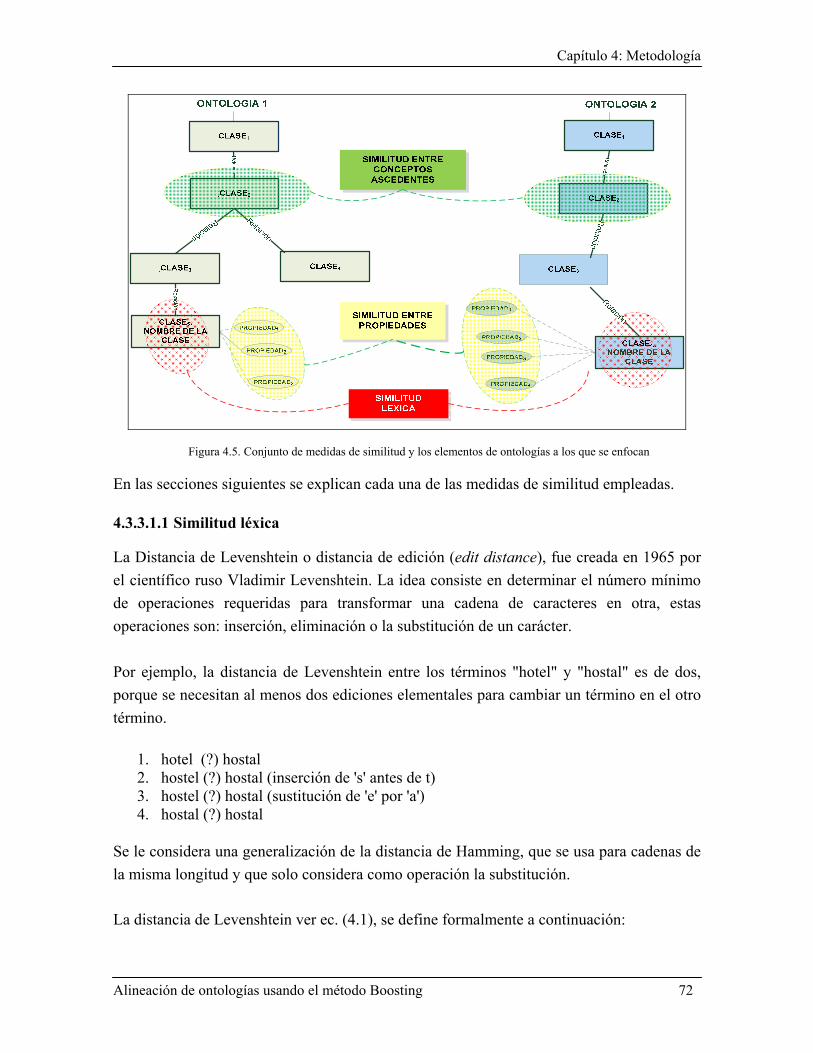
Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 72
Figura 4.5. Conjunto de medidas de similitud y los elementos de ontologías a los que se enfocan
En las secciones siguientes se explican cada una de las medidas de similitud empleadas.
4.3.3.1.1 Similitud léxica
La Distancia de Levenshtein o distancia de edición (edit distance), fue creada en 1965 por el científico ruso Vladimir Levenshtein. La idea consiste en determinar el número mínimo de operaciones requeridas para transformar una cadena de caracteres en otra, estas operaciones son: inserción, eliminación o la substitución de un carácter. Por ejemplo, la distancia de Levenshtein entre los términos "hotel" y "hostal" es de dos, porque se necesitan al menos dos ediciones elementales para cambiar un término en el otro término.
1. hotel (?) hostal 2. hostel (?) hostal (inserción de 's' antes de t) 3. hostel (?) hostal (sustitución de 'e' por 'a') 4. hostal (?) hostal
Se le considera una generalización de la distancia de Hamming, que se usa para cadenas de la misma longitud y que solo considera como operación la substitución.
La distancia de Levenshtein ver ec. (4.1), se define formalmente a continuación:

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 73
Dado un conjunto Op de operaciones en cadenas ( : ) y una función de costo; tal que para una pareja de cadenas existe una secuencia de operaciones que transforma la primer cadena en otra segunda cadena (y viceversa), la distancia Levenshtein es una disimilitud : 0,1 tal que , , es el costo de la secuencia menos costosa de operaciones que transforman S en T.
, min; … ∑ (4.1)
En otras palabras, la idea es transformar una cadena inicial S en otra T usando un mínimo de operaciones. El algoritmo general es ilustrado en la Tabla 4.5.
Tabla 4.5. Algoritmo general de la distancia Levenshtein
DistanciaLevenshtein(char Cadena1[1…m], char Cadena2 [1…n]){ Crear un matriz de enteros D con m+1 filas y n+1 columnas, D[0..m, 0..n] Para i desde 0 hasta m D [i][0]=i Para i desde 0 hasta n D [i][0]=j Para i desde 1 hasta m Para j desde 1 hasta n{Incrementa o decrementa el costo: Si (Cadena1[i]==Cadena2[j]){ Costo=0} No{ Costo=1 } Borrar = D[i-1][j] + 1 Inserción = D[i][j-1] + 1 Substitución = D[i-1][j-1] + Costo D[i,j]=ObtenMinimoOperaciones(Borrar, Inserción, Substitución) } Retorna D[m,n] }
En los métodos definidos en la Ontology Aligment API la distancia de edición está normalizada, es decir como resultado del cálculo de similitud se obtiene un valor que va desde 0 y hasta 1.
4.3.3.1.2 Similitud entre propiedades
El método de similitud entre propiedades se ha implementado con base en los métodos disponibles en la Ontology Aligment API (Euzenat, 2006a). También esta medida se desarrolló para el sistema OWL Lite Aligment5, el cual usa la similitud entre los nombres de clases y propiedades, considerando la propiedad de la simetría al calcular la similitud entre propiedades (Euzenat, et al., 2004a) . Ver Tabla 4.6. 5 http://www.iro.umontreal.ca/~owlola/

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 74
En esta medida, el propósito es comparar la distancia entre el conjunto de propiedades de dos clases, considerado la simetría de la similitud; es decir que la Similitud_propiedades(“hotel”, “botel”) sea la misma que Similitud_propiedades(“botel”, “hotel”).
Tabla 4.6. Algoritmo general de la similitud de propiedades
Similitud_Propiedades(Clase A, Clase B){ Obtener lista de propiedades p1 desde A.Obtener_propiedades() Obtener lista de propiedades p2 desde B.Obtener_propiedades() Para i desde 1 hasta p1.longitud() Para j desde 1 hasta p2.longitud(){ Obtener similitud léxica: SL[i]=Distancia(p1[i].nombre, p2[j].nombre,) } Definir correspondencias léxicas entre propiedades por concepto, utilizando un umbral Computar el numero de correspondencias léxicas Computar la similitud S
,| || |
Retornar S }
El objetivo es identificar si cada propiedad pn del conjunto de propiedades P de una clase C1, coincide con otra propiedad p’m del conjunto de propiedades de P’ de otra clase C2. Para realizar dicha comparación entre cada propiedad, se utilizan las etiquetas de ambas propiedades (o nombres) como entrada a una medida de similitud léxica, en este caso se ocupa la distancia de Levenshtein. En la expresión (4.2), A y B son los conjuntos de propiedades de las clases a y b, | | la intersección entre conjuntos, | | es la unión entre conjuntos:
,| || | (4.2)
4.3.3.1.3 Similitud entre superclases
Esta medida se enfoca en la similitud entre superclases (o similitud entre conceptos ascendentes) a partir de dos clases iníciales. La similitud entre algún par de superclases puede influir para establecer una correspondencia entre dos clases. Para calcular esta medida de similitud es necesario calcular previamente la similitud léxica y de propiedades de todas las parejas de clases.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 75
A continuación se define la similitud entre superclases en la ec. (4.3), dado , una pareja subclases:
_ , _ , (4.3)
La ec. (4.4) se expresa la similitud parcial: dado , una pareja de superclases obtenida desde , :
_ ,_ , _ ,
2 (4.4)
La idea intuitiva de la similitud parcial es obtener un valor que integre preliminarmente la similitud léxica y entre propiedades de forma equitativa. El objetivo es comparar parejas de superclases y seleccionar la pareja de superclases con mayor similitud entre sí, a fin de encontrar de manera aproximada la pareja de superclases en donde coincidan o converjan las clases y . Posteriormente, es posible modificar los pesos de las medidas en la similitud parcial a fin de mejorar el desempeño del sistema de alineación al encontrar con mejor precisión las correspondencias entre clases. Para encontrar la similitud entre superclases se sigue el procedimiento de la Tabla 4.7. Inicialmente la similitud parcial es usada tantas veces hasta calcular la similitud de todas las posibles parejas de superclases de y .
Tabla 4.7. Algoritmo general de la similitud de concepto ascendente
Similitud_superclases(Clase A, Clase B){
Obtener lista l1 de superclases p1 desde A.Obtener_superclases() Obtener lista l2 de superclases p2 desde B.Obtener_superclases () Para i desde 1 hasta l1.longitud() Para j desde 1 hasta l2.longitud(){
Valores[i]= _ l1. SuperClase i , l2. SuperClase j } Ordenar ascendentemente Valores Retornar Valores[0] }
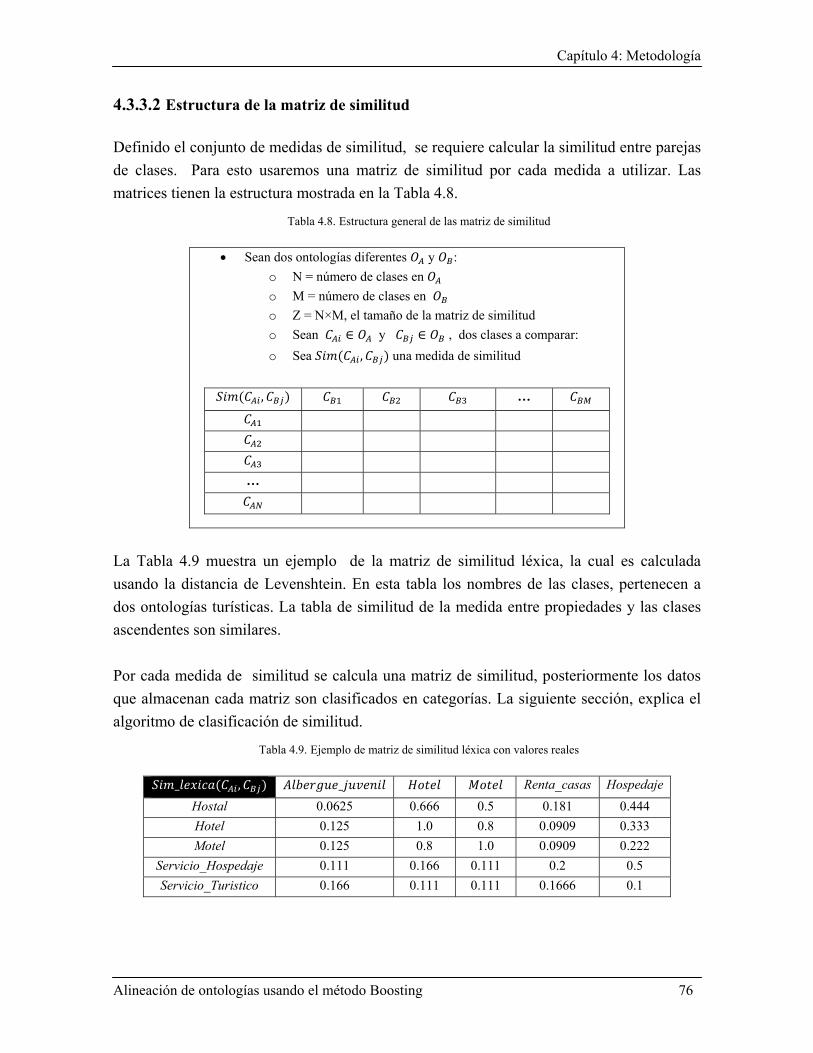
Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 76
4.3.3.2 Estructura de la matriz de similitud
Definido el conjunto de medidas de similitud, se requiere calcular la similitud entre parejas de clases. Para esto usaremos una matriz de similitud por cada medida a utilizar. Las matrices tienen la estructura mostrada en la Tabla 4.8.
Tabla 4.8. Estructura general de las matriz de similitud
• Sean dos ontologías diferentes y : o N = número de clases en o M = número de clases en o Z = N×M, el tamaño de la matriz de similitud o Sean y , dos clases a comparar: o Sea , una medida de similitud
, …
…
La Tabla 4.9 muestra un ejemplo de la matriz de similitud léxica, la cual es calculada usando la distancia de Levenshtein. En esta tabla los nombres de las clases, pertenecen a dos ontologías turísticas. La tabla de similitud de la medida entre propiedades y las clases ascendentes son similares. Por cada medida de similitud se calcula una matriz de similitud, posteriormente los datos que almacenan cada matriz son clasificados en categorías. La siguiente sección, explica el algoritmo de clasificación de similitud.
Tabla 4.9. Ejemplo de matriz de similitud léxica con valores reales
_ , _ Renta_casas Hospedaje Hostal 0.0625 0.666 0.5 0.181 0.444 Hotel 0.125 1.0 0.8 0.0909 0.333 Motel 0.125 0.8 1.0 0.0909 0.222
Servicio_Hospedaje 0.111 0.166 0.111 0.2 0.5 Servicio_Turistico 0.166 0.111 0.111 0.1666 0.1

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 77
4.3.3.3 Algoritmo para clasificar los valores de similitud
Después de calcular las matrices de similitud, es necesario clasificar las parejas de clases de acuerdo con su valor de similitud en dos posibles categorías: “Correspondencia fuerte” para las parejas de clases cuya similitud sea alta, y “Correspondencia débil”, para parejas de clases con similitud baja.
4.3.3.3.1 Algoritmo K-Vecinos (k-NN)
Para realizar la clasificación de valores de similitud, proponemos el uso del algoritmo K-Vecinos (k-NN, k-Nearest Neighbors). Este algoritmo clasifica patrones basándose en los vecinos más cercanos dado un conjunto de entrenamiento (el cual contiene patrones a clasificar). Los datos a clasificar son representados como puntos en un espacio n-dimensional. K-Vecinos también se le considera como un método no-paramétrico que puede ser usado para distribuciones de datos arbitrarias (Duda, et al., 2002), como las matrices de similitud ya mencionadas. K-NN (Hart, et al., 1967) es un método de clasificación que sirve para estimar una función de densidad F de un patrón x con respecto a una clase Cj. Dado un conjunto de entrenamiento que contiene m patrones, el clasificador K-Vecinos determina si un nuevo patrón pertenece a una clase C, siendo C la clase a la que sus patrones vecinos más cercanos pertenecen; es decir, k-NN asigna un nuevo patrón X a la categoría C, según el número k de vecinos más cercanos de X que pertenecen a C. Por ejemplo, al clasificar un patrón X (ver Figura 4.6), K-Vecinos puede decidir su clase de acuerdo con la siguiente información:
• k=8, k es el número de vecinos de un patrón X. • Cuatro patrones de la categoría 1. • Dos patrones de la categoría 2. • Dos patrones de la categoría 3. • Por el número de vecinos y su distancia, X puede pertenecer a la categoría 1.
Usando valores relativamente largos de k se reduce la precisión de la clasificación, ya que pueden influir otros patrones relativamente cercanos a X que pertenecen a otras clases. Se puede decir que K-Vecinos realiza una estimación de los valores de las probabilidades de las clases dado X, es decir la probabilidad que X pertenezca a una cierta clase.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 78
Figura 4.6. Un patrón X clasificado por K-Vecinos
La métrica de distancia usada en K-Vecinos, es una distancia Euclidiana, en nuestro caso los valores de similitud son atributos numéricos. Por tanto, la distancia entre dos patrones (x11,x12,…,x1n) y (x21,x22,…,x2n), se define en la ec. (4.5):
∑ , aj es un factor de escala para la dimensión j. (4.5)
El error de clasificación que pudiera existir dado un patrón X cuando se le asigna a una clase o categoría C (Nilsson, 1996). Puede ser dado por: | , donde p(i) es la probabilidad a priori de la categoría i, y | es la probabilidad (o función de densidad de probabilidad) de X, dado que X pertenece a la clase i, para todas las clases 1, … , . Suponga la probabilidad de error de la clasificación de patrones, tal que la mínima probabilidad de error de clasificación es . El teorema de Cover-Hart (Hart, et al., 1967) establece que la probabilidad de error , de un clasificador tipo K-Vecinos es delimitada por la ec. (4.6):
2 1 2 (4.6)
Donde R es el número de clases o categorías. Para el proceso de alineación, las matrices de similitud son el conjunto de entrenamiento para K-Vecinos que toma como entrada a las matrices de similitud. Para nuestra propuesta

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 79
de solución, K-Vecinos se considera como un algoritmo de clasificación “no supervisado” (Nilsson, 1996), porque se desconoce el número de clases o categorías a utilizar. Sin embargo es posible encontrar la clase útil para el proceso de alineación la cual agruparía los valores de similitud más altos. Esta clase recibe el nombre de “correspondencias fuertes parciales”. Al conjunto de las clases restantes reciben el nombre de “correspondencias débiles parciales”. Finalmente, se eligió el algoritmo K-Vecinos por su desempeño que ha sido comprobado en diferentes aplicaciones (Moore, 1992). En la Tabla 4.10 se ilustra el algoritmo K-Vecinos usado en esta tesis.
Tabla 4.10. Algoritmo K-Vecinos para AdaBoost
K_Vecinos(datos,umbral_pertenencia,Desviación_ini,rango_solución,iteraciones,umbral){ Inicializar matriz C de 2x2 C[1][1]={Maximo_valor(datos),Desviación_ini}: Desde 1 hasta iteraciones Desde i=1: hasta el número de datos a clasificar Desde j=1: hasta número de clases en C Si (distancia_euclidiana(patrones[i],C[j][i])<umbral_pertenencia) Patrones[i] pertenece a la clase j Etiquetar al elemento patrones[i] con la clase j Fin de condición Fin de ciclo Fin de ciclo Fin de ciclo Agregar información a la matriz de clases C con los elementos que le pertenecen Desde i=1: hasta el número de datos a clasificar Desde j=1: hasta número de clases en C Obtener en lista_clases la clase j desde C Si (Si tengo al menos un elemento en lista_clases) Agregar información de la clase j en C C[j][1]=Calcular_media_estándar (lista_clases); C[j][2]=Calcular_desviación_estándar(lista_clases); Fin de condición Fin de ciclo Fin de ciclo Verificar a que clase pertenece cada elemento Desde 1 hasta iteraciones Desde i=1: hasta el número de datos a clasificar Desde j=1: hasta número de clases en C Si (distancia_euclidiana(patrones[i],C[j][i])<umbral_pertenencia) Patrones[i] pertenece a la clase j Etiquetar al elemento patrones[i] con la clase j

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 80
Fin de condición Fin de ciclo Fin de ciclo Fin de ciclo Quitar clases innecesarias: Descartar clases que tuvieron menos de 1 elementos Crear otra clase o hipótesis Si (Se ha clasificado un número de elemento mayor al umbral) Generar una nueva clase (o hipótesis débil) usando el valor de desviación C=[C][J+1]+Clase_nueva Sino Salir de Knearest retornado C; Fin de condición Retorna C }

