
6. Teoría de decisión - ITAMallman.rhon.itam.mx/~lnieto/index_archivos/NotasEP3.pdf · PROFESOR:...
43
PROFESOR: LUIS E. NIETO BARAJAS Especialización en Evaluación de Proyectos Estadística y Probabilidad 193 6. Teoría de decisión 6.1 Fundamentos y Axiomas de coherencia El OBJETIVO de la estadística, y en particular de la estadística Bayesiana, es proporcionar una metodología para analizar adecuadamente la información con la que se cuenta (análisis de datos) y decidir de manera razonable sobre la mejor forma de actuar (teoría de decisión). DIAGRAMA de la Estadística: Tipos de INFERENCIA: Clásica Bayesiana Paramétrica √√√ √√ No paramétrica √√ √ Población Muestra Muestreo Inferencia Análisis de datos Toma de decisiones
Transcript of 6. Teoría de decisión - ITAMallman.rhon.itam.mx/~lnieto/index_archivos/NotasEP3.pdf · PROFESOR:...

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 193
6. Teoría de decisión
6.1 Fundamentos y Axiomas de coherencia
El OBJETIVO de la estadística, y en particular de la estadística
Bayesiana, es proporcionar una metodología para analizar
adecuadamente la información con la que se cuenta (análisis de
datos) y decidir de manera razonable sobre la mejor forma de
actuar (teoría de decisión).
DIAGRAMA de la Estadística:
Tipos de INFERENCIA:
Clásica Bayesiana
Paramétrica √√√ √√
No paramétrica √√ √
Población
Muestra
Muestreo Inferencia
AAnnáálliissiiss ddee ddaattooss
TToommaa ddee ddeecciissiioonneess

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 194
La estadística esta basada en la TEORÍA DE PROBABILIDADES.
Formalmente la probabilidad es una función que cumple con ciertas
condiciones (axiomas de la probabilidad), pero en general puede
entenderse como una medida o cuantificación de la incertidumbre.
Aunque la definición de función de probabilidad es una, existen
varias interpretaciones dela probabilidad: clásica, frecuentista y
subjetiva. La METODOLOGÍA BAYESIANA está basada en la
interpretación subjetiva de la probabilidad y tiene como punto
central el Teorema de Bayes.
Reverendo Thomas Bayes (1702-1761).
La inferencia estadística es una forma de tomar decisiones. Los
métodos clásicos de inferencia ignoran los aspectos relativos a la
toma de decisiones, en cambio los métodos Bayesianos sí los
toman en cuenta.
¿Qué es un problema de decisión?. Nos enfrentamos a un
problema de decisión cuando debemos elegir entre dos o más
formas de actuar.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 195
La TOMA DE DECISIONES es un aspecto primordial en la vida de un
profesionista, por ejemplo, un administrador debe de tomar
decisiones constantemente en un ambiente de incertidumbre;
decisiones sobre el proyecto más verosímil o la oportunidad de
realizar una inversión.
La TEORÍA DE DECISIÓN propone un método de tomar decisiones
basado en unos principios básicos sobre la elección coherente
entre opciones alternativas.
ELEMENTOS DE UN PROBLEMA DE DECISIÓN en ambiente de
incertidumbre:
Un problema de decisión se define por la cuarteta (D, E, C, ≤),
donde:
D : Espacio de opciones. Es el conjunto de posibles alternativas,
debe de construirse de manera que sea exhaustivo (que agote
todas las posibilidades que en principio parezcan razonables) y
excluyente (que la elección de uno de los elementos de D excluya
la elección de cualquier otro).
D = d1,d2,...,dk.
E : Espacio de eventos inciertos. Contiene los eventos inciertos
relevantes al problema de decisión.
Ei = Ei1,Ei2,...,Eimi., i=1,2,…,k.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 196
C : Espacio de consecuencias. Es el conjunto de consecuencias
posibles y describe las consecuencias de elegir una decisión.
C = c1,c2,...,ck.
≤ : Relación de preferencia entre las distintas opciones. Se define
de manera que d1≤d2 si d2 es preferido sobre d1.
ÁRBOL DE DECISIÓN (en ambiente de incertidumbre):
EJEMPLO 1: Un gerente tiene $B pesos y debe decidir si invertir en
un proyecto o guardar el dinero en el banco. Si guarda su dinero en
d1
di
dk
c11
c12
c1m1
No se tiene información completa sobre las consecuencias de tomar cierta decisión.
E11
E12
E1m1
Ei1
Ek1
Ei2
Ek2
Eimi
Ekmk
ci1
ck1
ci2
ck2
cimi
ckmk
Nodo de decisión Nodo aleatorio

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 197
el banco y si la tasa de interés se mantiene constante, al final del
año tendría el doble, pero si la tasa sube tendría 3 veces más. Si
invierte en el proyecto, puede ocurrir que el proyecto sea exitoso o
que fracase. Si el proyecto es exitoso y la tasa de interés se
mantiene constante, al final de un año tendría 10 veces la inversión
inicial, pero si la tasa sube tendría únicamente 4 veces más de su
inversión inicial. En caso de que el proyecto fracasara al final de un
año habrá perdido su inversión inicial.
D = d1, d2, donde d1 = proyecto, d2 = banco
E = E11, E12, E13, E21, E22, donde E11 = éxito / tasa constante, E12 =
éxito / tasa sube, E13 = fracaso, E21 = tasa constante, E22 =
tasa sube
C = c11, c12, c13, c21, c22, donde c11=$10B, c12=$5B, c13=-$B,
c21=$2B, c22=$4B
Proyecto
Banco
Éxito
Fracaso
T. cte.
T. sube
T. cte.
T. sube
$10B
$5B
-$B
$2B
$4B

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 198
En la práctica, la mayoría de los problemas de decisión tienen una
estructura más compleja. Por ejemplo, decidir si realizar o no un
proyecto, y en caso afirmativo tratar de decidir la acción más
adecuada según el resultado del proyecto. (Problemas de decisión
secuenciales).
Frecuentemente, el conjunto de eventos inciertos es el mismo para
cualquier decisión que se tome, es decir, Ei = Ei1,Ei2,...,Eimi =
E1,E2,...,Em = E, para todo i. En este caso, el problema se puede
representar como:
E1 ... Ej ... Em
d1 c11 ... c1j ... c1m
M M M M
di ci1 ... cij ... cim
M M M M
dk ck1 ... ckj ... ckm
El OBJETIVO de un problema de decisión en ambiente de
incertidumbre consiste entonces en elegir ¡la mejor! decisión di del
conjunto D sin saber cuál de los eventos Eij de Ei ocurrirá.
Aunque los sucesos que componen cada Ei son inciertos, en el
sentido de que no sabemos cuál de ellos tendrá lugar, en general
se tiene una idea sobre la probabilidad de cada uno de ellos. Por
ejemplo,

