
3.1. DISEÑO DE REPERTORIO DE INSTRUCCIONES. · 6.1 Introducción a la segmentación de...
35
Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011 Vicente Arnau Llombart 26/11/2010 SEGMENTACIÓN 6.1 Introducción a la segmentación de Instrucciones. La segmentación o pipeline es una técnica de realización de procesadores por la cual se solapa la ejecución de las instrucciones. Hoy en día es la técnica clave para la realización de CPU rápidas. La idea básica de la segmentación se puede extraer de una cadena de montaje de coches . Los coches no se montan uno a uno, si no que su construcción se divide en fases sucesivas y el montaje del coche se realiza tal como este va avanzando por estas fases. De esta forma cada fase está trabajando simultáneamente en la construcción de un coche diferente. De esta forma, la construcción de un coche cuesta el mismo tiempo que antes, pero ahora la frecuencia con que salen los coches construidos es mucho mayor (tantos como fases tenga su construcción). Cada uno de estas fases se denomina segmento o etapa de segmentación. Al igual que en los coches, la productividad de un computador va a depender del número de instrucciones que acaben por unidad de tiempo, y no de lo que le cueste a una instrucción individual. 6.2 Segmentación para DLX. Si queremos aplicar la técnica de la segmentación a la ejecución de instrucciones, deberemos dividir la ejecución de las mismas en una serie de etapas. Por ejemplo, en DLX la ejecución de una instrucción se divide en 5 etapas: IF: Lectura de instrucción. ID: Decodificación de Instrucción y lectura de registros. EXE: Ejecución de la instrucción. MEM: Acceso a memoria de datos. REG: Acceso a banco de registros. La realización de cada etapa de segmentación es un ciclo máquina. Esta duración está determinada por la duración de la etapa más lenta. Con frecuencia el ciclo máquina es un ciclo de reloj (a veces dos), aunque el reloj puede tener múltiples fases. El objetivo del diseñador de computadores es equilibrar correctamente el diseño de cada segmento para que todos tengan la misma duración. Si esto es así, entonces la duración de una instrucción será (si no hay atascos): Tiempo por instrucción en máquina no segmentada Número de etapas de la segmentación De forma ideal, el avance en rapidez del procesador por la segmentación se ve multiplicado por el número de etapas que dispongamos. Pero en la realidad no es exactamente así, las etapas no suelen estar perfectamente equilibradas y siempre surgen atascos en la ejecución de las instrucciones que hacen que no siempre se superponga su ejecución perfectamente (se suele obtener un 10% menos de rapidez de la prevista en el caso ideal). La segmentación es una técnica no visible al programador, que consigue una reducción en el tiempo de ejecución medio por instrucción. Esta técnica que explota el paralelismo entre instrucciones secuenciales.
Transcript of 3.1. DISEÑO DE REPERTORIO DE INSTRUCCIONES. · 6.1 Introducción a la segmentación de...

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
SEGMENTACIÓN
6.1 Introducción a la segmentación de Instrucciones.
La segmentación o pipeline es una técnica de realización de procesadores por la cual se solapa la
ejecución de las instrucciones. Hoy en día es la técnica clave para la realización de CPU rápidas.
La idea básica de la segmentación se puede extraer de una cadena de montaje de coches. Los
coches no se montan uno a uno, si no que su construcción se divide en fases sucesivas y el montaje
del coche se realiza tal como este va avanzando por estas fases. De esta forma cada fase está
trabajando simultáneamente en la construcción de un coche diferente. De esta forma, la construcción
de un coche cuesta el mismo tiempo que antes, pero ahora la frecuencia con que salen los coches
construidos es mucho mayor (tantos como fases tenga su construcción).
Cada uno de estas fases se denomina segmento o etapa de segmentación. Al igual que en los
coches, la productividad de un computador va a depender del número de instrucciones que acaben
por unidad de tiempo, y no de lo que le cueste a una instrucción individual.
