Algoritmos de Ordenamiento y Búsqueda y Transformación de Llaves
21
Universidad Tecnológica de Panamá Facultad de Ingeniería en Sistemas Computacionales Departamento de Computación y Simulación de Sistemas Lic. en Ingeniería en Sistemas y Computación Estructura de Datos y Algoritmos II Profesora Yolanda de Miguelena Proyecto No.3 Algoritmos de Ordenamiento y Búsqueda y Transformación de Llaves Integrantes del Grupo Espinosa, Joel Giron, Juan Guerra, Jean Ocampo, Félix Pineda, Jorge Pitti, Ida Ramos, Alcibiades Tejada, Jamir Vivar, Luis 1-IL-121 16 de noviembre de 2011
-
Upload
luis-eduardo-vivar -
Category
Documents
-
view
238 -
download
1
description
Proyecto No.3 de Estructura de Datos y Algoritmos II, Profesora Yolanda Miguelena
Transcript of Algoritmos de Ordenamiento y Búsqueda y Transformación de Llaves

Universidad Tecnológica de Panamá
Facultad de Ingeniería en Sistemas Computacionales
Departamento de Computación y Simulación de Sistemas
Lic. en Ingeniería en Sistemas y Computación
Estructura de Datos y Algoritmos II
Profesora Yolanda de Miguelena
Proyecto No.3
Algoritmos de Ordenamiento y Búsqueda y Transformación de Llaves
Integrantes del Grupo
Espinosa, Joel
Giron, Juan
Guerra, Jean
Ocampo, Félix
Pineda, Jorge
Pitti, Ida
Ramos, Alcibiades
Tejada, Jamir
Vivar, Luis
1-IL-121
16 de noviembre de 2011

Proyecto No.3
2
Algoritmos de Ordenamiento y Búsqueda
1. Notación de la Gran O (Big O)
Cuando trabajamos con algoritmos, normalmente nos interesa el rendimiento de éste. Nos
interesa saber, por ejemplo, de qué forma se comporta el algoritmo dada una cantidad
determinada de datos a procesar. Científicos en computación emplean una forma de categorizar y
comparar los algoritmos, de tal suerte que se pueda categorizar de forma rápida el rendimiento de
un algoritmo. Esta forma de medir se llama la Notación Gran O: Big-O Notation (BON).
Esta notación expresa la ejecución de un algoritmo dado un parámetro de entrada (i.e. el tamaño
de datos a procesar). La notación normalmente es O(n)
Básicamente notación gran O:
crece en forma de la gráfica matemática.
nos permite comparar los costos relativos de dos o más algoritmos para resolver el mismo problema.
Permite análisis de algoritmos, estima el consumo de recursos de un algoritmo.
Permite análisis de algoritmos también les da una herramienta a los diseñadores de algoritmos para estimar si una solución propuesta es probable que satisfaga las restricciones de recursos de un problema.
El concepto de razón de crecimiento, es la razón a la cual el costo de un algoritmo crece conforme el tamaño de la entrada crece.
Una función f(n) se define de orden O(g(n)), es decir, f(n) = O(g(n)) si existen constantes positivas n0 y c tales que: | f(n) | = c * <= | g(n) | , para toda n > n0100 n3 => O(n3) ::
6n2 + 2n + 4 => O(n2)
Tipo Notación Significado
Constante O(1) La ejecución es independiente del número de elementos a procesar.
Logarítmica O(log(n)) La ejecución crece logarítmicamente con respecto al número de elementos a procesar.
Lineal O(n) La ejecución crece linealmente, con el mismo factor, conforme crece el número de elementos a procesar.
N Log N O(n * log(n))
La ejecución crece como un producto de complejidad lineal y logarítmica.
Cuadrática O(n2) La ejecución crece de forma cuadrática con respecto al número de elementos a procesar.

