ALGORITMOS Y PROGRAMACIÓN ... - Universidad de...
56
Programación Paralela Esquemas de Programación Paralela 1 ALGORITMOS Y PROGRAMACIÓN PARALELA Esquemas de programación paralela REFERENCIAS • Almeida, Giménez, Mantas, Vidal: Introducción a la Programación Paralela. Cap 5 y 6 • Wilkinson, Allen • Quinn
Transcript of ALGORITMOS Y PROGRAMACIÓN ... - Universidad de...

Programación Paralela Esquemas de Programación Paralela 1
ALGORITMOS Y PROGRAMACIÓN PARALELA
Esquemas de programación paralela
REFERENCIAS
• Almeida, Giménez, Mantas, Vidal: Introducción a la Programación Paralela. Cap 5 y 6
• Wilkinson, Allen
• Quinn

Programación Paralela Esquemas de Programación Paralela 2
Esquemas de algoritmos paralelos
* Paralelismo de datos
* Particionado de datos
* Algoritmos relajados
* Recorrido de un árbol
* Computación pipeline
* Paralelismo síncrono
* Divide y vencerás
* Programación dinámica
* Branch and Bound
* Trabajadores replicados

Programación Paralela Esquemas de Programación Paralela 3
Paralelismo de datos
* Muchos datos tratados de una forma igual o similar (apropiado para GPU)* Algoritmos numéricos* Datos en arrays o vectores
- Procesamiento vectorial - Paralelismo asignando partes distintas del array a distintos procesadores
* Memoria Compartida: - Distribución del trabajo- Paralelización automática
* Memoria Distribuida: - Distribución de los datos- Técnica de particionado de datos

Programación Paralela Esquemas de Programación Paralela 4
Paralelismo de datosEjemplo: suma de n datos
* Esquema: s=0
for i=0 to n-1s=s+a[i]
endfor* Paralelización automática:
Con opción de compilación si no hay dependencia de datos* Con pragma:
s=0#Pragma: for paralelo (a compartida de lectura,
s compartida de lectura-escritura)for i=0 to n-1
s=s+a[i]endfor
* Distintas posibilidades de asignación de los datos a los procesadores:- Bloques contiguos- Cíclico- Incremental
#pragma omp parallel forprivate(i) reduction(+:s)#pragma omp parallel forprivate(i) reduction(+:s)
scheduling(static,tamano)

Programación Paralela Esquemas de Programación Paralela 5
Paralelismo de datosEjemplo: suma de n datos
* Con paralelismo explícito:#Pragma: llamada concurrente (i=0 to p-1)
sumaparcial( &a[(i*n)/p] , i )if nodo=0
s=sumatotal()endif
sumaparcial( a , i ):s=0for j=0 to n/p-1
s=s+a[j]endfora[0]=s
*¿Paralelización de sumatotal?Si pocos procesadores suele ser preferible que lo haga uno solo
sumatotal():s=0for j=0 to p-1 step n/p
s=s+a[j]endforreturn s

Programación Paralela Esquemas de Programación Paralela 6
Paralelismo de datosEjemplo: ordenación por rango
* Paralelismo implícito: #Pragma: for paralelo (a compartida de lectura,
r compartida de lectura-escritura)for i=0 to n-1
for j=0 to n-1if a[i]>a[j]
r[i]=r[i]+1endif
endforendfor se asignan varios valores de i a cada procesadorno hay problemas de coherencia en r

Programación Paralela Esquemas de Programación Paralela 7
Paralelismo de datosEjemplo: ordenación por rango
* Paralelismo explícito: #Pragma: llamada concurrente (for i=0 to p-1)
calcularrango(a,i) calcularrango(a,i):
for j=(i*n)/p to ((i+1)*n)/p-1for k=0 to n-1
if a[j]>a[k]r[j]=r[j]+1
endifendfor
endfor se hace asignación del trabajo entre los procesadores
P0 P1 P2
a n n n
r n/p n/p n/p

Programación Paralela Esquemas de Programación Paralela 8
Paralelismo de datosEjemplo: multiplicación de matrices
* Paralelismo implícito: #Pragma: for paralelo (a,b compartida de lectura,
c compartida de lectura-escritura)for i=0 to n-1
for j=0 to n-1c[i,j]=0for k=0 to n-1
c[i,j]=c[i,j]+a[i,k]*b[k,j]endfor
endforendfor Posiblemente mejor usar bloques contiguos para mejor uso de la caché
C A B
P0 P0 P0
P1 = P1 P1
P2 P2 P2

Programación Paralela Esquemas de Programación Paralela 9
Paralelismo de datosEjemplo: multiplicación de matrices
* Paralelismo explícito: #Pragma: llamada concurrente (for i=0 to p-1)
multiplicar(c,a,b,i) multiplicar(c,a,b,i):
for j=(i*n)/p to ((i+1)*n)/p-1for k=0 to n-1
c[j,k]=0for l=0 to n-1
c[j,k]=c[j,k]+a[j,l]*b[l,k]endfor
endforendfor

Programación Paralela Esquemas de Programación Paralela 10
Particionado de datos
* Especie de paralelismo de datos en Multicomputadores (Memoria Distribuida) * El espacio de datos se divide en regiones adyacentes:
- Se asignan a procesadores distintos- Intercambio de datos entre regiones adyacentes
* Para obtener buenas prestaciones:
intentar que el volumen de computación entre comunicaciones sea grande (paralelismo de grano grueso)

Programación Paralela Esquemas de Programación Paralela 11
Particionado de datosEjemplo: suma de n datos
- Computación: suma de n/p datos en cada procesador. - Comunicación: envío de datos (si no están distribuidos) igual conste que la computación
acumulación de los resultados depende de la topologíase puede pensar en topología lógica
- El programa similar al de Memoria Compartida.
n
P0 P1 P2
Programación Paralela Esquemas de Programación Paralela 12
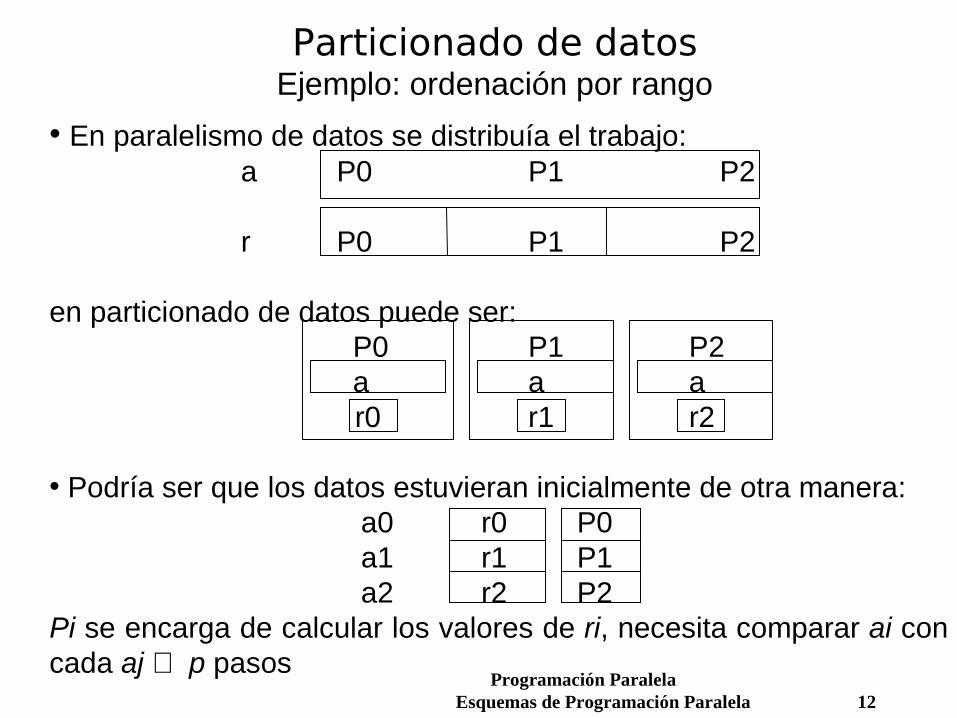
Particionado de datosEjemplo: ordenación por rango
• En paralelismo de datos se distribuía el trabajo:a P0 P1 P2
r P0 P1 P2
en particionado de datos puede ser: P0 P1 P2 a a a
r0 r1 r2
• Podría ser que los datos estuvieran inicialmente de otra manera: a0 r0 P0 a1 r1 P1 a2 r2 P2
Pi se encarga de calcular los valores de ri, necesita comparar ai con cada aj ⇒ p pasos