6.2 Segmentación para DLX.
Si queremos aplicar la técnica de la segmentación a la ejecución de instrucciones, deberemos
dividir la ejecución de las mismas en una serie de etapas. Por ejemplo, en DLX la ejecución de una
instrucción se divide en 5 etapas:
IF: Lectura de instrucción.
ID: Decodificación de Instrucción y lectura de registros.
EXE: Ejecución de la instrucción.
MEM: Acceso a memoria de datos.
REG: Acceso a banco de registros.
La realización de cada etapa de segmentación es un ciclo máquina. Esta duración está
determinada por la duración de la etapa más lenta. Con frecuencia el ciclo máquina es un ciclo de
reloj (a veces dos), aunque el reloj puede tener múltiples fases.
El objetivo del diseñador de computadores es equilibrar correctamente el diseño de cada
segmento para que todos tengan la misma duración. Si esto es así, entonces la duración de una
instrucción será (si no hay atascos):
Tiempo por instrucción en máquina no segmentada
Número de etapas de la segmentación
De forma ideal, el avance en rapidez del procesador por la segmentación se ve multiplicado
por el número de etapas que dispongamos. Pero en la realidad no es exactamente así, las etapas no
suelen estar perfectamente equilibradas y siempre surgen atascos en la ejecución de las instrucciones
que hacen que no siempre se superponga su ejecución perfectamente (se suele obtener un 10% menos
de rapidez de la prevista en el caso ideal).
La segmentación es una técnica no visible al programador, que consigue una reducción en
el tiempo de ejecución medio por instrucción. Esta técnica que explota el paralelismo entre
instrucciones secuenciales.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
La segmentación es una técnica de diseño de procesadores que se viene empleando desde la tercera
generación de computadores. En la figura siguiente podemos ver como se han diseñado los
procesadores en cada generación.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
En las dos figuras siguientes se puede observar cómo funciona la segmentación cuando se ejecutan
varias instrucciones sobre un procesador segmentado. La figura 1 es en el caso ideal, y la figura 2 en
el caso real.
Figura 1. Segmentación caso ideal.
Figura 2. Segmentación caso real. Se introducen numerosos retardos en la ejecución
de las instrucciones.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Ejemplo 1: Sea un procesador segmentado en 5 etapas con una duración de (50, 50, 60, 50, 50) nseg
de duración para cada una de las etapas. Es decir, cuando ejecuta una instrucción de forma no
segmentada, tarda 260 nseg en ejecutarla.
Si este mismo procesador lo diseñamos de forma segmentada, deberemos añadir 5 nseg. a cada etapa
debido al retardo de los biestables que almacenan la información entre etapas.
Ver el esquema siguiente:
La pregunta es, cuando ejecutamos N=10 instrucciones, ¿qué aceleración y que eficiencia se
consiguen?
86.2910
2600
))110(5(*65
10*260
))1((*
*
nk
n
T
TnAceleració
seg
ins
Segmentado
doNoSegmenta
71.014
10
))110(5(
10
))1(( nk
nEficiencia
465
260
))1((*
*limlim
seg
ins
seg
insnn
nk
nnAceleraciónMaximaAceleració
Realizar los cálculos de la Aceleración y la Eficiencia para cuando procesamos N = 4 y N = 32
instrucciones. (Importante: Usar siempre las formulas de este ejemplo).

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Ejemplo 2: En esta figura 6.3 del Tomo 2 de “Estructura y diseño de Computadores” (Ed. Reverté)
Se puede observar cómo se realiza la ejecución de una instrucción de DLX de forma no segmentada.
Se observa como al ejecutarse de forma segmentada, se necesita definir un único tiempo de
segmento, por lo cual elegimos el segmento de mayor duración.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Antes de pasar a ver como definimos con detalle las operaciones a realizar en cada uno de los
segmentos de ejecución segmentada de DLX, debemos recordar cuales son los tres formatos de
instrucciones de que dispone.
También necesitamos recordar la estructura del procesador DLX con ejecución monociclo, pues en
esta estructura nos basaremos para definir el procesador segmentado.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Ahora, ya estamos preparados para empezar a diseñar nuestro procesador Segmentado.
