
32352648 Taller de Base de Datos
42
-
Upload
jaznel-franco -
Category
Documents
-
view
2.394 -
download
0
Transcript of 32352648 Taller de Base de Datos

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 1/42

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 2/42
2
CONTENIDOCONTENIDO.............................................................................................................................2
UNIDAD 1.................................................................................................................................4
INTRODUCCIÓN AL SISTEMA MANEJADOR DE BASE DE DATOS (DBMS)................................4
1.1 CONCEPTOS...................................................................................................................7
1.2 CARACTERÍSTICAS DE UN DBMS....................................................................................8
UNIDAD 2.................................................................................................................................9
LENGUAJE DE DEFINICIÓN DE DATOS...................................................................................9
2.1 CREACIÓN DE BASE DE DATOS....................................................................................10
2.2 CREACIÓN DE TABLAS..................................................................................................11
2.2.1 INTEGRIDAD..........................................................................................................12
2.2.2 INTEGRIDAD REFERENCIAL DECLARATIVA.............................................................132.2.3 CREACIÓN DE ÍNDICES..........................................................................................14
UNIDAD 3...............................................................................................................................15
CONSULTAS Y LENGUAJE DE MANIPULACIÓN DE DATOS....................................................15
3.1 INSTRUCCIONES INSERT, UPDATE, DELETE..................................................................15
3.2 CONSULTAS BÁSICAS SELECT, WHERE Y FUNCIONES A NIVEL DE REGISTRO. ...............18
3.3 CONSULTAS SOBRE MÚLTIPLES TABLAS.......................................................................19
3.3.1 SUBCONSULTAS .....................................................................................................20
3.3.2 OPERADORES JOIN................................................................................................20
3.4 AGREGACIÓN GROUP BY, HAVING................................................................................22
4.1 PROPIEDAD DE UNA TRANSACCIÓN..............................................................................27
4.2 GRADOS DE CONSISTENCIA.........................................................................................28
4.3 NIVELES DE AISLAMIENTO............................................................................................29
4.4 INSTRUCCIONES COMMIT Y ROLLBACK .........................................................................30
UNIDAD 5...............................................................................................................................31
VISTAS...............................................................................................................................31
5.1 DEFINICIÓN Y OBJETIVO DE LAS VISTAS.......................................................................32
5.2 INSTRUCCIONES PARA LA ADMINISTRACIÓN DE VISTAS...............................................33
UNIDAD 6...............................................................................................................................33
SEGURIDAD........................................................................................................................33
6.1 ESQUEMAS DE AUTORIZACIÓN.....................................................................................34
6.2 INSTRUCCIONES GRANT Y REVOKE..............................................................................35
UNIDAD 7...............................................................................................................................36
INTRODUCCIÓN AL SQL PROCEDURAL................................................................................36
7.1 PROCEDIMIENTOS ALMACENADOS...............................................................................37
7.2 DISPARADORES (TRIGGERS).........................................................................................38
BIBLIOGRAFÍA........................................................................................................................39

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 3/42
3
INTRODUCCIÓN
Una base de datos o banco de datos es un conjunto de datos pertenecientesa un mismo contexto y almacenados sistemáticamente para su posterior
uso. En este sentido, una biblioteca puede considerarse una base de datoscompuesta en su mayoría por documentos y textos impresos en papel eindexados para su consulta. En la actualidad, y debido al desarrollotecnológico de campos como la informática y la electrónica, la mayoría delas bases de datos están en formato digital (electrónico), que ofrece unamplio rango de soluciones al problema de almacenar datos.Existen programas denominados sistemas gestores de bases de datos,abreviados SGBD, que permiten almacenar y posteriormente acceder a losdatos de forma rápida y estructurada. Las propiedades de estos SGBD, así como su utilización y administración, se estudian dentro del ámbito de lainformática.
Las aplicaciones más usuales son para la gestión de empresas einstituciones públicas. También son ampliamente utilizadas en entornoscientíficos con el objeto de almacenar la información experimental.Aunque las bases de datos pueden contener muchos tipos de datos, algunosde ellos se encuentran protegidos por las leyes de varios países. Porejemplo, en España los datos personales se encuentran protegidos por laLey Orgánica de Protección de Datos de Carácter Personal (LOPD).

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 4/42
4
UNIDAD 1
INTRODUCCIÓN AL SISTEMA MANEJADOR DE BASE DEDATOS (DBMS)
El sistema manejador de bases de datos es la porción más importante delsoftware de un sistema de base de datos. Un DBMS es una colección denumerosas rutinas de software interrelacionadas, cada una de las cuales esresponsable de alguna tarea específica.Las funciones principales de un DBMS son:
• Crear y organizar la Base de datos.• Manejar los datos de acuerdo a las peticiones de los usuarios.• Registrar el uso de las bases de datos.• Interacción con el manejador de archivos.• Respaldo y recuperación.• Control de concurrencia.•
Seguridad e integridad.Los Sistemas Gestores de Bases de Datos son un tipo de software muyespecífico, dedicado a servir de interfaz entre las bases de datos y lasaplicaciones que la utilizan. Se compone de un lenguaje de definición dedatos, de un lenguaje de manipulación de datos y de un lenguaje deconsulta. En los textos que tratan este tema, o temas relacionados, semencionan los términos SGBD y DBMS, siendo ambos equivalentes, yacrónimos, respectivamente, de Sistema Gestor de Bases de Datos yDataBase Management System, su expresión inglesa.
Motor ò Núcleo DBMS: recibe los requerimientos lógicos de E/S y losconvierte en operaciones de lectura y escritura.
Lógicos: son cualquier tipo de consulta requerimiento de lectura con ingresode datos (requerimiento de estructura) es ayudado por el Sistema Operativopara convertir estos requerimientos lógicos en físicos que actúan sobredispositivos de almacenamiento.
Herramientas de definición: permite definir y modificar la estructura de laBase de Datos, a este nivel definimos lo que se conoce como "Esquema "que es la definición total de Base de Datos, es que definimos la estructurade la tabla, los tipos de campos, las restricciones para los campos.
• Subesquema: manejo de vistas de datos, de niveles externos.• Esquema: manejo de niveles conceptuales.
5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 5/42
5
• Interface de Procesamiento: me provee de las facilidades deactualización, despliegue y visualización de datos.
• Desarrollo de Aplicaciones: me permite generar una aplicación por• Diccionario de Datos: este es el componente al subsistema con el que
interactúan directamente el DBA, le proporciona niveles de consulta yreportes útiles para su trabajo de administración. Es la descripción de
la estructura de Base de Datos y relaciones entre datos, y programas.DBMSCaracterísticas y Objetos:
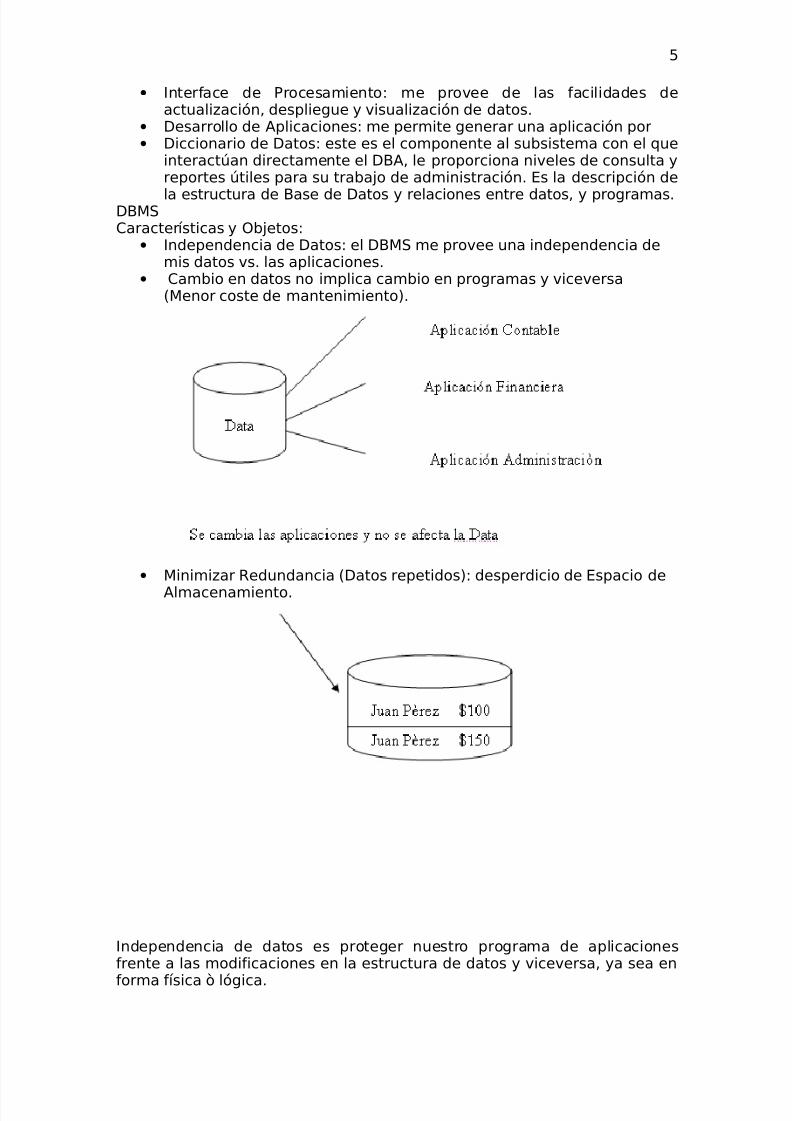
• Independencia de Datos: el DBMS me provee una independencia demis datos vs. las aplicaciones.
• Cambio en datos no implica cambio en programas y viceversa(Menor coste de mantenimiento).
• Minimizar Redundancia (Datos repetidos): desperdicio de Espacio deAlmacenamiento.
Independencia de datos es proteger nuestro programa de aplicacionesfrente a las modificaciones en la estructura de datos y viceversa, ya sea en
forma física ò lógica.