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 199
40 años
Algunas veces resulta difícil ordenar nuestras preferencias sobre
las distintas consecuencias posibles. Tal vez resulta más fácil
asignar una utilidad a cada una de las consecuencias y ordenar
posteriormente de acuerdo a la utilidad.
CUANTIFICACIÓN de los sucesos inciertos y de las consecuencias.
La información que el decisor tiene sobre la posible ocurrencia de
los eventos inciertos puede ser cuantificada a través de una función
de probabilidad sobre el espacio E.
¿viva 10 más?
¿muera en 1 mes?
¿llegue a los 100?
¿Cuál es más probable?
Consecuencias Ganar mucho dinero y
tener poco tiempo disponible
Ganar poco dinero y tener mucho tiempo
disponible
Ganar regular de dinero y tener regular de tiempo disponible
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 200
De la misma manera, es posible cuantificar las preferencias del
decisor entre las distintas consecuencias a través de una función de
utilidad de manera que 'j'iij cc ≤ ⇔ ( ) ( )'j'iij cucu ≤ .
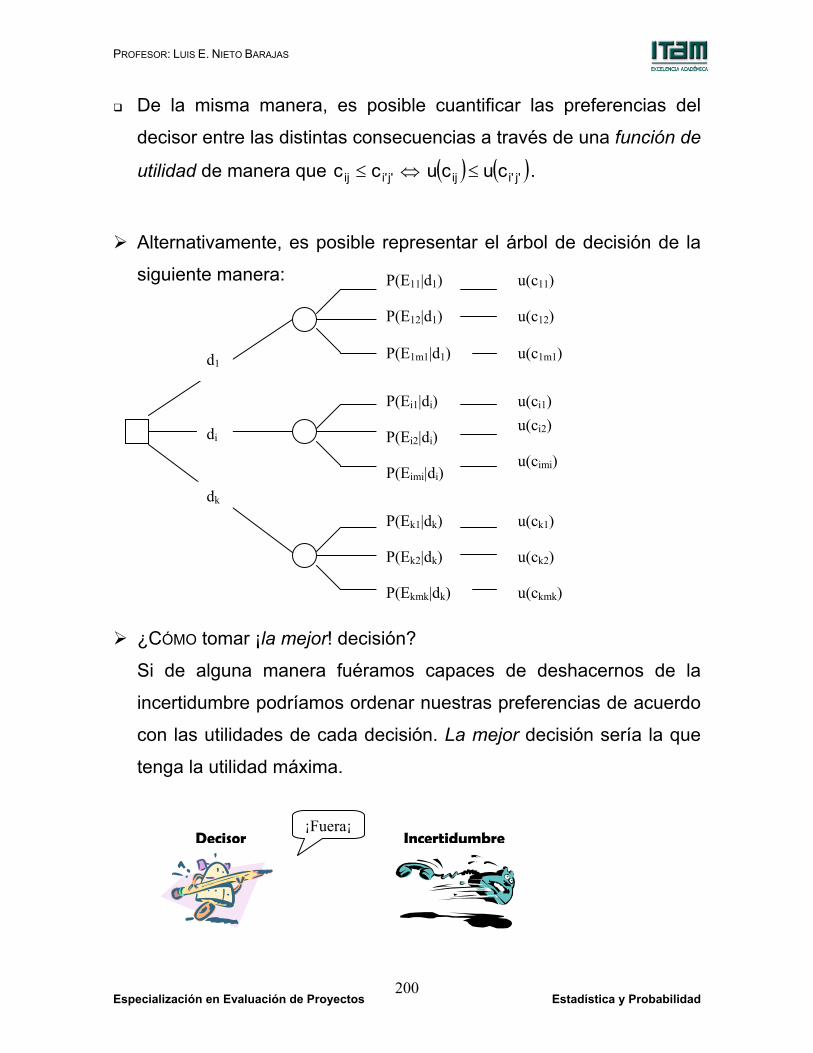
Alternativamente, es posible representar el árbol de decisión de la
siguiente manera:
¿CÓMO tomar ¡la mejor! decisión?
Si de alguna manera fuéramos capaces de deshacernos de la
incertidumbre podríamos ordenar nuestras preferencias de acuerdo
con las utilidades de cada decisión. La mejor decisión sería la que
tenga la utilidad máxima.
d1
di
dk
u(c11)
u(c12)
u(c1m1)
P(E11|d1)
P(E12|d1)
P(E1m1|d1)
P(Ei1|di)
P(Ek1|dk)
P(Ei2|di)
P(Ek2|dk)
P(Eimi|di)
P(Ekmk|dk)
u(ci1)
u(ck1)
u(ci2)
u(ck2)
u(cimi)
u(ckmk)
Incertidumbre Decisor ¡Fuera¡

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 201
ESTRATEGIAS: En un principio estudiaremos cuatro estrategias o
criterios propuestos en la literatura para tomar una decisión.
1) Optimista : Dar por “segura” a la mejor consecuencia de cada
opción.
2) Pesimista (o minimax): Dar por “segura” a la peor consecuencia
de cada opción.
3) Consecuencia más probable (o condicional): Dar por “segura” a
la consecuencia más probable de cada opción.
4) Utilidad esperada: Dar por “segura” una consecuencia promedio
para cada opción.
Cualquiera que sea la estrategia tomada, la mejor opción es aquella
que maximice la utilidad del árbol “sin incertidumbre”.
EJEMPLO 2: En unas elecciones parlamentarias en la Gran Bretaña
competían los partidos Conservador y Laboral. Una casa de
apuestas ofrecía las siguientes posibilidades:
a) A quien apostara a favor del partido Conservador, la casa estaba
dispuesta a pagar 7 libras por cada 4 que apostase si el
resultado favorecía a los conservadores, en caso contrario el
apostador perdía su apuesta.
b) A quien apostase a favor del partido Laboral, la casa estaba
dispuesta a pagar 5 libras por cada 4 que apostasen si ganaban
los laboristas, en caso contrario el apostador perdía su apuesta.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 202
o D = d1,d2
donde, d1 = Apostar al partido Conservador
d2 = Apostar al partido Laboral
o E = E1, E2
donde, E1 = Que gane el partido Conservador
E2 = Que gane el partido Laboral
o C = c11, c12, c21, c22. Si la apuesta es de k libras
entonces, k43k
47kc11 =+−=
kc12 −=
kc21 −=
k41k
45kc22 =+−=
Supongamos que la utilidad es proporcional al dinero, i.e.,
u(cij) = cij y sea π = P(E1), y π−1 = P(E2).
P(E) π π−1
u(d,E) E1 E2
d1 (3/4)k -k
d2 -k (1/4)k
¿A qué partido apostar?
Laboral Conservador