Lo primero que haremos será colocar los registros intermedios que nos permitirán almacenar datos y
señales de control de cada una de las instrucciones que entran en el cauce segmentado.
En la figura siguiente se muestra el esquema inicial del procesador DLX segmentado (ya lo
complicaremos después).

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Definición de Segmentación para DLX. Vamos a partir de un repertorio de instrucciones conocido como es el DLX, pero sin operaciones en
coma flotante. La ejecución de todas sus instrucciones puede descomponerse en 5 pasos básicos,
cada uno de los cuales tiene un duración de 1 o más ciclos de reloj. Veamos por partes cada paso:
1. IF-Paso de búsquea de instrucción: Se pasa el valor del Contador de Programa (PC) al Registro
de Acceso a Memoria (MAR). Se lee de memoria la siguiente instrucción y se carga en el RI.
MAR PC ; IR Mem[MAR
2. ID-Paso de búsqueda del registro/decodificación de instrucción. Se decodifica la instrucción
leída y se accede a los registros indicados. Se incrementa el PC para que apunte a la siguiente
instrucción.
A Rsl ; B Rs2; PC PC+4
Como la posición de los registros fuente para DLX siempre es la misma, entonces estos
valores pueden ser leídos a la vez que decodificamos la instrucción en curso.
3. EX-Paso de dirección efectiva /ejecución. La ALU podrá operar con los operandos del paso
anterior para realizar una de estas tres funciones.
i) Referencia a memoria: La ALU suma los operandos para formar la dirección efectiva y se
carga en el MDR.
MAR A+(IR16)16
##IR16..31; MDR Rd
ii) Instrucción ALU: La ALU realiza la instrucción especificada por el código de operación
sobre los registros Rs1 y Rs2 o Rs1 y un valor inmediato.
ALU-salida (A op B) ó (A op ((IR16)16
##IR16..31))
iii) Salto/bifurcación: La ALU suma el PC al valor inmediato de signo extendido (de 16 bits
para saltos y 26 para bifurcaciones) y así calcula la dirección de salto.
ALU-salida PC + ((IR16)16
##IR16..31)) ; cond (A op 0)
Para saltos condicionales se examina un registro que ha sido leído en un paso anterior para saber si la
dirección calculada se coloca en el PC.
La arquitectura de carga/almacenamiento de DLX supone que el cálculo de una dirección efectiva y
la ejecución de una instrucción en la ALU se pueden superponer, pues ninguna instrucción aritmética
necesita calcular una dirección para acceder a un operando.
4. MEM-Paso de completar salto/acceso a memoria: las únicas instrucciones DLX activas en este
paso son las de acceso a memoria y los saltos.
i) Referencia a memoria: Accede a memoria para leer o escribir un dato.
MDR Mem[MAR ó Mem[MAR MDR
ii) Salto: El valor de PC es sustituido por la dirección de salto.
if (cond) : PC ALU-salida
5. WB-Paso de postescritura (write-back): Escribe resultado en registro, tanto si proviene de
memoria como de la ALU.
Rd ALU-salida ó MDR

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Como resultado de poder subdividir cada instrucción en 5 segmentos (todos de 1 ciclo de
reloj), podemos leer una instrucción en cada ciclo de reloj. Y así, aunque la ejecución de cada
instrucción requiera 5 ciclos de reloj, el resultado es que cada ciclo de reloj (si no pasa nada) finaliza
una instrucción diferente. Recordar lo visto en la figura 1:
El resultado más evidente es que la segmentación aumenta el número de instrucciones emitidas y
finalizadas sobre una CPU por unidad de tiempo, pero sin reducir (antes al revés) la duración de
ejecución de una instrucción. Por ello, cara al programador, sus programas se ejecutan más rápidos.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Diseño de la Unidad Segmentada. Camino de datos. Muestra, como ya sabemos de cursos anteriores, como funciona el procesador de
DLX cuando está ejecutando una instrucción por ciclo (es decir, es un repaso de materia ya vista en
primero, en EC I). Es un ejemplo de cómo se propagan los datos a través del procesador.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Ejercicio: Aunque es un repaso de lo visto en cursos anteriores, completar el siguiente esquema.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Control para la segmentación.