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 6/42
6
Independencia Física: es protección a los programas de aplicación debido acambios en la estructura de archivos, con cambios en las características delos campos.
• Independencia Lógica: protección a los programas de aplicacióncuando se modifica el esquema.
• Redundancia, datos repetidos y distribuidos en cualquier parte. Elefecto que ocasiona la redundancia es tener inconsistencia de datos ydesperdicio de espacio de almacenamiento.
Esta se presenta cuando se repiten innecesariamente datos en los archivosque conforman la base de datos.
• Inconsistencia de Datos: dato que esta en lugar con un valor yencuentra en otro lugar con otro valor.
Ocurre cuando existe información contradictoria o incongruente en la basede datos.
1.1 CONCEPTOS

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 7/42
7
Un sistema de administración de bases de datos DBMS (DatabaseManagement System, por sus siglas en inglés) es un sistema basado encomputador (software) que maneja una base de datos, o una colección debases de datos o archivos. La persona que administra un D0BMS esconocida como el DBA (Database Administrator, por sus siglas en ingles).Esta compuesto por:
• DDL (Data Definition Language): Lenguaje de Definición de Datos.• DML (Data Manipulation Language): Lenguaje de Manipulación de
Datos.• SQL: Lenguaje de Consulta.
Los sistemas de administración de bases de datos son usados para:
• Permitir a los usuarios acceder y manipular la base de datosproveyendo métodos para construir sistemas de procesamiento dedatos para aplicaciones que requieran acceso a los datos.
• Proveer a los administradores las herramientas que les permitanejecutar tareas de mantenimiento y administración de los datos.
Algunas de las funciones de un DBMS son:
• Definición de la base de datos - como la información va a seralmacenada y organizada.
• Creación de la base de datos - almacenamiento de datos en una basede datos definida.
• Recuperación de los datos - consultas y reportes.• Actualización de los datos - cambiar los contenidos de la base de
datos.•
Programación de aplicaciones de para el desarrollo de software.• Control de la integridad de la base de datos.• Monitoreo del comportamiento de la base de datos.
5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 8/42
8
1.2 CARACTERÍSTICAS DE UN DBMSLas principales características de un manejador de base de datos son:
• CONTROL DE LA REDUNDANCIA DE DATOSEste consiste en lograr una mínima cantidad de espacio de
almacenamiento para almacenar los datos evitando la duplicación de la
información. • MANTENIMIENTO DE LA INTEGRIDAD
La integridad de los datos es la que garantiza la precisión o exactitud de lainformación contenida en una base de datos. Los datos interrelacionadosdeben siempre representar información correcta a los usuarios.
• SOPORTE PARA CONTROL DE TRANSACCIONES Y RECUPERACIÓN DEFALLAS.
Se conoce como transacción toda operación que se haga sobre la base dedatos. Las transacciones deben por lo tanto ser controladas de manera queno alteren la integridad de la base de datos. La recuperación de fallas tieneque ver con la capacidad de un sistema DBMS de recuperar la informaciónque se haya perdido durante una falla en el software o en el hardware.
• INDEPENDENCIA DE LOS DATOS.En las aplicaciones basadas en archivos, el programa de aplicación debe
conocer tanto la organización de los datos como las técnicas que elpermiten acceder a los datos. En los sistemas DBMS los programas deaplicación no necesitan conocer la organización de los datos en el discoduro. Este totalmente independiente de ello.
• SEGURIDAD
La disponibilidad de los datos puede ser restringida a ciertos usuarios.Según los privilegios que posea cada usuario de la base de datos, podráacceder a mayor información que otros.

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 9/42
9
• VELOCIDAD
Los sistemas DBMS modernos poseen altas velocidades de respuesta yproceso.
• INDEPENDENCIA DEL HARDWARE
La mayoría de los sistemas DBMS están disponibles para ser instalados enmúltiples plataformas de hardware.
UNIDAD 2LENGUAJE DE DEFINICIÓN DE DATOS
Un lenguaje de definición de datos (Data Definition Language, DDL por sussiglas en inglés) es un lenguaje proporcionado por el sistema de gestión debase de datos que permite a los usuarios de la misma llevar a cabo lastareas de definición de las estructuras que almacenarán los datos así comode los procedimientos o funciones que permitan consultarlos.
El lenguaje de programación SQL, el más difundido entre los gestores debases de datos, admite las siguientes sentencias de definición: CREATE,DROP y ALTER, cada una de las cuales se puede aplicar a las tablas, vistas,procedimientos almacenados y triggers de la base de datos.
Otras que se incluyen dentro del DDL, pero que su existencia depende de la
implementación del estándar SQL que lleve a cabo el gestor de base dedatos son GRANT y REVOKE, los cuales sirven para otorgar permisos oquitarlos, ya sea a usuarios específicos o a un rol creado dentro de la basede datos.
Una vez finalizado el diseño de una base de datos y escogido un SGBD parasu implementación, el primer paso consiste en especificar el esquemaconceptual y el esquema interno de la base de datos, y la correspondenciaentre ambos. En muchos SGBD no se mantiene una separación estricta deniveles, por lo que el administrador de la base de datos y los diseñadoresutilizan el mismo lenguaje para definir ambos esquemas, es el lenguaje dedefinición de datos (LDD). El SGBD posee un compilador de LDD cuyafunción consiste en procesar las sentencias del lenguaje para identificar las

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 10/42
10
descripciones de los distintos elementos de los esquemas y almacenar ladescripción del esquema en el catálogo o diccionario de datos.
2.1 CREACIÓN DE BASE DE DATOS
Una base de datos en un sistema relacional está compuesta por un conjuntode tablas, que corresponden a las relaciones del modelo relacional. En laterminología usada en SQL no se alude a las relaciones, del mismo modoque no se usa el término atributo, pero sí la palabra columna, y no se hablade tupla, sino de línea. A continuación se usarán indistintamente ambasterminologías, por lo que tabla estará en lugar de relación, columna en el deatributo y línea en el de tupla, y viceversa. Antes de poder proceder a lacreación de las tablas, normalmente hay que crear la base de datos, lo quea menudo significa definir un espacio de nombres separado para cadaconjunto de tablas. De esta manera, para una DBMS se pueden gestionardiferentes bases de datos independientes al mismo tiempo sin que se den
conflictos con los nombres que se usan en cada una de ellas. Para crear una base de datos por ejemplo en Mysql debes de utilizar lainstrucción CREATE DATABASE nombre_base_datos que es similar en losotros manejadores de bases de datos
Prácticamente, la creación de la base de datos consiste en la creación de lastablas que la componen. En realidad, antes de poder proceder a la creaciónde las tablas, normalmente hay que crear la base de datos, lo que amenudo significa definir un espacio de nombres separado para cadaconjunto de tablas. De esta manera, para una DBMS se pueden gestionardiferentes bases de datos independientes al mismo tiempo sin que se denconflictos con los nombres que se usan en cada una de ellas. El sistema
previsto por el estándar para crear los espacios separados de nombresconsiste en usar las instrucciones SQL "CREATE SCHEMA". A menudo, dicho

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 11/42
11
sistema no se usa pero cada DBMS prevé un procedimiento propietario paracrear una base de datos. Normalmente, se amplía el lenguaje SQLintroduciendo una instrucción no prevista en el estándar: "CREATEDATABASE".
La sintaxis empleada por PostgreSQL, pero también por las DBMS más
difundidas, es la siguiente:
CREATE DATABASE nombre_base de datos
2.2 CREACIÓN DE TABLAS
En general, la mayoría de las bases de datos poseen potentes editores debases que permiten la creación rápida y sencilla de cualquier tipo de tablacon cualquier tipo de formato.
Sin embargo, una vez la base de datos está alojada en el servidor, puededarse el caso de que queramos introducir una nueva tabla ya sea concarácter temporal (para gestionar un carrito de compra por ejemplo) o bien
permanente por necesidades concretas de nuestra aplicación.En estos casos, podemos, a partir de una sentencia SQL, crear la tabla conel formato que deseemos lo cual nos puede ahorrar más de un quebraderode cabeza.
Este tipo de sentencias son especialmente útiles para bases de datos comoMysql, las cuales trabajan directamente con comandos SQL y no por mediode editores.
Para crear una tabla debemos especificar diversos datos: El nombre que lequeremos asignar, los nombres de los campos y sus características.
Además, puede ser necesario especificar cuáles de estos campos van a seríndices y de qué tipo van a serlo.

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 12/42
12
La sintaxis de creación puede variar ligeramente de una base de datos aotra ya que los tipos de campo aceptados no están completamenteestandarizados.
Tras la creación de la base de datos el siguiente paso que se debe realizar
es la creación de la tabla, o tablas, que almacenarán la información. Losdatos de los clientes, de los pedidos, de los socios, etc.…
Esta información será la que gestionen todos los demás objetos de la basede datos (consultas, formularios, etc.), por lo que es muy importanteplanificar bien la estructura que van a tener los datos (como van a estardispuestos en la tabla, de que naturaleza o tipo va a ser cada uno, en queorden estarán colocados, etc…), con el fin de poder dar respuesta a todaslas cuestiones que se puedan plantear sobre el manejo de dichainformación.
Para crear una tabla debemos especificar diversos datos: El nombre que lequeremos asignar, los nombres de los campos y sus características.Además, puede ser necesario especificar cuáles de estos campos van a seríndices y de qué tipo van a serlo.
La sintaxis de creación puede variar ligeramente de una base de datos aotra ya que los tipos de campo aceptados no están completamenteestandarizados.
A continuación os explicamos someramente la sintaxis de esta sentencia yos proponemos una serie de ejemplos prácticos:
Sintaxis
Create Table nombre_tabla(nombre_campo_1 tipo_1nombre_campo_2 tipo_2nombre_campo_n tipo_nKey(campo_x,...)
2.2.1 INTEGRIDAD
El término integridad de datos se refiere a la corrección y completitud de losdatos en una base de datos. Cuando los contenidos se modifican consentencias INSERT, DELETE o UPDATE, la integridad de los datosalmacenados puede perderse de muchas maneras diferentes. Puedenañadirse datos no válidos a la base de datos, tales como un pedido queespecifica un producto no existente.Pueden modificarse datos existentes tomando un valor incorrecto, como porejemplo si se reasigna un vendedor a una oficina no existente. Los cambiosen la base de datos pueden perderse debido a un error del sistema o a unfallo en el suministro de energía. Los cambios pueden ser aplicadosparcialmente, como por ejemplo si se añade un pedido de un producto sinajustar la cantidad disponible para vender.
Una de las funciones importantes de un DBMS relacional es preservar laintegridad de sus datos almacenados en la mayor medida posible.