Programación Paralela Esquemas de Programación Paralela 13
Particionado de datosEjemplo: ordenación por rango
En cada Pi, i=0,1,...,p-1for j=0 to n/p-1
b[j]=a[j]endforfor j=1 to p
for k=0 to n/p-1for l=0 to n/p-1
if a[k]>b[l]r[k]=r[k]+1
endifendfor
endforenviar a[0]...a[n/p-1] a P(i-1) mod precibir en b[0],...,b[n/p-1] de P(i+1) mod p
endfor

Programación Paralela Esquemas de Programación Paralela 14
Algoritmos relajados
* Cada procesador computa de manera independiente.
- No hay sincronización ni comunicación. * Buenas prestaciones en Memoria Compartida y Distribuida.
- A veces a costa de no utilizar el mejor algoritmo paralelo.
* Fáciles de programar. * Difícil encontrar algoritmos que se adecúen a este esquema.
Programación Paralela Esquemas de Programación Paralela 15
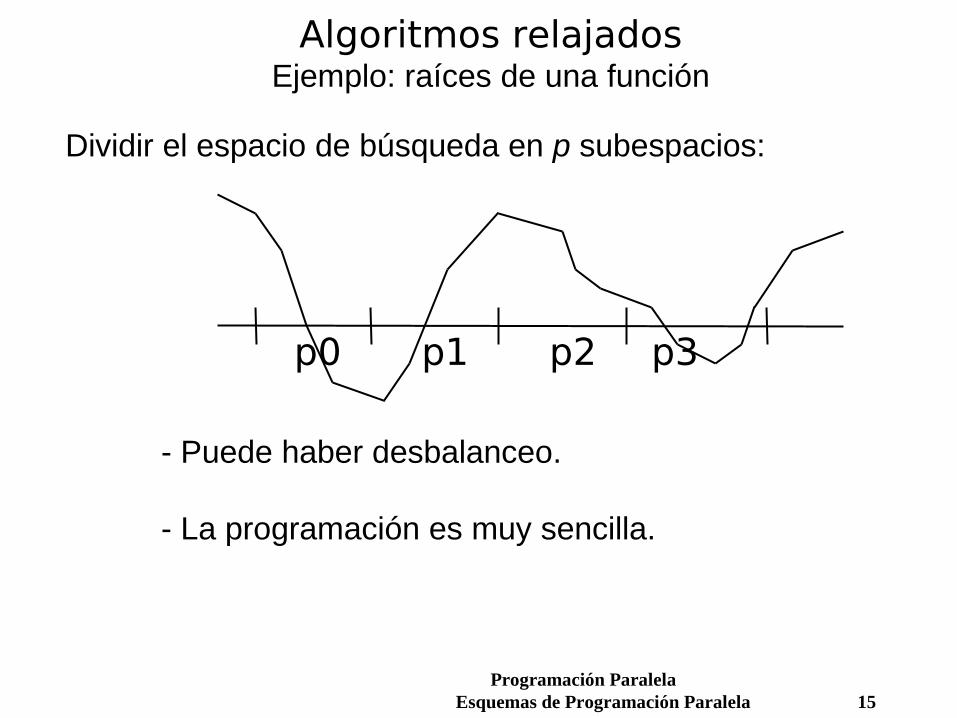
Algoritmos relajadosEjemplo: raíces de una función
Dividir el espacio de búsqueda en p subespacios:
- Puede haber desbalanceo.
- La programación es muy sencilla.
p0 p1
p2
p3
Programación Paralela Esquemas de Programación Paralela 16
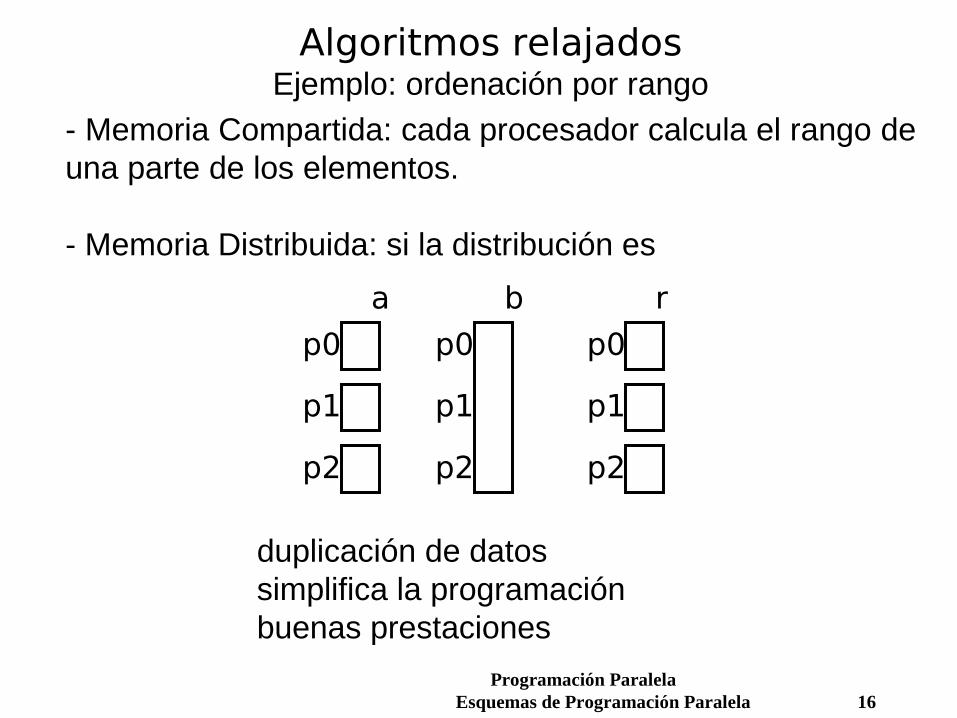
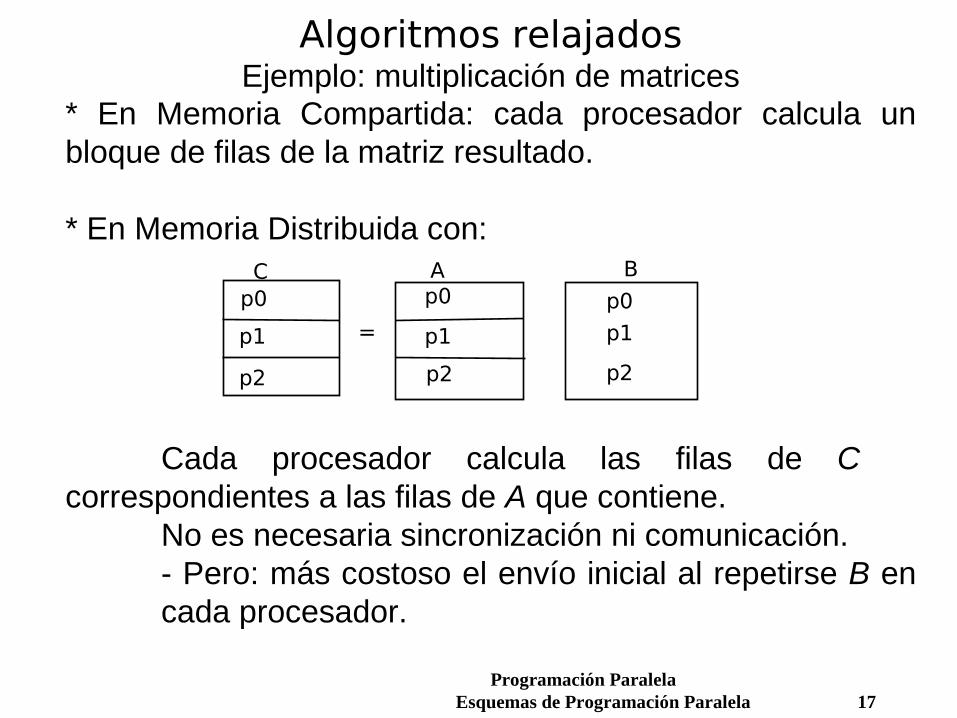
Algoritmos relajadosEjemplo: ordenación por rango
- Memoria Compartida: cada procesador calcula el rango de una parte de los elementos. - Memoria Distribuida: si la distribución es
duplicación de datossimplifica la programaciónbuenas prestaciones
p0
p1
p2
p0
p1
p2
p0
p1
p2
a b r
Programación Paralela Esquemas de Programación Paralela 17