La ejecución de instrucciones en un procesador segmentado requiere que en cada uno de los
segmentos seamos capaces de almacenar toda la información de la instrucción que se está ejecutando
en ese segmento.
Por ejemplo, si ejecutamos una instrucción de salto, en el primer segmento leeremos el código de la
instrucción e incrementaremos el PC almacenándolo en un registro NPC. Este valor puede que lo
necesitemos en el ciclo de EXE, y si no se va trasladando de segmento a segmento, ocurrirá que al
siguiente ciclo de reloj, al leer una nueva instrucción, borraremos este valor y ya no podrá ser
utilizado después.
Por este y otros motivos similares, en los registros intermedios del procesador segmentado para
DLX, se almacena toda la información necesaria de la instrucción que se está ejecutando en ese
segmento, y cuando pasamos al segmento siguiente, esta información si se va a utilizar en algún
segmento posterior, se traslada también copiándose en los registros que hay entre segmentos.
En la figura 6.19 observamos la forma que ha de tener el procesador segmentado para que la
segmentación funciones correctamente.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Observar:
Propagación del valor del NPC.
Propagación del código del registro destino hasta último segmento.
Propagación de resultado de la ALU: ALUOutput.
Como se actualiza el valor del contador de programa, usando una puerta AND.
Líneas de entrada del Banco de Registros.
Líneas de entrada de Memoria de Datos.
Una ALU para datos y otra para direcciones de saltos.
Ahora todo junto. Se muestra tanto el camino de datos como el camino de control para la realización
segmentada de instrucciones de DLX. (figura 6.30). Esta transparencia debe ser analizada con
detalle.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
6.3 Los riesgos de la segmentación.
Todo lo visto hasta ahora está muy bien, pero no siempre se pueden superponer la ejecución de las
instrucciones como se ha visto en los ejemplos anteriores. Hay situaciones llamadas riesgos
(“hazards”) que lo impiden, y que se pueden clasificar en tres clases:
Riesgos estructurales. Producidos por conflictos en la utilización del hardware. Impiden que
dos instrucciones se solapen en determinados segmentos.
Riesgos por dependencias de datos. Es cuando los datos que necesita una instrucción para
ejecutarse son inicializados por instrucciones anteriores que aun no han finalizado.
Riesgos de control. Suceden cuando hay un cambio brusco en el valor del PC producido por
una salto u otras instrucciones.
Cuando se detecta un riesgo, puede ser necesario detener la segmentación (no siempre). Pero
detener el procesador en una máquina no segmentada es fácil, basta terminar la instrucción en curso.
En una máquina segmentada hay varias instrucciones en curso, y por ello un detención supone, en la
mayoría de los casos, que algunas de las instrucciones en curso deben ejecutarse hasta finalizar, otras
se retardan y otras si pueden detenerse en un instante dado.
Por lo general, cuando una instrucción se detiene, las instrucciones anteriores finalizan
normalmente y las posteriores sufren un retardo en su ejecución. Durante el tiempo de retardo, no se
leen más instrucciones.
Vamos a pasar a estudiar en este apartado 1.5. los tres tipo de riesgos: estructurales, de dependencia
de datos y los de Control, aunque en el temario estos últimos riesgos figuren como un apartado
nuevo (el 1.6.).
Riesgos estructurales.
En una máquina segmentada deben de poderse solapar cualquier combinación de instrucciones. Si no
es así, se dice que la máquina posee riesgos estructurales. Una máquina sin riesgos estructurales
siempre tendrá un CPI más alto que si no los tuviera.
Para evitar estos riesgos en muchos casos tenemos que duplicar recursos. Por ejemplo, si
tenemos un único puerto de acceso a memoria, si una instrucción en un determinado segmento debe
acceder a memoria para leer o escribir, en ese segmento no se podrá leer ninguna instrucción, por lo
cual el inicio de una nueva instrucción se tendrá que retrasar un ciclo de reloj. En la figura siguiente
se ilustra este caso, aunque se ve mejor en la transparencia de la hoja siguiente (Fig. 3.6 y 3.7).