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 203
1) Optimista: d1 (apostar al partido Conservador)
2) Pesimista: d1 ó d2 (da igual cualquiera de las dos)
3) Consecuencia más probable: d1 ó d2 (dependiendo)
Si 2/1>π se toma a E1 como “seguro” ⇒ d1
Si 2/1≤π se toma a E2 como “seguro” ⇒ d2
4) Utilidad esperada: d1 ó d2 (dependiendo)
Las utilidades esperadas son:
( ) k1)4/7()k)(1(k)4/3(du 1 −π=−π−+π=
( ) k)4/5()4/1(k)4/1)(1()k(du 2 π−=π−+−π=
Entonces, la mejor decisión sería:
Si ( )1du > ( )2du ⇔ 12/5>π ⇒ d1
Si ( )1du < ( )2du ⇔ 12/5<π ⇒ d2
Si ( )1du = ( )2du ⇔ 12/5=π ⇒ d1 ó d2
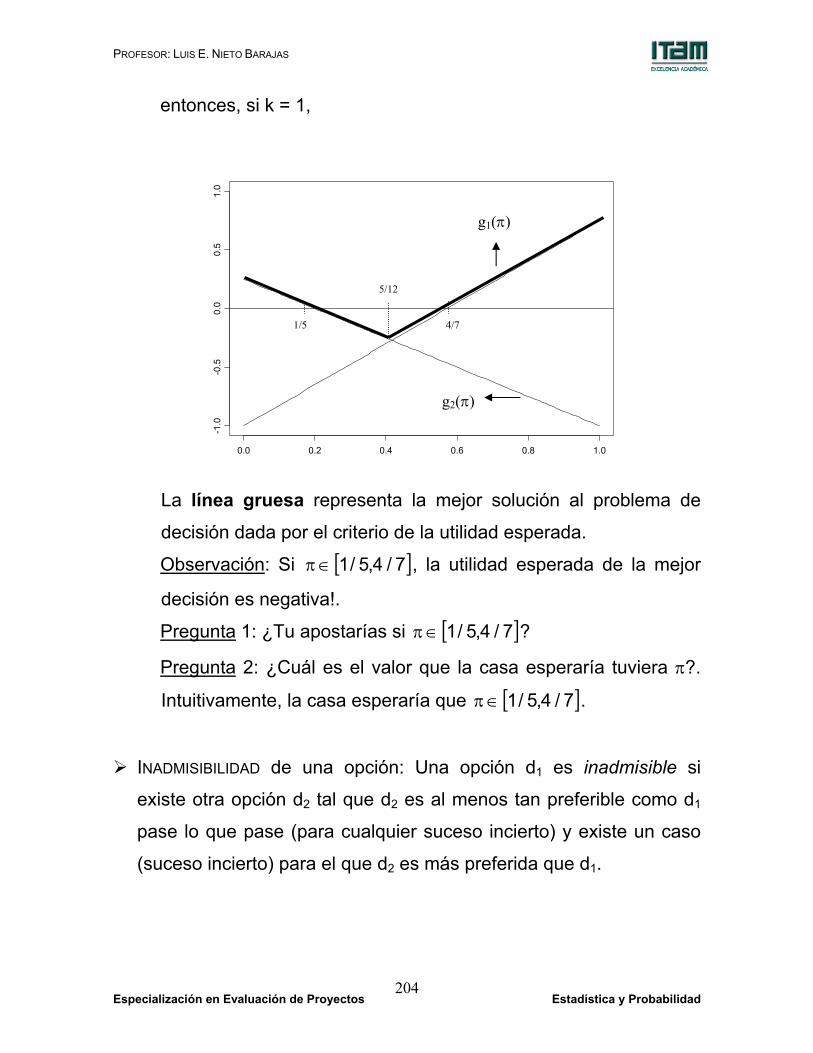
Gráficamente, si definimos las funciones
( ) ( )11 dukk47g =−π
=π , y
( ) ( )22 du4kk
45g =+π
−=π
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 204
entonces, si k = 1,
La línea gruesa representa la mejor solución al problema de
decisión dada por el criterio de la utilidad esperada.
Observación: Si [ ]7/4,5/1∈π , la utilidad esperada de la mejor
decisión es negativa!.
Pregunta 1: ¿Tu apostarías si [ ]7/4,5/1∈π ?
Pregunta 2: ¿Cuál es el valor que la casa esperaría tuviera π?.
Intuitivamente, la casa esperaría que [ ]7/4,5/1∈π .
INADMISIBILIDAD de una opción: Una opción d1 es inadmisible si
existe otra opción d2 tal que d2 es al menos tan preferible como d1
pase lo que pase (para cualquier suceso incierto) y existe un caso
(suceso incierto) para el que d2 es más preferida que d1.
5/12
1/5 4/7
g1(π)
g2(π)
0.0 0.2 0.4 0.6 0.8 1.0
-1.0
-0.5
0.0
0.5
1.0

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 205
AXIOMAS DE COHERENCIA. Son una serie de principios que establecen
las condiciones para tomar decisiones coherentemente y para
aclarar las posibles ambigüedades en el proceso de toma de
decisión. Los axiomas de coherencia son 4:
1. COMPARABILIDAD. Este axioma establece que al menos debemos
ser capaces de expresar preferencias entre dos posibles opciones y
por lo tanto entre dos posibles consecuencias. Es decir, no todas
las opciones ni todas las consecuencias son iguales.
Para todo par de opciones d1 y d2 en D, es cierta una y sólo una
de las siguientes condiciones:
d2 es más preferible que d1 ⇔ d1 < d2
d1 es más preferible que d2 ⇔ d2 < d1
d1 y d2 son igualmente preferibles ⇔ d1 ∼ d2
2. TRANSITIVIDAD. Este axioma establece que las preferencias deben
de ser transitivas para no caer en contradicciones.
Si d1, d2 y d3 son tres opciones cualesquiera y ocurre que d1<d2 y
d2<d3 entonces, necesariamente sucede que d1<d3.
Análogamente, si d1∼d2 y d2∼d3, entonces d1∼d3.
3. SUSTITUCIÓN Y DOMINANCIA. Este axioma establece que si se
tienen dos situaciones tales que para cualquier resultado que se
tenga de la primera, existe un resultado preferible en la segunda,

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 206
entonces la segunda situación es preferible para todos los
resultados.
Si d1 y d2 son dos opciones cualesquiera y E es un evento
incierto y sucede que d1<d2 cuando ocurre E y d1<d2 cuando no
ocurre E, entonces d1<d2 (sin importar los eventos inciertos).
Análogamente, si d1∼d2 cuando ocurre E y d1∼d2 cuando no
ocurre E, entonces d1∼d2.
4. EVENTOS DE REFERENCIA. Este axioma establece que para poder
tomar decisiones de forma razonable, es necesario medir la
información y las preferencias del decisor expresándolas en forma
cuantitativa. Es necesario una medida (P) basada en sucesos o
eventos de referencia.
El decisor puede imaginar un procedimiento para generar puntos
en el cuadrado unitario de dos dimensiones, de manera tal que
para cualesquiera dos regiones R1 y R2 en ese cuadrado , el
evento 1Rz∈ es más creíble que el evento 2Rz∈ únicamente
si el área de R1 es mayor que el área de R2.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 207
6.2 Principio de utilidad esperada máxima
IMPLICACIONES de los axiomas de coherencia:
En general, toda opción di se puede escribir como todas sus
posibles consecuencias dados los sucesos inciertos, es decir,
iijiji m,1,j ,Ecd K== .
1) Las consecuencias pueden verse como casos particulares de
opciones:
c ~ dc = Ωc ,
donde Ω es el evento seguro.
De esta forma podemos comparar las consecuencias:
c1 ≤ c2 ⇔ c1|Ω ≤ c2|Ω.
Por lo tanto, es posible encontrar dos consecuencias c∗ (la peor)
y c∗ (la mejor) tales que para cualquier otra consecuencia c, c∗ ≤
c ≤ c∗.
2) Los eventos inciertos también pueden verse como casos
particulares de opciones:
E ~ dE = c* Ec,Ec ∗ ,
donde c∗ y c* son la peor y la mejor consecuencias.
De esta forma podemos comparar los eventos inciertos:
E ≤ F ⇔ c*|E, c∗|Ec ≤ c*|F, c∗|Fc,
en este caso diremos que E no es más verosímil (probable) que
F.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 208
CUANTIFICACIÓN DE LAS CONSECUENCIAS: La cuantificación de la
consecuencia c será un número u(c) medido en la escala [0,1]. Esta
cuantificación estará basada en eventos de referencia.
o Definición: Utilidad.
La utilidad u(c) de una consecuencia c es la probabilidad q que
debe asignarse a la mejor consecuencia c* para que la
consecuencia c sea igualmente deseable que la opción
c*|Rq, c∗|Rqc
(que también se puede escribir como c*|q, c∗|1−q), donde Rq es un
evento de referencia en el cuadrado unitario de área q. De esta
forma, para toda consecuencia c existe una opción basada en
eventos de referencia tal que
c ∼ c*|u(c), c∗|1−u(c).
En virtud de los axiomas de coherencia 1, 2 y 3 siempre existe un
número u(c)∈[0,1] que cumpla con la condición anterior, puesto que
c* ~ c*|R0, c∗|R0c ⇒ u(c∗) = 0
c* ~ c*|R1, c∗|R1c ⇒ u(c∗) = 1
Por lo tanto, para toda c tal que c∗ ≤ c ≤ c∗ ⇒ 0 ≤ u(c) ≤ 1.
EJEMPLO 3: Utilidad del dinero. Supongamos que la peor y la mejor
consecuencias al jugar un juego de azar son:
c* = $0 (la peor) y c* = $1,000 (la mejor)
La idea es determinar una función de utilidad para cualquier
consecuencia c tal que c* ≤ c ≤ c*. Pensemos en una lotería: c*|q, c∗|1−q