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 13/42
13
Tipos de restricciones de integridad
Datos Requeridos: establece que una columna tenga un valor no NULL. Sedefine efectuando la declaración de una columna es NOT NULL cuando latabla que contiene las columnas se crea por primera vez, como parte de la
sentencia CREATE TABLE.• Chequeo de Validez: cuando se crea una tabla cada columna tiene un
tipo de datos y el DBMS asegura que solamente los datos del tipoespecificado sean ingresados en la tabla.
• Integridad de entidad: establece que la clave primaria de una tabladebe tener un valor único para cada fila de la tabla; si no, la base dedatos perderá su integridad. Se especifica en la sentencia CREATE
TABLE. El DBMS comprueba automáticamente la unicidad del valor dela clave primaria con cada sentencia INSERT Y UPDATE. Un intento deinsertar o actualizar una fila con un valor de la clave primaria yaexistente fallará.
• Integridad referencial: asegura la integridad entre las claves ajenas yprimarias (relaciones padre/hijo). Existen cuatro actualizaciones de labase de datos que pueden corromper la integridad referencial:
✔ La inserción de una fila hijo se produce cuando nocoincide la clave ajena con la clave primaria del padre.
✔ La actualización en la clave ajena de la fila hijo, donde seproduce una actualización en la clave ajena de la fila hijocon una sentencia UPDATE y la misma no coincide conninguna clave primaria.
✔ La supresión de una fila padre, con la que, si una filapadre -que tiene uno o más hijos- se suprime, las filas
hijos quedarán huérfanas.✔ La actualización de la clave primaria de una fila padre,
donde si en una fila padre, que tiene uno o más hijos seactualiza su clave primaria, las filas hijos quedaránhuérfanas.
2.2.2 INTEGRIDAD REFERENCIAL DECLARATIVA
La integridad de los datos es la propiedad que asegura que informacióndada es correcta, al cumplir ciertas aserciones.Las restricciones de integridad aseguran que la información contenida enuna base de datos es correcta.Las restricciones de integridad son propiedades de la base de datos que sedeben satisfacer en cualquier momento.Las restricciones de integridad aseguran que la información contenida en labase de datos cumple ciertas restricciones para los diferentes estados.

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 14/42
14
La integridad referencial es una propiedad deseable en las bases de datos.Gracias a la integridad referencial se garantiza que una entidad (fila oregistro) siempre se relaciona con otras entidades válidas, es decir, queexisten en la base de datos. Implica que en todo momento dichos datossean correctos, sin repeticiones innecesarias, datos perdidos y relacionesmal resueltas.
Todas las bases de datos relacionales gozan de esta propiedad gracias aque el software gestor de base de datos vela por su cumplimiento. Encambio, las bases de datos jerárquicas requieren que los programadores seaseguren de mantener tal propiedad en sus programas.
Ejemplo:
Supongamos una base de datos con las entidades Persona y Factura. Todafactura corresponde a una persona y solamente una. Implica que en todomomento dichos datos sean correctos, sin repeticiones innecesarias, datosperdidos y relaciones mal resueltas.
Supongamos que una persona se identifica por su atributo DNI (Documentonacional de identidad). También tendrá otros atributos como el nombre y ladirección. La entidad Factura debe tener un atributo DNI_cliente queidentifique a quién pertenece la factura.
Por sentido común es evidente que todo valor de DNI_cliente debecorresponder con algún valor existente del atributo DNI de la entidadPersona. Esta es la idea intuitiva de la integridad referencial.
Existen tres tipos de integridad referencial:
• Integridad referencial débil: si en una tupla de R todos los valores delos atributos de K tienen un valor que no es el nulo, entonces debeexistir una tupla en S que tome esos mismos valores en los atributosde J;
• Integridad referencial parcial: si en una tupla de R algún atributo de K toma el valor nulo, entonces debe existir una tupla en S que tome enlos atributos de J los mismos valores que los atributos de K con valorno nulo; y
• Integridad referencial completa: en una tupla de R todos los atributosde K deben tener el valor nulo o bien todos tienen un valor que no esel nulo y entonces debe existir una tupla en S que tome en los
atributos de J los mismos valores que toman los de K.
2.2.3 CREACIÓN DE ÍNDICES
Un índice (o KEY, o INDEX) es un grupo de datos que MySQL asocia con unao varias columnas de la tabla. En este grupo de datos aparece la relaciónentre el contenido y el número de fila donde está ubicado.

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 15/42
15
Los índices -como los índices de los libros- sirven para agilizar las consultasa las tablas, evitando que mysql tenga que revisar todos los datosdisponibles para devolver el resultado.
Podemos crear el índice a la vez que creamos la tabla, usando la palabraINDEX seguida del nombre del índice a crear y columnas a indexar (que
pueden ser varias):
INDEX nombre_indice (columna_indexada, columna_indexada2...)
La sintaxis es ligeramente distinta segun la clase de índice:PRIMARY KEY (nombre_columna_1 [,nombre_columna2...])UNIQUE INDEX nombre_indice (columna_indexada1[,columna_indexada2 ...])INDEX nombre_index (columna_indexada1 [,columna_indexada2...])
Podemos también añadirlos a una tabla después de creada:
ALTER TABLE nombre_tabla ADD INDEX nombre_indice (columna_indexada);Si queremos eliminar un índice: ALTER TABLE tabla_nombre DROP INDEXnombre_indice
Los index permiten mayor rápidez en la ejecución de las consultas a la basede datos tipo SELECT ... WHERE
La regla básica es pues crear tus índices sobre aquellas columnas que vayasa usar con una cláusula WHERE, y no crearlos con aquellas columnas quevayan a ser objeto de un SELECT: SELECT texto from tabla_libros WHEREautor = Vazquez; En este ejemplo, la de autor es una columna buenacandidata a un indice; la de texto, no.
Otra regla básica es que son mejores candidatas a indexar aquellascolumnas que presentan muchos valores distintos, mientras que no sonbuenas candidatas las que tienen muchos valores idénticos, como porejemplo sexo (masculino y femenino) porque cada consulta implicarásiempre recorrer prácticamente la mitad del índice.
Tipos de índice
En algunas bases de datos existen diferencias entre KEY e INDEX. No así enMySQL donde son sinónimos.
Un índice que sí es especial es el llamado PRIMARY KEY. Se trata de uníndice diseñado para consultas especialmente rápidas. Todos sus camposdeben ser UNICOS y no admite NULLUn indice UNIQUE es aquel que no permite almacenar dos valores iguales.
Los indices FULL TEXT permiten realizar búsquedas de palabras. Puedescrear indices FULLTEXT sobre columnas tipo CHAR, VARCHAR o TEXT.
UNIDAD 3

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 16/42
16
CONSULTAS Y LENGUAJE DE MANIPULACIÓN DEDATOS
Un Lenguaje de Manipulación de Datos (Data Manipulation Language, DML)es un lenguaje proporcionado por el sistema de gestión de base de datos
que permite a los usuarios de la misma llevar a cabo las tareas de consultao manipulación de los datos, organizados por el modelo de datos adecuado.
El lenguaje de manipulación de datos más popular hoy día es SQL, usadopara recuperar y manipular datos en una base de datos relacional. Otrosejemplos de DML son los usados por bases de datos IMS/DL1, CODASYL uotras.
Clasificación del lenguaje de manipulación de datos: Son DML: Select Insert Delete Update
Se clasifican en dos grandes grupos:
• Lenguajes de consulta procedimentalesLenguajes procedimentales. En este tipo de lenguaje el usuario dainstrucciones al sistema para que realice una serie de procedimientos uoperaciones en la base de datos para calcular un resultado final.
• lenguajes de consulta no procedimentalesEn los lenguajes no procedimentales el usuario describe la informacióndeseada sin un procedimiento específico para obtener esa información.
3.1 INSTRUCCIONES INSERT, UPDATE, DELETEEn SQL, hay fundamental y básicamente dos formas para insertar datos enuna tabla: Una es insertar una fila por vez, y la otra es insertar filasmúltiples por vez. Primero observemos como podemos insertamos datos através de una fila por vez:
La sintaxis para insertar datos en una tabla mediante una fila por vez es lasiguiente:
INSERT INTO "nombre_tabla" ("columna1", "columna2", ...)
VALUES ("valor1", "valor2", ...)Suponiendo que tenemos una taba con la siguiente estructura,
Tabla Store_Information
Column Name Data Type
store_name char(50)
Sales float
Date datetime
Y ahora deseamos insertar una fila adicional en la tabla que represente losdatos de ventas para Los Ángeles el 10 de enero de 1999. En ese día, estenegocio tenía $900 dólares estadounidenses en ventas. Por lo tanto,
utilizaremos la siguiente escritura SQL:

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 17/42
17
INSERT INTO Store_Information (store_name, Sales, Date)VALUES ('Los Angeles', 900, '10-Jan-1999')El segundo tipo de INSERT INTO nos permite insertar filas múltiples en unatabla. A diferencia del ejemplo anterior, donde insertamos una única fila alespecificar sus valores para todas las columnas, ahora utilizamos lainstrucción SELECT para especificar los datos que deseamos insertar en la
tabla. Si está pensando si esto significa que está utilizando información deotra tabla, está en lo correcto.
La sintaxis es la siguiente:
INSERT INTO "tabla1" ("columna1", "columna2", ...)SELECT "columna3", "columna4", ...FROM "tabla2"
Note que esta es la forma más simple. La instrucción entera puede contenerfácilmente cláusulas WHERE, GROUP BY, y HAVING, así como tambiénuniones y alias.
Entonces por ejemplo, si deseamos tener una tabla Store_Information, querecolecte la información de ventas para el año 1998, y ya conoce en dondereside la fuente de datos en tabla Sales_Information table,
Ingresaremos:
INSERT INTO Store_Information (store_name, Sales, Date)SELECT store_name, Sales, DateFROM Sales_InformationWHERE Year(Date) = 1998
Aquí hemos utilizado la sintaxis de Servidor SQL para extraer la informaciónanual por medio de una fecha. Otras bases de datos relacionales puedentener sintaxis diferentes. Por ejemplo, en Oracle, utilizará to_char(date,'yyyy')=1998.
Una vez que hay datos en la tabla, podríamos tener la necesidad demodificar los mismos. Para hacerlo, utilizamos el comando UPDATE. Lasintaxis para esto es,
UPDATE "nombre_tabla"SET "columna_1" = [nuevo valor]
WHERE {condición}Por ejemplo, digamos que actualmente tenemos la tabla a continuación:Tabla Store_Informationstore_name Sales Date
Los Angeles 1500 €05-Jan-1999
San Diego 250 €07-Jan-1999
Los Angeles 300 € 08-Jan-1999
Boston 700 € 08-Jan-1999
Y notamos que las ventas para Los Angeles el 08/01/1999 es realmente de
500€ en vez de 300€ dólares estadounidenses, y que esa entrada enparticular necesita actualizarse.Para hacerlo, utilizamos el siguiente SQL:

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 18/42
18
UPDATE Store_InformationSET Sales = 500WHERE store_name = "Los Angeles"AND Date = "08-Jan-1999"
La tabla resultante ser vería
Tabla Store_Informationstore_name Sales Date
Los Angeles 1500 €05-Jan-1999
San Diego 250 €07-Jan-1999
Los Angeles 500 € 08-Jan-1999
Boston 700 € 08-Jan-1999
En este caso, hay sólo una fila que satisface la condición en la cláusulaWHERE. Si hay múltiples filas que satisfacen la condición, todas ellas semodificarán.
También es posible UPDATE múltiples columnas al mismo tiempo. La
sintaxis en este caso se vería como la siguiente:
UPDATE "nombre_tabla"SET colonne 1 = [[valor1], colonne 2 = [valor2]WHERE {condición}
A veces podemos desear deshacernos de los registros de una tabla. Paraello, utilizamos el comando DELETE FROM. La sintaxis para esto es,
DELETE FROM "nombre_tabla"WHERE {condición}
Es más fácil utilizar un ejemplo. Por ejemplo, digamos que actualmentetenemos la siguiente tabla:
Tabla Store_Informationstore_name Sales Date
Los Angeles 1500 €05-Jan-1999
San Diego 250 €07-Jan-1999
Los Angeles 300 € 08-Jan-1999
Boston 700 € 08-Jan-1999
Y decidimos no mantener ninguna información sobre Los Ángeles en estatabla. Para lograrlo, ingresamos el siguiente SQL:
DELETE FROM Store_InformationWHERE store_name = "Los Angeles"store_name Sales Date
San Diego 250 €07-Jan-1999
Boston 700 € 08-Jan-1999
3.2 CONSULTAS BÁSICAS SELECT, WHERE Y FUNCIONES ANIVEL DE REGISTRO.
Para qué utilizamos los comandos SQL El uso común es la selección dedatos desde tablas ubicadas en una base de datos. Inmediatamente, vemos

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 19/42
19
dos palabras claves: necesitamos SELECT la información FROM una tabla.(Note que la tabla es un contenedor que reside en la base de datos dondese almacena la información. Para obtener más información acerca de cómomanipular tablas. Por lo tanto tenemos la estructura SQL más básica:
SELECT "nombre_columna" FROM "nombre_tabla"
Para ilustrar el ejemplo anterior, suponga que tenemos la siguiente tabla:
Tabla Store_Informationstore_name Sales Date
LosAngeles
1500€
05-Jan-1999
San Diego 250 € 07-Jan-1999
Los
Angeles300 € 08-Jan-
1999Boston 700 € 08-Jan-
1999
Podemos utilizar esta tabla como ejemplo a lo largo de la guía de referencia(esta tabla aparecerá en todas las secciones). Para seleccionar todos losnegocios en esta tabla, ingresamos:
SELECT store_name FROM Store_Information
Resultado:
store_nameLosAngelesSan DiegoLosAngelesBoston
Pueden seleccionarse los nombres de columnas múltiples, así como tambiénlos nombres de tablas múltiples.
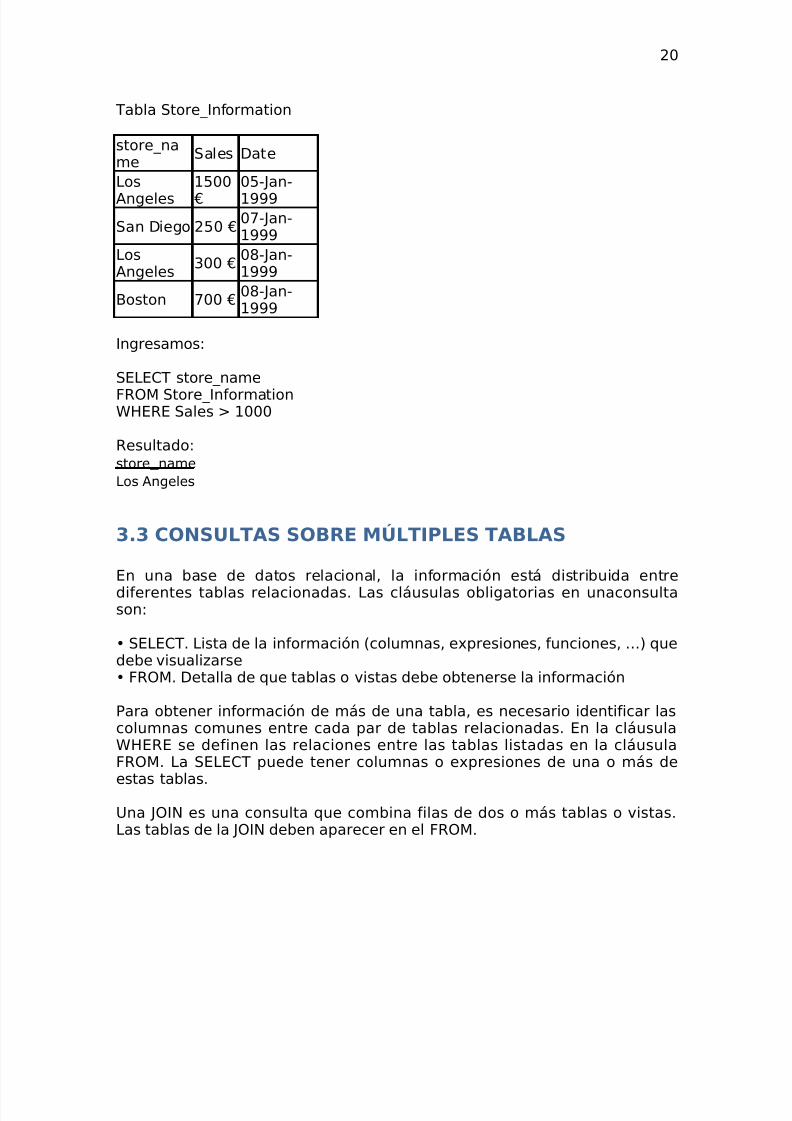
Luego, podríamos desear seleccionar condicionalmente los datos de unatabla. Por ejemplo, podríamos desear sólo recuperar los negocios con ventasmayores a $1.000 dólares. Para ello, utilizamos la palabra clave WHERE. Lasintaxis es la siguiente:
SELECT "nombre_columna"FROM "nombre_tabla"WHERE "condición"
Por ejemplo, para seleccionar todos los negocios con ventas mayores a1.000€ en la Tabla Store_Information,
5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 20/42
20
Tabla Store_Information
store_name
Sales Date
Los
Angeles
1500
€
05-Jan-
1999
San Diego 250 €07-Jan-1999
LosAngeles
300 € 08-Jan-1999
Boston 700 € 08-Jan-1999
Ingresamos:
SELECT store_name
FROM Store_InformationWHERE Sales > 1000
Resultado:store_name
Los Angeles
3.3 CONSULTAS SOBRE MÚLTIPLES TABLAS
En una base de datos relacional, la información está distribuida entrediferentes tablas relacionadas. Las cláusulas obligatorias en unaconsultason:
• SELECT. Lista de la información (columnas, expresiones, funciones, …) quedebe visualizarse• FROM. Detalla de que tablas o vistas debe obtenerse la información
Para obtener información de más de una tabla, es necesario identificar lascolumnas comunes entre cada par de tablas relacionadas. En la cláusulaWHERE se definen las relaciones entre las tablas listadas en la cláusulaFROM. La SELECT puede tener columnas o expresiones de una o más de
estas tablas.Una JOIN es una consulta que combina filas de dos o más tablas o vistas.Las tablas de la JOIN deben aparecer en el FROM.

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 21/42
21
3.3.1 SUBCONSULTAS
Es posible incorporar una instrucción SQL dentro de otra. Cuando esto sehace en las instrucciones where o having, tenemos una construcción desubconsulta.
La sintaxis es la siguiente:SELECT "nombre1_columna"FROM "nombre1_tabla"WHERE "nombre2_columna" [Operador de Comparación](SELECT "nombre3_columna"FROM "nombre2_tabla"WHERE [Condición])Una subconsulta es una sentencia select que aparece dentro de otrasentencia select que llamaremos consulta principal.
Se puede encontrar en la lista de selección, en la cláusula where o en lacláusula having de la consulta principal.
Una subconsulta tiene la misma sintaxis que una sentencia select normalexceptuando que aparece encerrada entre paréntesis, no puede contener lacláusula order by, ni puede ser la unión de varias sentencias select, ademástiene algunas restricciones en cuanto a número de columnas según el lugardonde aparece en la consulta principal.
A menudo, es necesario, dentro del cuerpo de una subconsulta, hacerreferencia al valor de una columna en la fila actual de la consulta principal,ese nombre de columna se denomina referencia externa. Una referencia
externa es un nombre de columna que estando en la subconsulta, no serefiere a ninguna columna de las tablas designadas en la from de lasubconsulta sino a una columna de las tablas designadas en la from de laconsulta principal.
Ejemplo:SELECT numemp, nombre, (SELECT MIN(fechapedido) FROM pedidos WHERErep = numemp) FROM empleados;
3.3.2 OPERADORES JOINAhora miremos las uniones. Para realizar uniones en SQL se requieren
mucho de los elementos que ya hemos presentado. Digamos que tenemoslas siguientes dos tablas:
Tabla Store_Informationstore_name Sales Date
LosAngeles
1500€
05-Jan-1999
San Diego 250 € 07-Jan-1999
Los
Angeles300 € 08-Jan-
1999Boston 700 € 08-Jan-