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 81
4.3.3.3.2 Algoritmo AdaBoost+K-Vecinos
A continuación presentamos la combinación del algoritmo K-Vecinos y AdaBoost. Ver Tabla 4.11.
Tabla 4.11. Algoritmo AdaBoost+K-Vecinos
AdaBoost+K (Matriz_similitud) Inicializar parámetros:
t=1 T=10
Kparametros.umbral_pertenencia=0.25 Kparametros.Desviación_inicial=1 Kparametros.rango_solución={0,1} Kparametros iteraciones=50; Kparametros umbral=15; Convertir la una matriz de similitud a un arreglo de valores: Kparametros.conjunto_prueba=Convierte_Matriz_Arreglo(Matriz_similitud); Inicializar distribución D D={01,…,0n} Obtener hipótesis débil ht y D con los elementos mal clasificados
ht, D = K-Vecinos(Kparametros);
Desde t hasta t=T{ Obtener elementos o patrones mal clasificados:
conjunto_prueba=Obtener_no_clasificados (Kparametros.conjunto_prueba, D); Si (Conjunto_prueba está vacío){ Imprimir: “Todos los elementos clasificados”
Salir de AdaBoost } Sino{ Concentración en la clasificación de los elementos mal clasificados
Computar el error de ht, con base en la distribución D
Computar el peso de la hipótesis: Actualizar conjunto de prueba a clasificar: Kparametros. conjunto_prueba= conjunto_prueba; Actualizar desviación inicial para generar nueva hipótesis Kparametros.Desviacion_inicial= 0.5*iter; Obtener hipótesis débil y realizar clasificación
ht, D =K_Nearest (Kparametros) .
} } Definir la clase de “correspondencia fuerte parcial” Definir la clase de “correspondencia débil parcial” Salida:
Hipótesis final ∑

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 82
El significado de los parámetros de entrada para K-Vecinos, es:
• Kparametros.umbral_pertenencia: Constante de pertenencia para el aprendizaje por K-Vecinos. Umbral para decidir si un objeto pertenece a una clase.
• Kparametros.Desviacion_inicial: Desviación estándar inicial para determinar una nueva clase, está relacionada con la distribución de los datos a clasificar.
• Kparametros.rango_solucion: El rango posible de soluciones para una nueva clase (de 0 a 1).
• Kparametros iteraciones: Número máximo de iteraciones para K-Vecinos.
• Kparametros umbral: Umbral para dejar de clasificar, si es que el proceso termina por número de iteraciones o por un porcentaje máximo de elementos clasificados.
• Kparametros.conjunto_prueba: Son los elementos de la matriz de similitud.
El algoritmo de la Tabla 4.11, es una implementación general de AdaBoost mas K-Vecimos (AdaBooost+K-vecinos) como entrada recibe valores de una matriz de similitud. La salida es la clasificación de estos valores en dos posibles clases: una clase que agrupa los valores de similitud más altos y otra clase que agrupa los valores de similitud más bajos. En AdaBoost+K-Vecinos el conjunto de distribución se obtiene a partir de identificar únicamente los elementos que fueron mal clasificados, e iterativamente eliminar los elementos bien clasificados. También se obtiene el error de clasificación en K-Vecinos con base en el número de elementos no clasificados. Si los resultados de las medidas de similitud reflejan una similitud incorrecta con respecto a las clases comparadas, AdaBoost detectará este comportamiento al no poder clasificar todos los valores de similitud, ya que el algoritmo depende de los datos de entrada. Por otro lado, si la cantidad de valores no clasificados es aceptable o menor a los parámetros establecidos, estos valores no clasificados serán reportados en el archivo final de resultados a fin de que sean revisados por el usuario. Por tanto, el valor de la similitud entre una pareja de clases puede ser clasificado en dos clases o categorías generales: “correspondencias fuertes débiles” y “correspondencias débiles parciales”, es decir, los tres valores de similitud para cada pareja de clases se clasificarán en alguna de estas categorías.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 83
El algoritmo intentara clasificar todos los valores de similitud. Es posible que AdaBoost+K-Vecinos encuentre una ó más clases, pero identificara la clase con los valores con alta similitud o magnitud máxima, la cual recibirá el nombre “correspondencias fuertes débiles”. El resto de las clases (si se encontraron más de una) representan los valores de similitud de mínima magnitud, entonces estas se agruparán en la clase general “correspondencias débiles parciales”, como se ilustra en la Figura 4.7.
Figura 4.7. Salida del algoritmo AdaBoost+K-vecinos
En la Figura 4.8, se aprecia la salida del algoritmo AdaBoost+K-Vecinos que obtiene como resultado seis grupos de valores clasificados: CF1, CF3 y CF5 representan las correspondencias fuertes parciales, un grupo por cada tipo de similitud empleada. Los grupos CD2, CD4 y CD6 representan las correspondencias débiles parciales.
4.3.3.4 Criterios para decidir correspondencias semánticas
Después de obtener los resultados de las tres clasificaciones realizadas, esta información debe ser integrada a fin de encontrar el conjunto de correspondencias semánticas finales. La Figura 4.8 ilustra de forma general el procedimiento de integración.
Figura 4.8. Integración de correspondencias parciales
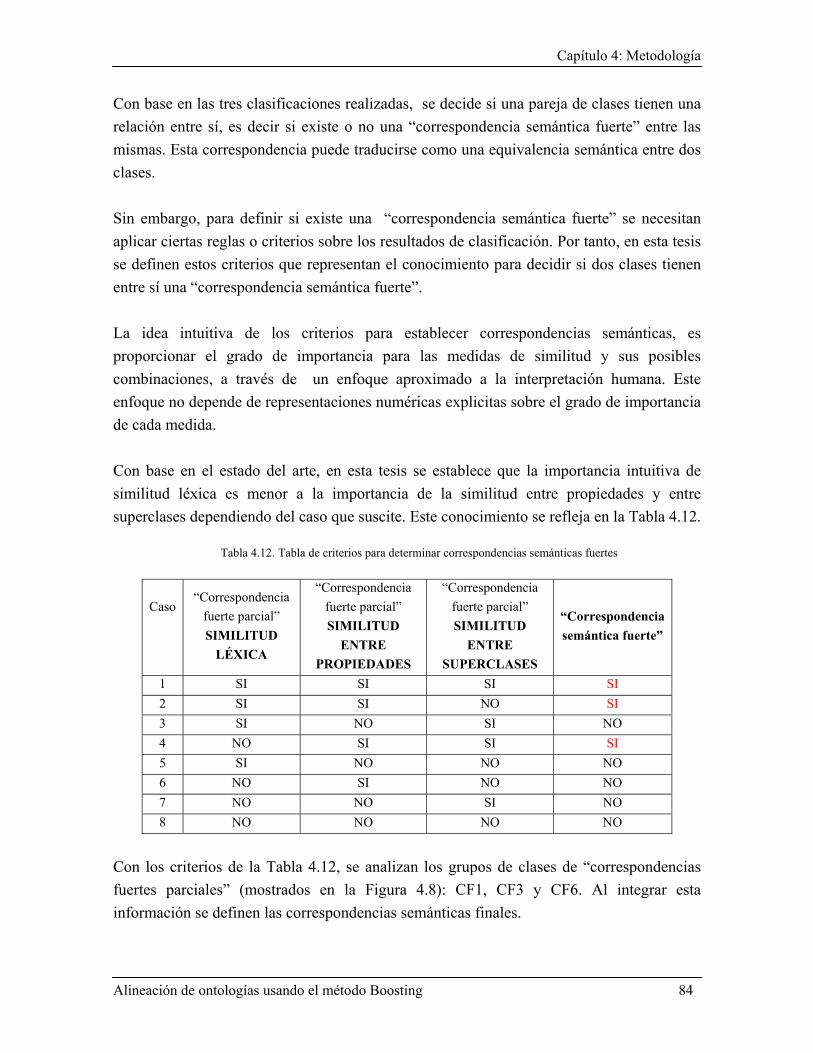
Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 84
Con base en las tres clasificaciones realizadas, se decide si una pareja de clases tienen una relación entre sí, es decir si existe o no una “correspondencia semántica fuerte” entre las mismas. Esta correspondencia puede traducirse como una equivalencia semántica entre dos clases. Sin embargo, para definir si existe una “correspondencia semántica fuerte” se necesitan aplicar ciertas reglas o criterios sobre los resultados de clasificación. Por tanto, en esta tesis se definen estos criterios que representan el conocimiento para decidir si dos clases tienen entre sí una “correspondencia semántica fuerte”. La idea intuitiva de los criterios para establecer correspondencias semánticas, es proporcionar el grado de importancia para las medidas de similitud y sus posibles combinaciones, a través de un enfoque aproximado a la interpretación humana. Este enfoque no depende de representaciones numéricas explicitas sobre el grado de importancia de cada medida. Con base en el estado del arte, en esta tesis se establece que la importancia intuitiva de similitud léxica es menor a la importancia de la similitud entre propiedades y entre superclases dependiendo del caso que suscite. Este conocimiento se refleja en la Tabla 4.12.
Tabla 4.12. Tabla de criterios para determinar correspondencias semánticas fuertes
Caso
“Correspondencia fuerte parcial” SIMILITUD
LÉXICA
“Correspondencia fuerte parcial” SIMILITUD
ENTRE PROPIEDADES
“Correspondencia fuerte parcial” SIMILITUD
ENTRE SUPERCLASES
“Correspondencia semántica fuerte”
1 SI SI SI SI 2 SI SI NO SI 3 SI NO SI NO 4 NO SI SI SI 5 SI NO NO NO 6 NO SI NO NO 7 NO NO SI NO 8 NO NO NO NO
Con los criterios de la Tabla 4.12, se analizan los grupos de clases de “correspondencias fuertes parciales” (mostrados en la Figura 4.8): CF1, CF3 y CF6. Al integrar esta información se definen las correspondencias semánticas finales.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 85
Los casos 1,2 y 4 de la Tabla 4.12 muestran las condiciones para establecer una “correspondencia semántica fuerte“. En el caso 1, una pareja de conceptos puede estar clasificada por su similitud léxica, entre propiedades y entre superclases en las categorías “correspondencia parcial fuerte” respectivamente, por lo tanto, se define una “correspondencia semántica fuerte”. En el caso 2, la pareja de conceptos está clasificada por su similitud léxica como “correspondencia parcial fuerte” y por su similitud entre propiedades, también es clasificada como “correspondencia parcial fuerte”. Aunque su similitud entre superclases fue clasificada como “correspondencia parcial débil”, se establece que la combinación de la similitud léxica y entre propiedades es más importante que la similitud de superclases. Por tanto, se define una “correspondencia semántica fuerte”. Para el caso 4, una pareja de conceptos es clasificada por su similitud léxica como “correspondencia parcial débil”, y por su similitud entre propiedades y superclases se clasifica como “correspondencia parcial fuerte” respectivamente. La combinación de similitud entre propiedades y superclases es más importante que la similitud léxica, por tanto, se establece una “correspondencia semántica fuerte”. Este caso representa a dos conceptos que tienen nombres diferentes pero el mismo significado. En el caso de solo existir una correspondencia en alguno de los tres conjuntos, el resultado final es una “correspondencia semántica débil”. Por supuesto que estos criterios pueden ser modificados y adaptados según sea conveniente. El siguiente ejemplo ilustra el uso de los criterios para establecer correspondencias. Dada la pareja de conceptos <Acapulco.hotel> y <Cancún.hotel>, podemos decir que está clasificada en las categorías: CF1 (similitud léxica), CF3 (similitud entre propiedades) y CF6 (similitud entre superclases), el resultado final es una “correspondencia semántica fuerte” entre ambos conceptos. En otro caso, si la pareja <Acapulco.hostal> y <Cancún.albergue_juvenil> está clasificada en las categorías CF3_Propiedades y CF6_Ascendente. Podemos concluir que existe una “correspondencia semántica fuerte”. Finalmente, como un valor informativo dirigido al usuario final, la ec. (4.7) define la similitud global:

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 86
_ , α _ , γ _ , ϕ _ ,
α 0.20, γ 0.50 ϕ 0.30
(4.7)
Los coeficientes γ,α y ϕ representan los pesos que miden la importancia asignada a cada medida de similitud, sus valores fueron definidos de forma empírica.
4.3.4 Archivo final de Alineación
El archivo final de resultados se crea con base en la estructura de la Tabla 4.13, la API JDOM6 es utilizada para crear el archivo XML de correspondencias. Los resultados se presenta en el siguiente orden: “correspondencias semánticas fuertes”, “correspondencias semánticas débiles” y “elementos no procesados”.
Tabla 4.13. Archivo de alineación final
<uri_onto1 id=“1”> “URI DE LA ONTOLOGIA 1”</uri1_onto1> <uri_onto2 id=“2”> “URI DE LA ONTOLOGIA 2”</uri2_onto2> <CorrespondenciasFuertes> <Pareja1> <entidad1 URI=”URI DE LA CLASE 1” id=“1”/> <entidad2 URI=” URI DE LA CLASE 2” id=“2”/> <SimilitudGlobal>valor</SimilitudGlobal> <relacion> “TIPO DE RELACION”</relacion> </Pareja1> …. <ParejaN>…</ParejaN> </CorrespondenciasFuertes> <ElementosNoProcesados> <Pareja1> …</Pareja1> … </ElementosNoProcesados>
6 JDOM-API es una biblioteca de funciones para acceder, manipular y crear archivos XML desde programas escritos en JAVA. URL: http://www.jdom.org/

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 87
4.3.5 Caso de aplicación en el dominio geoespacial: Turismo electrónico
Nuestra propuesta de aplicación de la alineación de ontologías en el dominio geoespacial, consiste en alinear dos ontologías relacionadas a servicios turísticos ubicados en Acapulco y Cancún, México. La idea es utilizar los resultados de la alineación en un sistema Web llamado OntoMashup, el cual está orientando al sector turístico-hotelero. Aplicando la alineación es posible lograr interoperación semántica entre estas ontologías turísticas. En la sección 2.3.4.1 se justificó la importancia de este caso de aplicación en el dominio geoespacial. El objetivo de OntoMashup es ubicar geográficamente hoteles en Acapulco y Cancún, considerando la información descriptiva y geográfica de los hoteles que está almacenada en dos ontologías turísticas respectivamente. OntoMashup explota la información de ambas ontologías, y combina los servicios de Google maps (Google maps, 2004) y Geonames.org (Geonames, 2006) para visualizar información sobre “hoteles”.
4.3.5.1 Alineación de ontologías turísticas
Las ontologías que serán alineadas se muestran en la Figura 4.9 y Figura 4.10. Cada una incorpora conceptos que representan parcialmente el dominio turístico en las zonas geográficas de Acapulco y Cancún, ambas ontologías están escritas en el lenguaje OWL (OWL, 2004) y desarrolladas en el editor de ontologías Protégé7. Estas ontologías describen el significado de servicios turísticos como hospedaje, también se caracterizan por usar una estructura jerárquica de conceptos. La ontología turística de Acapulco fue desarrollada previamente por (Torres, 2007), su estructura se aprecia en la Figura 4.9. Algunas propiedades consideradas para describir semánticamente el concepto “hotel” en Acapulco, son: Nombre de hotel, número de estrellas, zona geográfica, dirección, tipo de habitación, costo por habitación, y coordenadas-geográficas. La jerarquía de superclases que es parte de la descripción de la clase “hotel”, consiste en los siguientes conceptos: Turismo Acapulco, zona de Acapulco, servicios turísticos y servicios de hospedaje.
7 http://protege.stanford.edu/
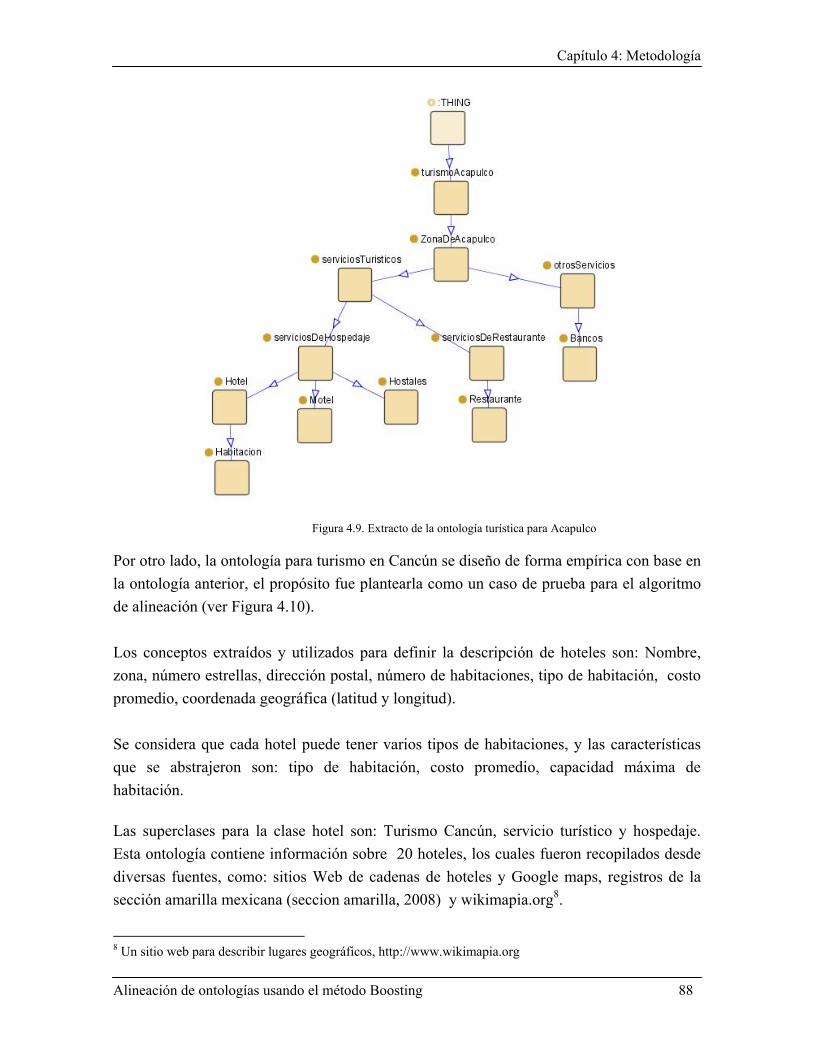
Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 88
Figura 4.9. Extracto de la ontología turística para Acapulco
Por otro lado, la ontología para turismo en Cancún se diseño de forma empírica con base en la ontología anterior, el propósito fue plantearla como un caso de prueba para el algoritmo de alineación (ver Figura 4.10). Los conceptos extraídos y utilizados para definir la descripción de hoteles son: Nombre, zona, número estrellas, dirección postal, número de habitaciones, tipo de habitación, costo promedio, coordenada geográfica (latitud y longitud). Se considera que cada hotel puede tener varios tipos de habitaciones, y las características que se abstrajeron son: tipo de habitación, costo promedio, capacidad máxima de habitación. Las superclases para la clase hotel son: Turismo Cancún, servicio turístico y hospedaje. Esta ontología contiene información sobre 20 hoteles, los cuales fueron recopilados desde diversas fuentes, como: sitios Web de cadenas de hoteles y Google maps, registros de la sección amarilla mexicana (seccion amarilla, 2008) y wikimapia.org8.
8 Un sitio web para describir lugares geográficos, http://www.wikimapia.org