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 209
Si el número de consecuencias es muy grande o incluso infinito la
función de utilidad se puede aproximar por un modelo obteniéndose
una de las siguientes formas:
NOTA: En algunos casos es más conveniente definir la función de
utilidad en una escala distinta al intervalo [0,1], como por ejemplo:
en tiempo, en números negativos, productos vendidos, empleos
generados, etc. Es posible demostrar que una función de utilidad
definida en otra escala es una transformación lineal de la utilidad
original definida en [0,1].
¿Cuál prefieres?
Ganar seguro
c
Ganar c* con probabilidad q
o Ganar c* con
probabilidad 1-q
0
1
0 1,000
c
u(c)
Para no caer en paradojas, es conveniente que la función de utilidad sea “aversa al riesgo”.
Indiferente al riesgo
c|1
Amante al riesgo
Aversión al riesgo

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 210
CUANTIFICACIÓN DE LOS EVENTOS INCIERTOS: La cuantificación de los
eventos inciertos E estará también basada en eventos de
referencia.
o Definición: Probabilidad.
La probabilidad P(E) de un evento incierto E es igual al área de una
región R del cuadrado unitario elegida de tal forma que las opciones
c*|E, c∗|Ec y c*|R, c∗|Rc sean igualmente deseables
(equivalentes).
o En otras palabras, si dE = c∗|E, c∗|Ec y dR = c∗|Rq, c∗|Rqc son tales
que
dE ∼ dRq ⇒ P(E) = q.
EJEMPLO 4: Asignación de la probabilidad de un evento E.
Supongamos que nos enfrentamos al problema de decidir en qué
proyecto invertir y que la peor y la mejor consecuencias son:
c∗ = −$1000 (la peor) y c* = $5,000 (la mejor)
Sea E = sube la tasa de interés. Para determinar la probabilidad de
E consideramos las siguientes loterías:
¿Cuál prefieres?
Ganar c* con probabilidad q
o Ganar c∗ con
probabilidad 1-q
Ganar c* si ocurre E
o Ganar c∗ si no ocurre E
c*|q, c∗|1−q c*|E, c∗|Ec

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 211
Finalmente, se aplica este mismo procedimiento a cada una de los
eventos inciertos, digamos, E1,E2,...,Ek. Si el número de eventos
inciertos es muy grande o incluso infinito la función de probabilidad
se puede aproximar por un modelo (discreto o continuo)
obteniéndose la siguiente forma,
NOTA: La probabilidad asignada a un evento, es siempre
condicional a la información que se posee en el momento de la
asignación, i.e., no existen probabilidades absolutas.
DERIVACIÓN DE LA UTILIDAD ESPERADA:
Hasta ahora, hemos cuantificado a las consecuencias y a los
eventos inciertos. Finalmente queremos asignar un número a las
opciones, del tal forma que la mejor opción es aquella a la que se le
asigna la cuantificación más alta.
o Teorema: Criterio de decisión Bayesiano.
Considérese el problema de decisión definido por D = d1,d2,...,dk,
donde di = ijij m,,1j,Ec K= , i=1,...,k. Sea P(Eij|di) la probabilidad de
que suceda Eij si se elige la opción di, y sea u(cij) la utilidad de la
a
θ
P(θ) Modelo continuo
b
Si Eθ =θ ⇒ E = θ | θ∈[a,b]

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 212
consecuencia cij. Entonces, la cuantificación de la opción di es su
utilidad esperada, i.e.,
( ) ( ) ( )∑=
=im
1jiijiji dEPcudu .
La decisión óptima es aquella d∗ tal que ( ) ( )ii
* dumaxdu = .
DEM.
ii imim2i2i1i1iiijiji Ec,,Ec,Ecm,,1j,Ecd KK ===
Por otro lado sabemos que,
ijc ∼ ( ) ( ) ijij*c
ijij* cu1c,cucRc,Rc −= ∗∗ ,
donde ( ) ( )ijij RAreacu = , y
c*E Ec,Ecd ∗= ∼ ( ) ( ) jj
*cEE
* EP1c,EPcRc,Rc −= ∗∗ ,
donde ( ) ( )ERAreaEP = .
Entonces, combinando ambas expresiones, tenemos
1ii im
cimim1i
c1i1ii ERc,Rc,,ERc,Rcd ∗
∗∗
∗= K
iiii im
cimimim1i
c1i1i1i ERc,ERc,,ERc,ERc ∩∩∩∩= ∗
∗∗
∗ K
( ) ( ) ( ) ( ) iiii im
cim1i
c1iimim1i1i ERERc ,ERERc ∩∪∪∩∩∪∪∩= ∗
∗ LL
Finalmente,
( ) ( ) ( ) ii imim1i1ii ERERAreadu ∩∪∪∩= L
( ) ( )∑=
=im
1jijij EAreaRArea ( ) ( )∑
=
=im
1jijij EPcu