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 22/42
22
1999
Tabla Geographyregion_name
store_name
East BostonEast New York
West LosAngeles
West San Diego
Y queremos saber las ventas por región. Vemos que la tabla Geographyincluye información sobre regiones y negocios, y la tabla Store_Informationcontiene información de ventas para cada negocio. Para obtener lainformación de ventas por región, debemos combinar la información de lasdos tablas. Al examinar las dos tablas, encontramos que están enlazadas através del campo común “nombre_negocio”
Primero presentaremos la instrucción SQL y explicaremos el uso de cadasegmento después:
SELECT A1.region_name REGION, SUM(A2.Sales) SALESFROM Geography A1, Store_Information A2
WHERE A1.store_name = A2.store_nameGROUP BY A1.region_name
Resultado:
REGIÓN
SALES
East 700 €
West2050€
Las primeras dos líneas le indican a SQL que seleccione dos campos, el
primero es el campo "nombre_región" de la tabla Geography (denominadoREGIÓN), y el segundo es la suma del campo "Sales" de la tablaStore_Information (denominado SALES). Note como se utilizan los alias detabla aquí: Geografía se denomina A1, e Información_Negocio se denominaA2. Sin los alias, la primera línea sería
SELECT Geography.region_name REGION, SUM(Store_Information.Sales)SALES
Que es mucho más problemática. En esencia, los alias de tabla facilitan elentendimiento de la totalidad de la instrucción SQL, especialmente cuandose incluyen tablas múltiples.
Luego, pongamos nuestra atención en la línea 2, la instrucción WHERE. Aquí es donde se especifica la condición de la unión. En este caso, queremos

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 23/42
23
asegurarnos que el contenido en “nombre_negocio” en la tabla Geografíaconcuerde con la tabla Store_Information, y la forma de hacerlo esigualarlos. Esta instrucción WHEREes esencial para asegurarse de queobtenga el resultado correcto. Sin la correcta instrucción WHERE seproducirá una Unión Cartesiana. Las uniones cartesianas darán porresultado que de la consulta se arroje toda combinación posible de las dos
tablas (o cualquiera que sea el número de tablas en la instrucción FROM).En este caso, una unión cartesiana resultaría en un total de 4x4 = Sepresenta un resultado de16 filas.
3.4 AGREGACIÓN GROUP BY, HAVING
Las funciones de agrupación operan sobre conjuntos de filas para dar unresultado por grupo. Así tenemos para atributos numéricos.Las funciones de agrupación ignoran los valores NULL en las consultas,aunque se puede utilizar NVL (en Oracle) para forzar a que considere a NULLcomo un valor determinado.La cláusula GROUP BY seguida de una lista de atributos permite agrupar lastuplas enGrupos que tengan los mismos valores en todos los atributos de esa listaEjemplo:“Obtener el número de profesores de cada área”
SELECT COUNT(*) ,AREAFROM PROFESORESGROUP BY AREA;
Si quisiéramos calcular el total de ventas para cada negocio entonces,necesitamos hacer dos cosas: Primero, necesitamos asegurarnos de quehayamos seleccionado el nombre del negocio así como también las ventastotales. Segundo, debemos asegurarnos de que todas las sumas de lasventas estén group by negocios. La sintaxis SQL correspondiente es,
SELECT "nombre1_columna", SUM("nombre2_columna")FROM "nombre_tabla"GROUP BY "nombre1-columna"
Ilustremos utilizando la siguiente tabla, Tabla Store_Informationstore_name Sales Date
LosAngeles
1500€
05-Jan-1999
San Diego 250 € 07-Jan-1999
LosAngeles 300 €
08-Jan-1999
Boston 700 € 08-Jan-

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 24/42
24
1999
Deseamos saber las ventas totales para cada negocio. Para hacerlo,ingresaríamos,
SELECT store_name, SUM(Sales)
FROM Store_InformationGROUP BY store_nameResultado:store_name
SUM(Sales)
LosAngeles
1800 €
SanDiego 250 €
Boston>700 €
La palabra clave group by se utiliza cuando estamos seleccionado columnasmúltiples desde una tabla (o tablas) y aparece al menos un operadoraritmético en la instrucción select. Cuando esto sucede, necesitamos groupby todas las otras columnas seleccionadas, es decir, todas las columnasexcepto aquella(s) que se operan por un operador aritmético.
La cláusula HAVING permite establecer una condición sobre los grupos demanera queSólo se seleccionan aquellos grupos que la cumplen“listar los profesores y el nº de clases que imparten, pero sólo de aquellos
profesores queImparten más de 10 clases”
SELECT PROFESOR,COUNT(*)FROM DOCENCIAGROUP BY PROFESORHAVING COUNT(*)>10;
Otra cosa que las personas pueden hacer es limitar el resultado según lasuma correspondiente (o cualquier otra función de agregado). Por ejemplo,podríamos desear ver sólo los negocios con ventas mayores a 1 500 €. Envez de utilizar la cláusula where en la instrucción sql, a pesar de que
necesitemos utilizar la cláusula having, que se reserva para funciones deagregados. La cláusula having se coloca generalmente cerca del fin de lainstrucción sql, y la instrucción sql con la cláusula having.
Puede o no incluir la cláusula group by sintaxis para having es,
Select "nombre1_columna", sum("nombre2_columna")from "nombre_tabla"group by "nombre1_columna"having (condición de función aritmética)Nota: la cláusula group by es opcional.
En nuestro ejemplo, tabla store_information,

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 25/42
25
Tabla store_informationstore_name
Sales Date
LosAngeles
1500€
05-Jan-1999
San Diego 250 €07-Jan-1999
LosAngeles
300 € 08-Jan-1999
Boston 700 € 08-Jan-1999
Ingresaríamos,SELECT store_name, SUM(sales)FROM Store_InformationGROUP BY store_nameHAVING SUM(sales) > 1500
Resultado:store_name
SUM(Sales)
LosAngeles
1800 €
3.5 FUNCIONES DE CONJUNTO DE REGISTROS COUNT,SUM, AVG, MAX, MINFunciones de agregación Son funciones que toman una colección de valorescomo entrada y producen un único valor de salida. SQL proporciona cincofunciones de agregación primitivas:
• avg: media aritmética de un atributo o una expresión numérica• min: mínimo de un atributo o expresión numérica• max: máximo de un atributo o expresión numérica• sum: suma total de atributos o expresiones numéricas•
count (*): contador de tuplas • count (distinct): contador de tuplasparcial, no tiene en cuenta
Todos los operadores, excepto avg y sum, pueden operar con números ycadenas de caracteres. La función de agregación se coloca en la líneaselect. La cláusula group by se utiliza cuando las funciones de agregación seaplican a un grupo de conjuntos de tuplas, y la cláusula having se utilizapara poner una condición a los grupos.
SQL tiene varias funciones aritméticas, y estas son:- AVG
- COUNT- MAX

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 26/42
26
- MIN- SUM
La sintaxis para el uso de funciones es,SELECT "tipo de función"("nombre_columna")FROM "nombre_tabla"
Por ejemplo, si deseamos obtener la sumatoria de todas las ventas de lasiguiente tabla,
Tabla Store_Informationstore_name Sales Date
LosAngeles
1500€
05-Jan-1999
San Diego 250 € 07-Jan-1999
LosAngeles 300 € 08-Jan-1999
Boston 700 € 08-Jan-1999
IngresaríamosSELECT SUM(Sales) FROM Store_InformationResultado:
SUM(Sales)
2750 €
2 750 € representa la suma de todas las entradas de Ventas: 1500 € + 250€ + 300 € + 700 €.Además de utilizar dichas funciones, también es posible utilizar SQL pararealizar tareas simples como suma (+) y resta (-). Para ingresar datos deltipo caracter, hay también varias funciones de cadenas disponibles, talescomo funciones de concatenación, reducción y subcadena. Los diferentesproveedores RDBMS tienen diferentes implementaciones de funciones decadenas, y es mejor consultar las referencias para sus RDBMS a fin de vercómo se utilizan estas funciones.Otra función aritmética es COUNT. Esto nos permite COUNT el número defilas en una tabla determinada. La sintaxis es,
SELECT COUNT("nombre_columna")FROM "nombre_columna"
Por ejemplo, si deseamos encontrar el número de entradas de negocios ennuestra tabla,
Tabla Store_Informationstore_name Sales Date
LosAngeles
1500
€05-Jan-1999
San Diego 250 € 07-Jan-1999

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 27/42
27
LosAngeles
300 € 08-Jan-1999
Boston 700 €08-Jan-1999
Ingresamos,SELECT COUNT(store_name)FROM Store_InformationResultado:
Count(store_name)
4 COUNT y DISTINCT pueden utilizarse juntos en una instrucción paradeterminar el número de las distintas entradas en una tabla. Por ejemplo, sideseamos saber el número de los distintos negocios, ingresaríamos,
SELECT COUNT(DISTINCT store_name)FROM Store_Information
Resultado:Count(DISTINCT store_name)
3
UNIDAD 4CONTROL DE TRANSACCIONES
Los sistemas que tratan el problema de control de concurrencia permitenque sus usuarios asuman que cada una de sus aplicaciones se ejecutaatómicamente, como si no existieran otras aplicaciones ejecutándoseconcurrentemente.
Esta abstracción de una ejecución atómica y confiable de una aplicación seconoce como una transacción.
Un algoritmo de control de concurrencia asegura que las transacciones seejecuten atómicamente controlando la intercalación de transacciones

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 28/42
28
concurrentes, para dar la ilusión de que las transacciones se ejecutanserialmente, una después de la otra, sin ninguna intercalación. Lasejecuciones intercaladas cuyos efectos son los mismos que las ejecucionesseriales son denominadas serializables y son correctos ya que soportan lailusión de la atomicidad de las transacciones.
El concepto principal es el de transacción. Informalmente, una transacciónes la ejecución de ciertas instrucciones que accedan a una base de datoscompartida. El objetivo del control de concurrencia y recuperación esasegurar que dichas transacciones se ejecuten atómicamente, es decir:
Cada transacción accede a información compartida sin interferir con otrastransacciones, y si una transacción termina normalmente, todos sus efectosson permanentes, en caso contrario no tiene afecto alguno.
Una transacción es la ejecución de ciertas instrucciones que accedan a unabase de datos compartida. El objetivo del control de concurrencia yrecuperación es asegurar que dichas transacciones se ejecutenatómicamente, es decir:
Cada transacción accede a información compartida sin interferir con otrastransacciones, y si una transacción termina normalmente, todos sus efectosson permanentes, en caso contrario no tiene afecto alguno.
Una base de datos está en un estado consistente si obedece todas lasrestricciones de integridad (significa que cuando un registro en una tablahaga referencia a un registro en otra tabla, el registro correspondientesdebe existir) definidas sobre ella.
Los cambios de estado ocurren debido a actualizaciones, inserciones ysupresiones de información. Por supuesto, se quiere asegurar que la basede datos nunca entre en un estado de inconsistencia.
4.1 PROPIEDAD DE UNA TRANSACCIÓNPROPIEDADES FUNDAMENTALES DE UNA TRANSACCIÓN:
• Atomicidad Se refiere al hecho de que una transacción se trata comouna unidad de operación. Por lo tanto, o todas las acciones de latransacción se realizan o ninguna de ellas se lleva a cabo. Laatomicidad requiere que si una transacción se interrumpe por unafalla, sus resultados parciales sean anulados.
• Consistencia La consistencia de una transacción es simplemente su
correctitud. En otras palabras, una transacción es un programacorrecto que lleva a la base de datos de un estado consistente a otro