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 89
Figura 4.10. Ontología turística para Cancún
4.3.5.2 Arquitectura del sistema web: OntoMashup
Para el caso de aplicación descrito anteriormente se propone una arquitectura Web llamada OntoMashup, la cual está enfocada a resolver búsquedas sobre hoteles localizados en Acapulco y Cancún México. La arquitectura web propuesta está basada en el modelo vista controlador (Singh, et al., 2002), un patrón de arquitectura de software que separa en tres componentes distintos: los datos (ontologías turísticas y motor de consultas), la interfaz de usuario o vista (cliente web), y la lógica de control (aplicación web central). OntoMashup está compuesto de tres módulos (ver Figura 4.11). Un cliente web, la aplicación central (almacenada en un servidor web) y el motor de consultas.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 90
Figura 4.11. Arquitectura web propuesta
4.3.5.2.1 Cliente web
Se encarga de capturar las consultas de los usuarios y se despliegan los resultados descriptivos y geográficos por medio de Google maps. Las opciones mostradas al usuario son: “hoteles en Cancún y Acapulco”, “hoteles en Cancún” y “hoteles en Acapulco”. Para cada una de estas consultas se explotan diferentes propiedades definidas en las respectivas ontologías y en el archivo XML de correspondencias. Internamente, existen procesos desarrollados en Java que vinculan la interfaz web con la API de Google maps, los resultados devueltos por la aplicación web central.
4.3.5.2.2 Aplicación web central
Se almacena en un servidor web Tomcat 5.5. En el lado del servidor se ejecuta el control de peticiones y el motor de consultas. En el control de peticiones se invocan procesos que realizan consultas sobre las ontologías.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 91
Los resultados son generados dinámicamente al responder las consultas del usuario y empaquetados para su visualización en Google maps. Las herramientas utilizadas son Java Server Pages y Java Servlets (tecnologías web Java).
4.3.5.2.3 Motor de consultas
Por medio de la API Jena (Jena, 2006), se extrae información usando SPARQL (SPARQL, 2004) desde las ontologías según el tipo de consulta seleccionada. Para procesar la consulta simultánea “hoteles en Acapulco y Cancún”, se utiliza el archivo XML de correspondencias proporcionado por MatchBoost. Para realizar búsquedas con base en las propiedades de hoteles en Acapulco, se definen consultas por nombre de hotel. En la Tabla 4.14 se muestra la estructura básica para una consulta construida en SPARQL, la cual busca hoteles en Acapulco usando la propiedad “nombre”. Esta consulta se compone de la sentencias SELECT donde se especifican las propiedades a considerar, WHERE para condicionar la búsqueda y FILTER para realizar un filtro sobre los resultados obtenidos con base a un parámetro. Para construir el resto de los tipos de consultas mencionados anteriormente con SPARQL, se realizan variaciones al contenido de estas sentencias.
Tabla 4.14. Ejemplo de una consulta SPARQL para búsqueda de hoteles en Acapulco por nombre
PREFIX table: <http://www.owl-ontologies.com/Acapulco.owl#> SELECT ?nombreHotel ?nombreZona ?numEstrellas ?costoHabitacion FROM <http://www.owl-ontologies.com/hoteles.owl> WHERE {+ ?Hotel table:nombreHotel ?parametro_hotel;" " table:nombreZona ? parametro_zona;" " table:numEstrellas ? parametro_estrellas;" " table:costoHabitacion ? parametro_costo." " FILTER (?nombreHotel='"+ parametro_nombre+"')" }
En las búsquedas con base en las propiedades de hoteles en Cancún, se definen consultas en base al costo de habitación.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 92
La Tabla 4.15 ilustra una consulta SPARQL para buscar hoteles en Cancún usando la propiedad “costo”. También para construir el resto de los tipos de consultas con SPARQL, se realizan modificaciones al contenido de las sentencias SELECT, WHERE y FILTER.
Tabla 4.15. Ejemplo de una consulta SPARQL para búsqueda de hoteles por costo en Cancún
PREFIX table: <http://www.owl-ontologies.com/Cancun.owl#> SELECT ? nombre ? zona ?estrellas ?costoHabitacion FROM <http://www.owl-ontologies.com/hoteles.owl> WHERE {+ ?Hotel table:nombre ? parametro_hotel;" " table: zona ? parametro_zona;" " table: Estrellas? parametro_estrellas ;" " table:costoPromedio ? parametro_costo." " FILTER (?costoPromedio <='"+ parametro_costo +"')" }
En la consulta simultánea “hoteles en Cancún y Acapulco”, se requiere el archivo XML de correspondencias, a fin de que este archivo sea un puente para vincular las dos ontologías turísticas, la Tabla 4.16 muestra un ejemplo de este archivo. El alcance de OntoMashup consiste en procesar la “correspondencia semántica fuerte” entre los conceptos “hotel” en ambas ontologías (ver el capítulo 5).
Tabla 4.16. Ejemplo del archivo XML de correspondencias a usar en la aplicación web
<uri_onto1 id=’1’>Acapulco </uri1_onto1> <uri_onto2 id=’2’> Cancun</uri2_onto2> <CorrespondenciasFuertes> <Pareja1> <entidad1 URI=Acapulco.hotel id=’1’> <entidad2 URI=Cancun.hotel id=’2’> <SimilitudGlobal>0.90</SimilitudGlobal> <relacion> “Correspondencia fuerte”</relacion> <Propiedades_ entidad1 id=’1’> <nombreHotel tipodato=“String”/> <numEstrellas tipodato=“Number”/> <costoHabitacion tipodato=“Float”/> …. </Propiedades_ entidad1> <Propiedades_ entidad2 id=’2’> <nombre tipodato=“String”/> <estrellas tipodato=“String”/> <CostoPromedio tipodato=“Float”/> …. </Propiedades_ entidad2> </Pareja1> </CorrespondenciasFuertes>

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 93
Posteriormente se podrían considerar el resto de las “correspondencias semánticas fuertes”, para incluir en las búsquedas por ejemplo “moteles” y “albergues_juveniles”, entre otros servicios de hospedaje. La consulta simultánea “hoteles en Cancún y Acapulco” también requiere definir una mapeo entre las propiedades del concepto “hotel”, y se realizará de forma manual después de obtener el archivo XML de correspondencias, por el momento estas adaptaciones se cargan directamente en el código fuente. Este mapeo permite plantear consultas búsqueda de “hoteles en Cancún y Acapulco por nombre” y “hoteles en Cancún y Acapulco por rango de precio”. Con el archivo XML de correspondencias y el mapeo entre propiedades definido, el motor de consultas expande la consulta simultánea en dos consultas SPARQL, como las mostradas en la Tabla 4.35 y Tabla 4.16 pero con los respectivos parámetros para Acapulco y Cancún. Posteriormente los resultados obtenidos serán mostrados en el cliente web mediante Google maps. Sin embargo, existen dificultades al procesar la coordenada geográfica cuando no se encuentra definida en las ontologías. Esto se debe a la escasa información geográfica en algunas referencias consultadas (e.g. sección amarilla (seccion amarilla, 2008)), ya que no fue posible obtener la coordenada geográfica para todos los hoteles. Por tanto el motor de búsqueda envía dinámicamente a Geonames.org el nombre del hotel, y obtiene sus coordenadas geográficas en el caso de que no existan en la ontología. El servicio web de Geonames.org se basa en una ontología geográfica (The GeoNames Ontology) y es posible consultar 6.2 millones de topónimos (nombres de sitios geográficos). Para obtener las coordenadas faltantes de un hotel. Se envía a Geonames.org la siguiente consulta; nombre de topónimo: “Hotel Ritz”, país: “México”, división geográfica: “Guerrero”, tipo de topónimo: “building”. De esta manera se intenta garantizar la obtención de la ubicación geográfica, para que el usuario pueda localizar con precisión la opción que satisfaga sus necesidades de hospedaje. Este mecanismo permite agregar nuevas instancias de hoteles, sin que sean requeridas las coordenadas geográficas.

Capítulo 4: Metodología
Alineación de ontologías usando el método Boosting 94
Finalmente en el capítulo 5, se muestran la interfaz grafica de OntoMashup y los resultados obtenidos para los diferentes tipos de consultas definidos, así como el archivo XML de correspondencias.
4.4 Comentarios finales
El enfoque propuesto, se basa en la idea de combinar diferentes medidas de similitud para obtener un valor de similitud más cercano a la semántica real de los conceptos comparados. Después esos valores de similitud son integrados por el método Boosting, el cual agrupa los valores de similitud. Finalmente, usando criterios se define si existe una correspondencia semántica entre dos conceptos. La arquitectura de MatchBoost permite agregar otras medidas de similitud (como las de tipo estructural) que mejorarían su desempeño. También, el propósito fue proponer una serie de criterios que definen intuitivamente y de manera más natural la importancia de las medidas de similitud; a diferencia de una definición basada en pesos. Se utilizaron tres medidas de similitud: distancia de edición, similitud entre propiedades (proporcionada por la OAEI) y similitud entre superclases, esta última medida fue planteada en este capítulo. También la implementación se realizo con base en la Ontology Aligment API escrita en Java y definida por la OAEI 2008. Sin embargo, esta API no está disponible en su versión final (Euzenat, 2006a); por tanto se tuvo que hacer adaptaciones al código fuente para la similitud entre propiedades, léxica y de superclases. En el siguiente capítulo se presentan los resultados obtenidos usando MatchBoost, así como las consultas resueltas por OntoMashup. También se discuten las pruebas realizadas para MatchBoost y los valores de similitud obtenidos.

Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 95
CAPÍTULO 5 : PRUEBAS Y RESULTADOS En este capítulo se presentan los resultados para MatchBoost (alineación de ontologías) y OntoMashup (el caso de aplicación de la alineación). Los resultados para MatchBoost se presentan de la siguiente manera: resultados de las medidas de similitud (tres medidas), proceso de clasificación (proporcionados por AdaBoost+K-Vecinos) y alineación de ontologías turísticas. En el caso de OntoMashup, como resultados finales se presentan: las consultas definidas para Acapulco, consultas para el puerto de Cancún, y finalmente las consultas definidas para el archivo de correspondencias.
5.1 Resultados para MatchBoost
Como caso de prueba, se propone alinear dos ontologías turísticas de Acapulco y Cancún. Los resultados que se exponen en las secciones posteriores, están basados en las clases o conceptos de estas dos ontologías. A través de matrices de similitud se muestran los resultados obtenidos por cada medida. En este sentido, MatchBoost recorre la jerarquía de clases de cada ontología, y asigna un número identificador a cada par de clases posible. Cada matriz contiene la similitud de doscientas parejas posibles de clases. Las columnas representan los nombres de todas las clases de la ontología turística para Cancún, mientras que las filas contienen los nombres de la clase de la ontología turística para Acapulco. En las siguientes secciones se ilustran los valores de similitud encontrados; posteriormente se discuten algunos de estos valores.
5.1.1 Resultados de la medida de similitud léxica
De acuerdo al capítulo anterior, usando la Distancia de Levenshtein se calculó la similitud léxica entre los nombres de todas las posibles parejas de clases. La matriz de similitud léxica se muestra en la 5. Aunque estas valores de similitud no sean suficientes para definir una relación semántica entre las clases, se aprecia que existen algunas de clases estas muy relacionadas con el nombre de otras, por ejemplo: “Hotel” y “Hotel” con valor=1.0, “Servicio_turístico” y “ServiciosTuristicos” con valor= 0.8947. .

Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 96
Tabla 5.1. Matriz de similitud léxica
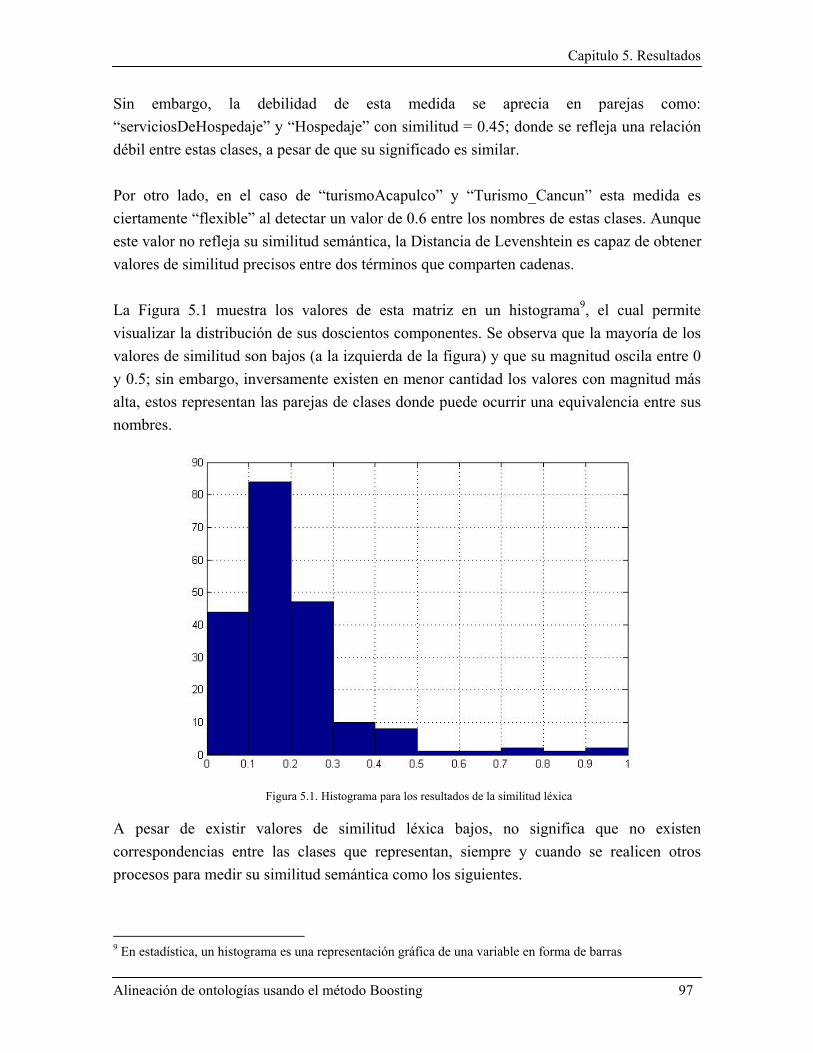
Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 97
Sin embargo, la debilidad de esta medida se aprecia en parejas como: “serviciosDeHospedaje” y “Hospedaje” con similitud = 0.45; donde se refleja una relación débil entre estas clases, a pesar de que su significado es similar. Por otro lado, en el caso de “turismoAcapulco” y “Turismo_Cancun” esta medida es ciertamente “flexible” al detectar un valor de 0.6 entre los nombres de estas clases. Aunque este valor no refleja su similitud semántica, la Distancia de Levenshtein es capaz de obtener valores de similitud precisos entre dos términos que comparten cadenas. La Figura 5.1 muestra los valores de esta matriz en un histograma9, el cual permite visualizar la distribución de sus doscientos componentes. Se observa que la mayoría de los valores de similitud son bajos (a la izquierda de la figura) y que su magnitud oscila entre 0 y 0.5; sin embargo, inversamente existen en menor cantidad los valores con magnitud más alta, estos representan las parejas de clases donde puede ocurrir una equivalencia entre sus nombres.
Figura 5.1. Histograma para los resultados de la similitud léxica
A pesar de existir valores de similitud léxica bajos, no significa que no existen correspondencias entre las clases que representan, siempre y cuando se realicen otros procesos para medir su similitud semántica como los siguientes.
9 En estadística, un histograma es una representación gráfica de una variable en forma de barras

Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 98
5.1.2 Resultados de la medida de similitud entre propiedades
Esta medida fue desarrollada con base en la Ontology Aligment API, y complementada con código adicional (ver anexos) para adaptarse a la propuesta de solución; por ejemplo se agrego una Librería de similitud léxica10 que incluye la Distancia de Levenshtein y algunas funciones de la API JENA. Por su naturaleza semántica y al ser un componente esencial para MatchBoost, es necesario abordar los resultados de esta medida. Como se observo en los resultados anteriores, pueden existir correspondencias semánticas entre clases que pueden ser descubiertas. Es decir, clases que tengan nombres diferentes pero que coincidan en el mismo significado o su significado es muy similar. En el caso opuesto donde existan clases con el mismo nombre pero con propiedades distintas. Aunque en el caso de aplicación propuesta no existe este caso, con el discernimiento entre el conjunto de medidas definido es posible abordar esta dificultad. En este sentido, con base a los resultados mostrados en la Tabla 5.2, la similitud entre propiedades proporciona un valor de semejanza más cercano al significado de las clases, con respecto a la medida anterior. Por ejemplo, “Albergue_juvenil” y “Hostal” tienen un valor de similitud de 0.5909 que es mayor al valor de su similitud léxica de 0.0625. Sin embargo, el valor 0.5909 no es suficiente para asegurar que estas clases tengan una relación entre ellas, agregando un nuevo componente como la similitud entre superclases podría alcanzarse una aproximación con más certeza. En la pareja “Turismo_Acapulco” y “Turismo_Cancun” se obtiene un valor de 0.7413, esto quiere decir, que por sus propiedades los conceptos están relacionados, el valor de similitud léxica (0.6) ya calculado puede ayudar a confirmar esta idea. No obstante, existen parejas donde el valor de similitud obtenida puede carecer de precisión (con respecto al caso de estudio) por ejemplo “Ferrocarril” y “Recorrido” con valor de 0.63. Otros casos donde se puede predecir una coincidencia son las parejas: “hotel” &“hotel” y “motel” &“motel”, en ambos casos su similitud es el valor máximo 1.0, que adicionado a la medición léxica después de aplicar AdaBoost, se puede esperar una “correspondencia semántica fuerte”. Las parejas de clases mencionadas arriba, fueron escogidas por su posición en sus respectivas ontologías, a fin de realizar una revisión sobre los casos más representativos; otras parejas de clases pueden ser analizadas.
10 http://www.dcs.shef.ac.uk/~sam/simmetrics.html
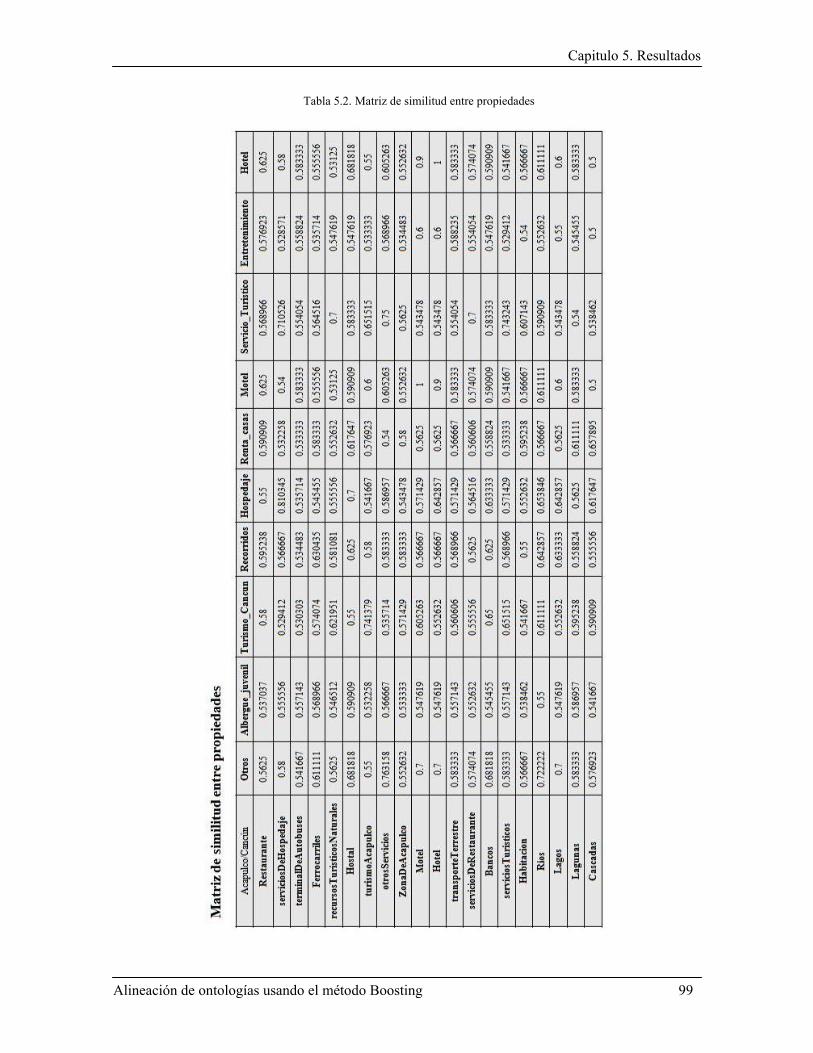
Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 99
Tabla 5.2. Matriz de similitud entre propiedades
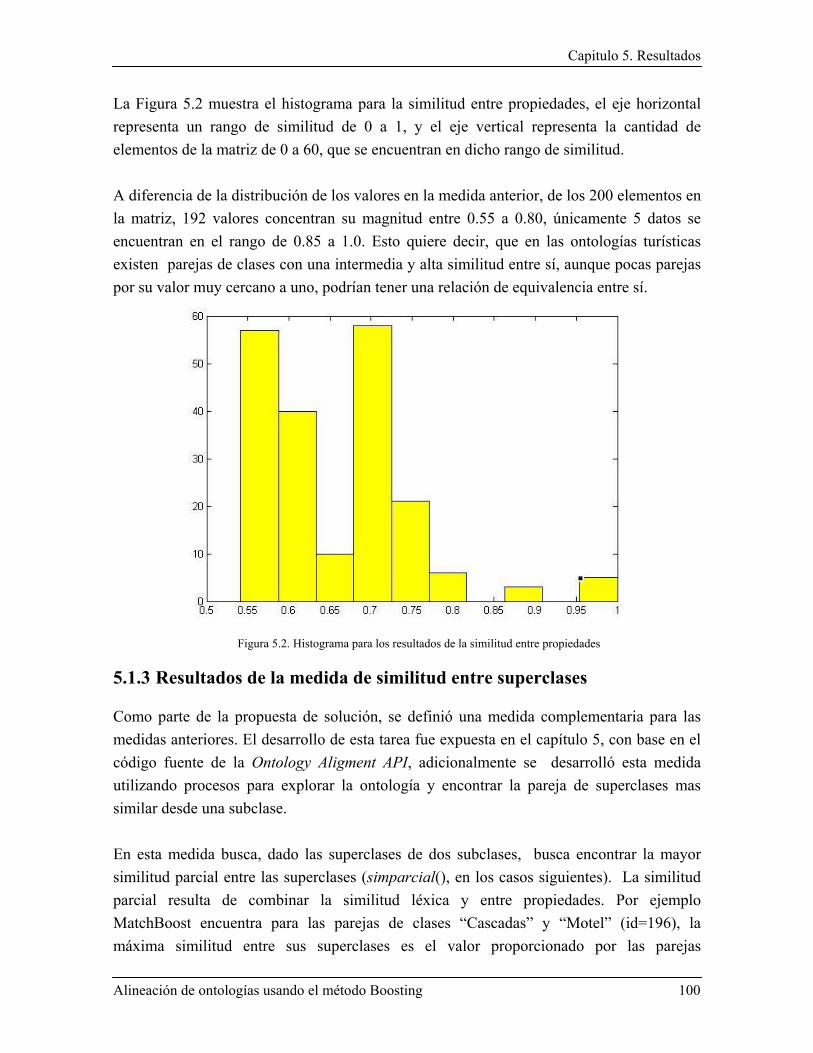
Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 100
La Figura 5.2 muestra el histograma para la similitud entre propiedades, el eje horizontal representa un rango de similitud de 0 a 1, y el eje vertical representa la cantidad de elementos de la matriz de 0 a 60, que se encuentran en dicho rango de similitud. A diferencia de la distribución de los valores en la medida anterior, de los 200 elementos en la matriz, 192 valores concentran su magnitud entre 0.55 a 0.80, únicamente 5 datos se encuentran en el rango de 0.85 a 1.0. Esto quiere decir, que en las ontologías turísticas existen parejas de clases con una intermedia y alta similitud entre sí, aunque pocas parejas por su valor muy cercano a uno, podrían tener una relación de equivalencia entre sí.
Figura 5.2. Histograma para los resultados de la similitud entre propiedades
5.1.3 Resultados de la medida de similitud entre superclases
Como parte de la propuesta de solución, se definió una medida complementaria para las medidas anteriores. El desarrollo de esta tarea fue expuesta en el capítulo 5, con base en el código fuente de la Ontology Aligment API, adicionalmente se desarrolló esta medida utilizando procesos para explorar la ontología y encontrar la pareja de superclases mas similar desde una subclase. En esta medida busca, dado las superclases de dos subclases, busca encontrar la mayor similitud parcial entre las superclases (simparcial(), en los casos siguientes). La similitud parcial resulta de combinar la similitud léxica y entre propiedades. Por ejemplo MatchBoost encuentra para las parejas de clases “Cascadas” y “Motel” (id=196), la máxima similitud entre sus superclases es el valor proporcionado por las parejas

Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 101
“turismoAcapulco” y “Turismo_Cancun”, siendo que cada una de estas clases se ubica en el punto más alto de su respectiva ontología. 196.-CLASE 1:Cascadas: 196.-CLASE 2:Motel:
62.-SimParcial(turismoAcapulco,Turismo_Cancun)=0.67068 47.-SimParcial(recursosTuristicosNaturales,Servicio_Turistico)=0.5351 67.-SimParcial(turismoAcapulco,Servicio_Turistico)=0.5095 42.-SimParcial(recursosTuristicosNaturales,Turismo_Cancun)=0.4406 63.-SimParcial(turismoAcapulco,Hospedaje)=0.4373 83.-SimParcial(ZonaDeAcapulco,Hospedaje)=0.3928 43.-SimParcial(recursosTuristicosNaturales,Hospedaje)=0.3850 87.-SimParcial(ZonaDeAcapulco,Servicio_Turistico)=0.3750 82.-SimParcial(ZonaDeAcapulco,Turismo_Cancun)=0.3214
El valor de similitud más alto es: 0.6706
La esencia de la similitud entre superclases, es dar una aproximación sobre la similitud estructural de dos ontologías; si solo existieran valores de similitud igual a cero, significa que dados clases no existe ninguna coincidencia con otra superclase. Para la pareja de clases “Hostal” y “Albergue_juvenil” el valor de similitud entre sus superclases es el proporcionado por las superclases “serviciosTuristicos” y “Servicio_Turistico” (al identificarse el valor de similitud parcial más alto). Nótese, que a mayor profundida de un par de subclases, mayor es la cantidad de resultados de similitud parcial para las superclases. 50.-CLASE 1:Hostal: 50.-CLASE 2:Albergue_juvenil: 147.-SimParcial(serviciosTuristicos,Servicio_Turistico)=0.8189 62.-SimParcial(turismoAcapulco,Turismo_Cancun)=0.6706 13.-SimParcial(serviciosDeHospedaje,Hospedaje)=0.6301 17.-SimParcial(serviciosDeHospedaje,Servicio_Turistico)=0.6301 67.-SimParcial(turismoAcapulco,Servicio_Turistico)=0.5095 63.-SimParcial(turismoAcapulco,Hospedaje)=0.4373 142.-SimParcial(serviciosTuristicos,Turismo_Cancun)=0.4310 83.-SimParcial(ZonaDeAcapulco,Hospedaje)=0.3928 12.-SimParcial(serviciosDeHospedaje,Turismo_Cancun)=0.3899 143.-SimParcial(serviciosTuristicos,Hospedaje)=0.3783 87.-SimParcial(ZonaDeAcapulco,Servicio_Turistico)=0.3750 82.-SimParcial(ZonaDeAcapulco,Turismo_Cancun)=0.3214 El valor de similitud más alto es: 0.8189 A continuación la Tabla 5.3 contiene los valores de similitud para cada pareja de clases.

Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 102
Tabla 5.3. Matriz de similitud entre superclases
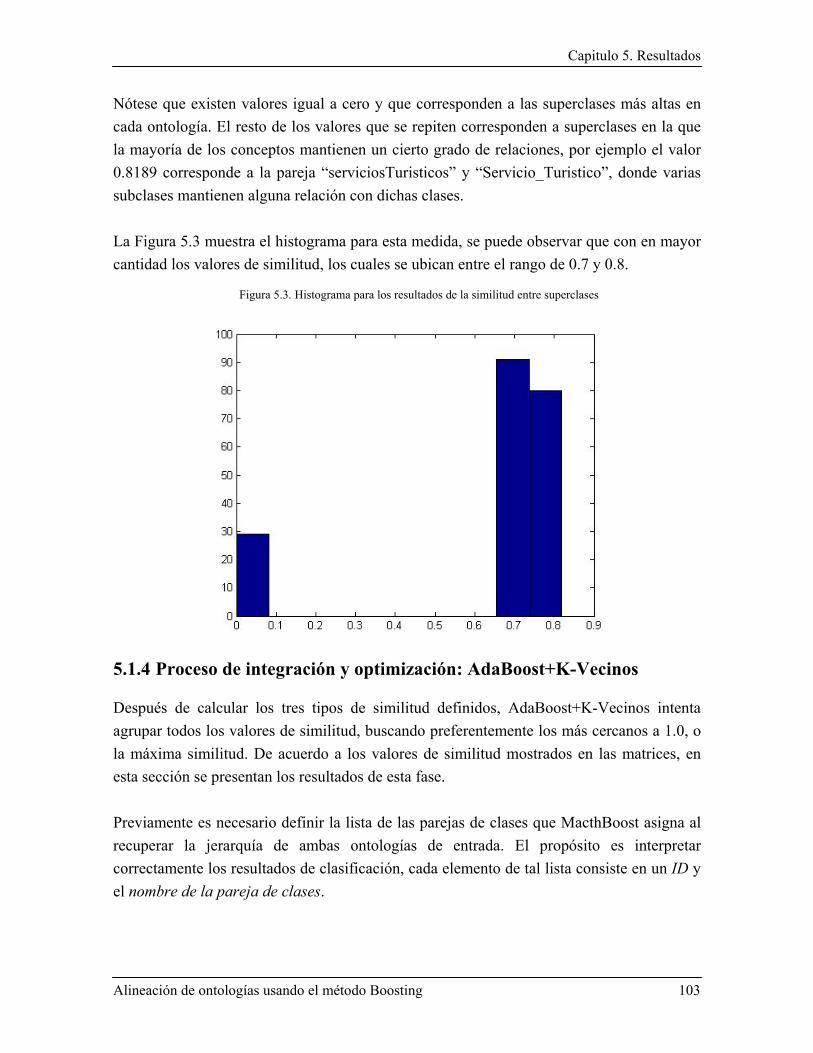
Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 103
Nótese que existen valores igual a cero y que corresponden a las superclases más altas en cada ontología. El resto de los valores que se repiten corresponden a superclases en la que la mayoría de los conceptos mantienen un cierto grado de relaciones, por ejemplo el valor 0.8189 corresponde a la pareja “serviciosTuristicos” y “Servicio_Turistico”, donde varias subclases mantienen alguna relación con dichas clases. La Figura 5.3 muestra el histograma para esta medida, se puede observar que con en mayor cantidad los valores de similitud, los cuales se ubican entre el rango de 0.7 y 0.8.
Figura 5.3. Histograma para los resultados de la similitud entre superclases
5.1.4 Proceso de integración y optimización: AdaBoost+K-Vecinos
Después de calcular los tres tipos de similitud definidos, AdaBoost+K-Vecinos intenta agrupar todos los valores de similitud, buscando preferentemente los más cercanos a 1.0, o la máxima similitud. De acuerdo a los valores de similitud mostrados en las matrices, en esta sección se presentan los resultados de esta fase. Previamente es necesario definir la lista de las parejas de clases que MacthBoost asigna al recuperar la jerarquía de ambas ontologías de entrada. El propósito es interpretar correctamente los resultados de clasificación, cada elemento de tal lista consiste en un ID y el nombre de la pareja de clases.

Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 104
Tabla 5.4. Lista de las parejas (id, de pareja) de clases asignada por OntoMashup
1: Restaurante-Albergue_juvenil 2: Restaurante-Turismo_Cancun 3: Restaurante-Recorridos 4: Restaurante-Hospedaje 5: Restaurante-Renta_casas 6: Restaurante-Motel 7: Restaurante-Servicio_Turistico 8: Restaurante-Entretenimiento 9: Restaurante-Hotel 10: serviciosDeHospedaje-Otros 11: serviciosDeHospedaje-Albergue_juvenil 12: serviciosDeHospedaje-Turismo_Cancun 13: serviciosDeHospedaje-Recorridos 14: serviciosDeHospedaje-Hospedaje 15: serviciosDeHospedaje-Renta_casas 16: serviciosDeHospedaje-Motel 17: serviciosDeHospedaje-Servicio_Turistico 18: serviciosDeHospedaje-Entretenimiento 19: serviciosDeHospedaje-Hotel 20: terminalDeAutobuses-Otros 21: terminalDeAutobuses-Albergue_juvenil 22: terminalDeAutobuses-Turismo_Cancun 23: terminalDeAutobuses-Recorridos 24: terminalDeAutobuses-Hospedaje 25: terminalDeAutobuses-Renta_casas 26: terminalDeAutobuses-Motel 27: terminalDeAutobuses-Servicio_Turistico 28: terminalDeAutobuses-Entretenimiento 29: terminalDeAutobuses-Hotel 30: Ferrocarriles-Otros 31: Ferrocarriles-Albergue_juvenil 32: Ferrocarriles-Turismo_Cancun 33: Ferrocarriles-Recorridos 34: Ferrocarriles-Hospedaje 35: Ferrocarriles-Renta_casas 36: Ferrocarriles-Motel 37: Ferrocarriles-Servicio_Turistico 38: Ferrocarriles-Entretenimiento 39: Ferrocarriles-Hotel 40: recursosTuristicosNaturales-Otros 41: recursosTuristicosNaturales-Albergue_juvenil 42: recursosTuristicosNaturales-Turismo_Cancun 43: recursosTuristicosNaturales-Recorridos 44: recursosTuristicosNaturales-Hospedaje 45: recursosTuristicosNaturales-Renta_casas 46: recursosTuristicosNaturales-Motel 47: recursosTuristicosNaturales-Servicio_Turistico 48: recursosTuristicosNaturales-Entretenimiento 49: recursosTuristicosNaturales-Hotel 50: Hostal-Otros 51: Hostal-Albergue_juvenil 52: Hostal-Turismo_Cancun 53: Hostal-Recorridos 54: Hostal-Hospedaje 55: Hostal-Renta_casas 56: Hostal-Motel 57: Hostal-Servicio_Turistico 58: Hostal-Entretenimiento 59: Hostal-Hotel 60: turismoAcapulco-Otros 61: turismoAcapulco-Albergue_juvenil 62: turismoAcapulco-Turismo_Cancun 63: turismoAcapulco-Recorridos 64: turismoAcapulco-Hospedaje
100: Hotel-Otros 101: Hotel-Albergue_juvenil 102: Hotel-Turismo_Cancun 103: Hotel-Recorridos 104: Hotel-Hospedaje 105: Hotel-Renta_casas 106: Hotel-Motel 107: Hotel-Servicio_Turistico 108: Hotel-Entretenimiento 109: Hotel-Hotel 110: transporteTerrestre-Otros 111: transporteTerrestre-Albergue_juvenil 112: transporteTerrestre-Turismo_Cancun 113: transporteTerrestre-Recorridos 114: transporteTerrestre-Hospedaje 115: transporteTerrestre-Renta_casas 116: transporteTerrestre-Motel 117: transporteTerrestre-Servicio_Turistico 118: transporteTerrestre-Entretenimiento 119: transporteTerrestre-Hotel 120: serviciosDeRestaurante-Otros 121: serviciosDeRestaurante-Albergue_juvenil 122: serviciosDeRestaurante-Turismo_Cancun 123: serviciosDeRestaurante-Recorridos 124: serviciosDeRestaurante-Hospedaje 125: serviciosDeRestaurante-Renta_casas 126: serviciosDeRestaurante-Motel 127: serviciosDeRestaurante-Servicio_Turistico 128: serviciosDeRestaurante-Entretenimiento 129: serviciosDeRestaurante-Hotel 130: Bancos-Otros 131: Bancos-Albergue_juvenil 132: Bancos-Turismo_Cancun 133: Bancos-Recorridos 134: Bancos-Hospedaje 135: Bancos-Renta_casas 136: Bancos-Motel 137: Bancos-Servicio_Turistico 138: Bancos-Entretenimiento 139: Bancos-Hotel 140: serviciosTuristicos-Otros 141: serviciosTuristicos-Albergue_juvenil 142: serviciosTuristicos-Turismo_Cancun 143: serviciosTuristicos-Recorridos 144: serviciosTuristicos-Hospedaje 145: serviciosTuristicos-Renta_casas 146: serviciosTuristicos-Motel 147: serviciosTuristicos-Servicio_Turistico 148: serviciosTuristicos-Entretenimiento 149: serviciosTuristicos-Hotel 150: Habitacion-Otros 151: Habitacion-Albergue_juvenil 152: Habitacion-Turismo_Cancun 153: Habitacion-Recorridos 154: Habitacion-Hospedaje 155: Habitacion-Renta_casas 156: Habitacion-Motel 157: Habitacion-Servicio_Turistico 158: Habitacion-Entretenimiento 159: Habitacion-Hotel 160: Rios-Otros 161: Rios-Albergue_juvenil 162: Rios-Turismo_Cancun 163: Rios-Recorridos 164: Rios-Hospedaje 165: Rios-Renta_casas

Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 105
65: turismoAcapulco-Renta_casas 66: turismoAcapulco-Motel 67: turismoAcapulco-Servicio_Turistico 68: turismoAcapulco-Entretenimiento 69: turismoAcapulco-Hotel 70: otrosServicios-Otros 71: otrosServicios-Albergue_juvenil 72: otrosServicios-Turismo_Cancun 73: otrosServicios-Recorridos 74: otrosServicios-Hospedaje 75: otrosServicios-Renta_casas 76: otrosServicios-Motel 77: otrosServicios-Servicio_Turistico 78: otrosServicios-Entretenimiento 79: otrosServicios-Hotel 80: ZonaDeAcapulco-Otros 81: ZonaDeAcapulco-Albergue_juvenil 82: ZonaDeAcapulco-Turismo_Cancun 83: ZonaDeAcapulco-Recorridos 84: ZonaDeAcapulco-Hospedaje 85: ZonaDeAcapulco-Renta_casas 86: ZonaDeAcapulco-Motel 87: ZonaDeAcapulco-Servicio_Turistico 88: ZonaDeAcapulco-Entretenimiento 89: ZonaDeAcapulco-Hotel 90: Motel-Otros 91: Motel-Albergue_juvenil 92: Motel-Turismo_Cancun 93: Motel-Recorridos 94: Motel-Hospedaje 95: Motel-Renta_casas 96: Motel-Motel 97: Motel-Servicio_Turistico 98: Motel-Entretenimiento 99: Motel-Hotel
166: Rios-Motel 167: Rios-Servicio_Turistico 168: Rios-Entretenimiento 169: Rios-Hotel 170: Lagos-Otros 171: Lagos-Albergue_juvenil 172: Lagos-Turismo_Cancun 173: Lagos-Recorridos 174: Lagos-Hospedaje 175: Lagos-Renta_casas 176: Lagos-Motel 177: Lagos-Servicio_Turistico 178: Lagos-Entretenimiento 179: Lagos-Hotel 180: Lagunas-Otros 181: Lagunas-Albergue_juvenil 182: Lagunas-Turismo_Cancun 183: Lagunas-Recorridos 184: Lagunas-Hospedaje 185: Lagunas-Renta_casas 186: Lagunas-Motel 187: Lagunas-Servicio_Turistico 188: Lagunas-Entretenimiento 189: Lagunas-Hotel 190: Cascadas-Otros 191: Cascadas-Albergue_juvenil 192: Cascadas-Turismo_Cancun 193: Cascadas-Recorridos 194: Cascadas-Hospedaje 195: Cascadas-Renta_casas 196: Cascadas-Motel 197: Cascadas-Servicio_Turistico 198: Cascadas-Entretenimiento 199: Cascadas-Hotel
Los resultados al clasificar la matriz de similitud léxica fueron los siguientes; se obtuvieron 5 clases o categorías, destacan las siguientes características:
• La primera contiene en valores que en promedio (media estándar) su magnitud oscilan alrededor de 0.8989, esto quiere decir que se ha detectado un grupo de parejas de clase con alta similitud léxica.
• La segunda clase se agruparon valores cuya magnitud oscilan alrededor de 0.4245, incluyendo los 29 elementos cuyo valor es 0.
• El resto oscila desde el 0.0855 y 0.0546 La Figura 5.4 ilustra los resultados obtenidos, en donde son identificados aquellos elementos con alta similitud.
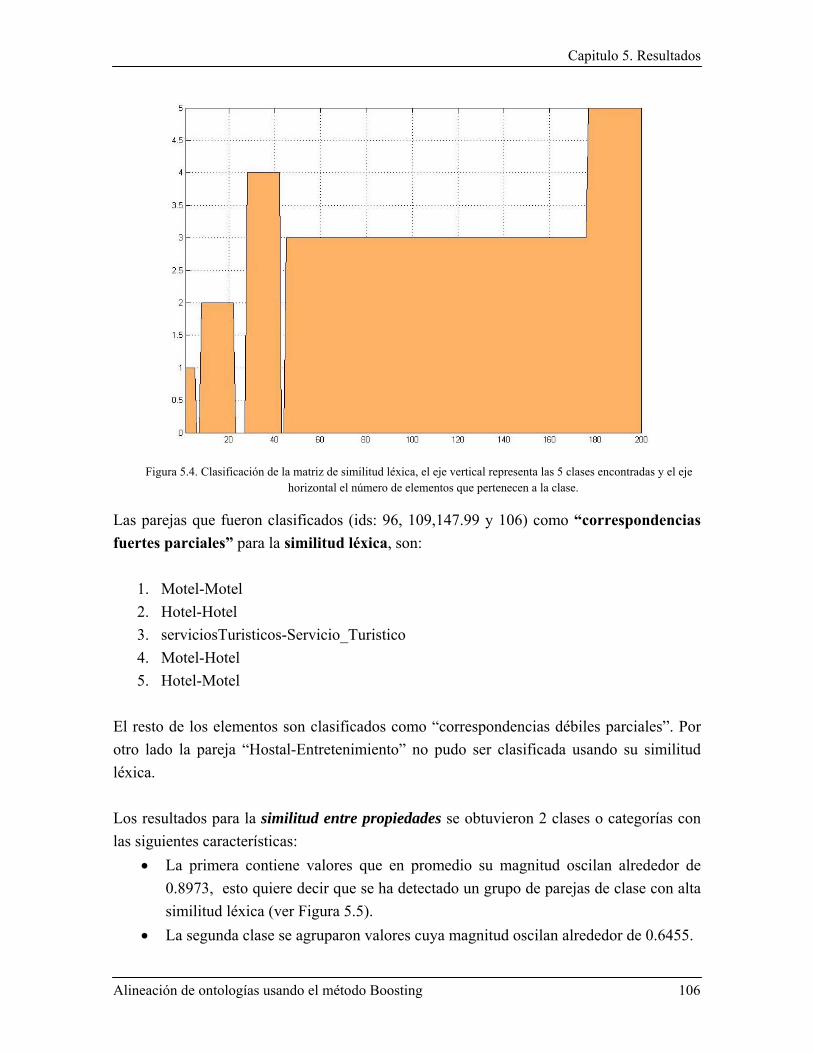
Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 106
Figura 5.4. Clasificación de la matriz de similitud léxica, el eje vertical representa las 5 clases encontradas y el eje
horizontal el número de elementos que pertenecen a la clase.
Las parejas que fueron clasificados (ids: 96, 109,147.99 y 106) como “correspondencias fuertes parciales” para la similitud léxica, son:
1. Motel-Motel 2. Hotel-Hotel 3. serviciosTuristicos-Servicio_Turistico 4. Motel-Hotel 5. Hotel-Motel
El resto de los elementos son clasificados como “correspondencias débiles parciales”. Por otro lado la pareja “Hostal-Entretenimiento” no pudo ser clasificada usando su similitud léxica. Los resultados para la similitud entre propiedades se obtuvieron 2 clases o categorías con las siguientes características:
• La primera contiene valores que en promedio su magnitud oscilan alrededor de 0.8973, esto quiere decir que se ha detectado un grupo de parejas de clase con alta similitud léxica (ver Figura 5.5).
• La segunda clase se agruparon valores cuya magnitud oscilan alrededor de 0.6455.
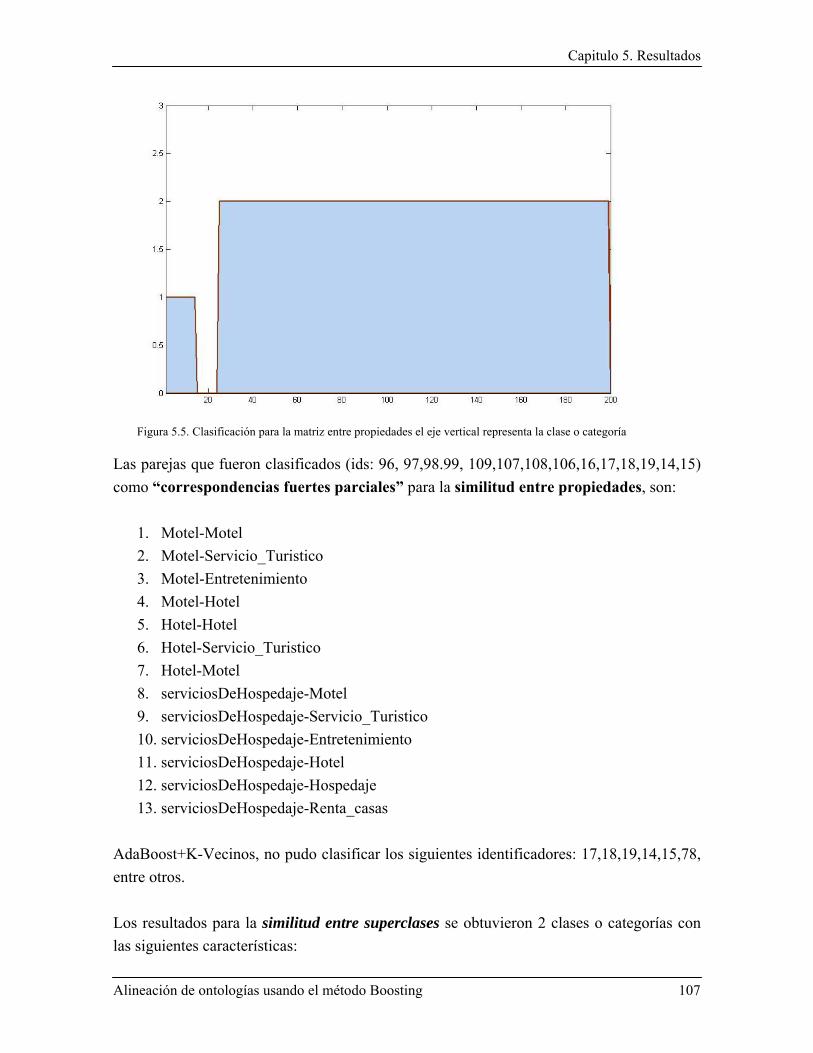
Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 107
Figura 5.5. Clasificación para la matriz entre propiedades el eje vertical representa la clase o categoría
Las parejas que fueron clasificados (ids: 96, 97,98.99, 109,107,108,106,16,17,18,19,14,15) como “correspondencias fuertes parciales” para la similitud entre propiedades, son:
1. Motel-Motel 2. Motel-Servicio_Turistico 3. Motel-Entretenimiento 4. Motel-Hotel 5. Hotel-Hotel 6. Hotel-Servicio_Turistico 7. Hotel-Motel 8. serviciosDeHospedaje-Motel 9. serviciosDeHospedaje-Servicio_Turistico 10. serviciosDeHospedaje-Entretenimiento 11. serviciosDeHospedaje-Hotel 12. serviciosDeHospedaje-Hospedaje 13. serviciosDeHospedaje-Renta_casas
AdaBoost+K-Vecinos, no pudo clasificar los siguientes identificadores: 17,18,19,14,15,78, entre otros. Los resultados para la similitud entre superclases se obtuvieron 2 clases o categorías con las siguientes características:
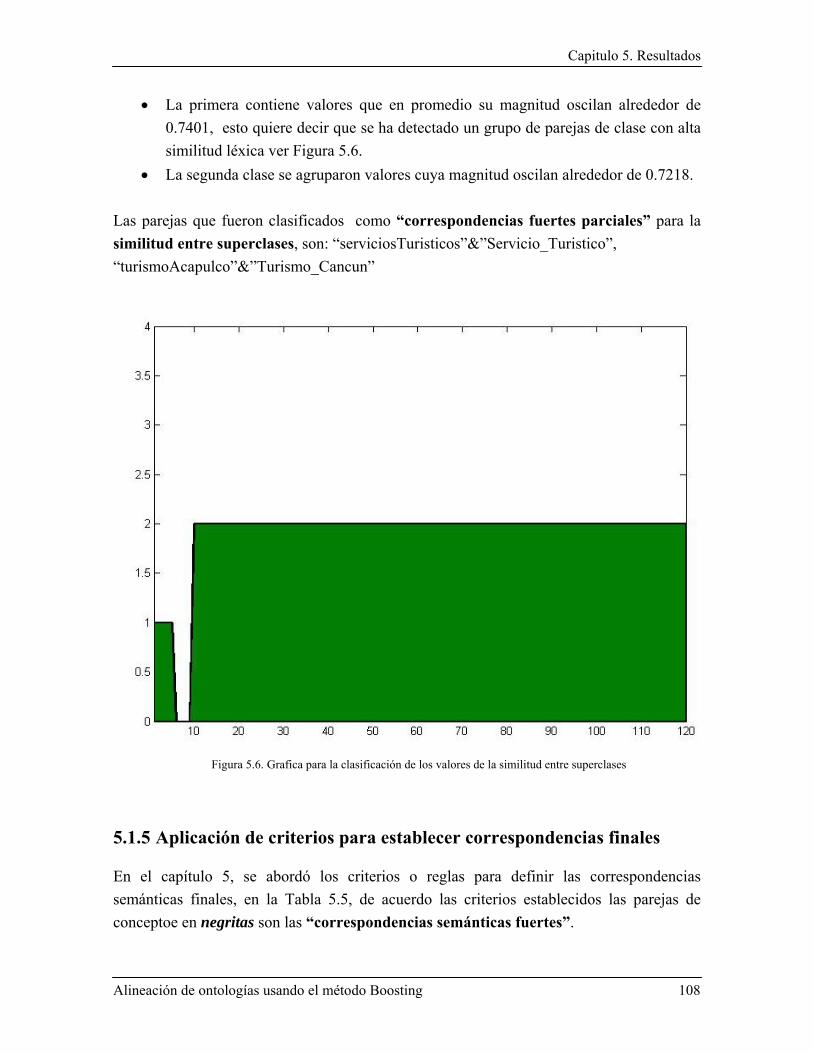
Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 108
• La primera contiene valores que en promedio su magnitud oscilan alrededor de 0.7401, esto quiere decir que se ha detectado un grupo de parejas de clase con alta similitud léxica ver Figura 5.6.
• La segunda clase se agruparon valores cuya magnitud oscilan alrededor de 0.7218. Las parejas que fueron clasificados como “correspondencias fuertes parciales” para la similitud entre superclases, son: “serviciosTuristicos”&”Servicio_Turistico”, “turismoAcapulco”&”Turismo_Cancun”
Figura 5.6. Grafica para la clasificación de los valores de la similitud entre superclases
5.1.5 Aplicación de criterios para establecer correspondencias finales
En el capítulo 5, se abordó los criterios o reglas para definir las correspondencias semánticas finales, en la Tabla 5.5, de acuerdo las criterios establecidos las parejas de conceptoe en negritas son las “correspondencias semánticas fuertes”.

Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 109
Tabla 5.5. Resultados finales sobre “correspondencias parciales fuertes” obtenidas desde AdaBoost+K-Vecinos
TIPO DE SIMILITUD PAREJAS
SIMILITUD LÉXICA
Motel-Motel Hotel-Hotel
serviciosTuristicos-Servicio_Turistico Motel-Hotel Hotel-Motel
SIMILITUD ENTRE
PROPIEDADES
Motel-Motel Motel-Servicio_Turistico Motel-Entretenimiento
Motel-Hotel Hotel-Hotel
Hotel-Servicio_Turistico Hotel-Motel
serviciosDeHospedaje-Motel serviciosDeHospedaje-Servicio_Turistico
serviciosDeHospedaje-Entretenimiento serviciosDeHospedaje-Hotel
serviciosDeHospedaje-Hospedaje serviciosDeHospedaje-Renta_casas
SIMILITUD ENTRE SUPERCLASES
serviciosTuristicos-Servicio_Turistico urismoAcapulco-Turismo_Cancun
5.1.6 Archivo XML de correspondencias
Con base a la aplicación de los criterios anteriores es posible visualizar el archivo XML que contiene las correspondencias semánticas: <uri_onto1 id=’1’>Acapulco </uri1_onto1> <uri_onto2 id=’2’> Cancun</uri2_onto2> <CorrespondenciasFuertes> <Pareja1> <entidad1 URI=Acapulco.hotel id=’1’> <entidad2 URI=Cancun.hotel id=’2’>

Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 110
<SimilitudGlobal>0.90</SimilitudGlobal> <relacion> “Correspondencia fuerte”</relacion> <entidad1 URI=Acapulco.motel id=’1’> <entidad2 URI=Cancun. motel id=’2’> <SimilitudGlobal>1.0</SimilitudGlobal> <relacion> “Correspondencia fuerte”</relacion> </Pareja1> </CorrespondenciasFuertes>
5.2 Resultados para OntoMashup
En el caso de búsquedas por nombre de hotel, Onto-Mashup, envía una página de resultados dividida en dos secciones: información geográfica y descriptiva, la primera muestra coordenadas geográficas (útiles en un GPS), y en la segunda presenta datos relevantes sobre el hotel buscado. Además, en el cliente web todos los hoteles encontrados son marcados en el mapa proporcionado por Google maps. De esta manera, se obtiene una vista integral con la información turística-geografica. En adicción, todos los hoteles encontrados son ubicados en el mapa proporcionado por Google maps. De esta forma, se proporciona una vista integral con la ubicación de cada hotel y la representación espacial del municipio de Acapulco.
5.2.1 Consultas relacionadas a las ontología de Cancún y Acapulco
A continuación, se presentan la interfaz general para realizar consultas a las ontologías, principalmente se muestra el acceso a la información contenida en la ontología de Acapulco, para tipo de búsquedas por nombre de hotel, ver Figura 5.7 y Figura 5.8 . El mecanismo de OntoMashup es simple, hasta el momento solo realiza los dos tipos de consulta mencionados, Esta misma interfaz de acceso, puede ser ocupada para explotar la información contenida en la ontología de Cancún. El propósito por el cual se planteó OntoMashup es plantear una arquitectura de sistema para mostrar la aplicación de la alineación de ontologías.
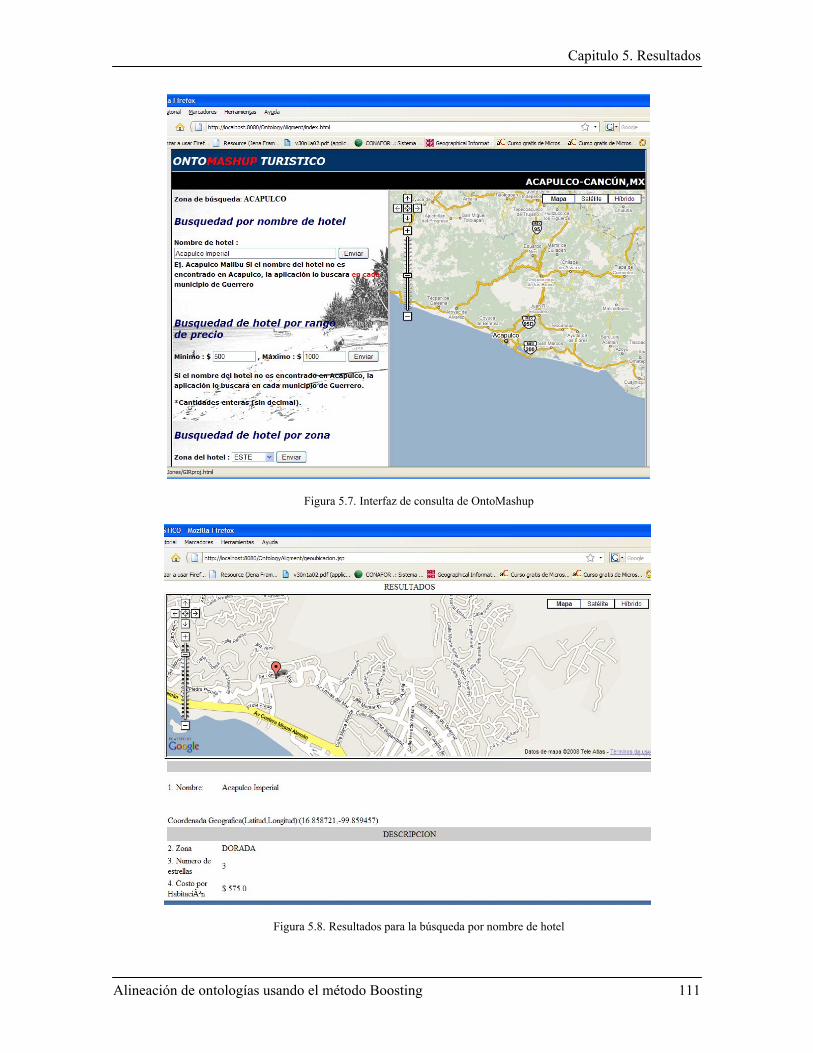
Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 111
Figura 5.7. Interfaz de consulta de OntoMashup
Figura 5.8. Resultados para la búsqueda por nombre de hotel

Capitulo 5. Resultados
Alineación de ontologías usando el método Boosting 112
5.3 Comentarios finales
Los resultados muestran el potencial de MatchBoost, su arquitectura puede ser mejorada a fin de obtener alineaciones más precisas, al final la participación del usuario se disminuye al solo validar los resultados. Por otro lado OntoMashup, ha demostrado una interfaz directa para realizar consultas simultáneas a dos ontologías turísticas. Finalmente, el Capítulo 6 se discuten las conclusiones y el trabajo a futuro.