Ciclos de Reloj
Instrucción 1 2 3 4 5 6 7 8 9
Carga IF ID EX MEM WB
Instrucción i+1 IF ID EX MEM WB
Instrucción i+2 IF ID EX MEM WB
Instrucción i+3 detención IF ID EX MEM WB
Instrucción i+4 IF ID EX MEM
Sin embargo hay máquinas que se diseñan con riegos estructurales, el motivo es sencillo:
Para reducir el coste en la producción. Está claro que si un determinado riesgo estructural no se
presenta muy a menudo, puede que no valga la pena evitarlo, y simplemente introducimos un retardo
en el funcionamiento.
En este caso, el riesgo es tan notorio por el elevado número de veces que ocurre que vale la pena
realizar el procesador con dos puertos de acceso, uno para lectura de datos y otro para lectura de
instrucciones.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
También hay que destacar que aparecen dos tipos de riesgos más:
El riesgo estructural que se introduce al acceder al banco de registros.
El riesgo estructural que se produce cuando tenemos instrucciones cuya ejecución dura más
de un ciclo de reloj.
El primero en los riesgos se soluciona realizando un banco de registros de forma que el acceso de
escritura y de lectura se realicen en un mismo ciclo de reloj, pero en flancos distintos. Además, es
mejor que primero sea la escritura y luego la lectura, pues evitaremos un posible riesgo por
dependencia de datos.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
El segundo riesgo lo analizaremos con más detalle cuando introduzcamos las instrucciones
multiciclo. Pero ahora vamos a realizar un pequeño estudio, considerando lo que ocurriría si todas las
instrucciones tuviesen un ciclo de reloj en ejecución salvo las instrucciones de multiplicación y
división que tienen 2 ciclos.
Aquí se plantean varias alternativas que habrá que analizar:
Duplicar la unidad de ejecución de la Mult/Div (Ex-M), o segmentarla.
Separar (si se puede) las dos instrucciones de multiplicar. (Ins-Mult-Ins-Mult). A esto se le
llama planificar el código.
Se pide analizar estas dos opciones y decidir cuál es la más conveniente.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Caso 1: Segmentación Inicial.
Caso 2: Duplicamos unidad aritmética de Mult/Div. Tenemos una burbuja o ciclo de espera en la
ejecución de estas 4 instrucciones.
Caso 3: No duplicamos unidad aritmética pero Si planificamos Código. Seguimos teniendo una
burbuja o ciclo de espera en la ejecución de estas 4 instrucciones.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Riesgos por dependencia de datos.
Los riesgos por dependencia de datos surgen cuando una instrucción escribe un resultado en un
determinado registro (durante el último segmento) y alguna de las instrucciones siguientes hace uso
del valor de este registro antes de que se produzca dicha escritura.
Se ve mucho mejor con el ejemplo; sea las siguientes dos instrucciones:
ADD R1, R2, R3
SUB R4, R1, R5
La instrucción SUB tiene como registro fuente R1, y la instrucción anterior ADD guarda el
resultado de una suma en este mismo registro. Si ejecutásemos de forma segmentada estas dos
instrucciones tendríamos:
Ciclos de Reloj
Instrucción 1 2 3 4 5 6
ADD IF ID EX MEM WB_en_R1
SUB IF ID_leo_R1 EX MEM WB
Si no introdujéramos un retardo entre estas dos instrucciones, la instrucción SUB manejaría
un valor de R1 no correcto. Esto es inaceptable en un procesador.
Ciclos de Reloj
Instrucción 1 2 3 4 5 6 7 8 9
ADD IF ID EX MEM WB_R1
nop - - - - -
nop - - - - -
SUB IF ID_R1 EX MEM WB
El problema planteado aquí se resuelve con una sencilla técnica llamada según autores de la
siguiente forma:
Adelantamiento, “forwarding”, desvío, “bypassing” o cortocircuito.