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 213
RESUMIENDO: Si se aceptan los axiomas de coherencia,
necesariamente se debe proceder de la siguiente manera:
1) Asignar una utilidad u(c) para toda c en C.
2) Asignar una probabilidad P(E) para toda E en E.
3) Elegir la opción (óptima) que maximiza la utilidad esperada.
6.3 Proceso de aprendizaje y distribución predictiva
La reacción natural de cualquiera que tenga que tomar una decisión
cuyas consecuencias dependen de la ocurrencia de eventos
inciertos E, es intentar reducir su incertidumbre obteniendo más
información sobre E.
¿Cómo reducir la incertidumbre sobre un evento E?.
Adquirir información adicional (Z) sobre E.
LA IDEA es entonces recolectar información que reduzca la
incertidumbre de los eventos inciertos, o equivalentemente, que
mejore el conocimiento que se tiene sobre E.
¿De dónde obtengo información adicional?.
Encuestas, estudios previos, experimentos, etc.
El problema central de la inferencia estadística es el de
proporcionar una metodología que permita asimilar la información
accesible con el objeto de mejorar nuestro conocimiento inicial.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 214
¿Cómo utilizar Z para mejorar el conocimiento sobre E?.
( )EP ( )ZEP
Mediante el Teorema de Bayes.
o TEOREMA DE BAYES: Sean Jj,E j ∈ una partición finita de Ω (E), i.e.,
Ej∩Ek=∅ ∀j≠k y Ω=∈U
JjjE . Sea Z ≠ ∅ un evento. Entonces,
( ) ( ) ( )( ) ( )∑
∈
=
Jjii
iii EPEZP
EPEZPZEP , i =1,2,...,k.
DEM.
( ) ( )( )
( ) ( )( )ZP
EPEZPZP
ZEPZEP iiii =
∩=
como ( )UUJj
jJj
j EZEZZZ∈∈
∩=
∩=Ω∩= tal que
( ) ( ) ∅=∩∩∩ kj EZEZ ∀j≠k
( ) ( ) ( ) ( ) ( )∑∑∈∈∈
=∩=
∩=⇒Jj
jjJj
jJj
j EPEZPEZPEZPZP U .
Comentarios:
2) Una forma alternativa de escribir el Teorema de Bayes es:
( ) ( ) ( )iii EPEZPZEP ∝
P(Z) es llamada constante de proporcionalidad.
¿ ?

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 215
3) A las P(Ej) se les llama probabilidades iniciales o a-priori y a las
P(Ej|Z) se les llama probabilidades finales o a-posteriori.
Además, P(Z|Ej) es llamada verosimilitud y P(Z) es llamada
probabilidad marginal de la información adicional.
Recordemos que todo esto de la cuantificación inicial y final de los
eventos inciertos es para reducir la incertidumbre en un problema
de decisión.
Supongamos que para un problema particular se cuenta con lo
siguiente:
( )ijEP : cuantificación inicial de los eventos inciertos
( )ijcu : cuantificación de las consecuencias
Z: información adicional sobre los eventos inciertos
( )EP ( )ZEP
En este caso se tienen dos situaciones:
1) Situación inicial (a-priori):
( )ijEP , ( )ijcu , ( ) ( )∑j
ijij EPcu
2) Situación final (a-posteriori):
( )ZEP ij , ( )ijcu , ( ) ( )∑j
ijij ZEPcu
Teo. Bayes
Utilidad esperada
inicial
Utilidad esperada
final

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 216
¿Qué pasa si de alguna manera se obtiene aún más información
adicional acerca de E?. Suponga que primero se tiene acceso a Z1
(información adicional acerca de E) y posteriormente se obtiene Z2
(más información adicional acerca de E). Existen dos formas para
actualizar la información que se tiene sobre E:
1) Actualización secuencial:
( )EP ( )1ZEP ( )21 Z,ZEP
Los pasos son:
Paso 1: ( ) ( ) ( )( )1
11 ZP
EPEZPZEP = ,
Paso 2: ( ) ( ) ( )( )12
11221 ZZP
ZEPE,ZZPZ,ZEP = .
2) Actualización simultánea:
( )EP ( )21 Z,ZEP
¿Cómo se hace?
Paso único: ( ) ( ) ( )( )21
2121 Z,ZP
EPEZ,ZPZ,ZEP = .
¿Serán equivalentes ambas formas de actualización?
Z1 Z2
Z1,Z2

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 217
( ) ( ) ( )( )
( )( )
( )( )
( )( )
==
1
21
1
1
1
21
12
11221
ZPZ,ZP
ZPE,ZP
E,ZPE,Z,ZP
ZZPZEPE,ZZP
Z,ZEP
( )( )
( ) ( )( )21
21
21
21
Z,ZPEPEZ,ZP
Z,ZPE,Z,ZP
==
EJEMPLO 5: Un paciente va al médico con algún padecimiento y
quiere que el médico le de un diagnóstico. Supongamos que la
enfermedad del paciente cae en alguna de las siguientes tres
categorías:
E1 = enfermedad muy frecuente (resfriado)
E2 = enfermedad relativamente frecuente (gripa)
E3 = enfermedad poco frecuente (pulmonía)
El médico sabe por experiencia que
P(E1)=0.6, P(E2)=0.3, P(E3)=0.1 (probabilidades iniciales)
El médico observa y obtiene información adicional (Z = síntomas)
acerca de la posible enfermedad del paciente. De acuerdo con los
síntomas el doctor dictamina que
P(Z | E1)=0.2, P(Z | E2)=0.6, P(Z | E3)=0.6 (verosimilitud)
¿Qué enfermedad es más probable que tenga el paciente?.
Usando el Teorema de Bayes, obtenemos:
( ) ( ) ( ) 0.36(0.6)(0.1)(0.6)(0.3)(0.2)(0.6)EPEZPZP3
1jjj =++== ∑
=
( )31
36.0)6.0)(2.0(ZEP 1 == (probabilidades
finales)

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 218
( )21
36.0)3.0)(6.0(ZEP 2 ==
( )61
36.0)1.0)(6.0(ZEP 3 ==
Por lo tanto, es más probable que el paciente tenga una
enfermedad relativamente frecuente (E2).
Problema de Inferencia.
PROBLEMA DE INFERENCIA. Sea F ( ) Θ∈θθ= ,xf una familia
paramétrica indexada por el parámetro θ∈Θ. Sea X1,...,Xn una m.a.
de observaciones de f(x|θ) ∈F. El problema de inferencia
paramétrico consiste en aproximar el verdadero valor del parámetro
θ.
El problema de inferencia estadístico se puede ver como un
problema de decisión con los siguientes elementos:
D = espacio de decisiones de acuerdo al problema específico
E = Θ (espacio parametral)
C = ( ) Θ∈θ∈θ ,d:,d D
≤ : Será representado por una función de utilidad o pérdida.
La muestra proporciona información adicional sobre los eventos
inciertos θ∈Θ. El problema consiste en cómo actualizar la
información.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 219
Por lo visto con los axiomas de coherencia, el decisor es capaz de
cuantificar su conocimiento acerca de los eventos inciertos
mediante una función de probabilidades. Definamos,
( )θf la distribución inicial (ó a-priori). Cuantifica el
conocimiento inicial sobre θ.
( )θxf proceso generador de información muestral.
Proporciona información adicional acerca de θ.
( )θxf la función de verosimilitud. Contiene toda la información
sobre θ proporcionada por la muestra ( )n1 X,XX K= .
Toda esta información acerca de θ se combina para obtener un
conocimiento final o a-posteriori después de haber observado la
muestra. La forma de hacerlo es mediante el Teorema de Bayes:
( ) ( ) ( )( )xf
fxfxf
θθ=θ ,
donde ( ) ( ) ( )∫Θ
θθθ= dfxfxf ó ( ) ( )∑θ
θθ fxf .
Como ( )xf θ es función de θ, entonces podemos escribir
( ) ( ) ( )θθ∝θ fxfxf
Finalmente,
( )xf θ la distribución final (ó a-posteriori). Proporciona todo el
conocimiento que se tiene sobre θ (inicial y muestral).
NOTA: Al tomar θ el carácter de aleatorio, debido a que el
conocimiento que tenemos sobre el verdadero valor θ es incierto,