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 29/42
29
con la misma característica. Debido a esto, las transacciones noviolan las restricciones de integridad de una base de datos.
• Aislamiento Una transacción en ejecución no puede revelar susresultados a otras transacciones concurrentes antes de finalizar. Másaún, si varias transacciones se ejecutan concurrentemente, losresultados deben ser los mismos que si ellas se hubieran ejecutado
de manera secuencial.• Permanencia Es la propiedad de las transacciones que asegura que
una vez que una transacción finaliza exitosamente, sus resultadosson permanentes y no pueden ser borrados de la base de datos poralguna falla posterior. Por lo tanto, los sistemas manejadores de basede datos aseguran que los resultados de una transacción sobrevivirána fallas del sistema. Esta propiedad motiva el aspecto derecuperación de base de datos, el cual trata sobre cómo recuperar labase de datos a un estado consistente donde todas las acciones quehan finalizado con éxito queden reflejadas en la base.
• En esencia, lo que se persigue con el procesamiento de transaccioneses, por una parte obtener una transparencia adecuada de lasacciones concurrentes a una base de datos y por otra, manejaradecuadamente las fallas que se puedan presentar en una base dedatos. La mayoría de medianas y grandes compañías modernasutilizan el procesamiento de transacciones para sus sistemas deproducción, y es tan imprescindible que las organizaciones nopueden funcionar en ausencia de él.
El procesamiento de transacciones representa una enorme y significativaporción del mercado de los sistemas informáticos (más de cincuentabillones de dólares al año) y es, probablemente, la aplicación simple másamplia de las computadoras.
Además, se ha convertido en el elemento que facilita el comercioelectrónico.
Como puede percibirse, el procesamiento de transacciones es una delas tareas más importantes dentro de un sistema de base de datos,pero a la vez, es una de las más difíciles de manejar debido adiversos aspectos, tales como:
• Confiabilidad Puesto que los sistemas de base de datos en línea nopueden fallar.
• Disponibilidad Debido a que los sistemas de base de datos en líneadeben estar actualizados correctamente todo el tiempo.
• Tiempos de Respuesta En sistemas de este tipo, el tiempo derespuesta de las transacciones no debe ser mayor a doce segundos.
• hroughput Los sistemas de base de datos en línea requieren procesarmiles de transacciones por segundo.
• Atomicidad En el procesamiento de transacciones no se aceptanresultados parciales.
• Permanencia No se permite la eliminación en la base de datos de losefectos de una transacción que ha culminado con éxito
4.2 GRADOS DE CONSISTENCIA
Consistencia es un término más amplio que el de integridad. Podría definirsecomo la coherencia entre todos los datos de la base de datos. Cuando se

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 30/42
30
pierde la integridad también se pierde la consistencia. Pero la consistenciatambién puede perderse por razones de funcionamiento.
Una transacción finalizada ( confirmada parcialmente ) puede no confirmarsedefinitivamente (consistencia).
• Si se confirma definitivamente el sistema asegura la persistencia delos cambios que ha efectuado en la base de datos.• Si se anula los cambios que ha efectuado son deshechos.
La ejecución de una transacción debe conducir a un estado de la base dedatos consistente (que cumple todas las restricciones de integridaddefinidas).
• Si se confirma definitivamente el sistema asegura la persistencia delos cambios que ha efectuado en la base de datos.
• Si se anula los cambios que ha efectuado son deshechos.
Una transacción que termina con éxito se dice que está comprometida(commited), una transacción que haya sido comprometida llevará a la basede datos a un nuevo estado consistente que debe permanecer incluso si hayun fallo en el sistema. En cualquier momento una transacción sólo puedeestar en uno de los siguientes estados.
• Activa (Active): el estado inicial; la transacción permanece en esteestado durante su ejecución.
• Parcialmente comprometida (Uncommited): Después de ejecutarse laúltima transacción.
• Fallida (Failed): tras descubrir que no se puede continuar la ejecuciónnormal.
• Abortada (Rolled Back): después de haber retrocedido la transaccióny restablecido la base de datos a su estado anterior al comienzo de latransacción.
• Comprometida (Commited): tras completarse con éxito. Aspectos relacionados al procesamiento de transaccionesLos siguientes son los aspectos más importantes relacionados con el
procesamiento de transacciones:• Modelo de estructura de transacciones. Es importante considerar si
las transacciones son planas o pueden estar anidadas.•
Consistencia de la base de datos interna. Los algoritmos de control dedatos semántico tienen que satisfacer siempre las restricciones deintegridad cuando una transacción pretende hacer un commit.
• Protocolos de confiabilidad. En transacciones distribuidas esnecesario introducir medios de comunicación entre los diferentesnodos de una red para garantizar la atomicidad y durabilidad de lastransacciones. Así también, se requieren protocolos para larecuperación local y para efectuar los compromisos (commit)globales.
• Algoritmos de control de concurrencia. Los algoritmos de control deconcurrencia deben sincronizar la ejecución de transaccionesconcurrentes bajo el criterio de correctitud. La consistencia entre
transacciones se garantiza mediante el aislamiento de las mismas.4.3 NIVELES DE AISLAMIENTO

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 31/42
31
Las transacciones especifican un nivel de aislamiento que define el grado enque se debe aislar una transacción de las modificaciones de recursos odatos realizadas por otras transacciones. Los niveles de aislamiento sedescriben en cuanto a los efectos secundarios de la simultaneidad que sepermiten, como las lecturas desfasadas o ficticias.
Control de los niveles de aislamiento de transacción:• Controla si se realizan bloqueos cuando se leen los datos y qué tipos
de bloqueos se solicitan.• Duración de los bloqueos de lectura.• Si una operación de lectura que hace referencia a filas modificadas
por otra transacción:
✔ Se bloquea hasta que se libera el bloqueo exclusivo de la fila.✔ Recupera la versión confirmada de la fila que existía en el
momento en el que empezó la instrucción o la transacción.✔
Lee la modificación de los datos no confirmados.El estándar ANSI/ISO SQL define cuatro niveles de aislamiento transaccional
en función de tres eventos que son permitidos o no dependiendo del nivelde aislamiento. Estos eventos son:
Lectura sucia. Las sentencias SELECT son ejecutadas sin realizar bloqueos,pero podría usarse una versión anterior de un registro. Por lo tanto, laslecturas no son consistentes al usar este nivel de aislamiento.
• Lectura no repetible. Una transacción vuelve a leer datos quepreviamente había leído y encuentra que han sido modificados o
eliminados por una transacción cursada.• Lectura fantasma. Una transacción vuelve a ejecutar una consulta,
devolviendo un conjunto de registros que satisfacen una condición debúsqueda y encuentra que otros registro que satisfacen la condiciónhan sido insertadas por otra transacción cursada.
Los niveles de aislamiento SQL son definidos basados en si ellos permiten acada uno de los eventos definidos anteriormente. Es interesante notar queel estándar SQL no impone un esquema de cierre específico o confiere pormandato comportamientos particulares, pero más bien describe estosniveles de aislamiento en términos de estos teniendo muchos mecanismosde cierre/coincidencia, que dependen del evento de lectura.
Niveles de aislamiento:

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 32/42
32
Según el estándar SQL,SQL Server permite todosestos niveles, Oracle sólopermite la lectura
comprometida y secuenciable. Los niveles se pueden establecer en ambospara cada transacción. Sin embargo esto no es necesariamente cierto.El estándar SQL trataba de establecer los niveles de aislamiento que
permitirían a varios grados de consistencia para querys ejecutadas en cadanivel de aislamiento. Las lecturas repetibles "REPEATABLE READ" es el nivelde aislamiento que garantiza que un query un resultado consistente. En ladefinición SQL estándar, la lectura comprometida "READ COMMITTED" noregresa resultados consistentes, en la lectura no comprometida "READUNCOMMITTED" las sentencias SELECT son ejecutadas sin realizar bloqueos,pero podría usarse una versión anterior de un registro. Por lo tanto, laslecturas no son consistentes al usar este nivel de aislamiento.
A mayor grado de aislamiento, mayor precisión, pero a costa de menorconcurrencia.El nivel de aislamiento para una sesión SQL establece el comportamiento de
los bloqueos para las instrucciones SQL.
4.4 INSTRUCCIONES COMMIT Y ROLLBACK
Rollback transaction sin savepoint_name o transaction_name revierte todaslas instrucciones hasta el principio de la transacción. Cuando se trata detransacciones anidadas, esta misma instrucción revierte todas lastransacciones internas hasta la instrucción begin transaction más externa.En ambos casos, rollback transaction disminuye la función del sistema@@trancount a 0, mientras que rollback transaction con savepoint_name nodisminuye @@trancount.
Una instrucción rollback transaction que especifica un savepoint_name nolibera ningún bloqueo.
Rollback transaction no puede hacer referencia a un savepoint_name entransacciones distribuidas que se iniciaron explícitamente con begindistributed transaction o que se escalaron a partir de una transacción local.
Una transacción no se puede revertir después de ejecutar una instruccióncommit transaction.
En una transacción se permiten nombres de puntos de almacenamientoduplicados, pero una instrucción rollback transaction que utilice este
nombre sólo revierte las transacciones realizadas hasta la instrucción savetransaction más reciente que también utilice este nombre.
Comportamiento permitido
Nivel de aislamientoLectura
SuciaNo repetibleFantasma
Lectura no comprometida Sí Sí Sí
Lectura comprometida No Sí Sí
Lectura repetible No No Sí
Secuenciable No No No