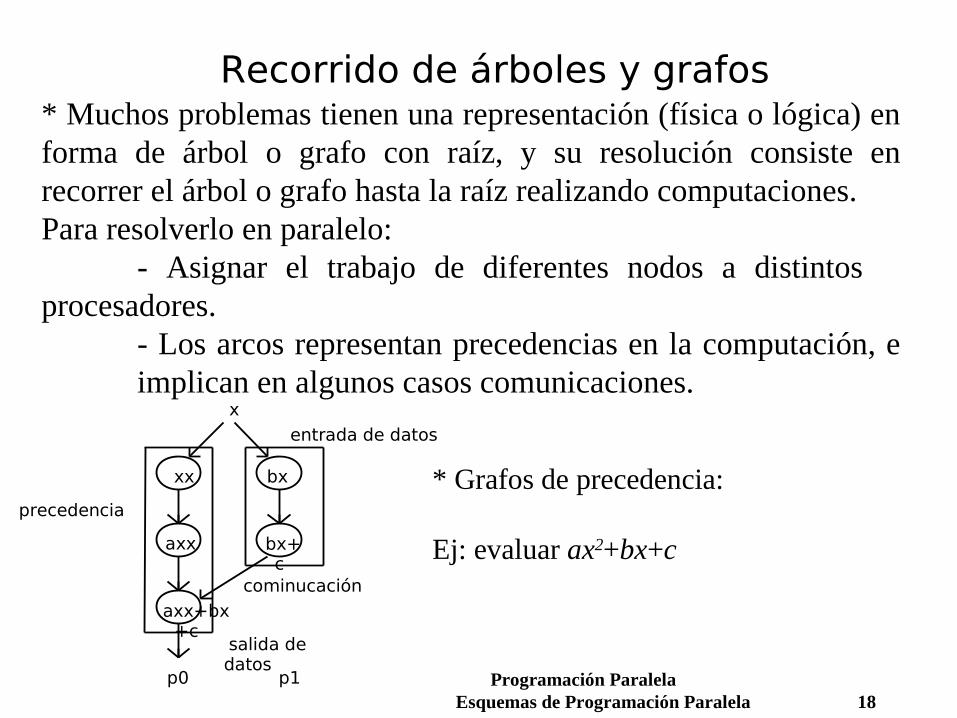
Algoritmos relajadosEjemplo: multiplicación de matrices
* En Memoria Compartida: cada procesador calcula un bloque de filas de la matriz resultado. * En Memoria Distribuida con:
Cada procesador calcula las filas de C correspondientes a las filas de A que contiene.
No es necesaria sincronización ni comunicación.- Pero: más costoso el envío inicial al repetirse B en cada procesador.
C A B
=
p0
p1
p2
p0
p1 p2
p0
p1
p2
Programación Paralela Esquemas de Programación Paralela 18
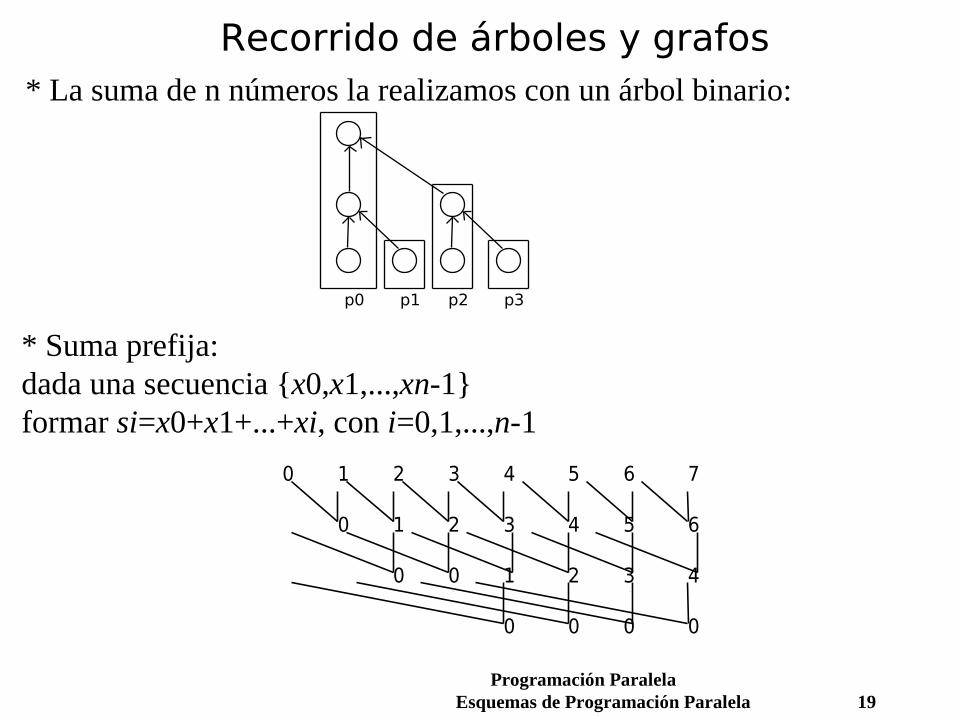
Recorrido de árboles y grafos* Muchos problemas tienen una representación (física o lógica) en forma de árbol o grafo con raíz, y su resolución consiste en recorrer el árbol o grafo hasta la raíz realizando computaciones.Para resolverlo en paralelo:
- Asignar el trabajo de diferentes nodos a distintos procesadores.
- Los arcos representan precedencias en la computación, e implican en algunos casos comunicaciones.
bx
bx+c
xx
axx
axx+bx+c
x
p0 p1
entrada de datos
salida de datos
precedencia
cominucación
* Grafos de precedencia: Ej: evaluar ax2+bx+c
Programación Paralela Esquemas de Programación Paralela 19
Recorrido de árboles y grafos
p0 p1 p2 p3
* La suma de n números la realizamos con un árbol binario:
0 1 2 3 4 5 6 7
01
12
23
34
45
56
67
02
03
14
25
36
47
0 0 0 0
* Suma prefija:dada una secuencia {x0,x1,...,xn-1}formar si=x0+x1+...+xi, con i=0,1,...,n-1