Capitulo 6. Conclusiones
Alineación de ontologías usando el método Boosting 113
CAPÍTULO 6 : CONCLUSIONES Y TRABAJO A FUTURO En esta tesis se presentó un método para alineación de ontologías, implementado en una aplicación llamada MatchBoost, el cual integra un conjunto de medidas de similitud por medio del método Boosting. El objetivo es encontrar correspondencias semánticas entre dos ontologías. El uso de de un conjunto de medidas de similitud como un componente en los procesos de alineación, es necesario. El enfoque propuesto en esta tesis, radica en una selección adecuada de un conjunto de medidas de similitud, para que de forma general sus resultados sean sintetizados por Boosting, que para definir las correspondencias semánticas finales, se utilizan una serie de reglas que definen la importancia de cada medida de similitud. La dificulta para expresar la importancia de estas medidas, es un problema presente en los sistemas de alineación actuales; puesto que es posible, elegir una expresión numérica como los pesos o un conjunto de reglas más cercanas al entendimiento humano (el enfoque propuesto en esta tesis). Podemos concluir que la expresividad de la importancia de las medidas de similitud, es crucial para discernir entre la heterogeneidad de las ontologías alineadas, para explorar las descripciones de un concepto y decidir si tiene relación con otros conceptos. El análisis del estado del arte, también respalda este argumento. Boosting es visto como un mecanismo para optimizar el proceso de alineación e integrar resultados desde diferentes medidas de similitud. La idea de la integración consiste en agrupar adecuadamente valores de similitud en categorías que correspondan a su semántica implícita, ¿cuál es esa semántica?; las clases que agrupan los conceptos con mayor similitud entre sí. En este sentido Boosting es independiente y modular, es decir, puede ser probado con otro conjunto de medidas de similitud, la idea es que prevalezca la forma en cómo integra sus resultado. En otro aspecto, MatchBoost no depende del uso bases de datos léxicas como WordNet(ingles) y EuroWordNet (castellano), para encontrar las correspondencias semánticas, lo que permite que el enfoque propuesto no depende de fuentes de información relacionadas a cierto idioma. Sin embargo, puede ser útil el uso de estas fuentes para mejorar el proceso de búsqueda de coincidencias utilizando sinónimos.

Capitulo 6. Conclusiones
Alineación de ontologías usando el método Boosting 114
La alineación de ontologías, es un mecanismo que busca establecer interoperación entre fuentes de datos heterogéneas, como las ontologías. Nuestro caso de aplicación es una forma de integrar información turística por medio de MatchBoost, que puede ser visto como un mecanismo de interoperación semántica entre ontologías, es decir, una forma de poder intercambiar información desde una ontología hacia otra. Finalmente, se puede decir que la intervención del usuario en el proceso de alineación aun es requerida. En el caso de MatchBoost solo se requiere su intervención en la validación de los resultados finales.
6.1.1 Contribuciones
Las contribuciones que esta tesis ha realizado, pueden ser sintetizadas en los siguientes aspectos:
• Definición de un conjunto de medidas de similitud, que explota la sintaxis de las clases, su propiedades y la ubicación de las superclases con respecto a la jerarquía de cada ontología. Formalmente, métodos de similitud basados en cadenas para la similitud entre nombres y propiedades, y un método de análisis básico estructural (similitud entre superclases).
• Un método de alineación de ontologías basado en Boosting, que integra la sinergia del conjunto de medidas de similitud. Es decir, combinación de medidas de similitud por medio de AdaBoost+K-Vecinos y criterios de integración.
• Definición de reglas para encontrar correspondencias semánticas finales, basada en la interpretación humana.
• Una arquitectura de sistema de alineación de ontologías, modular y escalable
6.1.2 Limitaciones
• Considerar aspectos como el tipo de relación entre clases y axiomas, como información adicional para el proceso de alineación. No se considero el procesamiento de ontologías de tamaño grande.
• Se requieren de más medidas de similitud estructural. • Explotar mas el uso de la sintaxis de OWL, como tipo de datos entre propiedades,
etc.

Capitulo 6. Conclusiones
Alineación de ontologías usando el método Boosting 115
6.1.3 Trabajo a futuro
• Integrar otras medidas de similitud semántica y de similitud estructural: como similarity flooding, GMO, y otras definidas por los sistemas de alineación (ver capítulo 2) validados por la OAEI.
• Realizar una evaluación de otras medidas de similitud (de tipo léxica y estructural) por medio del método Boosting
• Diseñar un mecanismo para procesar ontologías de mayor escala, dividiendo cada ontología para comparar extractos de ambas ontologías, similar a la estrategia utilizada por Falcon-OA.
• Integrar a MatchBoost una base de datos léxico-conceptual como WordNet o EuroWordNet, la cual esté involucrada directamente con el proceso para establecer correspondencias, al explotar relaciones de sinonimia entre los concepto; por tanto, la detección de sinonimia entre dos concepto ya no solo dependería de análisis léxico al nombre de las clases, si no que estaría repaldado por el conocimiento sobre el idioma de las ontologías.
• Integrar con AdaBoost algoritmos de alineación validados por la OAEI
• Probar otros algoritmos de aprendizaje automático como redes neuronales o redes bayesianas.
• Explorar otras variaciones actuales de los algoritmos tipo Boosting.
• A fin de mejorar la precisión de los resultados, es necesario proporcionar significado a todas las clases obtenidas por K-Vecinos.
• Extender las capacidades de OntoMashup, de tal manera que sea autoconfigurable al recibir el archivo XML de correspondencias.
• Extender las consultas de OntoMashup para explotar las propiedades de las clases y plantear consultas como: “Hoteles en Cancún y Acapulco con habitaciones de lujo y restaurantes”.

Referencias
Alineación de ontologías usando el método Boosting 116
REFERENCIAS
(Alexiev, et al., 2004) 1. Alexiev, V., Breu, M.; Bruijn, J.; Fensel, D.; Lara, R.; Holger, L. Information Integration with
Ontologies: Experiences from an Industrial Showcase. (ed.) Wiley. 2004. (Anderson, 1958)
2. Anderson J. R. An Introduction to Multivariate Statiscal Analysis, (ed.) John Wiley, 1958. (Berners-Lee, et al., 2001)
3. Berners-Lee J., Hendler J. & Lassila O. The Semantic Web. Scientific American. Vol. 184, 2001. (Bishop, 2007)
4. Bishop, C., M. Pattern Recognition and Machine Learning. (ed.) Springer, 2007. (Boosting.org, 2002)
5. Boosting.org, Boosting 2002. URL: http://www.boosting.org/. (Cai, et al., 2003)
6. Cai, L. & Hofmann, T. Text Categorization by Boosting Automatically Extracted Concepts. Conference on Research and Development in Information Retrieval (SIGIR). Proceedings of the 26th Annual International ACM SIGIR. Toronto, Canada, 2003.
(Caracciolo, et al., 2008) 7. Caracciolo, C., Euzenat, J., Hollink, L., & Ichise, R. First results of the Ontology Alignment
Evaluation Initiative 2008. The Third International Workshop on Ontology Matching. Proceedings. Karlsruhe, Germany, 2008.
(Cardoso, 2006) 8. Cardoso J. E-Tourism: Creating Dynamic Packages using Semantic Web Processes. W3C
Workshop on Frameworks for Semantics in Web Service . 2006. (Chen, 2008)
9. Chen Harry. Geospatial Semantic Web. URL: http://www.geospatialsemanticweb.com/. (Cocchiarella, 1991)
10. Cocchiarella N. B. Formal Ontology. Handbook of Metaphysics and Ontology. Philosophia, (ed.) Springer-Verlag. Munich , 1991.
(Corcho, et al., 2003) 11. Corcho O., Fernández M. & Gómez A. Methodologies, tools and languages for building
ontologies. Where is their meeting point? Data Knowledge Eng. Amsterdam. The Netherlands, 2003.
(Cruz, et al., 2007) 12. Cruz, I. F., Sunna, W., Makar, N., & Bathala, S. A Visual Tool for Ontology Alignment to
Enable Geospatial Interoperability. Journal of Visual Languages and Computing. 2007. (Duda, et al., 2002)
13. Duda Richard, Hart Peter & Stork David Pattern Classification. WWW Line Available, 2002. (Egenhofer, 2002)
14. Egenhofer M. J. Toward the Semantic Geospatial Web. Proceedings of the Tenth ACM International Symposium on. McLean. Virginia, 2002.
(El-Yaniv's, 2008) 15. El-Yaniv's Ran Classification Applet.
URL=http://www.cs.technion.ac.il/~rani/LocBoost/index.html. (Euzenat, et al., 2006)
16. Euzenat, J., Shvaiko, M., Stuckenschmidt, H., Šváb, O. & Svátek, V. Results of the Ontology Alignment Evaluation Initiative 2006. Ontology Matching. Georgia, USA, 2006.
(Euzenat, et al., 2004a) 17. Euzenat J. & Loup D. Ontology Alignment with OL. Proceedings of the 3rd EON Workshop. -
Hiroshima (JP). 2004. (Euzenat, et al., 2004b)
18. Euzenat J. & Shvaiko A. State of the art on ontology alignment. KnoledgeWeb Consortium, 2004. URL: http://knowledgeweb.semanticweb.org/semanticportal/deliverables/D2.2.3.pdf

Referencias
Alineación de ontologías usando el método Boosting 117
(Euzenat, 2005) 19. Euzenat J. Specification of a benchmarking methodology for alignment techniques. KnoledgeWeb
Consortium, 2005. (Euzenat, et al., 2006)
20. Euzenat J. Specification of the delivery alignment format, Knowledge Web, 2006. (Euzénat, et al., 2003). URL= http://knowledgeweb.semanticweb.org/semanticportal/deliverables/D2.2.2.pdf.
21. Euzénat J., Remize M. & Ochanine H. Projet Hi-Touch: Le web sémantique au secours du tourisme. Hélène Ochanine, W3C.Archimag, 2003.
(Euzenat, et al., 2007) 22. Euzenat J.& Shvaiko P. Ontology Matching . (eds.) Springer-Verlag, Berlin Heidelberg, 2007.
(Euzenat, 2006a) 23. Euzenat Jérome An API for ontology alignment. The Semantic Web Conference. (ed.) Springer.
Berlin, 2006. URL= http://alignapi.gforge.inria.fr/. (Floridi, 2005)
24. Floridi Luciano Is Information Meaningful Data?. Philosophy and Phenomenological Research, (eds.) Oxford University. 2005.
(Fonseca, et al., 2002) 25. Fonseca, F., Egenhofer, M., Agouris, P. & Camara, G. Using Ontologies for Integrated
Geographic Information Systems. Transactions in GIS. 2002. (Freund, et al., 1999)
26. Freund Y & Schapire R. E. A Short Introduction to Boosting . Journal of Japanese Society for Artificial Intelligence. Japan , 1999.
(Freund, et al., 1996) 27. Freund Y. & Schapire R. E. Experiments with a new boosting algorithm. In Machine Learning
International Conference in Machine Learning: Proceedings of the Thirteenth International Conference, 1996.
(Freund, et al., 2003) 28. Freund Y., Iyer R. E. & Schapire R. An effcient boosting algorithm for combining preferences.
Journal of Machine Learning Research. 2003. (Geonames, 2006)
29. Geonames. URL: http://www.geonames.org. (Gruber, 1993)
30. Gruber T. R. A translation approach to portable ontology specifications. Knowl. Acquis. - London, UK, 1993.
(Google maps, 2004) 31. Google maps URL: http://maps.google.com/.
(Gruber, 1993) 32. Gruber T. R. A translation approach to portable ontology specifications. Knowl. Acquis. London,
UK, 1993. (Gruber, 1995)
33. Gruber T. R. Toward principles for the design of ontologies used for knowledge sharing. Int. J. Hum.-Comput. 1995.
(Guarino, 1992) 34. Guarino N. Formal Ontology and Information Systems. Formal Ontology in Information
Systems. Amsterdam, Netherlands, 1992. (Guarino, 1998)
35. Guarino N. Formal Ontology and Information Systems. Formal Ontology in Information Systems. - Amsterdam,Netherlands. : Formal Ontology in Information Systems, 1998.
(Guarino, 1995) 36. Guarino N. Ontologies and knowledge bases: towards a terminological. Towards Very Large
Knowledge Bases, Knowledge Building and Knowledge Sharing. IOS Press. Amsterdam, 1995.

Referencias
Alineación de ontologías usando el método Boosting 118
(Hart, et al., 1967) 37. Hart P. & Cover T. Nearest Neighbor Pattern Classification. IEEE Trans. on Information
Theory. 1967. (Hepp, et al., 2006)
38. Hepp Martin & Siorpaes Katharina Towards the Semantic Web in e-Tourism: Lack of Semantics or Lack of Content? ESWC 2006. Vol. Poster Session.
(Herbrich, et al., 2000) 39. Herbrich R., Graepel T. & Obermayer K. Large Margin rank boundaries for ordinal
regression. MIT Press. Cambridge, MA, 2000. (Hochmair, 2005)
40. Hochmair H. H. Ontology Matching for Spatial Data Retrieval From Internet Portals. First Interntational Conference, GeoS 2005. (eds.) Springer-Verlag. Mexico City, 2005.
(imagineit, 2006) 41. imagineit Imagine it project. URL: http://www.imagineit-eu.com/.
(ISO, 2008) 42. ISO ISO 704:2000.
URL:http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=31696. (Jena, 2006)
43. Jena. Jena A Semantic Web Framework for Java. URL=http://jena.sourceforge.net/. (Jeong, et al., 2008)
44. Jeong, B., Lee, D., Cho, H, & Lee, J. A novel method for measuring semantic similarity for XML schema matching. Expert Systems with Applications: An International Journa. - NY, USA, 2008.
(Jian, et al., 2005) 45. Jian Ningsheng [et al.]. Falcon-AO: Aligning Ontologies with Falcon. Workshop on Integrating
Ontologies. - 2005. (Kayak, 2008)
46. Kayak. URL= http://www.kayak.com. (Li, et al., 2008)
47. Li Juanzi & Tang Jie. RiMOM. IEEE Transactions on Knowledge and Data Engineering. - 2008. (Liddell, et al., 1996)
48. Liddell Henry George & Scott Robert Semantikos. A Greek-English Lexicon. 1996 : (McIlraith, et al., 2001)
49. McIlraith Sheila A., Cao Tran & Zeng Honglei Semantic Web Services. IEEE Intelligent Systems. Stanford University.
(Melnik, et al., 2001) 50. Melnik S., Garcia-Molina H. & Erhard R. Similarity Flooding: A Versatile Graph Matching
Algorithm. Stanford. 2001. (Miller, et al., 1993)
51. Miller George A., Beckwith R. & Fellbaum C. Introduction to WordNet: An On-line Lexical Database, Introduction to WordNet: an on-line lexical database. International Journal of Lexicography. 1993.
(Missikoff, et al., 2003) 52. Missikoff M. Harmonise: an Ontology-Based Approach for Semantic Interoperability 2002.
(Missikoff, et al., 2003) 53. Missikoff M., Werthner H. & Hopken W. Harmonise – Towards Interoperability in the Tourism
Domain. Proceedings of the 10th International Conference on Information and Communications Technologies in Travel&Tourism. Filand, 2003.
(Mitchell, 1997) 54. Mitchell Thomas Machine Learning. McGraw Hill Higher Education, 1997.
(Moore, 1992) 55. Moore A. Fast Robust Adaptive Control by Learning Only Forward Models. Advances in Neural
Information Processing Systems. - San Francisco, 1992. (Morales-Manzanares, 2008)

Referencias
Alineación de ontologías usando el método Boosting 119
56. Morales-Manzanares E. F. Ensambles de Clasificadores, Escalamiento, Muestreo y Selección de Atributos. URL=http://ccc.inaoep.mx/~emorales/Cursos/KDD03/node52.html.
(NASA, 2008) 57. NASA Semantic Web for Earth and Environmental Terminology.
URL= http://sweet.jpl.nasa.gov (Neches, et al., 1991)
58. Neches, R., Fikes, R. E., Finin, T., Gruber, T. R., T., Senator & Swartout, W. R. Enabling technology for knowledge sharing. AI Magazine. Kluwer Academic Publishers, 1991.
(Nilsson, 1996) 59. Nilsson Nils J. Introduction to Machine Learning. Stanford University, 1996.
URL= http://robotics.stanford.edu/~nilsson/MLDraftBook/MLBOOK.pdf (Noy, et al., 1999)
60. Noy N. F. & Musen M. A. An algorithm for merging and aligning ontologies: Automation and tool support. Workshop on Ontology Management at the Sixteenth National Conference on Artificial Intelligence. - Stanford, CA : AAAI Press, 1999.
(Noy, et al., 2005) 61. Noy Natalya F. & McGuinness Deborah L. Desarrollo de Ontologías-101: Guía Para Crear Tu
Primera Ontología. Stanford University, 2005. (OAEI, 2004)
62. OAEI Ontology Alignment Evaluation Initiative 2007. URL=http://oaei.ontologymatching.org/. (OGC, 2007)
63. OGC OGC Web Services 2007. URL=http://www.opengeospatial.org/projects/initiatives/ows-2.
(Open Geospatial Consortium, 2006) 64. Open Geospatial Consortium Geospatial Semantic Web Interoperability Experiment Report, OGC,
2006. (OWL, 2004)
65. OWL. OWL Web Ontology Language 2004. URL= http://www.w3.org/TR/owl-features/. (programmableweb, 2008)
66. Programmableweb. programmableweb 2008. URL= http://www.programmableweb.com/tag/travel.
(Programme, 2006) 67. Programme The Sixth Framework. The Sixth Framework Programme, European Commision
URL=http://ec.europa.eu/research/fp6/index_en.cfm. (Protégé, 2006)
68. Protégé. Protégé 2006. URL=- http://protege.stanford.edu/. (Rahm, et al., 2001)
69. Rahm Erhard & Bernstein Philip A. A survey of approaches to automatic schema matching.The VLDB Journal. Springer-Verlag, 2001.
(Rodríguez, et al., 2003) 70. Rodríguez M. A. & Egenhofer. M. J. Determining Semantic Similarity among Entity Classes from
Different Ontologies. IEEE Transactions on Knowledge and Data Engineering. 2003. (Schapire, 1999)
71. Schapire R. E. Improved boosting algorithms using confidence-rated predictions. Mach. Learn. - 1999.
(seccion amarilla, 2008) 72. Seccionamarilla 2008. URL= http://www.seccionamarilla.com.mx/.
(Sheldon, 1998) 73. Sheldon P. J. Tourism Information Technology. (ed.) CABI , 1998.
(Singh, et al., 2002) 74. Singh I. & Stearns B. Designing Enterprise Applications with the J2EE Platform. (ed.) Addison-
Wesley, 2002. (Staab, et al., 2004)

Referencias
Alineación de ontologías usando el método Boosting 120
75. Staab Steffen & Studer Rudi Handbook of ontologies. Berlin : International handbooks on information systems. (eds.) Springer Verlag, 2004.
(Stojanovic, et al., 2004) 76. Stojanovic L., J. Schneider & Maedche A. The role of ontologies in autonomic computing
systems. IBM SYSTEMS JOURNAL. 2004. (Sunna, et al., 2007)
77. Sunna W. & Cruz I. Structure-based Methods to Enhance Geospatial Ontology Alignment. GEOS 2007. Springer. MEXICO, 2007.
(Tomlinson, 2000) 78. Tomlinson Roger. Thinking About GIS: Geographic Information System Planning For Managers.
(eds.) ESRI Press, 2000. (Torres, 2007)
79. Torres M. Phd. Thesis: Phd. Thesis: "Representación ontológica basada en descriptores semánticos aplicada a objetos geográficos". - Mexico City : CIC-IPN, 2007.
(Tsou, et al., 2003) 80. Tsou Ming-hsiang Tsou & Peng Zhong-Ren. Internet GIS: Distributed Geographic Information
Services for the Internet. John Wiley and Sons, 2003. (Varelas, et al., 2005)
81. Varelas, G., E., Voutsakis, P., Raftopolou, E., Petrakis & E., Milios Semantic similarity methods in WordNet and their application to information retrieval on the web. Proceedings of the 7th annual ACM international workshop on Web information and data management. Bremen, Germany , 2005.
(W.N. Borst, 1997) 82. W.N. Borst W. N. Construction of Engineering Ontologies. PhD Thesis, University of Tweenty,
Enschede, NL. - Centre for Telematica and Information Technology . 1997. (W3C, 2004)
83. W3C. OWL-S: Semantic Markup for Web Services . URL= http://www.w3.org/Submission/OWL-S/.
(OWL, 2004) 84. W3C. OWL Web Ontology Language 2004. URL=http://www.w3.org/TR/owl-features/.
(SPARQL, 2004) 85. W3C. Web Semántica. Guias breves de la Web
Semántica. URL=http://www.w3c.es/Divulgacion/Guiasbreves/WebSemantica. (W3C, 2002)
86. W3C Web Services. URL= http://www.w3.org/2002/ws/. (Worboys, et al., 2004)
87. Worboys & Duckham GIS: A Computing Perspective. Second Edition. (ed.) CRC Press, 2004. (WTO, 2006)
88. WTO. World Tourism Organization. Tourism 2020 Vision, 2006. URL= http://www.unwto.org/facts/eng/vision.htm.
(Xu, et al., 2007) 89. Xu Jun & Hang Li. AdaRank: A Boosting Algorithm for Information Retrieval, SIGIR 2007.
Amsterdam, 2007. (Yahoo, 2008)
90. Yahoo. Yahoo Travel. URL=http://travel.yahoo.com. (Yee, 2005)
91. Yee R. Pro Web 2.0 mashups : remixing data and Web services, (ed.) Apress, 2005. (Zhang, et al., 2004)
92. Zhang Dell & Sun Wee Web Taxonomy Integration through Co-Bootstrapping. SIGIR 2004. South Yorkshire, 2004.