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 33/42
33
Si se emite la instrucción ROLLBACK TRANSACTION en un desencadenador:
• Se revierten todas las modificaciones de datos realizadas hasta esepunto de la transacción actual, incluidas las que realizó eldesencadenador.
• El desencadenador continúa la ejecución del resto de las
instrucciones después de la instrucción ROLLBACK. Si alguna de estasinstrucciones modifica datos, no se revierten las modificaciones. Laejecución de las instrucciones restantes no activa ningúndesencadenador anidado.
• Tampoco se ejecutan las instrucciones del lote después de lainstrucción que activó el desencadenador.
COMMIT TRANSACTION
Si la transacción que se ha confirmado era una transacción Transact-SQLdistribuida, COMMIT TRANSACTION hace que MS DTC utilice el protocolo deconfirmación en dos fases para confirmar los servidores involucrados en latransacción. Si una transacción local afecta a dos o más bases de datos dela misma instancia del Database Engine (Motor de base de datos), lainstancia utiliza una confirmación interna en dos fases para confirmar todaslas bases de datos involucradas en la transacción.
Cuando se utiliza en transacciones anidadas, las confirmaciones de lastransacciones anidadas no liberan recursos ni hacen permanentes susmodificaciones. Las modificaciones sobre los datos sólo quedanpermanentes y se liberan los recursos cuando se confirma la transacciónmás externa. Cada commit transaction que se ejecute cuando @@trancountsea mayor que 1 sólo reduce @@trancount en 1. Cuando @@trancount llegaa 0, se confirma la transacción externa entera. Como database engine(motor de base de datos) omite transaction_name, la ejecución de unainstrucción commit transaction que haga referencia al nombre de unatransacción externa cuando haya transacciones internas pendientes sóloreduce @@trancount en 1.
UNIDAD 5VISTAS
Una vista de base de datos es un resultado de una consulta SQL de una ovarias tablas; también se le puede considerar una tabla virtual.Las vistas tienen la misma estructura que una tabla: filas y columnas. La
única diferencia es que sólo se almacena de ellas la definición, no los datos.Los datos que se recuperan mediante una consulta a una vista sepresentarán igual que los de una tabla. De hecho, si no se sabe que se está

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 34/42
34
trabajando con una vista, nada hace suponer que es así. Al igual que sucedecon una tabla, se pueden insertar, actualizar, borrar y seleccionar datos enuna vista. Aunque siempre es posible seleccionar datos de una vista, enalgunas condiciones existen restricciones para realizar el resto de lasoperaciones sobre vistas.Una vista se especifica a través de una expresión de consulta (una
sentencia SELECT) que la calcula y que puede realizarse sobre una o mástablas. Sobre un conjunto de tablas relacionales se puede trabajar con unnúmero cualquiera de vistas. Una vista se caracteriza porque:
• –Se considera que forma parte del esquema externo.• Una vista es una tabla virtual (no tiene una correspondencia a nivel
físico)• Se puede consultar como cualquier tabla básica.• Las actualizaciones se transfieren a la/s tabla/s original/es (con
ciertas limitaciones).
5.1 DEFINICIÓN Y OBJETIVO DE LAS VISTAS
Una vista en SQL es el resultado de una consulta de varias tablas que te
aparece como una sola tabla.
Una vista es como una ventana a través de la cual se puede consultar ocambiar información de la tabla a la que está asociada.
Las vistas tienen la misma estructura que una tabla: filas y columnas. Laúnica diferencia es que sólo se almacena de ellas la definición, no los datos.Los datos que se recuperan mediante una consulta a una vista sepresentarán igual que los de una tabla. De hecho, si no se sabe que se estátrabajando con una vista, nada hace suponer que es así. Al igual que sucedecon una tabla, se pueden insertar, actualizar, borrar y seleccionar datos enuna vista. Aunque siempre es posible seleccionar datos de una vista, enalgunas condiciones existen restricciones para realizar el resto de lasoperaciones sobre vistas.
• Las vistas pueden proporcionar un nivel adicional de seguridad. Porejemplo, en la tabla de empleados, cada responsable dedepartamento sólo tendrá acceso a la información de sus empleados.La siguiente sentencia produce la creación de la vista de losempleados del departamento de administración (cod_dep=100).
• Las vistas permiten ocultar la complejidad de los datos. Una BD secompone de muchas tablas. La información de dos o más tablaspuede recperarse utilizando una combinación de dos o más tablas, y
estas combinaciones pueden llegar a ser muy confusas. Creando una

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 35/42
35
vista como resultado de la combinación se puede ocultar lacomplejidad al usuario.
• Las vistas ayudan a mantener unos nombres razonables. Las vistas tienen la misma estructura que una tabla: filas y columnas. Laúnica diferencia es que sólo se almacena de ellas la definición, no los datos.
Los datos que se recuperan mediante una consulta a una vista sepresentarán igual que los de una tabla. De hecho, si no se sabe que se estátrabajando con una vista, nada hace suponer que es así. Al igual que sucedecon una tabla, se pueden insertar, actualizar, borrar y seleccionar datos enuna vista. Aunque siempre es posible seleccionar datos de una vista, enalgunas condiciones existen restricciones para
Las vistas son útiles:• Proporcionan un poderoso mecanismo de seguridad, ocultando partes
de la base de datos a ciertos usuarios. El usuario no sabrá que existenaquellos atributos que se han omitido al definir una vista.
5.2 INSTRUCCIONES PARA LA ADMINISTRACIÓN DEVISTAS
Muchas bases de datos relacionales que se utilizan en aplicaciones delmundo real tienen esquemas complejos y formados por muchas tablas. Enocasiones, es conveniente que algunos grupos o perfiles de usuarios tenganuna vista parcial de ese esquema, o que tengan una visión de la misma conuna estructura diferente a la del esquema que realmente está almacenado.Precisamente para estos casos, el lenguaje SQL permite definir vistas.
Una vista es esencialmente una consulta almacenada que devuelve unconjunto de resultados y a la que se le pone un nombre. Una vista es una“tabla virtual”, aparece como una tabla más del esquema, aunquerealmente no lo es.Sintaxis
La sintaxis general para crear una vista es la siguiente:
CREATE VIEW view_name [(column_list)]
AS sentencia_select
UNIDAD 6

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 36/42
36
SEGURIDAD
La ejecución de una operación en los datos de la base de datos por parte deun usuario está supeditada a la posesión por parte del usuario de losprivilegios necesarios para la operación concreta ejecutada en el conjuntode datos específico.En general, los privilegios se asignan del siguiente modo:
• Un usuario que crea una tabla o cualquier otro objeto de la base dedatos es el propietario y se le garantizan automáticamente todos losprivilegios aplicables a dicho objeto, con la posibilidad de darlestambién a otros usuarios dichos privilegios (privilegio de concesión).
• Un usario que tenga un privilegio y posea además sobre él el
privilegio de concesión puede asignarle tal pricilegio a otro usuario ypasarle también el privilegio de concesión.
• Los privilegios los concede quien tiene el permiso (es decir elpropietario del objeto y quien tiene el privilegio de concesión)
mediante la orden GRANT, y los revoca mediante la orden REVOKE. En SQL Server nos encontramos con tres niveles o capas en los cualespodemos gestionar la seguridad. El primero de ellos se encuentra a nivel deservidor, en él podemos gestionar quién tiene acceso al servidor y quién no,y además gestionamos que roles va a desempeñar. Para que alguien puedaacceder al servidor debe tener un inicio de sesión (login) asignado, y a éstese asignaremos los roles o funciones que puede realizar sobre el servidor.El que alguien tenga acceso al servidor no quiere decir que pueda acceder alas bases de datos que se encuentran en él. Para ello hay que tener accesoa la siguiente barrera de seguridad, que es a nivel de base de dato. Paraque un login tenga acceso a una base de datos, tenemos que crear en ellaun usuario (user). Deberemos crear un usuario en cada una de las bases dedatos a las que queramos que acceda un login.Análogamente, el que un usuario tenga acceso a una base de datos noquiere decir que tenga acceso a todo su contenido, ni a cada uno de losobjetos que la componen. Para que esto ocurra tendremos que irleconcediendo o denegando permisos sobre cada uno de los objetos que lacomponen.
6.1 ESQUEMAS DE AUTORIZACIÓN
Un esquema SQL se identifica con un nombre de esquema, y consta de unidentificador de autorización que indica el usuario o la cuenta propietaria delesquema, además de los descriptores de cada elemento del esquema. Loselementos del esquema comprenden tablas, restricciones, vistas, dominiosy otros integrantes (como concesiones de autorización) que describen elesquema.Un esquema se crea mediante la sentencia CREATE SCHEMA, que puedecontener todas las definiciones de elementos del esquema. Comoalternativa, podemos asignar un nombre y un identificador de autorizaciónde esquema y definir dichos elementos más adelante.

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 37/42
37
Además del concepto de esquema, SQL2 emplea el concepto de catálogo odiccionario de datos DD (colección nombrada de esquemas). Un catálogosiempre contiene un esquema especial llamado INFORMATION_SCHEMA, queproporciona a los usuarios autorizados información sobre todos losdescriptores de elementos de todos los esquemas del catálogo. Se puedendefinir restricciones de integridad entre relaciones, como la integridad
referencial, sólo si dichas relaciones existen en esquemas dentro del mismocatálogo. Además, los esquemas del mismo catálogo pueden compartirciertos elementos, como las definiciones de dominio.
Tipos de Autorización para la modificación del esquema de datos:
• Autorización de índicesPermite creación y borrado de índices
• Autorización de recursos
Permite la creación de relaciones nuevas
• Autorización de alternaciónPermite el añadido o el borrado de atributos de las relaciones
• Autorización de eliminación
Permite el borrado de relaciones
6.2 INSTRUCCIONES GRANT Y REVOKE
Los comandos GRANT y REVOKE permiten a los administradores de sistemascrear cuentas de usuario MySQL y darles permisos y quitarlos de lascuentas.
La información de cuenta de MySQL se almacena en las tablas de la base dedatos mysql . Esta base de datos y el sistema de control de acceso sediscuten extensivamente en que puede consultar para más detalles.
Si las tablas de permisos tienen registros de permisos que contienennombres de tablas o bases de datos con mayúsculas y minúsculas y lavariable de sistema lower_case_table_names está activa, REVOKE no puedeusarse para quitar los permisos. Es necesario manipular las tablas depermisos directamente.
Grant permite al creador de un objeto el dar permisos específicos a todoslos usuarios (public) o a un cierto usuario o grupo. Usuarios distintos al