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 220
entonces la función de densidad que genera observaciones con
información relevante para θ es realmente una función de densidad
condicional.
o Definición: Llamaremos una muestra aleatoria (m.a.) de tamaño n
de una población f(x|θ), que depende de θ, a un conjunto X1,...,Xn
de variables aleatorias condicionalmente independientes dado θ,
i.e.,
( ) ( ) ( )θθ=θ n1n1 xfxfx,xf LK .
En este caso, la función de verosimilitud es la función de densidad
(condicional) conjunta de la m.a. vista como función del parámetro,
i.e.,
( ) ( )∏=
θ=θn
1iixfxf .
DISTRIBUCIÓN PREDICTIVA: La distribución predictiva es la función de
densidad (marginal) f(x) que me permite determinar qué valores de
la v.a. X resultan más probables.
Lo que conocemos acerca de X esta condicionado al valor del
parámetro θ, i.e., f(x|θ) (su función de densidad condicional). Como
θ es un valor desconocido, f(x|θ) no puede utilizarse para describir
el comportamiento de la v.a. X.
Distribución predictiva inicial. Aunque el verdadero valor de θ sea
desconocido, siempre se dispone de cierta información sobre θ

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 221
(mediante su distribución inicial f(θ)). Esta información puede
combinarse para poder dar información sobre los valores de X. La
forma de hacerlo es:
( ) ( ) ( )∫ θθθ= dfxfxf ó ( ) ( ) ( )∑θ
θθ= fxfxf
Supongamos que se cuenta con información adicional (información
muestral) X1,X2,..,Xn de la densidad f(x|θ), por lo tanto es posible
tener un conocimiento final sobre θ mediante su distribución final
( )xf θ .
Distribución predictiva final. Supongamos que se quiere obtener
información sobre los posibles valores que puede tomar una nueva
v.a. XF de la misma población f(x|θ). Si XF es independiente de la
muestra X1,X2,..,Xn, entonces
( ) ( ) ( )∫ θθθ= dxfxfxxf FF ó ( ) ( ) ( )∑θ
θθ= xfxfxxf FF
EJEMPLO 6: Lanzar una moneda. Se tiene un experimento aleatorio
que consiste en lanzar una moneda. Sea X la v.a. que toma el valor
de 1 si la moneda cae sol y 0 si cae águila, i.e., X∼Ber(θ). En
realidad se tiene que X|θ ∼Ber(θ), donde θ es la probabilidad de que
la moneda caiga sol.
( ) ( ) )x(I1xf 1,0x1x −θ−θ=θ .
El conocimiento inicial que se tiene acerca de la moneda es que
puede ser una moneda deshonesta (dos soles).

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 222
P(honesta) = 0.95 y P(deshonesta) = 0.05
¿Cómo cuantificar este conocimiento sobre θ?
moneda honesta ⇔ θ = 1/2 θ ∈ 1/2, 1
moneda deshonesta ⇔ θ = 1
por lo tanto,
( ) 95.02/1P ==θ y ( ) 05.01P ==θ
es decir,
( )
=θ=θ
=θ1 si ,05.0
2/1 si ,95.0f
Supongamos que al lanzar la moneda una sola vez se obtuvo un
sol, i.e, X1=1. Entonces la verosimilitud es
( ) ( ) θ=θ−θ=θ= 011 11XP .
Combinando la información inicial con la verosimilitud obtenemos,
( ) ( ) ( ) ( ) ( )1P11XP2/1P2/11XP1XP 111 =θ=θ=+=θ=θ===
( )( ) ( )( ) 525.005.0195.05.0 =+=
( ) ( ) ( )( )
( )( ) 9047.0525.0
95.05.01XP
2/1P2/11XP1X2/1P
1
11 ==
==θ=θ=
===θ
( ) ( ) ( )( )
( )( ) 0953.0525.0
05.011XP
1P11XP1X1P
1
11 ==
==θ=θ=
===θ
es decir,
( )
=θ=θ
==θ1 si ,0953.0
2/1 si ,9047.01xf 1
La distribución predictiva inicial es
( ) ( ) ( ) ( ) ( )1P11XP2/1P2/11XP1XP =θ=θ=+=θ=θ===

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 223
( )( ) ( )( ) 525.005.0195.05.0 =+=
( ) ( ) ( ) ( ) ( )1P10XP2/1P2/10XP0XP =θ=θ=+=θ=θ===
( )( ) ( )( ) 475.005.0095.05.0 =+=
es decir,
( )
==
=0x si ,475.01x si ,525.0
xf
La distribución predictiva final es
( ) ( ) ( ) ( ) ( )1x1P11XP1x2/1P2/11XP1x1XP 1F1F1F ==θ=θ=+==θ=θ==== ( )( ) ( )( ) 54755.00953.019047.05.0 =+=
( ) ( ) ( ) ( ) ( )1x1P10XP1x2/1P2/10XP1x0XP 1F1F1F ==θ=θ=+==θ=θ==== ( )( ) ( )( ) 45235.00953.009047.05.0 =+=
es decir,
( )
==
==0x si ,452.01x si ,548.0
1xxfF
F1F .
EJEMPLO 7: Proyectos de inversión. Las utilidades de un
determinado proyecto pueden determinarse a partir de la demanda
(θ) que tendrá el producto terminal. La información inicial que se
tiene sobre la demanda es que se encuentra alrededor de $39
millones de pesos y que el porcentaje de veces que excede los $49
millones de pesos es de 25%.
De acuerdo con la información proporcionada, se puede concluir
que una distribución normal modela “adecuadamente” el
comportamiento inicial, entonces
θ ∼ ( )2,N σµ ,
donde µ=E(θ)=media y σ2=Var(θ)=varianza. Además

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 224
¿Cómo?
( ) 25.03949ZP49P =
σ−
>=>θ ⇒ σ−
=3949Z 25.0 ,
como Z0.25 = 0.675 (valor de tablas) ⇒ 675.010
=σ
Por lo tanto, θ ∼ N(39, 219.47).
Para adquirir información adicional sobre la demanda, se
considerarán 3 proyectos similares cuyas utilidades dependen de la
misma demanda. Supongamos que la utilidad es una variable
aleatoria con distribución Normal centrada en θ y con una
desviación estándar de σ=2.
X|θ ∼ N(θ, 4) y θ ∼ N(39, 219.47)
Se puede demostrar que la distribución predictiva inicial toma la
forma
X ∼ N(39, 223.47)
¿Qué se puede derivar de esta distribución predictiva?
( ) ( ) 0808.04047.1ZP47.2233960ZP60XP =>=
−
>=> ,
lo cual indica que es muy poco probable tener una utilidad mayor a
60.
Suponga que las utilidades de los 3 proyectos son: x1=40.62,
x2=41.8, x3=40.44.
Demanda (θ) alrededor de 39 µ=39
P(θ > 49) = 0.25 σ=14.81