Proyecto No.3
3
1024 => O(1)
1+2+3+4+...+n-1+n= n * (n+1)/2 = O(n2)
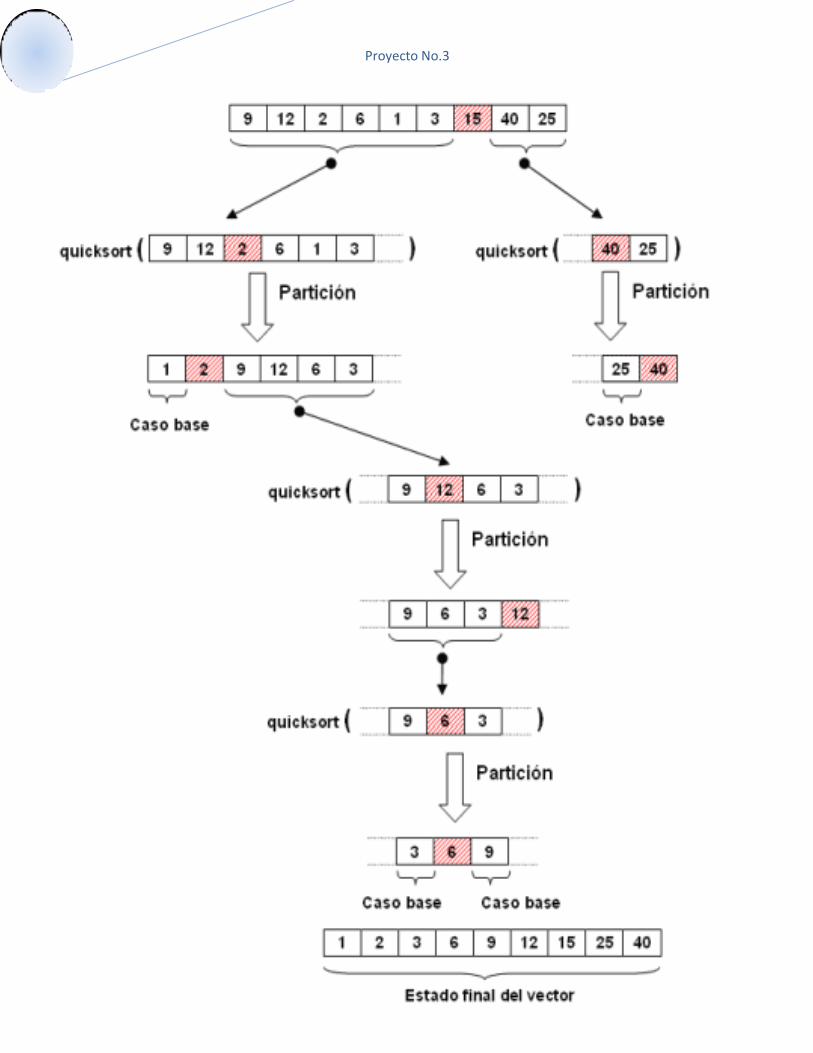
2. Método de QuickSort
Esta es probablemente la técnica más rápida conocida. Fue desarrollada por C.A.R. Hoare en 1960. El algoritmo original es recursivo, pero se utilizan versiones iterativas para mejorar su rendimiento (los algoritmos recursivos son en general más lentos que los iterativos, y consumen más recursos). El algoritmo fundamental es el siguiente:
Eliges un elemento de la lista. Puede ser cualquiera (en Optimizando veremos una forma más efectiva). Lo llamaremos elemento de división.
Buscas la posición que le corresponde en la lista ordenada (explicado más abajo). Acomodas los elementos de la lista a cada lado del elemento de división, de manera que a
un lado queden todos los menores que él y al otro los mayores (explicado más abajo también). En este momento el elemento de división separa la lista en dos sub-listas (de ahí su nombre).
Realizas esto de forma recursiva para cada sub-lista mientras éstas tengan un largo mayor que 1. Una vez terminado este proceso todos los elementos estarán ordenados.
Una idea preliminar para ubicar el elemento de división en su posición final sería contar la cantidad de elementos menores y colocarlo un lugar más arriba. Pero luego habría que mover todos estos elementos a la izquierda del elemento, para que se cumpla la condición y pueda aplicarse la recursividad. Reflexionando un poco más se obtiene un procedimiento mucho más efectivo. Se utilizan dos índices: i, al que llamaremos contador por la izquierda, y j, al que llamaremos contador por la derecha. El algoritmo es éste:
Recorres la lista simultáneamente con i y j: por la izquierda con i (desde el primer elemento), y por la derecha con j (desde el último elemento).
Cuando lista[i] sea mayor que el elemento de división y lista[j] sea menor los intercambias.
Repites esto hasta que se crucen los índices. El punto en que se cruzan los índices es la posición adecuada para colocar el elemento de
división, porque sabemos que a un lado los elementos son todos menores y al otro son todos mayores (o habrían sido intercambiados).