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 38/42
38
creador pueden no tener permisos de acceso a menos que el creador se losconceda, una vez que el objeto ha sido creado. Una vez que un usuariotiene privilegios sobre un objeto, tiene posibilidad de ejecutar ese privilegio.No hay necesidad de conceder privilegios al creador de un objeto; el creadorobtiene automáticamente todos los privilegios, y puede también eliminar elobjeto. Privilege los posibles privilegios son: select acceso a todas las
columnas de una tabla/vista específica. Insert inserta datos en todas lascolumnas de una tabla específica. Update actualiza todas las columnas deuna tabla específica. Delete elimina filas de una tabla específica.
• RULEDefine las reglas de la tabla(vista (cer sentencia CREATE RULE).
• ALLOtorga todos los privilegios-
• objectEl nombre de un objeto al que se quiere conceder el acceso. Los posiblesobjetos son: tabla vista secuencia indice
• PUBLICUna abreviación para representar a todos los usuarios.
• GROUP groupUn grupo al que se otorgan privilegios. En la actual versión, el grupo debehaber sido creado explícitamente como se describe más adelante.
• usernameEl nombre de un usuario al que se quiere conceder privilegios. PUBLIC esuna abreviatura para representar a todos los usuarios.
• CHANGEMensaje devuelto se la acción se ha realizado satisfactoriamente.
• ERROR: Change Acl: class “object” not foundMensaje devuelto si el objeto especificado no está disponible o si es
imposible dar los provilegios a grupo o usuarios especificado.
UNIDAD 7INTRODUCCIÓN AL SQL PROCEDURAL
El SQL PL es, en realidad, un subconjunto del SQL que proporcionaconstrucciones de procedimiento que se pueden utilizar para implementar lalógica alrededor de las sentencias de SQL tradicionales. El SQL PL es unlenguaje de programación de alto nivel con una sintaxis sencilla ysentencias habituales de control de programación, que incluyen lassentencias IF, ELSE, WHILE, FOR, ITERATE y GOTO, así como otrassentencias.
Procedimientos de SQL PL y de SQL.
Los procedimientos de SQL PL pueden contener parámetros, variables,sentencias de asignación, sentencias de control de SQL PL y sentencias deSQL compuestas. Los procedimientos de SQL PL también dan soporte a un

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 39/42
39
potente mecanismo de manejo de errores y condiciones, a las llamadasanidadas y repetitivas y a la devolución de varios conjuntos de resultados alllamante o a la aplicación cliente. Para conocer el conjunto completo deelementos del lenguaje soportado en los procedimientos de SQL PL, vea lasentencia CREATE PROCEDURE (SQL) en la Consulta de SQL.
Funciones, activador y sentencias dinámicas compuestas de SQL PL en líneay de SQLA partir de DB2 Versión 7.2, está soportado un subconjunto de SQL PL en loscuerpos de los activadores y las funciones de SQL. Este subconjunto de SQLPL se conoce como SQL PL en línea. La palabra en línea hace resaltar unadiferencia importante entre el SQL PL en línea y el lenguaje SQL PLcompleto. Mientras que un procedimiento de SQL PL se implementacompilando estáticamente sus consultas de SQL individuales en seccionesde un paquete, una función de SQL PL en línea se implementa, como sunombre sugiere, colocando en línea el cuerpo de la función en la consultaque la utiliza. De esta diferencia, surgen algunas consideraciones relativasal rendimiento y se deben tener en cuenta cuando planifique si ha deimplementar la lógica de procedimiento en SQL PL en un procedimiento outilizar el SQL PL en línea.
Una sentencia dinámica compuesta es una sentencia que, en realidad, lepermite agrupar varias sentencias de SQL en un bloque lógico atómicopequeño, en el cual puede declarar variables y elementos para el manejo decondiciones. DB2 compila estas sentencias como una sola sentencia de SQL,y pueden contener elementos de SQL PL. Dentro de una sentencia dinámicacompuesta, es posible incluir el subconjunto de SQL PL conocido como SQLPL en línea y tan sólo un pequeño conjunto de sentencias de SQL básicas.Las sentencias dinámicas compuestas son útiles para crear scripts reducidos
que realicen pequeñas unidades de trabajo lógico con un mínimo flujo decontrol, pero con un flujo de datos significativo. Si le interesa una lógica máscompleja que requiera parámetros, pase de conjuntos de resultados u otroselementos de procedimiento más avanzados, pueden convenirle más losprocedimientos y las funciones de SQL.
7.1 PROCEDIMIENTOS ALMACENADOS
Un procedimiento almacenado (stored procedure en inglés) es un programa(o procedimiento) el cual es almacenado físicamente en una base de datos.Su implementación varía de un manejador de bases de datos a otro. Laventaja de un procedimiento almacenado es que al ser ejecutado, enrespuesta a una petición de usuario, es ejecutado directamente en el motorde bases de datos, el cual usualmente corre en un servidor separado. Comotal, posee acceso directo a los datos que necesita manipular y sólo necesita
enviar sus resultados de regreso al usuario, deshaciéndose de la sobrecargaresultante de comunicar grandes cantidades de datos salientes y entrantes.

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 40/42
40
Usos típicos para procedimientos almacenados incluyen la validación dedatos siendo integrados a la estructura de base de datos (losprocedimientos almacenados utilizados para este propósito a menudo sonllamados disparadores; triggers en inglés), o encapsular un proceso grandey complejo. El último ejemplo generalmente ejecutará más rápido como unprocedimiento almacenado que de haber sido implementado como, por
ejemplo, un programa corriendo en el sistema cliente y comunicándose conla base de datos mediante el envío de consultas SQL y recibiendo susresultados.Los procedimientos pueden ser ventajosos: Cuando una base de datos esmanipulada desde muchos programas externos. Al incluir la lógica de laaplicación en la base de datos utilizando procedimientos almacenados, lanecesidad de embeber la misma lógica en todos los programas que accedena los datos es reducida. Esto puede simplificar la creación y,particularmente, el mantenimiento de los programas involucrados.Podemos ver un claro ejemplo de estos procedimientos cuando requerimosrealizar una misma operación en un servidor dentro de algunas o todas lasbases de datos y a la vez dentro de todas o algunas de las tablas de lasbases de datos del mismo. Para ello podemos utilizar a los Procedimientosalmacenados auto creable que es una forma de generar ciclos redundantesa través de los procedimientos almacenados.
Estos procedimientos, se usan a menudo, pero no siempre, para realizarconsultas SQL sobre los objetos del banco de datos de una maneraabstracta, desde el punto de vista del cliente de la aplicación. Unprocedimiento almacenado permite agrupar en forma exclusiva parte dealgo específico que se desee realizar o, mejor dicho, el SQL apropiado paradicha acción.
Los usos 'típicos' de los procedimientos almacenados se aplican en lavalidación de datos, integrados dentro de la estructura del banco de datos.Los procedimientos almacenados usados con tal propósito se llamancomúnmente disparadores, o triggers. Otro uso común es la 'encapsulación'de un API para un proceso complejo o grande que podría requerir la'ejecución' de varias consultas SQL, tales como la manipulación de un'dataset' enorme para producir un resultado resumido.
También pueden ser usados para el control de gestión de operaciones, yejecutar procedimientos almacenados dentro de una transacción de talmanera que las transacciones sean efectivamente transparentes para ellos.
La ventaja de un procedimiento almacenado, en respuesta a una petición deusuario, está directamente bajo el control del motor del manejador de basesde datos, lo cual corre generalmente en un servidor separado de manejadorde bases de datos aumentando con ello, la rapidez de procesamiento derequerimientos del manejador de bases de datos. El servidor de la base dedatos tiene acceso directo a los datos necesarios para manipular y sólonecesita enviar el resultado final al usuario. Los procedimientosalmacenados pueden permitir que la lógica del negocio se encuentre comoun API en la base de datos, que pueden simplificar la gestión de datos yreducir la necesidad de codificar la lógica en el resto de los programascliente. Esto puede reducir la probabilidad de que los datos seancorrompidos por el uso de programas clientes defectuosos o erróneos. De
este modo, el motor de base de datos puede asegurar la integridad de losdatos y la consistencia, con la ayuda de procedimientos almacenados.

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 41/42
41
Algunos afirman que las bases de datos deben ser utilizadas para elalmacenamiento de datos solamente, y que la lógica de negocio sólodebería ser aplicada en la capa de negocio de código, a través deaplicaciones cliente que deban acceder a los datos. Sin embargo, el uso deprocedimientos almacenados no se opone a la utilización de una capa denegocio.
7.2 DISPARADORES (TRIGGERS)
Un trigger (o disparador) en una Base de datos, es un procedimiento que seejecuta cuando se cumple una condición establecida al realizar unaoperación de inserción (INSERT), actualización (UPDATE) o borrado(DELETE).
Son usados para mejorar la administración de la Base de datos, sinnecesidad de contar con que el usuario ejecute la sentencia de SQL.Además, pueden generar valores de columnas, previene errores de datos,
sincroniza tablas, modifica valores de una vista, etc.Permite implementar programas basados en paradigma lógico (sistemasexpertos, deducción).
Un trigger es un bloque PL/SQL asociado a una tabla, que se ejecuta cuandouna determinada instrucción en SQL se va a ejecutar sobre dicha tabla.
La sintaxis para crear un trigger es la siguiente:
CREATE [OR REPLACE] TRIGGER{BEFORE|AFTER} {DELETE|INSERT|UPDATE [OF col1, col2, . . ., colN][OR {DELETE|INSERT|UPDATE [OF col1, col2, . . ., colN]. . .]}ON table[REFERENCING OLD AS oldname, NEW as newname][FOR EACH ROW [WHEN (condition)]]pl/sql_block
El uso de OR REPLACE permite sobreescribir un trigger existente. Si seomite, y el trigger existe, se producirá, un error.
El modificador FOR EACH ROW indica que el trigger se disparará cada vezque se desee hacer operaciones sobre una fila de la tabla. Si se acompañadel modificador WHEN, se establece una restricción; el trigger solo actuará,
sobre las filas que satisfagan la restricción.
BIBLIOGRAFÍA
http://www.programatium.com/tutoriales/cursos/oracle/11.htm
http://tallerbd.hostoi.com/index.php?option=com_content&view=article&id=70&Itemid=91
http://sql.1keydata.com/es/sitemap.php
http://www.paginasprodigy.com.mx/evaristopacheco/taller

5/11/2018 32352648 Taller de Base de Datos - slidepdf.com
http://slidepdf.com/reader/full/32352648-taller-de-base-de-datos 42/42
42
http://es.wikipedia.org/wiki/











![Solucion Taller 01 de Base de Datos Relacional[1]](https://static.fdocuments.ec/doc/165x107/5571fc3c497959916996cf8a/solucion-taller-01-de-base-de-datos-relacional1.jpg)