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 225
Se puede demostrar que si
donde, 20
2
020
2
1 1n
1xn
σ+
σ
θσ
+σ
=θ y 20
2
21 1n
1
σ+
σ
=σ .
Por lo tanto,
x=40.9533, θ0 = 39, σ2 = 4, σ02 = 219.47, n=3
θ1 = 40.9415, σ12 = 1.3252 ∴ xθ ∼ N(40.9415, 1.3252)
6.4 Distribuciones iniciales informativas, no informativas y conjugadas
Existen diversas clasificaciones de las distribuciones iniciales. En
términos de la cantidad de información que proporcionan se
clasifican en informativas y no informativas.
DISTRIBUCIONES INICIALES INFORMATIVAS: Son aquellas distribuciones
iniciales que proporcionan información relevante e importante sobre
la ocurrencia de los eventos inciertos θ.
X|θ ∼ N(θ, σ2) y θ ∼ N(θ0, σ02) ⇒ xθ ∼N(θ1, σ1
2)

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 226
EJEMPLO 8: La distribución inicial para θ del Ejemplo 7 es un
ejemplo de distribución inicial informativa. En el mismo contexto del
Ejemplo 7, supongamos ahora que existen únicamente 3 posibles
estados de la demanda: θ1 = demanda baja, θ2 = demanda media y
θ3 = demanda alta. Suponga además que la demanda media se
cree tres veces tan probable que la demanda baja y la demanda
alta dos veces tan probable que la demanda baja. Especifica la
distribución inicial para la demanda.
Sea pi=P(θi), i =1,2,3. Entonces,
p2=3p1 y p3=2p1. Además, 1ppp 321 =++
⇒ p1+ 3p1+ 2p1=1 ⇔ 6p1=1 ∴ p1=1/6, p2=1/2 y p3=1/3
DISTRIBUCIONES INICIALES NO INFORMATIVAS: Son aquellas
distribuciones iniciales que no proporcionan información relevante o
importante sobre la ocurrencia de los eventos inciertos θ.
Existen varios criterios para definir u obtener una distribución inicial
no informativa:
1) Principio de la razón insuficiente: Bayes (1763) y Laplace (1814,
1952). De acuerdo con este principio, en ausencia de evidencia en
contra, todas las posibilidades deberían tenerla misma probabilidad
inicial.
o En particular, si θ puede tomar un número finito de valores,
digamos m, la distribución inicial no informativa, de acuerdo con
este principio es:

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 227
( ) )(Im1f
m21 ,,, θ=θ θθθ K
o ¿Qué pasa cuando el número de valores (m) que puede tomar θ
tiende a infinito?
( ) .ctef ∝θ
En este caso se dice que f(θ) es una distribución inicial impropia,
porque no cumple con todas las propiedades para ser una
distribución inicial propia.
2) Distribución inicial invariante: Jeffreys (1946) propuso una
distribución inicial no informativa invariante ante
reparametrizaciones, es decir, si πθ(θ) es la distribución inicial no
informativa para θ entonces, ( ) )(J)()( ϕϕθπ=ϕπ θθϕ es la distribución
inicial no informativa de ϕ = ϕ(θ). Esta distribución es generalmente
impropia.
o La regla de Reffreys consiste en lo siguiente: Sea F
= ( ) Θ∈θθ :xf , Θ⊂ℜd un modelo paramétrico para la variable
aleatoria X. La distribución inicial no informativa de Jeffreys para
el parámetro θ con respecto al modelo F es
2/1)(Idet)( θ∝θπ , θ∈Θ,
donde ( )
θ∂θ∂θ∂
−=θ θ ' Xflog
E)(I2
|X es la matriz de información de
Fisher