Programación Paralela Esquemas de Programación Paralela 20
Recorrido de árboles y grafosEjemplo: suma prefija
Para cada Pi, i=0,1,...,n-1desp=1for j=0 to log n-1
if i<(n-desp)enviar x a Pi+desp
endifif i>=desp
recibir en y de Pi-despx=x+y
endifdesp=desp*2
endfor

Programación Paralela Esquemas de Programación Paralela 21
Recorrido de árboles y grafosEjemplo: clases de equivalencia
En una representación de conjuntos por medio de árboles:
se trata de encontrar el representante de la clase a la que pertenece cada nodo.Los arcos indican comunicaciones si están en distinto procesador. De cada nodo sale como mucho un arco⇒ el patrón de comunicaciones es fijo. Para cada nodo se lee el valor del padre,si el valor leído es igual al que hay en el nodo ese nodo envía un mensaje de fin al nodo con el que se comunica y acaba.
1
2
3 4
5
6
7 8
9
1 2 3 4 5 6 7 8 9
2 3 3 5 5 7 7 7 8
3 3 3 5 5 7 7 7 7
← ← ← ← → →
Programación Paralela Esquemas de Programación Paralela 22
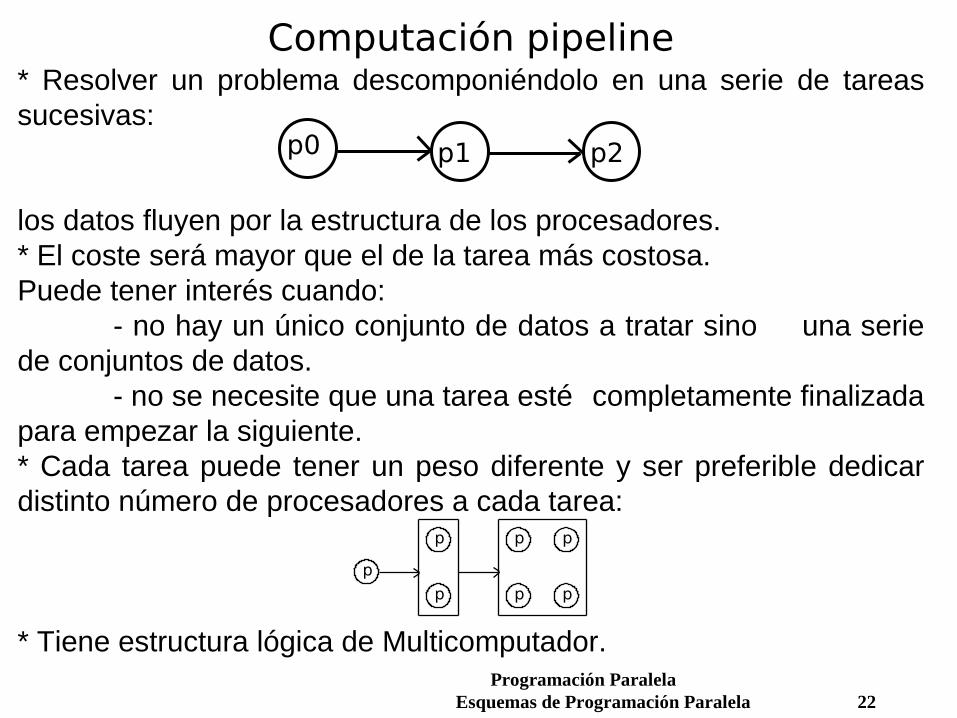
Computación pipeline* Resolver un problema descomponiéndolo en una serie de tareas sucesivas:
los datos fluyen por la estructura de los procesadores.* El coste será mayor que el de la tarea más costosa.Puede tener interés cuando:
- no hay un único conjunto de datos a tratar sino una serie de conjuntos de datos.
- no se necesite que una tarea esté completamente finalizada para empezar la siguiente.* Cada tarea puede tener un peso diferente y ser preferible dedicar distinto número de procesadores a cada tarea:
* Tiene estructura lógica de Multicomputador.
p0
p1
p2
p0
p1
p2
p3
p4
p5
p6
Programación Paralela Esquemas de Programación Paralela 23
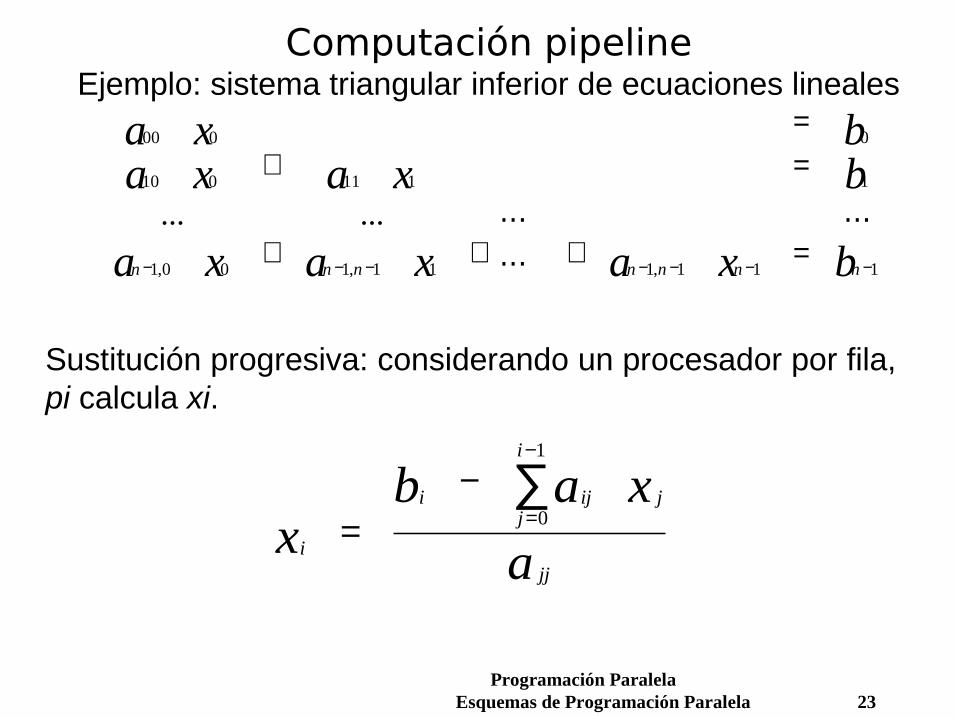
Computación pipelineEjemplo: sistema triangular inferior de ecuaciones lineales
Sustitución progresiva: considerando un procesador por fila, pi calcula xi.
00 0 0
10 0 11 1 1
1 0 0 1 1 1 1 1 1 1
a x ba x a x b
a x a x a x bn n n n n n n
=+ =
+ + + =− − − − − − −
... ... ... ...
..., , ,
i
i ij jj
i
jj
xb a x
a=
−=
−
∑0
1

Programación Paralela Esquemas de Programación Paralela 24
Computación pipelineEjemplo: sistema triangular inferior de ecuaciones lineales
#Pragma: llamada concurrente (for i=0 to n-1)resolver(i)
resolver(i):
suma=0for j=0 to i-1
P(valor[j])V(valor[j])suma=suma+a[i,j]*x[j]
endforx[i]=(b[i]-suma)/a[i,i]V(valor[i])
donde:- valor[i] son semáforos inicializados a 0.- se puede hacer con otras construcciones como llaves o canales.

Programación Paralela Esquemas de Programación Paralela 25
Computación pipelineEjemplo: sistema triangular inferior de ecuaciones lineales
- Coste secuencial: - Coste paralelo:
- Speed-up: - Eficiencia: 12.5% * Con procesos de mayor grano: n/p filas por procesador eficiencia del 50%,porque se puede empezar la computación de una tarea sin haberse acabado la de las anteriores.
2
n n+
8 nn8

Programación Paralela Esquemas de Programación Paralela 26
Computación pipelineEjemplo: sistema triangular inferior de ecuaciones lineales
* En Memoria Distribuida, sustituir los semáforos por envíos y recepciones: En cada Pi, i=0,1,...,n-1
if i=0 x=b/a[0]enviar x a P1
else if i<>n-1for j=0 to i-1
recibir x de Pi-1enviar x a Pi+1suma=suma+a[j]*x
endforx=(b-suma)/a[i]
else for j=0 to n-2recibir x de Pn-2suma=suma+a[j]*x
endforx=(b-suma)/a[n-1]
endif

Programación Paralela Esquemas de Programación Paralela 27
Divide y vencerás* Idea general: Dividir un problema p en subproblemas p1,p2,...pn Resolver los subproblemas pi obteniendo si Combinar las soluciones parciales s1,s2,...,sn para obtener la solución global de pEl éxito del método depende de que se pueda hacer la división y la combinación de forma eficiente.* Paralelismo:
La solución de los subproblemas se puede hacer en paralelo⇒ la división debe producir subproblemas de coste balanceadola división y la combinación implicarán comunicaciones y sincronización
Es el esquema más adecuado para paralelizar,se puede considerar que todos los programas paralelos siguen este esquema.