Proyecto No.3
4
Al finalizar este procedimiento el elemento de división queda en una posición en que todos los elementos a su izquierda son menores que él, y los que están a su derecha son mayores. Análisis de la eficiencia del Método de Quicksort Diversos estudios realizados sobre el comportamiento del mismo demuestran que si se escoge en cada pasada el elemento que ocupa la posición central del conjunto de datos a analizar, el número de pasadas necesarias para ordenar es del orden de Log n. Respecto al número de comparaciones, si el tamaño del arreglo es una potencia de 2, en la primera pasada realizará (n-1) comparaciones, en la 2ª pasada realizará (n-1)/2 comparaciones, pero en 2 conjuntos diferentes, en la tercera pasada realizará (n-1)/4 comparaciones pero en 4 conjuntos diferentes y así sucesivamente.
Código para el método Quicksort recursivo
void quicksort(int a[], int l, int r)
{
int i,j,v;
if(r > l)
{
v = a[r];
i = l-1;
j = r;
for(;;)
{
while(a[++i] < v && i < r);
while(a[--j] > v && j > l);
if( i >= j)
break;
swap(a,i,j);
}
swap(a,i,r);
quicksort(a,l,i-1);
quicksort(a,i+1,r);
}
}
Proyecto No.3
5

Proyecto No.3
6
3. Método de Heapsort
Introducción al método:
Recordemos que un montículo Max es un árbol binario completo cuyos elementos están
ordenados del siguiente modo: para cada subárbol se cumple que la raíz es mayor que ambos
hijos. Si el montículo fuera Min, la raíz de cada subárbol tiene que cumplir con ser menor que sus
hijos.
Recordamos que, si bien un montículo se define como un árbol, para representar éste se utiliza un
array de datos, en el que se acceden a padres e hijos utilizando las siguientes transformaciones
sobre sus índices. Si el montículo está almacenado en el array A, el padre de A[i] es A[i/2]
(truncando hacia abajo), el hijo izquierdo de A[i] es A[2*i] y el hijo derecho de A[i] es A[2*i+1].
Características.
Es un algoritmo que se construye utilizando las propiedades de los montículos binarios.
El orden de ejecución para el peor caso es O(N·log(N)), siendo N el tamaño de la entrada.
Aunque teóricamente es más rápido que los algoritmos de ordenación vistos hasta aquí,
en la práctica es más lento que el algoritmo de ordenación de Shell utilizando la secuencia
de incrementos de Sedgewick.
El ordenamiento por montículos (heapsort en inglés) es un algoritmo de ordenamiento no recursivo, no estable, con complejidad computacional Θ(nlog n). Este algoritmo consiste en almacenar todos los elementos del vector a ordenar en un montículo (heap), y luego extraer el nodo que queda como nodo raíz del montículo (cima) en sucesivas iteraciones obteniendo el conjunto ordenado. Basa su funcionamiento en una propiedad de los montículos, por la cual, la cima contiene siempre el menor elemento (o el mayor, según se haya definido el montículo) de todos los almacenados en él.

Proyecto No.3
7
4. método de Búsqueda de Cadena Knuth-Morris Pratt.
Suponga que se está comparando el patrón y el texto en una posición dada, cuando se encuentra una discrepancia.
Sea X la parte del patrón que calza con el texto, e Y la correspondiente parte del texto, y suponga que el largo de X es j. El algoritmo de fuerza bruta mueve el patrón una posición hacia la derecha, sin embargo, esto puede o no puede ser lo correcto en el sentido que los primeros j-1 caracteres de X pueden o no pueden calzar los últimos j-1caracteres de Y.
La observación clave que realiza el algoritmo Knuth-Morris-Pratt (en adelante KMP) es que X es igual a Y, por lo que la pregunta planteada en el párrafo anterior puede ser respondida mirando solamente el patrón de búsqueda, lo cual permite pre-calcular la respuesta y almacenarla en una tabla.
Por lo tanto, si deslizar el patrón en una posición no funciona, se puede intentar deslizarlo en 2, 3, ..., hasta j posiciones.
Se define la función de fracaso (failure function) del patrón como:
Intuitivamente, f(j) es el largo del mayor prefijo de X que además es sufijo de X. Note que j = 1 es un caso especial, puesto que si hay una discrepancia en b1 el patrón se desliza en una posición.

Proyecto No.3
8
Si se detecta una discrepancia entre el patrón y el texto cuando se trata de calzar bj+1, se desliza el patrón de manera que bf(j) se encuentre donde bj se encontraba, y se intenta calzar nuevamente.
Suponiendo que se tiene f(j) pre-calculado, la implementación del algoritmo KMP es la siguiente:
// n = largo del texto // m = largo del patron // Los indices comienzan desde 1 int k=0; int j=0; while (k<n && j<m) { while (j>0 && texto[k+1]!=patron[j+1]) { j=f[j]; } if (texto[k+1])==patron[j+1])) { j++; } k++; } // j==m => calce, j el patron estaba en el texto
Ejemplo:

Proyecto No.3
9
El tiempo de ejecución de este algoritmo no es difícil de analizar, pero es necesario ser cuidadoso al hacerlo. Dado que se tienen dos ciclos anidados, se puede acotar el tiempo de ejecución por el número de veces que se ejecuta el ciclo externo (menor o igual a n) por el número de veces que se
ejecuta el ciclo interno (menor o igual a m), por lo que la cota es igual a , ¡que es igual a lo que demora el algoritmo de fuerza bruta!.
El análisis descrito es pesimista. Note que el número total de veces que el ciclo interior es ejecutado es menor o igual al número de veces que se puede reducir j, dado que f(j)<j. Pero j comienza desde cero y es siempre mayor o igual que cero, por lo que dicho número es menor o igual al número de veces que j es incrementado, el cual es menor que n. Por lo tanto, el
tiempo total de ejecución es . Por otra parte, k nunca es reducido, lo que implica que el algoritmo nunca se devuelve en el texto.
Queda por resolver el problema de definir la función de fracaso, f(j). Esto se puede realizar inductivamente. Para empezar, f(1)=0 por definición. Para calcular f(j+1) suponga que ya se tienen almacenados los valores de f(1), f(2), ..., f(j). Se desea encontrar un i+1 tal que el (i+1)-ésimo carácter del patrón sea igual al (j+1)-ésimo carácter del patrón.
Para esto se debe cumplir que i=f(j). Si bi+1=bj+1, entonces f(j+1)=i+1. En caso contrario, se reemplaza i por f(i) y se verifica nuevamente la condición.
El algoritmo resultante es el siguiente (note que es similar al algoritmo KMP):
// m es largo del patron // los indices comienzan desde 1 int[] f=new int[m]; f[1]=0; int j=1; int i; while (j<m) { i=f[j]; while (i>0 && patron[i+1]!=patron[j+1]) { i=f[i]; } if (patron[i+1]==patron[j+1])

Proyecto No.3
10
{ f[j+1]=i+1; } else { f[j+1]=0; } j++; }
El tiempo de ejecución para calcular la función de fracaso puede ser acotado por los incrementos y
decrementos de la variable i, que es .
Por lo tanto, el tiempo total de ejecución del algoritmo, incluyendo el pre-procesamiento del
patrón, es .

Proyecto No.3
11
5. método de Búsqueda de Boyer-Moore.
El algoritmo de Boyer-Moore, considerado el algoritmo más eficiente en la búsqueda de patrones en cadena de caracteres, se basa en desplazar la ventana de comparación lo máximo posible.
El algoritmo se desplaza dentro de la cadena de búsqueda de izquierda a derecha, y dentro del patrón de derecha a izquierda. La mayor eficiencia se consigue minimizando el número de comparaciones entre caracteres, desplazando lo máximo posible la venta de comparación, a costa de una computación previa.
Notación
y: cadena dónde se busca.
x: patrón de búsqueda.
| y | = n, longitud de y.
| x | = m, longitud de x.
j: posición en y desde dónde se prueba la coincidencia.
i: posición en x de comparación, dónde se produce una no coincidencia , y[j+i] <>
x[i], y[j+i] = b, x[i] = a.
u: coincidencia en la comparación, sufijo de x, u = y[j+i+..j+m] = x[i+1..m-1].
v: prefijo de x.
s: salto del patrón para la siguiente comparación.
Al producirse una ocurrencia del patrón, o un error en la comparación de un carácter, se calcula el desplazamiento máximo del patrón a lo largo de la cadena de búsqueda.
Partimos de una situación en que no hay coincidencia, existe diferencia entre y[j+i] y x[i], pero las posiciones de x siguientes a i sí coinciden con sus asociadas en y, u = y[j+i+..j+m] = x[i+1..m-1]; hacer notar que u es sufijo de x.
El desplazamiento de x a lo largo de y se limita a causa del carácter en y que produjo la no coincidencia, y[i+j] (1), y los caracteres de x posteriores a i (2), sufijo de x que tenía coincidencia parcial con y.
(1) Teniendo en cuenta el carácter que produjo la no coincidencia en y, y[i+j] = b, el desplazamiento máximo, s, será la distancia entre la aparición más a la derecha de b en x[0..m-2] y la longitud de x, m. La nueva j sería j’=j+s, lo que se consigue es alinear las dos coincidencias de b en x e y, desde dónde es posible que se produzca una coincidencia del patrón. Se considera el intervalo 0..m-2, porque si se da el caso de que b es igual al último carácter de x, el desplazamiento sería 0, y podría provocar un bucle infinito debido a que el patrón no varía su posición.