Anexos
Alineación de ontologías usando el método Boosting 121
Anexos Consultas al modelo: CargaConocimiento package gis; import java.io.IOException; import java.io.Reader; import java.io.StringReader; import java.util.Iterator; import java.util.List; import java.util.Vector; import org.geonames.Toponym; import org.geonames.ToponymSearchCriteria; import org.geonames.ToponymSearchResult; import org.geonames.WebService; import org.jdom.Document; import org.jdom.Element; import org.jdom.JDOMException; import org.jdom.input.SAXBuilder; import com.hp.hpl.jena.ontology.OntClass; import com.hp.hpl.jena.ontology.OntModel; import com.hp.hpl.jena.ontology.OntModelSpec; import com.hp.hpl.jena.query.Query; import com.hp.hpl.jena.query.QueryExecution; import com.hp.hpl.jena.query.QueryExecutionFactory; import com.hp.hpl.jena.query.QueryFactory; import com.hp.hpl.jena.query.ResultSet; import com.hp.hpl.jena.query.ResultSetFormatter; import com.hp.hpl.jena.rdf.model.ModelFactory; import com.hp.hpl.jena.util.FileManager; import com.hp.hpl.jena.util.iterator.ExtendedIterator; public class CargarConocimiento { OntModel modelAcapulco; OntModel modelCancun; int espacios=0; Vector jerarquia=new Vector(); public CargarConocimiento(){ iniciar_jenaontologias("file:///C:/Documents%20and%20Settings/Gerardo/workspace1/OntologyAligment/src/owlAcapulco/acapulco2.owl", "file:///C:/Documents%20and%20Settings/Gerardo/workspace1/OntologyAligment/src/owlAcapulco/OntologiaCancun.owl"); } public static void main(String arg[]){ CargarConocimiento aux = new CargarConocimiento(); //aux.iniciar_jenaontologias("file:///C:/Documents%20and%20Settings/Gerardo/workspace1/OntologyAligment/src/owlAcapulco/acapulco2.owl", "file:///C:/Documents%20and%20Settings/Gerardo/workspace1/OntologyAligment/src/owlAcapulco/OntologiaC

Anexos
Alineación de ontologías usando el método Boosting 122
ancun.owl"); //aux.getHotelesZona("ESTE"); aux.getHotelesNombre("Acapulco Imperial"); //aux.getHotelesPrecioCancun("10","13"); //new CargarConocimiento().getHotelesNombre("Acapulco Malibu"); //aux.getHotelesZonaCancun("Zona Cancun"); } public void iniciar_jenaontologias(String uri1, String uri2){ this.modelAcapulco = ModelFactory.createOntologyModel(OntModelSpec.OWL_MEM_RULE_INF ); // crear un modelo utilizando como razonador OWL_MEM_RULE_INF this.modelAcapulco.read(uri1); this.modelCancun = ModelFactory.createOntologyModel(OntModelSpec.OWL_MEM_RULE_INF ); // crear un modelo utilizando como razonador OWL_MEM_RULE_INF this.modelCancun.read(uri2); } public void cerrarConexion() throws IOException{ modelAcapulco.close(); modelCancun.close(); } public Vector getHotelesPrecio(String minimo, String maximo){ Vector result; String queryString = "PREFIX table: <http://www.owl-ontologies.com/hoteles.owl#>"+ "SELECT ?nombreHotel ?nombreZona ?numEstrellas ?costoHabitacion "+ "FROM <http://www.owl-ontologies.com/hoteles.owl>"+ "WHERE {"+ " ?Hotel table:nombreHotel ?nombreHotel; "+ " table:nombreZona ?nombreZona; "+ " table:numEstrellas ?numEstrellas; "+ " table:costoHabitacion ?costoHabitacion. "+ " FILTER (?costoHabitacion>=100&&?costoHabitacion<=500)"+ "}"; Query query = QueryFactory.create(queryString); QueryExecution qe = QueryExecutionFactory.create(query, this.modelAcapulco); try{ ResultSet results = qe.execSelect(); String aux=ResultSetFormatter.asXMLString(results); System.out.println(aux); ResultSetFormatter.out(results, query); result=getInfoFromXML(aux); } finally { qe.close() ; } return result; } public Vector getHotelesPrecioCancun(String minimo, String maximo){ Vector result; String queryString = "PREFIX table: <http://www.owl-ontologies.com/Ontology1218472055.owl#>"+ "SELECT ?Nombre_Hotel ?Zona ?Numero_estrellas ?Costo"+ "FROM <http://www.owl-ontologies.com/Ontology1218472055.owl>"+

Anexos
Alineación de ontologías usando el método Boosting 123
"WHERE {"+ "?Hotel"+ "table:Nombre_Hotel?Nombre_Hotel;"+ "table:Zona ?Zona;"+ "table:Numero_estrellas?Numero_estrellas;"+ "table:Costo ?Costo;"+ "FILTER (?Costo>2000&&?Costo<4000)"+ "}"; Query query = QueryFactory.create(queryString); QueryExecution qe = QueryExecutionFactory.create(query, this.modelCancun); try{ ResultSet results = qe.execSelect(); String aux=ResultSetFormatter.asXMLString(results); System.out.println(aux); ResultSetFormatter.out(results, query); result=getInfoFromXML(aux); } finally { qe.close() ; } return result; } public Vector getHotelesNombre(String nombre){ Vector result=new Vector(); String queryString = "PREFIX table: <http://www.owl-ontologies.com/hoteles.owl#>"+ "SELECT ?nombreHotel ?nombreZona ?numEstrellas ?costoHabitacion "+ "FROM <http://www.owl-ontologies.com/hoteles.owl>"+ "WHERE {"+ " ?Hotel table:nombreHotel ?nombreHotel;"+ " table:nombreZona ?nombreZona;"+ " table:numEstrellas ?numEstrellas;"+ " table:costoHabitacion ?costoHabitacion."+ " FILTER (?nombreHotel='"+nombre+"')"+ "}"; Query query = QueryFactory.create(queryString); QueryExecution qe = QueryExecutionFactory.create(query, this.modelAcapulco); try{ ResultSet results = qe.execSelect(); String aux=ResultSetFormatter.asXMLString(results); System.out.println(aux); ResultSetFormatter.out(results, query); result=getInfoFromXML(aux); } finally { qe.close() ; } return result; } public Vector getHotelesNombreCancun(String nombre){ Vector result=new Vector(); String queryString =

Anexos
Alineación de ontologías usando el método Boosting 124
"PREFIX table: <http://www.owl-ontologies.com/Ontology1218472055.owl#>"+ "SELECT ?Zona ?Numero_estrellas ?Costo "+ "FROM <http://www.owl-ontologies.com/Ontology1218472055.owl>"+ "WHERE { ?Hotel"+ //"table:Nombre_Hotel?Nombre_Hotel;"+ "table:Zona ?Zona; "+ "table:Numero_estrellas?Numero_estrellas;"+ "table:Costo ?Costo;"+ // "FILTER (?Zona='"+nombre+"')"+ "}"; Query query = QueryFactory.create(queryString); QueryExecution qe = QueryExecutionFactory.create(query, this.modelCancun); try{ ResultSet results = qe.execSelect(); String aux=ResultSetFormatter.asXMLString(results); System.out.println(aux); ResultSetFormatter.out(results, query); result=getInfoFromXML(aux); } finally { qe.close() ; } return result; } public Vector getHotelesZona(String zona){ Vector result=new Vector(); String queryString = "PREFIX table: <http://www.owl-ontologies.com/hoteles.owl#>"+ "SELECT ?nombreHotel ?nombreZona ?numEstrellas ?costoHabitacion "+ "FROM <http://www.owl-ontologies.com/hoteles.owl>"+ "WHERE {"+ " ?Hotel table:nombreHotel ?nombreHotel;"+ " table:nombreZona ?nombreZona;"+ " table:numEstrellas ?numEstrellas;"+ " table:costoHabitacion ?costoHabitacion."+ " FILTER (?nombreZona='"+zona+"')"+ "}"; Query query = QueryFactory.create(queryString); QueryExecution qe = QueryExecutionFactory.create(query, this.modelAcapulco); try{ ResultSet results = qe.execSelect(); String aux=ResultSetFormatter.asXMLString(results); System.out.println(aux); ResultSetFormatter.out(results, query); result=getInfoFromXML(aux); } finally { qe.close() ; } return result; } public Vector getHotelesZonaCancun(String zona){

Anexos
Alineación de ontologías usando el método Boosting 125
Vector result=new Vector(); String queryString = "PREFIX table: <http://www.owl-ontologies.com/Ontology1218472055.owl#hote>"+ "SELECT ?Nombre_Hotel ?Zona ?Numero_estrellas ?Costo"+ "FROM <http://www.owl-ontologies.com/Ontology1218472055.owl>"+ "WHERE {"+ "?Hotel table:Nombre_Hotel?Nombre_Hotel;"+ "table:Zona ?Zona;"+ "table:Numero_estrellas?Numero_estrellas;"+ "table:Costo ?Costo;"+ "FILTER (?Zona='"+zona+"')"+ ")"; Query query = QueryFactory.create(queryString); QueryExecution qe = QueryExecutionFactory.create(query, this.modelCancun); try{ ResultSet results = qe.execSelect(); String aux=ResultSetFormatter.asXMLString(results); System.out.println(aux); ResultSetFormatter.out(results, query); result=getInfoFromXML(aux); } finally { qe.close() ; } return result; } public Vector getSuperClases2(String uri_string){ Vector tempv=new Vector(); OntClass pruebaclass1=this.modelAcapulco.getOntClass(uri_string); ExtendedIterator a=pruebaclass1.listSuperClasses(false); while(a.hasNext()){ OntClass clase=(OntClass)a.next(); tempv.add(clase.getURI()); Object tempnull=tempv.lastElement(); if(tempnull==null){ tempv.remove(tempnull); } } return tempv; } public Vector getInfoFromXML(String MyXML){ Document xmlDoc = ConvertStringToXML(MyXML); Element root=xmlDoc.getRootElement(); List hijosdeRoot=root.getChildren(); Vector valores=new Vector(); Element resultados=(Element)hijosdeRoot.get(1); List resultadosRecordset=resultados.getChildren(); System.out.println(resultados.getName()); for(int i=0; i<resultadosRecordset.size();i++){

Anexos
Alineación de ontologías usando el método Boosting 126
Element result=(Element)resultadosRecordset.get(i); List binding = result.getChildren(); infogeograficaTO data = new infogeograficaTO(); data.setNombre(((Element)binding.get(0)).getValue()); data.setZona(((Element)binding.get(1)).getValue()); data.setNumEstrellas(((Element)binding.get(2)).getValue()); data.setCostoHabitacion(((Element)binding.get(3)).getValue()); valores.add(data); } return valores; } public Vector ProcesaRespuestaXML(String MyXML) { Document xmlDoc = ConvertStringToXML(MyXML); Element root=xmlDoc.getRootElement(); List hijosdeRoot=root.getChildren(); Vector valores=new Vector(); Element resultados=(Element)hijosdeRoot.get(1); List resultadosRecordset=resultados.getChildren(); System.out.println(resultados.getName()); for(int i=0; i<resultadosRecordset.size();i++){ Element result=(Element)resultadosRecordset.get(i); List binding = result.getChildren(); Element literal =(Element)binding.get(0); valores.add(literal.getValue()); } return valores; } public Document ConvertStringToXML(String xmlresultado) { SAXBuilder saxBuilder=new SAXBuilder("org.apache.xerces.parsers.SAXParser"); Reader stringReader=new StringReader(xmlresultado); Document jdomDocument=null; try { jdomDocument = saxBuilder.build(stringReader); } catch (JDOMException e) { System.out.println("Error grave en JDOM al convertir de String a XML(webservice), funcion: extraerXMLresultados. INTENTE MAS TARDE"); System.out.println("Error grave en JDOM al convertir de String a XML(webservice), funcion: extraerXMLresultados"); e.printStackTrace(); } catch (IOException e){ System.out.println("Error en flujo de datos:");e.printStackTrace(); System.out.println("Error en flujo de datos: Intente más tarde"); } return jdomDocument; } void PrintVector(Vector temp){ for(int i=0; i<temp.size();i++){ System.out.println("---------------------------------");

Anexos
Alineación de ontologías usando el método Boosting 127
System.out.println("Consultado: "+temp.get(i).toString()); System.out.println("---------------------------------"); } } public String explora(OntClass pruebaclass, int saltos, String NameSuperClass){ //Answer a class that is the sub-class of this class. If there is more than one such class, an arbitrary selection is made. If there is no such class, return null. int numhermanos=1; String subClass=" "; saltos++; ExtendedIterator axu= pruebaclass.listSubClasses(true); while(axu.hasNext( )) { OntClass tt=(OntClass)axu.next(); generalClass currentClass= new generalClass(); subClass=currentClass.name_class=tt.getLocalName(); currentClass.super_classname=NameSuperClass; jerarquia.add(currentClass); for(int j=1; j<=saltos;j++)System.out.print(" "); System.out.print(tt.getLocalName()+"-"+numhermanos); System.out.println(" "); currentClass.sub_classname= explora(tt,saltos,tt.getLocalName());; numhermanos++; } return NameSuperClass; } public void print(Vector temp){ for(int i=0; i<temp.size();i++){ System.out.println(" URL: "+temp.get(i)); } } } class generalClass{ String name_class; String super_classname; String sub_classname; int profundida; } Clase de procesamiento: infogeograficaBO package gis; import java.util.Enumeration; import java.util.List; import java.util.Vector; import javax.servlet.http.HttpServletRequest; import org.geonames.Toponym;

Anexos
Alineación de ontologías usando el método Boosting 128
import org.geonames.ToponymSearchCriteria; import org.geonames.ToponymSearchResult; import org.geonames.WebService; public class infogeograficaBO { parametrosGenerales param1=new parametrosGenerales(); CargarConocimiento consultas = new CargarConocimiento(); public infogeograficaBO(HttpServletRequest request, int forward){ this.param1.tipooperacion=Integer.parseInt(request.getParameter("idOper1")); switch(forward){ case 1: this.param1.setNombrehotel(request.getParameter("nombrehotel")); break; case 2: this.param1.setPreciomin(request.getParameter("preciomin")); this.param1.setPreciomax(request.getParameter("preciomax")); break; case 3: this.param1.setNombrezona(request.getParameter("nombrezona")); break; } } public void geonamesDataPlace(String place, infogeograficaTO datos){ boolean conCoordenadad=false; ToponymSearchCriteria searchCriteria = new ToponymSearchCriteria(); searchCriteria.setQ(place); //searchCriteria.setName("Acapulco"); searchCriteria.setCountryCode("MX"); searchCriteria.setAdminCode1("12"); //searchCriteria.setAdminCode2("12001"); ToponymSearchResult searchResult; try{ searchResult = WebService.search(searchCriteria); for (Toponym toponym : searchResult.getToponyms()){ //datos.setNombre(toponym.getName()); datos.setPais(toponym.getCountryName()); datos.setLatitud(toponym.getLatitude()); datos.setLongitud(toponym.getLongitude()); datos.setNamealternativo(toponym.getAlternateNames()); //this.datosq1.setTipooperacion(Integer.parseInt()); datos.setStatus("Edificio encontrado."); conCoordenadad=true; } if(conCoordenadad==false){ datos.setStatus("No se encontro la coordenada"); } datos.print(); } catch (Exception e){ e.printStackTrace(); }

Anexos
Alineación de ontologías usando el método Boosting 129
} public infogeograficaTO ejecutaQueryUno(){ boolean encontradoCoordenada=false; infogeograficaTO findHotel=new infogeograficaTO(); Vector hoteles = consultas.getHotelesNombre(param1.getNombrehotel()); if(hoteles.size()==0){ findHotel.setStatus("No existe ningun resgistro del hotel."); }else{ findHotel=(infogeograficaTO)hoteles.get(0); findHotel.setCostoHabitacion(findHotel.getCostoHabitacion().trim()); findHotel.setNombre(findHotel.getNombre().trim()); findHotel.setNumEstrellas(findHotel.getNumEstrellas().trim()); findHotel.setZona(findHotel.getZona().trim()); geonamesDataPlace(findHotel.getNombre(),findHotel); } findHotel.print(); return findHotel; } public infogeograficaTO ejecutaQueryDos(){ boolean encontradoCoordenada=false; infogeograficaTO datosq2= new infogeograficaTO(); String tabla="", mapa="", status="No se encontro la coordenada"; int i; Vector resultset=consultas.getHotelesPrecio(param1.getPreciomin(),param1.getPreciomax()); for(i=0; i<resultset.size();i++){ infogeograficaTO tempdata = (infogeograficaTO)resultset.get(i); geonamesDataPlace(tempdata.getNombre(),tempdata); if(tempdata.getStatus().trim().compareTo(status.trim())!=0){ tabla=tabla+creartabla(tempdata); mapa=mapa+crearMapa(tempdata,i); } } datosq2.setPreciohoteltabs(tabla); datosq2.setPreciohotelmaps(mapa); if(resultset.size()==0){ datosq2.setStatus("No existe ningun hotel en ese rango de precios."); } else{ infogeograficaTO tempdata = (infogeograficaTO)resultset.get(0); } return datosq2; } public infogeograficaTO ejecutaQueryTres(){ boolean encontradoCoordenada=false; infogeograficaTO datosq3= new infogeograficaTO(); String tabla="", mapa="", status="No se encontro la coordenada"; int i; Vector resultset=consultas.getHotelesZona(param1.getNombrezona());