Programación Paralela Esquemas de Programación Paralela 28
Divide y vencerásEjemplo: ordenación por mezcla
* Multiprocesador:#Pragma: llamada concurrente (for i=0 to p-1)
ordenarsimple(i,a) (*Ordenar en cada procesador el trozo de array que le
corresponde*)proc=p/2 (*Número de procesadores que intervienen en la mezcla*)for j=1 to log p-1
#Pragma: llamada concurrente (for i=0 to proc-1)mezclar(i,n/proc,a)
proc=proc/2endformezclasimple(0,n,a) mezclar(i,l,a):
mezclasimple(i*l,(i+1)*l-1,a) No hay recursión: se divide en función del número de procesadores.
* Secuencial, recursivo:ordenar(p,q,a):
if q-p>limm=(p+q)/2ordenar(p,m,a)ordenar(m+1,q,a)mezclar(p,m,q,a)
elseordenarbasico
endif
Programación Paralela Esquemas de Programación Paralela 29
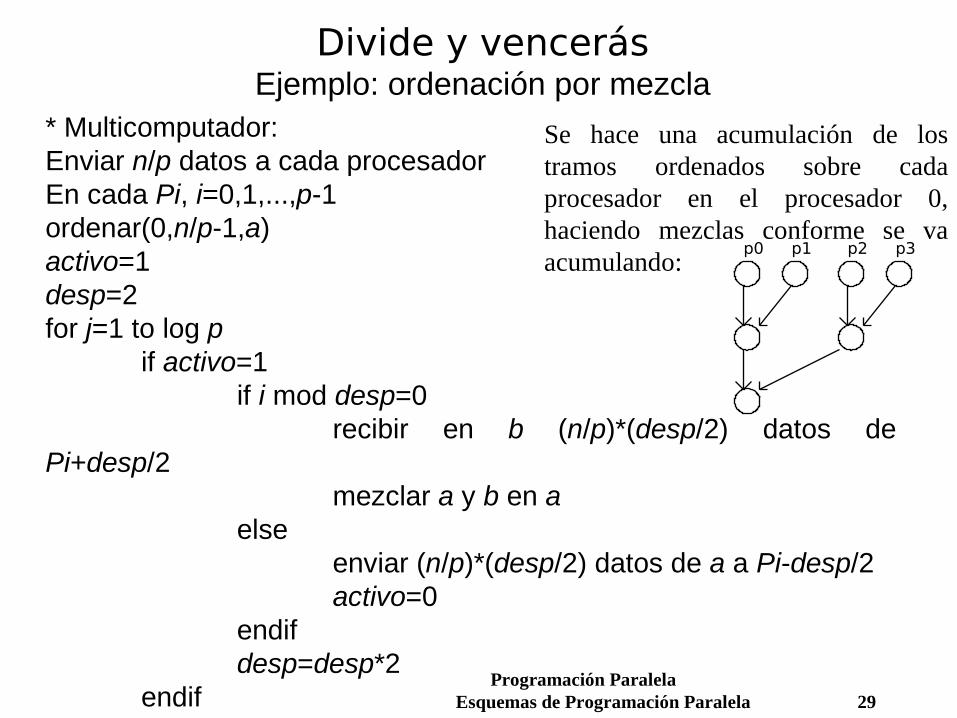
Divide y vencerásEjemplo: ordenación por mezcla
* Multicomputador:Enviar n/p datos a cada procesadorEn cada Pi, i=0,1,...,p-1ordenar(0,n/p-1,a)activo=1desp=2for j=1 to log p
if activo=1if i mod desp=0
recibir en b (n/p)*(desp/2) datos de Pi+desp/2
mezclar a y b en aelse
enviar (n/p)*(desp/2) datos de a a Pi-desp/2activo=0
endifdesp=desp*2
endifendif
Se hace una acumulación de los tramos ordenados sobre cada procesador en el procesador 0, haciendo mezclas conforme se va acumulando:
p0 p1 p2 p3

Programación Paralela Esquemas de Programación Paralela 30
Divide y vencerásEjemplo: ordenación rápida
* Multiprocesador:m[0]=0m[1..p]←n-1m[p/2]=particionar(0,n-1,a)proc=2for j=1 to log p-1
#Pragma: llamada concurrente (for i=0 to proc-1)m[p/(2*proc)+i*p/proc]=particionar(m[i*p/proc],m[(i+1)*p/proc],a)
proc=2*proc endfor#Pragma: llamada concurrente (for i=0 to p-1)
ordenar(m[i],m[i+1],a) Al particionar se forman grupos de datos ordenados entre sí, utilizando el array m de índices para indicar los límites de las particiones. El trabajo no estará balanceado porque las secuencias de datos no tienen la misma longitud.
* Secuencial:ordenar(p,q,a):
if q-p>limm=particionar(p,q,a)ordenar(p,m,a)ordenar(m+1,q,a)
else ordenarbasicoendif
En el particionado se hace la ordenación

Programación Paralela Esquemas de Programación Paralela 31
Divide y vencerásEjemplo: ordenación rápida
* Multicomputador:En cada Pi, i=0,1,...,p-1m1=n-1 ; desp=p ; activo=0if i mod (desp/2)=0 activo=1 endiffor j=1 to log p
if activo=1if i mod desp=0
m=particionar(0,m1,a)enviar m1-m+1 y a[m+1],...,a[m1] a Pi+desp/2m1=m
elserecibir en l y a de Pi-desp/2m1=l-1m=particionar(0,m1,a)enviar m1-m+1 y a[m+1],...,a[m1] a Pi+desp/2m1=m
endifendifdesp=desp/2if i mod (desp/2)=0 activo=1 endif
endforordenar(a) y acumular sobre P0
Suponiendo que tenemos los datos en el procesador 0 se irán haciendo y enviando particiones, de manera que en cada paso se duplica el número de procesadores implicados.
Hay desbalanceo y mensajes de distinta longitud.
Programación Paralela Esquemas de Programación Paralela 32
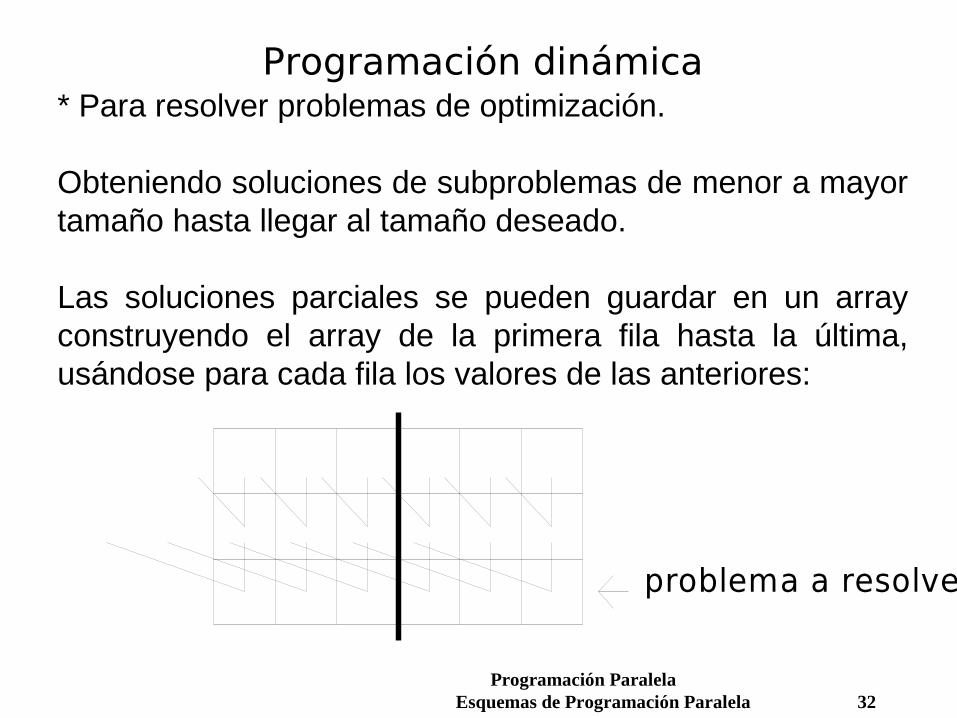
Programación dinámica* Para resolver problemas de optimización. Obteniendo soluciones de subproblemas de menor a mayor tamaño hasta llegar al tamaño deseado. Las soluciones parciales se pueden guardar en un array construyendo el array de la primera fila hasta la última, usándose para cada fila los valores de las anteriores:
problema a resolver

Programación Paralela Esquemas de Programación Paralela 33
Programación dinámica
* En Memoria Compartida:En cada fila intervienen los procesadores obteniendo cada uno valores de distintos tamaños,basándose en la línea anterior para leer ⇒ no hay problema de coherencia,pero se necesita sincronización entre los pasos sucesivos (uno por línea). * En Memoria Distribuida:Un procesador puede necesitar datos almacenados en otro: indicados por las flechas que cruzan la línea gruesa.