Proyecto No.3
12
(1)
(2) Teniendo en cuenta los caracteres posteriores a i en x (u, sufijo de x), que coinciden de forma parcial con y, hay que alinear u lo más a la derecha posible de x, sin que esté precedido por x[i] = a (2.a); al no estar u ya precedido por x[i] = a <> x[i-s] = c, en la nueva posición de x respecto de y, sabemos que existe la coincidencia u precedida por c, es posible que se produzca una ocurrencia en y. Si no se encuentra la situación anterior, se tratará de alinear el mayor sufijo posible de x con un prefijo v también de x (2.b); como u coincide parcialmente en y, al buscar el prefijo v de x que también es sufijo de x, v también está en y. Si no se producen ninguno de los dos casos anteriores, el patrón se podrá desplazar toda su longitud.
(2.a)
(2.b)
Proyecto No.3
13
Transformación de llaves
1. Definición y conceptos
El método de transformación de claves consiste en convertir la clave dada (numérica o
alfanumérica) en una dirección (índice) dentro del array. La correspondencia entre las claves y la
dirección en el medio de almacenamiento o Array se establece por una función de conversión
(función o hash).
Así por ejemplo en el caso de una lista de empleados (100) de una pequeña empresa. Si cada uno
de los cien empleados tiene un número de identificación (clave) del 1 al 100, evidentemente puede
existir una correspondía directa entre la clave y la dirección definida en un vector o un Array de 100
elementos.
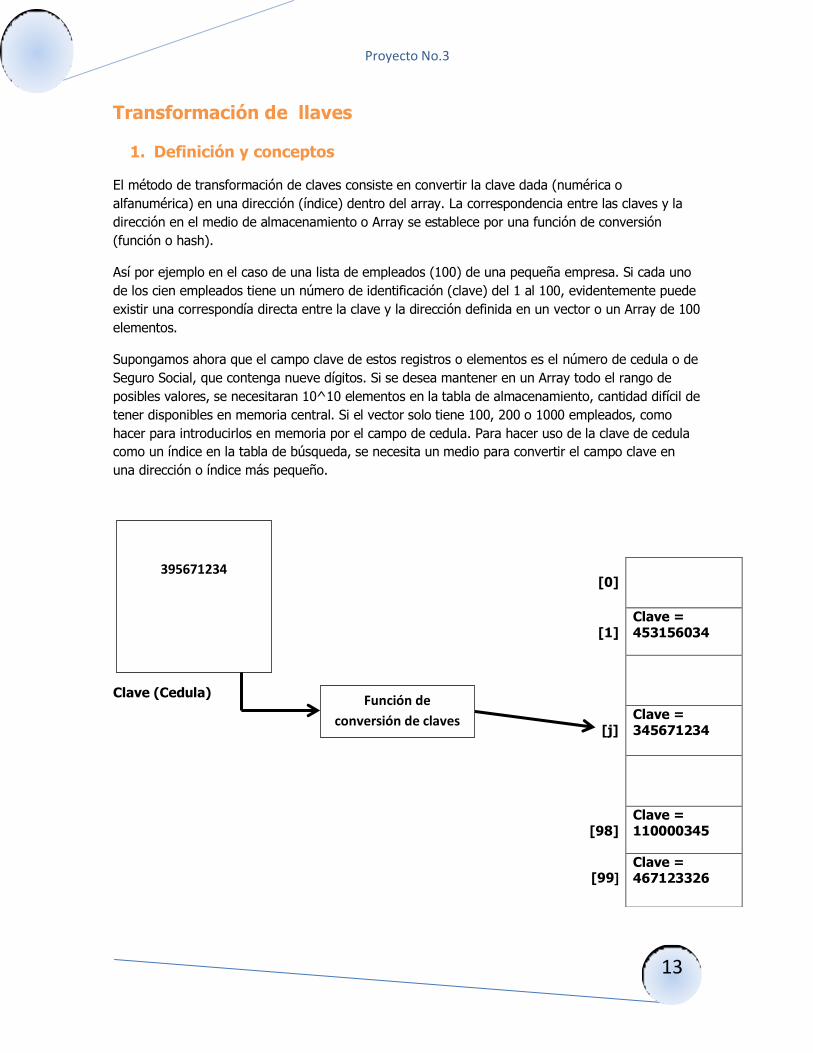
Supongamos ahora que el campo clave de estos registros o elementos es el número de cedula o de
Seguro Social, que contenga nueve dígitos. Si se desea mantener en un Array todo el rango de
posibles valores, se necesitaran 10^10 elementos en la tabla de almacenamiento, cantidad difícil de
tener disponibles en memoria central. Si el vector solo tiene 100, 200 o 1000 empleados, como
hacer para introducirlos en memoria por el campo de cedula. Para hacer uso de la clave de cedula
como un índice en la tabla de búsqueda, se necesita un medio para convertir el campo clave en
una dirección o índice más pequeño.
Clave (Cedula)
[0]
[1]
Clave = 453156034
[j]
Clave = 345671234
[98]
Clave = 110000345
[99]
Clave = 467123326
395671234
Función de
conversión de claves