El funcionamiento hardware de esta técnica es sencillo: las distintas unidades funcionales se
adelantan los datos entre ellas sin necesidad que estos datos estén escritos en el Banco de Registros,
para de aquí se leídos.
En las transparencias de la página siguiente (FIGURE 3.9 y FIGURE 3.10) se muestra el
funcionamiento de esta técnica de formalmente.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Con ello se consigue que si una instrucción utiliza un registro como fuente y la instrucción
anterior lo tiene como destino de una operación, entonces la segunda instrucción utilizará como valor
del registro fuente la salida de la ALU. Así, aunque el valor no se grabe en el registro conflictivo
hasta 2 ciclos después, la segunda instrucción ya habrá hecho uso de su valor.
Como hemos visto, en la segmentación de DLX, no solo la instrucción siguiente puede
necesitar un valor de un registro todavía no actualizado, también las tres siguientes instrucciones
pueden necesitar este valor, que hasta el final del cuarto segmento (el de WB) no estará
correctamente almacenado.
En la figura 3.10 anterior se muestra un ejemplo de cómo una instrucción utiliza como
registro destino R1 y las siguientes 4 instrucciones lo tienen como registro fuente. El resultado
deberá ser adelantado para las dos siguientes instrucciones. (Figura 6.7).
La primera instrucción ADD inicializa el valor del registro R1.
Las cuatro instrucciones restantes lo utilizan.
El valor de R1 se desvía para ser utilizado por las dos restantes: SUB, AND y OR.
La instrucción OR y la XOR cuando necesitan R1, la instrucción ADD ya a realizado la escritura en
el banco de Registros.
Recordar: tener en cuenta que el segmento ID accede a dos registros del banco de registros, y
a su vez, al solaparse con el segmento WB este debe realizar una escritura sobre otro registro. Esto es
complicado y se resuelve haciendo que las escrituras se realicen durante la primera mitad del ciclo de
reloj y las lecturas durante la segunda mitad.
En la página siguiente se muestra como se realizarían los adelantamientos de datos para estas dos
secuencias de instrucciones:
FIGURE 3.11: adelantamiento de ALU a
memoria y de memoria a memoria.
FIGURE 3.12: adelantamiento de memoria a
unidad aritmética: ¿!!?.
ADD R1, R2, R3
LW R4, 0(R1)
SW 12(R1), R4
LW R1, 0(R2)
SUB R4, R1, R5
AND R6, R1, R7
OR R8, R1, R9
El primer ejemplo de adelantamiento se realiza sin problemas, pero no ocurre lo mismo en el
adelantamiento de memoria a ALU:
Este es el único caso en que el procesador de DLX necesitará introducir un retraso (o burbuja) para
conseguir que el programa se ejecute correctamente. (Esto mismo lo veremos también más adelante
en los apuntes).