Programación Paralela Esquemas de Programación Paralela 34
Programación dinámicaEjemplo: problema de la mochila 0/1
Mochila de capacidad Cobjetos numerados 1,2,...,ncada objeto tiene un peso piy un beneficio bi. Maximizar sujeto a xi=0 o 1, y Se obtiene la fórmula:
Ejemplo: C=9 p=(3,5,2) b=(4,6,5)1 2 3 4 5 6 7 8
91 0 0 4 4 4 4 4 442 0 0 4 4 6 6 6
10 103 0 5 5 5 9 9 9
11 11
i ii
n
x b=∑
1
i ii
n
x p C=∑ ≤
1
M i X max{M i X M i X p bi i}( , ) ( , ), ( , )= − − − +1 1

Programación Paralela Esquemas de Programación Paralela 35
Programación dinámicaEjemplo: problema de la mochila 0/1
* Multiprocesador:for i=1 to n-1
#Pragma: llamada concurrente (for j=1 to p)calcular(i,j,M)
endforM[n,C]=max{M[n-1,C],M[n-1,C-p[n]]+b[n]} calcular(i,j,M):
for k=(j-1)*C/p+1 to j*C/pM[i,k]=max{M[i-1,k],M[i-1,k-p[i]]+b[i]}
endfor

Programación Paralela Esquemas de Programación Paralela 36
Programación dinámicaEjemplo: problema de la mochila 0/1
* Multicomputador: Suponemos una columna por procesador.Para cada Pi, i=1,...,Cif p[1]≤i M=b[1] (*Se rellena la primera fila*)else M=0endifif i+p[2]≤C (*Se comprueba qué procesadores necesitan datos*)
enviar M a Pi+p[2]endiffor j=2 to n-1
if i-p[j]≥1 (*Se comprueba si recibe dato de la fila anterior*)recibir en N de Pi-p[j]
else N=0endifM=max{M,N+b[j]}if i+p[j+1]≤C enviar M a Pi+p[j+1] endif
endforif i-p[n]≥1 recibir en N de Pi-p[n]else N=0endifM=max{M,N+b[j]}

Programación Paralela Esquemas de Programación Paralela 37
Paralelismo síncrono
* Iteraciones sucesivas: - cada procesador realiza el mismo trabajo sobre una porción distinta de los datos.
- datos de una iteración se utilizan en la siguiente.- al final de cada iteración sincronización (local o
global). * Prestaciones afectadas por la sincronización:
- en Memoria Compartida buenas prestaciones.- en Memoria Distribuida bajan las prestaciones pues
hay comunicación.
Programación Paralela Esquemas de Programación Paralela 38
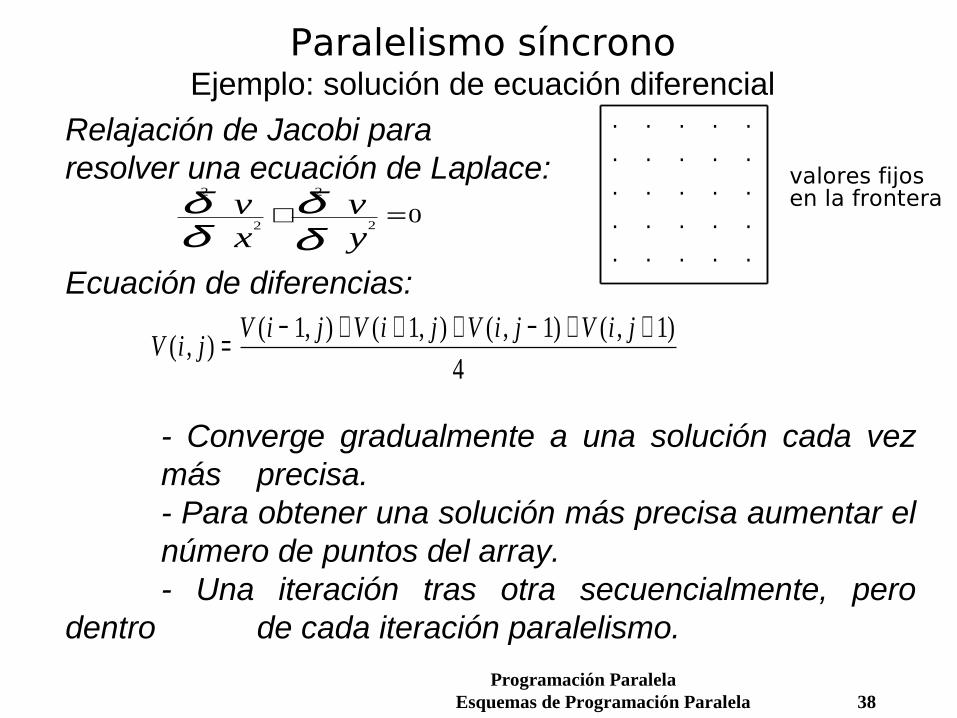
Paralelismo síncronoEjemplo: solución de ecuación diferencial
Relajación de Jacobi para resolver una ecuación de Laplace:
Ecuación de diferencias:
- Converge gradualmente a una solución cada vez más precisa.- Para obtener una solución más precisa aumentar el número de puntos del array.- Una iteración tras otra secuencialmente, pero
dentro de cada iteración paralelismo.
2
2
2
20δ
δδδ
vx
vy
+ =
. . . . .
. . . . .
. . . . .
. . . . .
. . . . .
valores fijosen la frontera
V i jV i j V i j V i j V i j
( , )( , ) ( , ) ( , ) ( , )= − + + + − + +1 1 1 1
4

Programación Paralela Esquemas de Programación Paralela 39
Paralelismo síncronoEjemplo: solución de ecuación diferencial
* En Multiprocesador:b←afor i=1 to numiter/2#Pragma: for paralelo (a compartida de lectura,
b compartida de escritura)for j=1 to n
for k=1 to nb[j,k]=(a[j-1,k]+a[j+1,k]+a[j,k-1]+a[j,k+1])/4
endforendfor
#Pragma: for paralelo (a compartida de escritura,b compartida de lectura)
(*lo mismo del pragma anterior pero de b en a*)endfor - Sincronización por acabar el pragma. - En dos partes para evitar copias.- Asigna filas completas a cada procesador:
topología lógica de anillo.

Programación Paralela Esquemas de Programación Paralela 40
Paralelismo síncronoEjemplo: solución de ecuación diferencial
* Puede ser más interesante crear un proceso por cada procesador:b←a#Pragma: llamada concurrente (for i=0 to p-1)
iterar(a,b,i) iterar(a,b,i):
for j=1 to numiter/2for k=i*n/p+1 to (i+1)*n/p
for l=1 to nb[k,l]=(a[k-1,l]+a[k+1,l]+a[k,l-
1]+a[k,l+1])/4endfor
endforBARRERA
(*lo mismo pero de b en a*)BARRERA
endfor
En Memoria Distribuida a y b son locales:La barrera implica sincronización y comunicación.

Programación Paralela Esquemas de Programación Paralela 41
Paralelismo síncronoBarrera lineal
* Normalmente las barreras se proporcionan con el sistema.* Se pueden implementar de distintas maneras.* Implementación por conteo de variables:Barrera:
P(llegada)cont=cont+1if cont<n
V(llegada)else
V(salida)endifP(salida)cont=cont-1if cont>0
V(salida)else
V(llegada)endif
Coste lineal.
En Memoria Distribuida habría que acceder a una variable global.
Programación Paralela Esquemas de Programación Paralela 42
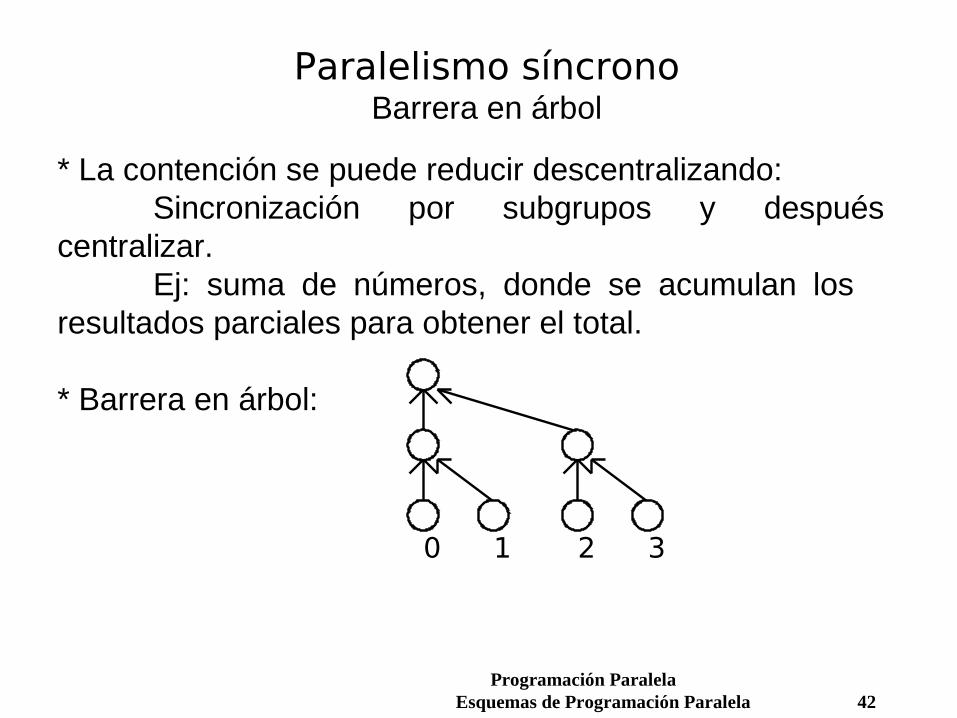
Paralelismo síncronoBarrera en árbol
* La contención se puede reducir descentralizando:Sincronización por subgrupos y después
centralizar.Ej: suma de números, donde se acumulan los
resultados parciales para obtener el total.
* Barrera en árbol:
0 1 2 3