Proyecto No.3
14
La función de transformación de clave, H(k) convierta la clave (k) en un dirección (d),
evidentemente es esta entonces una función de paso o conversión de múltiples claves a
direcciones. Dada una clave k, el primer paso en la operación de búsqueda es calcular su índice
asociado dH(k) y el segundo paso –evidentemente necesario- es verificar si o no el elemento con
la clave k es identificado verdaderamente por d en el array T.
La idea básica de este método consiste en aplicar una función que traduce un conjunto de posibles valores llave en un rango de direcciones relativas. Un problema potencial encontrado en este proceso, es que tal función no puede ser uno a uno; las direcciones calculadas pueden no ser todas únicas, cuando R(k1 )= R(k2) Pero: K1 diferente de K2 decimos que hay una colisión. A dos llaves diferentes que les corresponda la misma dirección relativa se les llama sinónimos.
A las técnicas de cálculo de direcciones también se les conoce como:
Técnicas de almacenamiento disperso Técnicas aleatorias Métodos de transformación de llave - a- dirección Técnicas de direccionamiento directo Métodos de tabla Hash Métodos de Hashing
Pero el término más usado es el de hashing. Al cálculo que se realiza para obtener una dirección a partir de una llave se le conoce como función hash. Ventaja
1. Se pueden usar los valores naturales de la llave, puesto que se traducen internamente a direcciones fáciles de localizar
2. Se logra independencia lógica y física, debido a que los valores de las llaves son independientes del espacio de direcciones
3. No se requiere almacenamiento adicional para los índices.
Desventajas
1. No pueden usarse registros de longitud variable 2. El archivo no está clasificado 3. No permite llaves repetidas 4. Solo permite acceso por una sola llave
Costos
Tiempo de procesamiento requerido para la aplicación de la función hash Tiempo de procesamiento y los accesos E/S requeridos para solucionar las
colisiones.

Proyecto No.3
15
La eficiencia de una función hash depende de:
1. La distribución de los valores de llave que realmente se usan 2. El número de valores de llave que realmente están en uso con respecto al tamaño
del espacio de direcciones 3. El número de registros que pueden almacenarse en una dirección dad sin causar
una colisión 4. La técnica usada para resolver el problema de las colisiones
2. Técnicas de cálculo de direcciones
Existen numerosos métodos de transformación de claves. Todos ellos tienen en común la necesidad
de convertir claves en direcciones. En esencia la función de conversión equivale a una caja negra
que podríamos llamar calculador de direcciones. Cuando se desea localizar un elemento de clave x,
el indicador de direcciones indicara en qué posición del array estará el elemento.
2.1 Hashing por residuo
La idea de este método es la de dividir el valor de la llave entre un numero apropiado, y después utilizar el residuo de la división como dirección relativa para el registro (dirección = llave módulo divisor).
Mientras que el valor calculado real de una dirección relativa, dados tanto un valor de llave como el divisor, es directo; la elección del divisor apropiado puede no ser tan simple. Existen varios factores que deben considerarse para seleccionar el divisor:
1. El rango de valores que resultan de la operación "llave % divisor", va desde cero hasta el divisor 1. Luego, el divisor determina el tamaño del espacio de direcciones relativas. Si se sabe que el archivo va a contener por lo menos n registros, entonces tendremos que hacer que divisor > n, suponiendo que solamente un registro puede ser almacenado en una dirección relativa dada.
2. El divisor deberá seleccionarse de tal forma que la probabilidad de colisión sea minimizada. ¿Cómo escoger este número? Mediante investigaciones se ha demostrado que los divisores que son números pares tienden a comportase pobremente, especialmente con los conjuntos de valores de llave que son predominantemente impares. Algunas investigaciones sugieren que el divisor deberá ser un número primo. Sin embargo, otras sugieren que los divisores no primos trabajan también como los divisores primos, siempre y cuando los divisores no primos no contengan ningún factor primo menor de 20. Lo más común es elegir el número primo más próximo al total de direcciones.
Todas las funciones hash comienzan a trabajar probablemente cuando el archivo está casi lleno. Por lo general el máximo factor de carga que puede tolerarse en un archivo para un rendimiento razonable es de entre el 70 % y 80 %.