Anexos
Alineación de ontologías usando el método Boosting 130
for(i=0; i<resultset.size();i++){ infogeograficaTO tempdata = (infogeograficaTO)resultset.get(i); geonamesDataPlace(tempdata.getNombre(),tempdata); tabla=tabla+creartabla(tempdata); if(tempdata.getStatus().trim().compareTo(status.trim())!=0){ mapa=mapa+crearMapa(tempdata,i); } } datosq3.setPreciohoteltabs(tabla); datosq3.setPreciohotelmaps(mapa); if(resultset.size()==0){ datosq3.setStatus("No existe ningun en ninguna zona."); } return datosq3; } String creartabla(infogeograficaTO tempdata){ return "<tr>"+ "<td height='32' colspan='2' bgcolor='#CCCCCC' class='texto'> <div align='center'>Información geografica"+ "<div align='center'></div>"+ "</div></td>"+ "</tr>"+ " <tr>"+ "<td class='texto'>Resultado:</td>"+ "<td class='txtnomal Estilo2'>"+tempdata.getStatus()+"</td>"+ "</tr>"+ "<tr>"+ "<td width='96' class='texto'><p>1. Nombre:</p></td>"+ "<td width='280' class='txtnomal'>"+tempdata.getNombre()+"</td>"+ "</tr>"+ "<tr>"+ "<td class='texto'>2. Sinonimia </td>"+ "<td class='txtnomal'>"+tempdata.getNamealternativo()+"</td>"+ "</tr>"+ "<tr>"+ "<td class='texto'>3. Latitud </td>"+ "<td class='txtnomal'>"+tempdata.getLatitud()+"</td>"+ "</tr>"+ "<tr>"+ "<td class='texto'>4. Longitud </td>"+ "<td class='txtnomal'>"+tempdata.getLongitud()+"</td>"+ "</tr>"+ "<tr>"+ "<td class='texto'>5. Páis </td>"+ "<td class='txtnomal'>"+tempdata.getPais()+"</td>"+ "</tr>"+ "<td height='28' colspan='2' bgcolor='#CCCCCC' class='texto'><div align='center'>DESCRIPCION</div></td>"+ "</tr>"+ "<tr>"+

Anexos
Alineación de ontologías usando el método Boosting 131
"<td class='texto'>6. Zona </td>"+ "<td class='txtnomal'>"+tempdata.getZona()+"</td>"+ "</tr>"+ "<tr>"+ "<td class='texto'>7. Numero de estrellas </td>" + "<td class='txtnomal'>"+tempdata.getNumEstrellas()+"</td>"+ "</tr>"+ "<tr>"+ "<td class='texto'>8. Costo por Habitación </td>" + "<td class='txtnomal'>$"+tempdata.getCostoHabitacion()+"</td>"; } String crearMapa(infogeograficaTO tempdata, int i){ return "var point = new GLatLng("+tempdata.getLatitud()+","+tempdata.getLongitud()+");"+ "var marker = createMarker(point,'<div> Hotel: "+tempdata.getNombre().trim()+", Costo: "+tempdata.getCostoHabitacion().trim()+", Estrellas:"+tempdata.getNumEstrellas().trim()+"</div>');"+ "map.addOverlay(marker);"; } } Clase objHotel package gis; public class objHotel { String longitud; String latitude; String nombre; String zona; String tipoHabitacion; String numEstrellas; String costoHabitacion; public objHotel() {} public objHotel(String longitud, String latitude, String nombre, String zona, String tipoHabitacion, String numEstrellas) { this.longitud=longitud; this.latitude=latitude; this.nombre=nombre; this.zona=zona; this.tipoHabitacion=tipoHabitacion; this.numEstrellas=numEstrellas; } public String getLongitud() { return longitud; } public void setLongitud(String longitud) { this.longitud = longitud; } public String getLatitude() { return latitude; }

Anexos
Alineación de ontologías usando el método Boosting 132
public void setLatitude(String latitude) { this.latitude = latitude; } public String getNombre() { return nombre; } public void setNombre(String nombre) { this.nombre = nombre; } public String getZona() { return zona; } public void setZona(String zona) { this.zona = zona; } public String getTipoHabitacion() { return tipoHabitacion; } public void setTipoHabitacion(String tipoHabitacion) { this.tipoHabitacion = tipoHabitacion; } public String getNumEstrellas() { return numEstrellas; } public void setNumEstrellas(String numEstrellas) { this.numEstrellas = numEstrellas; } public String getCostoHabitacion() { return costoHabitacion; } public void setCostoHabitacion(String costoHabitacion) { this.costoHabitacion = costoHabitacion; } } Archivo controlador: ServletController package gis; import java.io.IOException; import javax.servlet.ServletException; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import javax.servlet.http.HttpSession; public class ServletController extends javax.servlet.http.HttpServlet implements javax.servlet.Servlet { static final long serialVersionUID = 1L; /* (non-Java-doc) * @see javax.servlet.http.HttpServlet#HttpServlet() */ public ServletController() {

Anexos
Alineación de ontologías usando el método Boosting 133
super(); } /* (non-Java-doc) * @see javax.servlet.http.HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response) */ protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { String direccion = "./"; boolean hayErrores=false; int forward = Integer.parseInt(request.getParameter("idOper1")); String nombrehotel=request.getParameter("nombrehotel"); System.out.println("nombre del hotel: "+nombrehotel); System.out.println(nombrehotel); switch(forward){ case 1: infogeograficaBO m1 = new infogeograficaBO(request,forward); infogeograficaTO mod = m1.ejecutaQueryUno(); HttpSession ses = request.getSession(); mod.print(); //ses.setAttribute("datosModUno", mod); ses.setAttribute("datosEndrada", mod); if(mod.getTipooperacion()==0){ response.sendRedirect(direccion+"geoubicacion.jsp"); } else if(mod.getTipooperacion()==1){ response.sendRedirect(direccion+"sif_ERRORgrnegocioMod1.jsp"); } break; case 2: infogeograficaBO m2 = new infogeograficaBO(request,forward); infogeograficaTO mod2 = m2.ejecutaQueryDos(); HttpSession ses2 = request.getSession(); mod2.print(); ses2.setAttribute("datosEndrada", mod2); if(mod2.getTipooperacion()==0){ response.sendRedirect(direccion+"geoubicacionprecio.jsp"); } else if(mod2.getTipooperacion()==1){ response.sendRedirect(direccion+"sif_ERRORgrnegocioMod1.jsp"); } break;

Anexos
Alineación de ontologías usando el método Boosting 134
case 3: infogeograficaBO m3 = new infogeograficaBO(request,forward); infogeograficaTO mod3 = m3.ejecutaQueryTres(); HttpSession ses3 = request.getSession(); mod3.print(); ses3.setAttribute("datosEndrada", mod3); if(mod3.getTipooperacion()==0){ response.sendRedirect(direccion+"geoubicacionprecio.jsp"); } else if(mod3.getTipooperacion()==1){ response.sendRedirect(direccion+"sif_ERRORgrnegocioMod1.jsp"); } break; } } /* (non-Java-doc) * @see javax.servlet.http.HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response) */ } Página principal de ONTOMASHUP <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xmlns:v="urn:schemas-microsoft-com:vml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"/> <title>Google Maps</title> <script src="http://maps.google.com/maps?file=api&v=2&sensor=false&key=ABQIAAAAzr2EBOXUKnm_jVnk0OJI7xSosDVG8KKPE1-m51RBrvYughuyMxQ-i1QfUnH94QxWIa6N4U6MouMmBA" type="text/javascript"></script> <script type="text/javascript"> function initialize() { if (GBrowserIsCompatible()) { var map = new GMap2(document.getElementById("map_canvas")); map.setCenter(new GLatLng(16.75706 ,-99.75395),8); map.addControl(new GLargeMapControl()); map.addControl(new GMapTypeControl()); // bind a search control to the map, suppress result list map.addControl(new google.maps.LocalSearch(), new GControlPosition(G_ANCHOR_BOTTOM_RIGHT, new GSize(10,20))); } } GSearch.setOnLoadCallback(initialize);

Anexos
Alineación de ontologías usando el método Boosting 135
</script> <style type="text/css"> <!-- body { margin-left: 0px; margin-top: 0px; margin-right: 0px; margin-bottom: 0px; background-color: #E8E8E8; } .QueryT { font-family: Verdana; font-size: 14pt; font-style: italic; line-height: normal; font-weight: bold; font-variant: normal; color: #000066; } .queryParam { font-family: Verdana; font-size: 10pt; font-style: normal; line-height: normal; font-weight: bold; font-variant: normal; text-transform: none; color: #000000; } .OntoMashup { font-family: verdana; font-size: 24px; } --> </style> <link href="Estilos.css" rel="stylesheet" type="text/css" /> <style type="text/css"> <!-- .Estilo6 { color: #003366; font-size: 20pt; } .Estilo11 { color: #FFFFFF; line-height: normal; font-variant: normal; font-family: Verdana; font-size: 18px; font-weight: bold; } .Estilo1 {color: #FFFFFF}

Anexos
Alineación de ontologías usando el método Boosting 136
.Estilo12 { color: #FF0000; font-style: italic; } .Estilo13 {color: #FF0000} --> </style> <script type="text/JavaScript"> <!-- function MM_findObj(n, d) { //v4.01 var p,i,x; if(!d) d=document; if((p=n.indexOf("?"))>0&&parent.frames.length) { d=parent.frames[n.substring(p+1)].document; n=n.substring(0,p);} if(!(x=d[n])&&d.all) x=d.all[n]; for (i=0;!x&&i<d.forms.length;i++) x=d.forms[i][n]; for(i=0;!x&&d.layers&&i<d.layers.length;i++) x=MM_findObj(n,d.layers[i].document); if(!x && d.getElementById) x=d.getElementById(n); return x; } function MM_validateForm() { //v4.0 var i,p,q,nm,test,num,min,max,errors='',args=MM_validateForm.arguments; for (i=0; i<(args.length-2); i+=3) { test=args[i+2]; val=MM_findObj(args[i]); if (val) { nm=val.name; if ((val=val.value)!="") { if (test.indexOf('isEmail')!=-1) { p=val.indexOf('@'); if (p<1 || p==(val.length-1)) errors+='- '+nm+' must contain an e-mail address.\n'; } else if (test!='R') { num = parseFloat(val); if (isNaN(val)) errors+='- '+nm+' must contain a number.\n'; if (test.indexOf('inRange') != -1) { p=test.indexOf(':'); min=test.substring(8,p); max=test.substring(p+1); if (num<min || max<num) errors+='- '+nm+' must contain a number between '+min+' and '+max+'.\n'; } } } else if (test.charAt(0) == 'R') errors += '- '+nm+' is required.\n'; } } if (errors) alert('The following error(s) occurred:\n'+errors); document.MM_returnValue = (errors == ''); } //--> </script> </head> <body onload="initialize()" onunload="GUnload()"> <table width="933" height="643" border="1" align="center" cellpadding="1" cellspacing="0" bordercolor="#000000" bgcolor="#FFFFFF"> <tr> <td height="44" colspan="2" bordercolor="#000066" bgcolor="#003366" class="Titulo Estilo1"><em>ONTO</em><span class="Estilo12">MASHUP</span> <em>TURISTICO</em></td> </tr> <tr> <td height="21" colspan="2" bgcolor="#000000"><div align="right"><span class="tituloII Estilo6"><span class="Estilo11">ACAPULCO-CANCÚN,MX</span></span></div></td> </tr> <tr> <td width="416" height="552" align="left" valign="top"><table width="433" border="0" background="imagenes/playa-acapulco.jpg"> <tr> <td width="427" align="left" valign="top" background="imagenes/playa-acapulco.jpg"

Anexos
Alineación de ontologías usando el método Boosting 137
bgcolor="#999999"> <form id="query1" method="post" action="ServletController"> <label><span class="queryParam">Zona de búsqueda</span>: <strong>ACAPULCO</strong> <span class="QueryT"><br /> <br /> Busquedad por nombre de hotel</span> <br /> <span class="queryParam"><br /> Nombre de hotel : <input name="nombrehotel" type="text" id="nombrehotel" onblur="MM_validateForm('nombrehotel','','R');MM_validateForm('nombrehotel','','R','preciomin','','RisNum','preciomax','','RisNum');return document.MM_returnValue" value="Acapulco Malibu" size="50" maxlength="100" /> </span></label> <span class="queryParam"> <label> <input name="cmdq1" type="submit" id="cmdq1" value="Enviar" /> <br /> Ej. </label> </span><span class="queryParam"> Acapulco Malibu </span> <span class="queryParam"> <input name="idOper1" type="hidden" id="idOper1" value="1" /> Si el nombre del hotel no es encontrado </span><span class="queryParam">en Acapulco, la aplicación lo buscara</span> <span class="queryParam"><span class="Estilo13">en cada</span> municipio de Guerrero</span> <p> </p> </form></td> </tr> <tr> <td><form id="query2" method="post" action="ServletController"> <label><span class="QueryT">Busquedad de hotel por rango <br /> de precio </span> <br /> <span class="queryParam"><br /> Minimo : $ <input name="preciomin" type="text" id="preciomin" value="500" size="10" maxlength="10" /> </span></label> <span class="queryParam"> <label> , Máximo : $ <input name="preciomax" type="text" id="preciomax" value="1000" size="10" maxlength="10" /> </label> <label> </label> <label> <input name="cmdq2" type="submit" id="cmdq2" value="Enviar" /> </label> </span> <p> <span class="queryParam"> <input name="idOper1" type="hidden" id="idOper1" value="2" /> Si el nombre del hotel no es encontrado en Acapulco, la aplicación lo buscara en cada municipio de

Anexos
Alineación de ontologías usando el método Boosting 138
Guerrero. </span></p> <p class="queryParam">*Cantidades enteras (sin decimal). </p> <p class="queryParam"> </p> </form></td> </tr> <tr> <td height="74" align="left" valign="top"><form id="query3" method="post" action="ServletController"> <label><span class="QueryT">Busquedad de hotel por zona </span> <br /> <br /> <span class="queryParam">Zona del hotel : <select name="nombrezona" id="nombrezona"> <option value="ESTE">ESTE</option> <option value="DORADA">DORADA</option> </select> </span> </label> <label> <input name="cmdq3" type="submit" id="cmdq3" value="Enviar" /> </label> <input name="idOper12" type="hidden" id="idOper12" value="3" /> </form></td> </tr> </table></td> <td width="513" align="left" valign="top" <div id="map_canvas" style="width: 513px; height: 643px"></div> </td> </tr> <tr> <td height="21" colspan="2" bgcolor="#333333"> </td> </tr> </table> <p> </p> <p> </p> <meta http-equiv="content-type" content="text/html; charset=UTF-8"/> <title></title> </body> </html>
Interfaz Web para el cliente, archivo (resultados): geoubicacion.jsp
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xmlns:v="urn:schemas-microsoft-com:vml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"/> <title>ONTO-MASHUP TURISTICO</title> <jsp:useBean id="datosEndrada" scope="session" class="gis.infogeograficaTO" /> <script

Anexos
Alineación de ontologías usando el método Boosting 139
src="http://maps.google.com/maps?file=api&v=2&sensor=false&key=ABQIAAAAzr2EBOXUKnm_jVnk0OJI7xSosDVG8KKPE1-m51RBrvYughuyMxQ-i1QfUnH94QxWIa6N4U6MouMmBA" type="text/javascript"></script> <script type="text/javascript"> function initialize() { if (GBrowserIsCompatible()) { var map = new GMap2(document.getElementById("map_canvas")); map.setCenter(new GLatLng(16.75706 ,-99.75395),8); var bounds = map.getBounds(); var southWest = bounds.getSouthWest(); var northEast = bounds.getNorthEast(); var point = new GLatLng(16.858721,-99.859457); map.addOverlay(new GMarker(point)); map.addControl(new GLargeMapControl()); map.addControl(new GMapTypeControl()); // bind a search control to the map, suppress result list map.addControl(new google.maps.LocalSearch(), new GControlPosition(G_ANCHOR_BOTTOM_RIGHT, new GSize(10,20))); } } GSearch.setOnLoadCallback(initialize); </script> <script type="text/javascript"> <style type="text/css"> <!-- body { margin-left: 0px; margin-top: 0px; margin-right: 0px; margin-bottom: 0px; background-color: #FFFFFF; } .QueryT { font-family: Georgia; font-size: 14pt; font-style: italic; line-height: normal; font-weight: bold; font-variant: normal; color: #000066; } .queryParam { font-family: Verdana; font-size: 10pt; font-style: normal; line-height: normal; font-weight: bold; font-variant: normal; text-transform: none;

Anexos
Alineación de ontologías usando el método Boosting 140
color: #000000; } .texto { font-family: "Tw Cen MT"; font-size: 12pt; font-style: normal; line-height: normal; font-weight: bold; font-variant: normal; text-transform: none; } .titulo2 { font-family: Georgia; font-size: 24pt; font-style: italic; line-height: normal; font-weight: bold; font-variant: normal; text-transform: none; color: #FFFFFF; } .txtnomal { font-family: "Tw Cen MT"; font-size: 12pt; font-style: normal; line-height: normal; font-weight: normal; font-variant: normal; } --> </style> <link href="Estilos.css" rel="stylesheet" type="text/css" /> <style type="text/css"> <!-- .Estilo1 {color: #FFFFFF} .Estilo2 { color: #FF0000; font-weight: bold; } #Layer1 { position:absolute; width:806px; height:383px; z-index:1; overflow: scroll; left: 114px; top: 628px; visibility: visible; } --> </style></script> </head> <body onload="initialize()" onunload="GUnload()"> <table width="956" height="496" border="0" align="center" cellspacing="0" bgcolor="#FFFFFF"> <tr> <td height="33" bordercolor="#000066" bgcolor="#003366" class="Titulo"><div align="center"> <div align="left"> <table width="954" border="0"> <tr> <td width="472" height="49"><div align="center"><span class="Titulo Estilo1"><span class="tituloII"> ONTO-MASHUP TURISTICO</span></span></div></td> <td width="472"> </td>

Anexos
Alineación de ontologías usando el método Boosting 141
</tr> </table> </div> </div></td> </tr> <tr> <td height="21" background="imagenes/azuldegradado.JPG" bgcolor="#000099"><div align="center" class="Titulo Estilo1"> </div></td> </tr> <tr> <td height="21" bgcolor="#FFFFFF"><div align="center"><span class="Titulo">RESULTADOS</span></div></td> </tr> <tr> <td width="954" height="312" align="left" valign="top"><table width="200" border="1"> <tr> <td><div id="map_canvas" style="width: 954px; height: 312px"></div></td> </tr> </table></td> </tr> <tr> <td height="52" align="left" valign="top"><table width="957" border="0" align="center"> <tr> <td colspan="2" bgcolor="#CCCCCC" class="texto"> </td> </tr> <tr> <td width="103" class="texto"><p>1. Nombre:</p></td> <td width="844" class="txtnomal"><jsp:getProperty name="datosEndrada" property="nombre"/> </td> </tr> <tr> <td class="texto"> </td> <!-- <td class="txtnomal Estilo2"><span class="texto">Estatus:</span> <jsp:getProperty name="datosEndrada" property="status" /></td>--> </tr> <tr> <!--Esto es un comentario--> <td colspan="2" class="texto">Coordenada Geografica(Latitud,Longitud):(16.858721,-99.859457) <!--( <jsp:getProperty name="datosEndrada" property="latitud" /> , <jsp:getProperty name="datosEndrada" property="longitud" /> )</td>--> </tr> <tr> <td height="28" colspan="2" bgcolor="#CCCCCC" class="texto"><div align="center">DESCRIPCION</div></td> </tr> <tr> <td class="texto">2. Zona </td> <td class="txtnomal"><jsp:getProperty name="datosEndrada" property="zona" /></td> </tr> <tr> <td class="texto">3. Numero de estrellas </td> <td class="txtnomal"><jsp:getProperty name="datosEndrada" property="numEstrellas" /> </td> </tr>

Anexos
Alineación de ontologías usando el método Boosting 142
<tr> <td class="texto">4. Costo por Habitación </td> <td class="txtnomal">$ <jsp:getProperty name="datosEndrada" property="costoHabitacion" /></td> </tr> </table> </td> </tr> <tr> <td height="21" background="imagenes/azuldegradado.JPG"> </td> </tr> </table> <p> <tr> <td width="9" background="imagenes/grisdegradado2.JPG"> </td> <td width="391" height="462" align="left" valign="top"> </td> <td width="560" align="left" valign="top"><table width="200" border="1" cellpadding="1" bordercolor="#666666"> <tr> <td> </body> </html>


