Programación Paralela Esquemas de Programación Paralela 43
Paralelismo síncronoBarrera en árbol
barrera(i): (*i=0,...,p-1; número de proceso*) des=1 act=1 for j=1 to log p if act=1 des=des*2 if i mod des>0 activo=0 enviar a Pi-des/2 else recibir de Pi+des/2 endif endif endfor
Coste log p, pero más complejo que el lineal.
des=pfor j=1 to log p des=des/2 if i mod des=0 act=1 endif if act=1 if i mod (des*2)=0 enviar a Pi+des else recibir de Pi-des endif endifendfor
Programación Paralela Esquemas de Programación Paralela 44
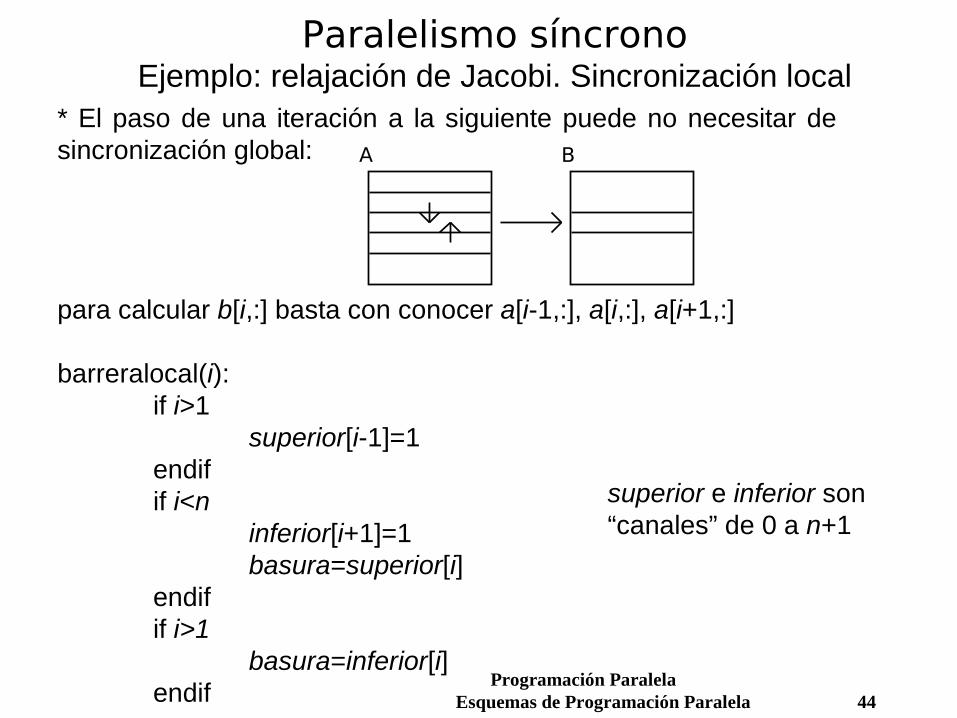
Paralelismo síncronoEjemplo: relajación de Jacobi. Sincronización local
* El paso de una iteración a la siguiente puede no necesitar de sincronización global:
para calcular b[i,:] basta con conocer a[i-1,:], a[i,:], a[i+1,:] barreralocal(i):
if i>1superior[i-1]=1
endifif i<n
inferior[i+1]=1basura=superior[i]
endifif i>1
basura=inferior[i]endif
superior e inferior son “canales” de 0 a n+1
A B

Programación Paralela Esquemas de Programación Paralela 45
Paralelismo síncronoEjemplo: relajación de Jacobi. Sincronización local
* En Memoria Distribuida: barreralocal(i):
if i>0enviar a Pi-1
endifif i<p-1
enviar a Pi+1endifif i>0
recibir de Pi-1endifif i<p-1
recibir de Pi+1endif
Además habría que enviar y recibir datos.
- Coste de las transferencias4α+4nβ
- Si se asignan bloques cuadrados
⇒ más escalable
8 8α β+ n
p
Programación Paralela Esquemas de Programación Paralela 46
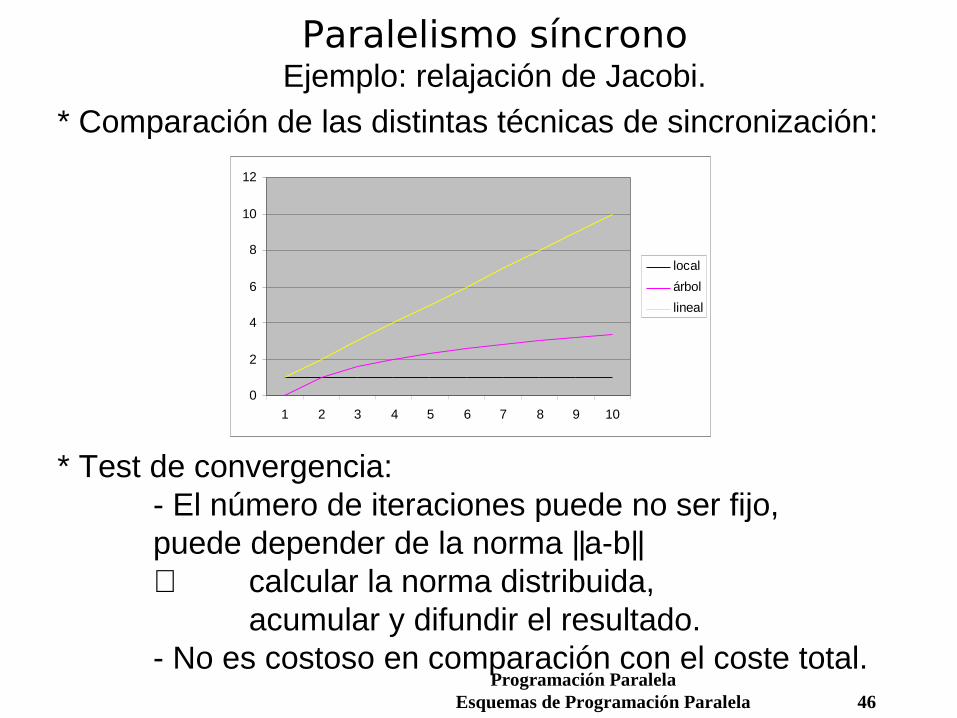
Paralelismo síncronoEjemplo: relajación de Jacobi.
* Comparación de las distintas técnicas de sincronización: * Test de convergencia:
- El número de iteraciones puede no ser fijo, puede depender de la norma ||a-b||⇒ calcular la norma distribuida,
acumular y difundir el resultado. - No es costoso en comparación con el coste total.
0
2
4
6
8
10
12
1 2 3 4 5 6 7 8 9 10
local
árbol
lineal

Programación Paralela Esquemas de Programación Paralela 47
Branch and Bound* En problemas de búsqueda en un espacio de soluciones.El espacio de búsqueda es un árbol donde cada nodo representa un subespacio de búsqueda.Obtener solución óptima explorando la menor cantidad posible de nodos.* Características:- expansión:
el trabajo en un nodo consiste en generar todos los hijos obteniendo por cada nodo unas cotas inferior y superior del beneficio alcanzable por una solución a partir de ese nodo, y una estimación del beneficio obtenible.- selección:
de todos los nodos vivos (de los que no se han generado los hijos) se elige uno según algún criterio: primero generado, el de mayor beneficio estimado, ...- poda:
para evitar generar nodos innecesarios, cuando la cota inferior de un nodo es mayor que la cota superior de otro, éste último se
puede eliminar * Es proceso secuencial: se necesita información global para la selección y la poda.