Proyecto No.3
16
2.2 Hashing por cuadrado medio
En esta técnica, la llave es elevada al cuadrado, después algunos dígitos específicos se extraen de la mitad del resultado para constituir la dirección relativa. Si se desea una dirección de n dígitos, entonces los dígitos se truncan en ambos extremos de la llave elevada al cuadrado, tomando n dígitos intermedios. Las mismas posiciones de n dígitos deben extraerse para cada llave. Ejemplo: Utilizando esta función hashing el tamaño del archivo resultante es de 10n donde n es el número de dígitos extraídos de los valores de la llave elevada al cuadrado.
2.3 Hashing por pliegue
En esta técnica el valor de la llave es particionada en varias partes, cada una de las cuales (Excepto la última) tiene el mismo número de dígitos que tiene la dirección relativa objetivo. Estas particiones son después plegadas una sobre otra y sumadas. El resultado, es la dirección relativa. Igual que para el método del medio del cuadrado, el tamaño del espacio de direcciones relativas es una potencia de 10.
La definición que encontramos en el libro de texto nos dice que: esta técnica consiste en la
partición de la clave en diferentes partes y la combinación de las partes en un mondo conveniente
(sumas o multiplicaciones) para obtener el índice.
La clave x se divide en varias partes (x1, x2,…,xn) donde cada parte, con la única posible excepción
de la última parte tiene el mismo número de dígitos que la dirección más alta que podrá ser
utilizada.
h(x)= x1+ x2+…+xn
En esta operación se desprecian los dígitos más significativos que se obtengan de arrastre o
acarreo.
3. Comparación entre las funciones Hash
Aunque alguna otra técnica pueda desempeñarse mejor en situaciones particulares, la técnica del residuo de la división proporciona el mejor desempeño. Ninguna función hash se desempeña siempre mejor que las otras. El método del medio del cuadrado puede aplicarse en archivos con factores de cargas bastantes bajas para dar generalmente un buen desempeño. El método de pliegues puede ser la técnica más fácil de calcular pero produce resultados bastante erráticos, a menos que la longitud de la llave se aproximadamente igual a la longitud de la dirección. Si la distribución de los valores de llaves no es conocida, entonces el método del residuo de la división es preferible. Note que el hashing puede ser aplicado a llaves no numéricas. Las

Proyecto No.3
17
posiciones de ordenamiento de secuencia de los caracteres en un valor de llave pueden ser utilizadas como sus equivalentes "numéricos". Alternativamente, el algoritmo hash actúa sobre las representaciones binarias de los caracteres. Todas las funciones hash presentadas tienen destinado un espacio de tamaño fijo. Aumentar el tamaño del archivo relativo creado al usar una de estas funciones, implica cambiar la función hash, para que se refiera a un espacio mayor y volver a cargar el nuevo archivo.
4. Métodos para el manejo del problema de las colisiones
La función de conversión h(x) no siempre proporciona valores distintos, puede suceder que para dos claves diferentes K1 y K2 se obtenga la misma dirección. Esta situación se denomina colisión y se deben encontrar métodos para su correcta resolución.
Una colisión de hash es una situación que se produce cuando dos entradas distintas a
una función de hash producen la misma salida.
Es matemáticamente imposible que una función de hash carezca de colisiones, ya que el número
potencial de posibles entradas es mayor que el número de salidas que puede producir un hash. Sin
embargo, las colisiones se producen más frecuentemente en los malos algoritmos. En ciertas
aplicaciones especializadas con un relativamente pequeño número de entradas que son conocidas
de antemano es posible construir una función de hash perfecta, que se asegura que todas las
entradas tengan una salida diferente. Pero en una función en la cual se puede introducir datos de
longitud arbitraria y que devuelve un hash de tamaño fijo (como MD5), siempre habrá colisiones,
dado que un hash dado puede pertenecer a un infinito número de entradas.
Ahora considere las llaves K1 y K2 que son sinónimas para la función hash R. Si K1 es almacenada primero en el archivo y su dirección es R(K1), entonces se dice que K1 esta almacenado en su dirección de origen.
Existen dos métodos básicos para determinar dónde debe ser alojado K2 :
Direccionamiento abierto.- Se encuentra entre dirección de origen para K2 dentro del archivo.
Separación de desborde (Área de desborde).- Se encuentra una dirección para K2 fuera del área principal del archivo, en un área especial de desborde, que es utilizada exclusivamente para almacenar registro que no pueden ser asignados en su dirección de origen
Los métodos más conocidos para resolver colisiones son:

Proyecto No.3
18
Sondeo lineal Que es una técnica de direccionamiento abierto. Este es un proceso de búsqueda secuencial desde la dirección de origen para encontrar la siguiente localidad vacía. Esta técnica es también conocida como método de desbordamiento consecutivo. Para almacenar un registro por hashing con sondeo lineal, la dirección no debe caer fuera del límite del archivo, En lugar de terminar cuando el límite del espacio de dirección se alcanza, se regresa al inicio del espacio y sondeamos desde ahí. Por lo que debe ser posible detectar si la dirección base ha sido encontrada de nuevo, lo cual indica que el archivo está lleno y no hay espacio para la llave. Para la búsqueda de un registro por hashing con sondeo lineal, los valores de llave de los registros encontrados en la dirección de origen, y en las direcciones alcanzadas con el sondeo lineal, deberá compararse con el valor de la llave buscada, para determinar si el registro objetivo ha sido localizado o no.

Proyecto No.3
19
El sondeo lineal puede usarse para cualquier técnica de hashing. Si se emplea sondeo lineal para almacenar registros, también deberá emplearse para recuperarlos.
Doble hashing
En esta técnica se aplica una segunda función hash para combinar la llave original con el resultado del primer hash. El resultado del segundo hash puede situarse dentro del mismo archivo o en un archivo de sobre flujo independiente; de cualquier modo, será necesario algún método de solución si ocurren colisiones durante el segundo hash.
La ventaja del método de separación de desborde es que reduce la situación de una doble colisión, la cual puede ocurrir con el método de direccionamiento abierto, en el cual un registro que no está almacenado en su dirección de origen desplazara a otro registro, el que después buscará su dirección de origen. Esto puede evitarse con direccionamiento abierto, simplemente moviendo el registro extraño a otra localidad y almacenando al nuevo registro en la dirección de origen ahora vacía. Puede ser aplicado como cualquier direccionamiento abierto o técnica de separación de desborde. Para ambas métodos para la solución de colisiones existen técnicas para mejorar su desempeño como:
1.- Encadenamiento de sinónimos Una buena manera de mejorar la eficiencia de un archivo que utiliza el cálculo de direcciones, sin directorio auxiliar para guiar la recuperación de registros, es el encadenamiento de sinónimos. Mantener una lista ligada de registros, con la misma dirección de origen, no reduce el número de colisiones, pero reduce los tiempos de acceso para recuperar los registros que no se encuentran en su

Proyecto No.3
20
localidad de origen. El encadenamiento de sinónimos puede emplearse con cualquier técnica de solución de colisiones. Cuando un registro debe ser recuperado del archivo, solo los sinónimos de la llave objetivo son accesados.
2.- Direccionamiento por cubetas
Otro enfoque para resolver el problema de las colisiones es asignar bloques de espacio (cubetas), que pueden acomodar ocurrencias múltiples de registros, en lugar de asignar celdas individuales a registros. Cuando una cubeta es desbordada, alguna nueva localización deberá ser encontrada para el registro. Los métodos para el problema de sobrecupo son básicamente el mismo que los métodos para resolver colisiones.
COMPARACIÓN ENTRE SONDEO LINEAL Y DOBLE HASHING
De ambos métodos resultan distribuciones diferentes de sinónimos en un archivo relativo. Para aquellos casos en que el factor de carga es bajo (< 0.5), el sondeo lineal tiende a agrupar los sinónimos, mientras que el doble hashing tiende a dispersar los sinónimos más ampliamente a travéz del espacio de direcciones. El doble hashing tiende a comportarse casi también como el sondeo lineal con factores de carga pequeños (< 0.5), pero actúa un poco mejor para factores de carga mayores. Con un factor de carga > 80 %, el sondeo lineal por lo general resulta tener un comportamiento terrible, mientras que el doble hashing es bastante tolerable para búsquedas exitosas pero no así en búsquedas no exitosas.

Proyecto No.3
21
Bibliografía y Web grafía
1. https://sites.google.com/site/fernandoagomezf/programacion-en-c/tips-de-programador-
c/algoritmos/la-notacion-big-o
2. http://lc.fie.umich.mx/~calderon/programacion/notas/Quicksort.html
3. http://c.conclase.net/orden/?cap=quicksort
4. http://es.wikipedia.org/wiki/Heapsort
5. http://es.wikipedia.org/wiki/Algoritmo_de_b%C3%BAsqueda_de_cadenas_Boyer-Moore
6. http://www.geocities.ws/luisja80/esp/boyermoore.html
7. http://es.wikipedia.org/wiki/Colisi%C3%B3n_(hash)
8. Fundamentos de Programación, Algoritmos, estructura de datos y objetos. Luis Joyanes
Aguilar. Cuarta Edición.