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
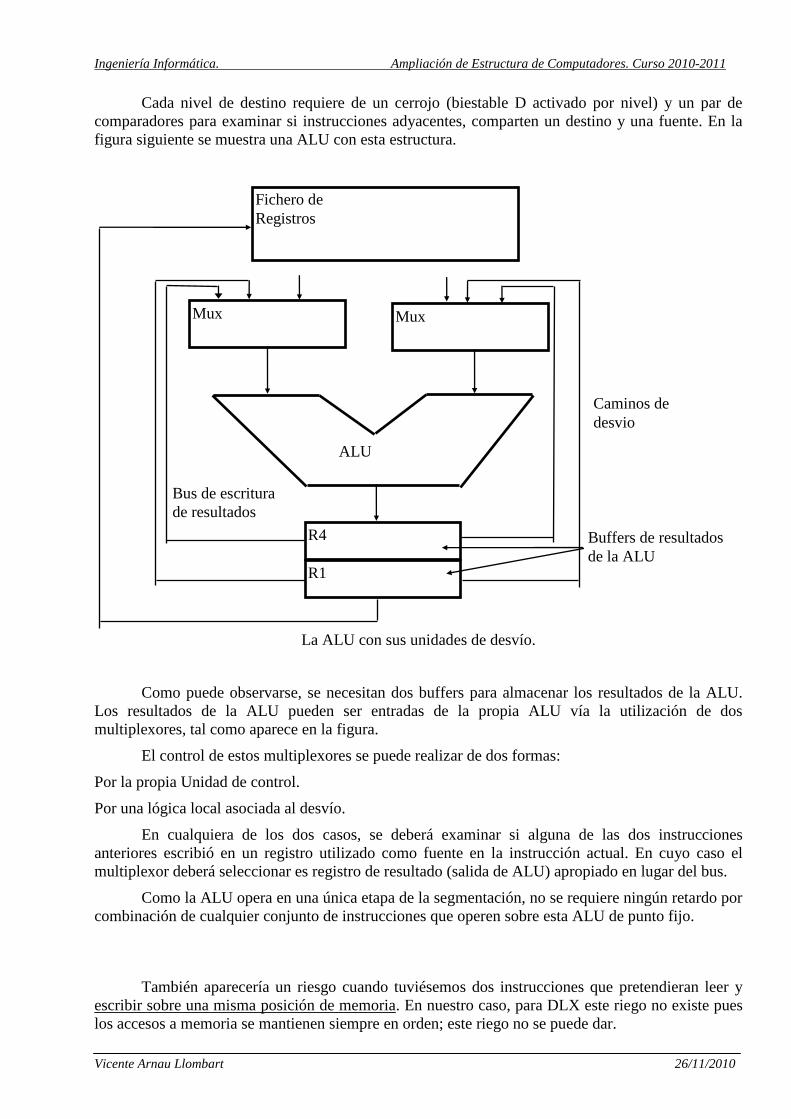
Bus de escritura
de resultados
Cada nivel de destino requiere de un cerrojo (biestable D activado por nivel) y un par de
comparadores para examinar si instrucciones adyacentes, comparten un destino y una fuente. En la
figura siguiente se muestra una ALU con esta estructura.
La ALU con sus unidades de desvío.
Como puede observarse, se necesitan dos buffers para almacenar los resultados de la ALU.
Los resultados de la ALU pueden ser entradas de la propia ALU vía la utilización de dos
multiplexores, tal como aparece en la figura.
El control de estos multiplexores se puede realizar de dos formas:
Por la propia Unidad de control.
Por una lógica local asociada al desvío.
En cualquiera de los dos casos, se deberá examinar si alguna de las dos instrucciones
anteriores escribió en un registro utilizado como fuente en la instrucción actual. En cuyo caso el
multiplexor deberá seleccionar es registro de resultado (salida de ALU) apropiado en lugar del bus.
Como la ALU opera en una única etapa de la segmentación, no se requiere ningún retardo por
combinación de cualquier conjunto de instrucciones que operen sobre esta ALU de punto fijo.
También aparecería un riesgo cuando tuviésemos dos instrucciones que pretendieran leer y
escribir sobre una misma posición de memoria. En nuestro caso, para DLX este riego no existe pues
los accesos a memoria se mantienen siempre en orden; este riego no se puede dar.
Fichero de
Registros
Mux Mux
ALU
R4
R1
Caminos de
desvio
Buffers de resultados
de la ALU

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Los fallos de acceso a cache podrían también desordenar las referencias a memoria si se
permitiera que el procesador siguiese trabajando con instrucciones posteriores. Pero en DLX, cuando
esto ocurre, detenemos la segmentación por completo, haciendo que la ejecución de la instrucción
que causo fallo se prolongue todos los ciclos de reloj que haga falta.