Programación Paralela Esquemas de Programación Paralela 48
Branch and BoundPosibilidades de paralelismo
* Búsqueda paralela usando diferentes algoritmos en diferentes procesadores:
diferencias en el cálculo de las cotas,de la estimación del beneficio,y del criterio de selección.
-Se repiten nodos pero hay pocas comunicaciones. * Expansión en paralelo de cada nodo:
- Se necesita que la expansión de cada nodo sea costosa:
gran número de hijos,alto coste de los cálculos de cada hijo.
- Gestión de la lista de nodos vivos centralizada ⇒ muchas comunicaciones.

Programación Paralela Esquemas de Programación Paralela 49
Branch and BoundPosibilidades de paralelismo
* Evaluación paralela de subproblemas:- De la lista de nodos vivos se asignan diferentes
nodos a cada procesador.- Posibilidades en la distribución de los nodos:
1. Estática: pocas comunicaciones,se pueden difundir las cotas para podar.
con asignación balanceada de nodos, con asignación ponderada de nodos.
2. Asignación dinámica con bolsa de tareas: más comunicaciones.
con actualización inmediata de la bolsa de tareas, con actualización pospuesta.
Programación Paralela Esquemas de Programación Paralela 50
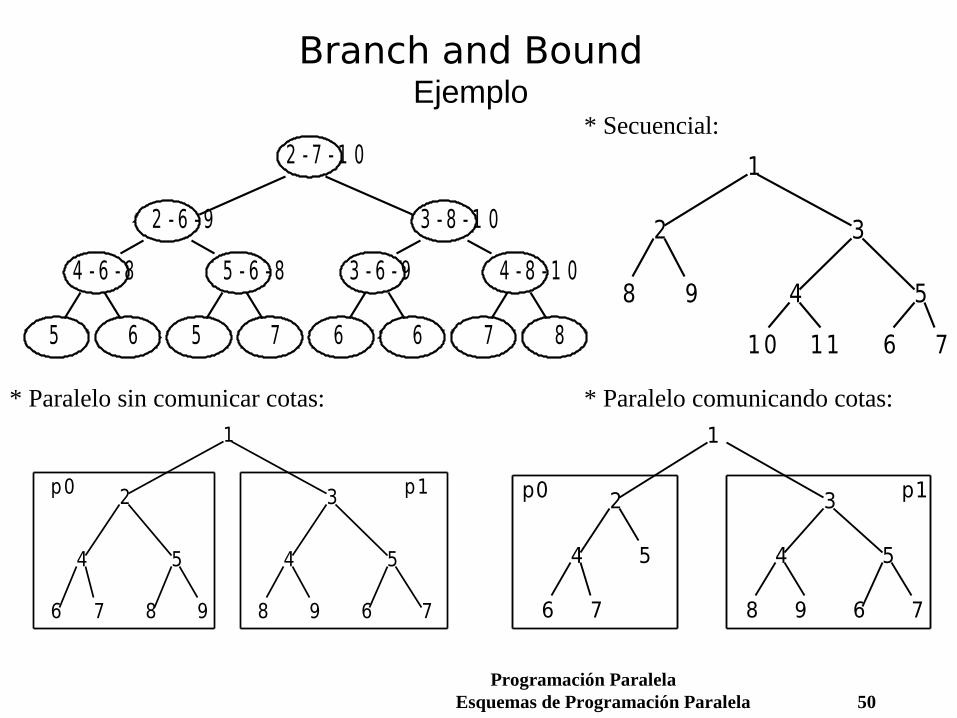
Branch and BoundEjemplo
2 - 7 - 1 0
2 - 6 - 9 3 - 8 - 1 0
4 - 6 - 8 5 - 6 - 8 3 - 6 - 9 4 - 8 - 1 0
5 6 5 7 6 6 7 8 10 11 6 7
4 58 9
2 3
1
6 7 8 9 8 9 6 7
4 5 4 5
2 3
1
p0 p1
6 7 8 9 6 7
4 5 4 5
2 3
1
p0 p1
* Secuencial:
* Paralelo sin comunicar cotas: * Paralelo comunicando cotas:

Programación Paralela Esquemas de Programación Paralela 51
Trabajadores replicados
* Se mantiene una bolsa central de tareas. * Trabajadores:
- Toman tareas de la bolsa.- Generan otras nuevas.
* Acaba la computación cuando la bolsa está vacía y todos los trabajadores han acabado. * Útil en problemas combinatorios: búsqueda en árbol. * Asignación dinámica de trabajos para balancear la computación.

Programación Paralela Esquemas de Programación Paralela 52
Trabajadores replicados* Bolsa de tareas:
conjunto de descriptores de tareas,cada descriptor especifica una computación.
* En Multiprocesadores:una estructura centralizada de la que los trabajadores toman
trabajos y posiblemente depositan otros nuevos* En Multicomputadores:
la estructura en la memoria de uno o varios procesadores,petición y depósito de tareas conllevan comunicación.
* Aspectos a tener en cuenta:- Contención:
Por ser la bolsa de tareas centralizada.Cuantos más procesadores mayor contención.
- Balanceo:Si se descentraliza la bolsa:mayor desbalanceo y menor contención⇒ compromiso entre contención y balanceo
- Terminación:El test de terminación es global ⇒ sincronización.

Programación Paralela Esquemas de Programación Paralela 53
Trabajadores replicadosEjemplo: algoritmo del camino más corto
En un grafo dirigido, encontrar el camino más corto de un vértice a los demás.
distancia←∞cola={1}distancia[1]=0while no vacía cola
x=el de menor distancia en la colafor i=1 to n
dist=distancia[x]+pesos[x,i]if dist<distancia[i]
distancia[i]=distif i no está en la cola
incluir i en la colaendif
endifendfor
endwhile
Estructuras:
vertices: 1..n
pesos: array[1..n,1..n]
distancia: array[1..n]
cola: conjunto de vértices para los que se ha actualizado la
distancia mínima.

Programación Paralela Esquemas de Programación Paralela 54
Trabajadores replicadosEjemplo: algoritmo del camino más corto
Ejemplo:
inicialmente: cola=1 distancias: 0,∞,∞,∞,∞paso1: cola=2,3 distancias: 0,4,8,∞,∞paso2: cola=4,3 distancias: 0,4,7,5,∞paso3: cola=3,5 distancias: 0,4,7,5,15paso4: cola=5 distancias: 0,4,7,5,12paso5: cola=∅ distancias: 0,4,7,5,12
1 2 3 4 5
1 4 8
2 3 1
3 5
4 2 10
5
∞ ∞ ∞∞ ∞ ∞∞ ∞ ∞ ∞∞ ∞ ∞∞ ∞ ∞ ∞ ∞

Programación Paralela Esquemas de Programación Paralela 55
Trabajadores replicadosEjemplo: algoritmo del camino más corto. Memoria Compartida
Programa: distancia←∞ enconjunto←false distancia[1]=0 enconjunto[1]=true #Pragma: llamada concurrente (for i=1 to p) trabajador(i) trabajador(i): tomar(i,v) while v<>-1 (*-1 indica que ha acabado*) bloquear enconjunto[v] enconjunto[v]=false desbloquear enconjunto[v] for j=1 to n if pesos[v,j]<∞ bloquear distancia[v] dist=distancia[v]+pesos[v,j] desbloquear distancia[v] bloquear distancia[j]
if dist<distancia[j] distancia[j]=dist desbloquear distancia[j] bloquear enconjunto[j] if not enconjunto[j] enconjunto[j]=true desbloquear enconjunto[j] poner(i,j) else desbloquear enconjunto[j] endif else desbloquear distancia[j] endif endif endforendwhile

Programación Paralela Esquemas de Programación Paralela 56
Trabajadores replicadosEjemplo: algoritmo del camino más corto. Memoria Compartida
Contadores: trabajadores=p (*trabajadores activos*)tareas=1 (*tareas por hacer*)
tomar(i,j):bloquear trabajadorescont=trabajadores-1trabajadores=contdesbloquear trabajadoresif cont=0
bloquear tareasif tareas=0
desbloquear tareasj=-1
elsedesbloquear tareasbloquear colaj=cabeza de coladesbloquear cola
endifelse
bloquear colaj=cabeza de coladesbloquear cola
endif
poner(i,j):bloquear tareastareas=tareas+1desbloquear tareasbloquear colainsertar j en coladesbloquear cola
El bloqueo con espera activa