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 228
o EJEMPLO 9: Sea X una v.a. con distribución condicional dado θ,
Ber(θ), i.e., ( ) ( ) )x(I1xf 1,0x1x −θ−θ=θ , θ∈(0,1).
( ) )x(Ilog)1log()x1()log(xxflog 1,0+θ−−+θ=θ
( )θ−
−−
θ=θ
θ∂∂
1x1xxflog
( ) 222
2
)1(x1xxflogθ−−
−θ
−=θθ∂∂
( ) ( ) ( )( ) )1(
11
XE1XE)1(
X1XEI 2222|X θ−θ==
θ−
θ−+
θ
θ=
θ−−
−θ
−−=θ θ L
( ) )(I1)1(
1)( )1,0(2/12/1
2/1
θθ−θ=
θ−θ∝θπ −−
∴ ( )2/1,2/1Beta)( θ=θπ .
3) Criterio de referencia: Bernardo (1986) propuso una nueva
metodología para obtener distribuciones iniciales mínimo
informativas o de referencia, basándose en la idea de que los datos
contienen toda la información relevante en un problema de
inferencia.
o La distribución inicial de referencia es aquella distribución inicial
que maximiza la distancia esperada que hay entre la distribución
inicial y la final cuando se tiene un tamaño de muestra infinito.
o Ejemplos de distribuciones iniciales de referencia se encuentran
en el formulario.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 229
DISTRIBUCIONES CONJUGADAS: Las distribuciones conjugadas surgen
de la búsqueda de cuantificar el conocimiento inicial de tal forma
que la distribución final sea fácil de obtener de “manera analítica”.
Debido a los avances tecnológicos, esta justificación no es válida
en la actualidad.
o Definición: Familia conjugada. Se dice que una familia de
distribuciones de θ es conjugada con respecto a un determinado
modelo probabilístico f(x|θ) si para cualquier distribución inicial
perteneciente a tal familia, se obtiene una distribución final que
también pertenece a ella.
o EJEMPLO 10: Sea X1,X2,...,Xn una m.a. de Ber(θ). Sea θ∼Beta(a,b)
la distribución inicial de θ. Entonces,
( ) ( ) ( )∏=
−∑θ−∑θ=θn
1ii1,0
xnx xI1xf ii
( ) ( ) )(I1)b()a()ba(f )1,0(
1b1a θθ−θΓΓ+Γ
=θ −−
⇒ ( ) ( ) )(I1xf )1,0(1xnb1xa ii θ∑θ−∑θ∝θ −−+−+
∴ ( ) ( ) )(I1)b()a()ba(xf )1,0(
1b1a
11
11 11 θθ−θΓΓ+Γ
=θ −− ,
donde ∑+= i1 xaa y ∑−+= i1 xnbb . Es decir,
)b,a(Betax 11∼θ .
o Más ejemplos de familias conjugadas se encuentran en el
formulario.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 230
6.5 Problemas de inferencia paramétrica
Los problemas típicos de inferencia son: estimación puntual,
estimación por intervalos y prueba o contraste de hipótesis.
ESTIMACIÓN PUNTUAL. El problema de estimación puntual visto como
problema de decisión se describe de la siguiente manera:
o D = E = Θ.
o ( )θθ,~v la pérdida de estimar mediante θ~ el verdadero valor del
parámetro de interés θ. Considérense tres funciones de pérdida:
1) Función de pérdida cuadrática:
( ) ( )2~ a,~v θ−θ=θθ , donde a > 0
En este caso, la decisión óptima que minimiza la pérdida esperada
es
( )θ=θ E~ .
2) Función de pérdida absoluta:
( ) θ−θ=θθ ~ a,~v , donde a > 0
En este caso, la decisión óptima que minimiza la pérdida esperada
es
La mejor estimación de θ con pérdida cuadrática es la media de la distribución de θ al momento de producirse la
estimación.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 231
( )θ=θ Med~ .
3) Función de pérdida vecindad:
( ) )(I1,~v )~(B θ−=θθ θε,
donde ( )θε~B denota una vecindad (bola) de radio ε con centro en θ~ .
En este caso, la decisión óptima que minimiza la pérdida esperada
cuando 0→ε es
( )θ=θ Moda~ .
EJEMPLO 11: Sean X1,X2,...,Xn una m.a. de una población Ber(θ).
Supongamos que la información inicial que se tiene se puede
describir mediante una distribución Beta, i.e., θ ∼ Beta(a,b). Como
demostramos en el ejemplo pasado, la distribución final para θ es
también una distribución Beta, i.e.,
θ|x ∼ Beta
−++ ∑∑
==
n
1ii
n
1ii Xnb ,Xa .
La idea es estimar puntualmente a θ,
La mejor estimación de θ con pérdida absoluta es la mediana de la distribución de θ al momento de producirse la
estimación.
La mejor estimación de θ con pérdida vecindad es la moda de la distribución de θ al momento de producirse la estimación.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 232
1) Si se usa una función de pérdida cuadrática:
( )nbaxa
xE~ i
+++
=θ=θ ∑ ,
2) Si se usa una función de pérdida vecindad:
( )2nba1xa
xModa~ i
−++−+
=θ=θ ∑ .
ESTIMACIÓN POR INTERVALO. El problema de estimación por intervalo
visto como problema de decisión se describe de la siguiente
manera:
o D = D : D ⊂ Θ,
donde, D es un intervalo de probabilidad al (1-α) si
( ) α−=θθ∫ 1dfD
.
Nota: para un α∈(0,1) fijo no existe un único intervalo de
probabilidad.
o E = Θ.
o ( ) )(ID,Dv D θ−=θ la pérdida de estimar mediante D el verdadero
valor del parámetro de interés θ.
Esta función de pérdida refleja la idea intuitiva que para un α
dado es preferible reportar un intervalo de probabilidad D* cuyo
tamaño sea mínimo. Por lo tanto,
La mejor estimación por intervalo de θ es el intervalo D* cuya longitud es mínima.
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 233
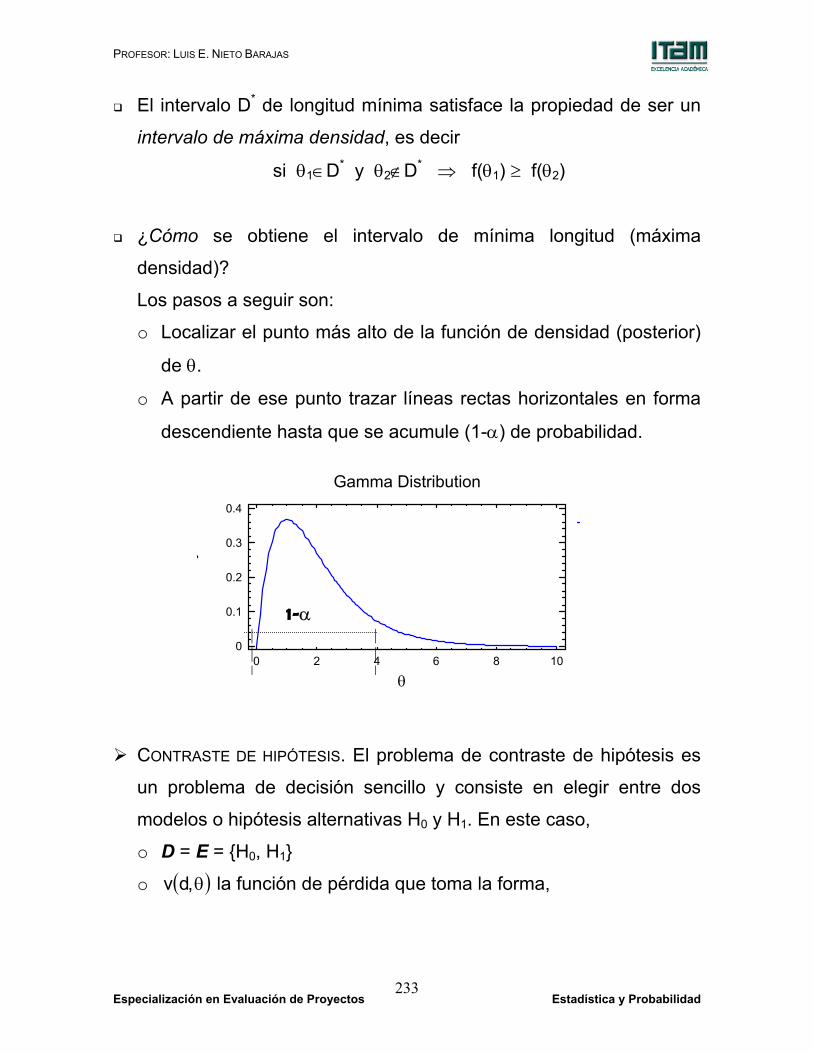
El intervalo D* de longitud mínima satisface la propiedad de ser un
intervalo de máxima densidad, es decir
si θ1∈D* y θ2∉D* ⇒ f(θ1) ≥ f(θ2)
¿Cómo se obtiene el intervalo de mínima longitud (máxima
densidad)?
Los pasos a seguir son:
o Localizar el punto más alto de la función de densidad (posterior)
de θ.
o A partir de ese punto trazar líneas rectas horizontales en forma
descendiente hasta que se acumule (1-α) de probabilidad.
Shape,Scale2,1
Gamma Distribution
x
dens
ity
0 2 4 6 8 100
0.1
0.2
0.3
0.4
CONTRASTE DE HIPÓTESIS. El problema de contraste de hipótesis es
un problema de decisión sencillo y consiste en elegir entre dos
modelos o hipótesis alternativas H0 y H1. En este caso,
o D = E = H0, H1
o ( )θ,dv la función de pérdida que toma la forma,
θ
| | |
| |
|
1-α

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 234
v(d,θ) H0 H1
H0 v00 v01
H1 v10 v11
donde, v00 y v11 son la pérdida de tomar una decisión correcta
(generalmente v00 = v11 = 0),
v10 es la pérdida de rechazar H0 (aceptar H1) cuando H0 es
cierta y
v01 es la pérdida de no rechazar H0 (aceptar H0) cuando H0
es falsa.
Sea p0 = P(H0) = probabilidad asociada a la hipótesis H0 al
momento de tomar la decisión (inicial o final). Entonces, la pérdida
esperada para cada hipótesis es:
( ) ( ) ( ) 00001010010000 pvvvp1vpvHvE −−=−+=
( ) ( ) ( ) 01011110110101 pvvvp1vpvHvE −−=−+=
cuya representación gráfica es de la forma:
0 1
p0
p* H1 H0
v01 v10
( ) 1HvE( ) 0HvE
v11 v00

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 235
donde, 00011110
1101*
vvvvvvp
−+−−
= .
Finalmente, la solución óptima es aquella que minimiza la pérdida
esperada:
si ( ) ( ) 0H pp vvvv
p-1p HvEHvE *
00010
1101
0
010 ⇒>⇔
−−
>⇔<
H0 si p0 es suficientemente grande comparada con 1-p0.
si ( ) ( ) 1H pp vvvv
p-1p HvEHvE *
00010
1101
0
010 ⇒<⇔
−−
<⇔>
H1 si p0 es suficientemente pequeña comparada con 1-p0.
si 1H0H ó pp *0 ⇒=
Indiferente entre H0 y H1 si p0 no es ni suficientemente grande ni
suficientemente pequeña comparada con 1-p0.


