En ocasiones puede ser necesario adelantar el resultado de una unidad funcional a otra unidad
funcional. Por ejemplo, analicemos las siguientes instrucciones:
ADD R1, R2, R3
SW 25(R1), R1
El resultado de la suma almacenado en R1, cuando está a la salida de la ALU ya se puede
utilizar para el cálculo de la siguiente instrucción, y a su vez este valor será adelantado al MDR
(Registro de Datos de Memoria) para que sea almacenado en una dirección de memoria el contenido
del registro R1.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Clasificación:
Pero en cualquier procesador segmentado genérico, los riesgos por dependencia de datos se pueden
clasificar en tres tipos, atendiendo al orden de acceso de lectura y escritura de las instrucciones. Sean
dos instrucciones, primero i y luego j; entonces la clasificación podría ser esta:
RAW (Read After Write): una instrucción j intenta leer antes de que la instrucción i realice
la escritura. El resultado es que se lee un valor no correcto (ya hemos visto ejemplos antes).
WAR (Write After Read): una instrucción j escribe un valor antes de que la instrucción i lo
lea. Esto en DLX no ocurre, pues las lecturas se realizan antes en ID y las escrituras después
en WB. Ocurre cuando hay instrucciones que escriben anticipadamente el resultado, como
por ejemplo cuando se autoincrementa un registro en cálculo de una dirección.
WAW (Write After Write). Es cuando las dos instrucciones, tanto i como j, realizan una
escritura por ejemplo en un registro; pero la instrucción j lo realiza antes que la i por hacerlo
en segmentos anteriores. Ocurre en segmentaciones que escriben en más de una etapa.
Como es de imaginar, RAR no supone un riesgo.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Observar el detalle de cómo funciona la unidad de detección de riesgos: En el ciclo 3 de reloj se está
ejecutando la instrucción “SUB R2, R1, R3” que inicializa el registro R2. Cuando esta instrucción
pasa en el ciclo 4 al segmento MEM, entrará en EXE la instrucción “ADD R4, R2, R5” que
necesitará recibir de forma adelantada el contenido de R2, pues el valor leído en el banco de registros
no es el correcto.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Inevitables:
Pero no todos los riesgos son inevitables. Cuando leemos un dato de memoria y lo cargamos en un
registro, el registro no estará correctamente accesible hasta después del ciclo de acceso a memoria.
Analicemos por ejemplo la siguiente secuencia de código:
LW R1,32(R6)
ADD R4,R1,R7
SUB R5,R1,R8
AND R6,R1,R7
La primera instrucción LW no posee el dato hasta que finaliza el 4º segmento, en el cual
grabara en R1 el dato leído.
Y la instrucción siguiente ADD necesita leer R1 durante su 2º periodo (en ID), por lo tanto,
deberá introducirse 2 ciclos de espera en la ejecución segmentada de estas instrucciones.
Además SUB también requerirá un ciclo de espera pues no podrá leer en ID correctamente el
valor del registro R1. Para la instrucción AND ya no habrá problemas.
Ciclos de Reloj
Instrucción 1 2 3 4 5 6 7 8 9
LW R1,32(R6) IF ID EX MEM WB
ADD R4,R1,R7 IF ID EX MEM WB
SUB R5,R1,R8 IF ID EX MEM WB
AND R6,R1,R7 IF ID EX MEM WB
nop IF ID EX MEM WB
Pero podemos acortar el tiempo de detención si hacemos que la ALU lea directamente desde
el MDR. Es también un adelantamiento de los datos, con lo cual el multiplexor de entrada de la ALU
ya no tendrá 3 sino 4 entradas a seleccionar. Con ello ya solo será necesario, para este caso,
introducir un ciclo de espera, como muestra la figura siguiente.
Ciclos de Reloj
Instrucción 1 2 3 4 5 6 7 8 9 10
LW R1,32(R6) IF ID EX MEM WB
ADD R4,R1,R7 IF ID detención EX MEM WB
SUB R5,R1,R8 IF detención ID EX MEM WB
AND R6,R1,R7 detención IF ID EX MEM WB
nop IF ID EX MEM WB
Generalmente, cuando tenemos una instrucción del tipo A = B + C hay una probabilidad bastante
alta de que se produzca una detención debido a la carga del segundo dato. Sin embargo podemos

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
evitar con facilidad que se produzca un retraso en el almacenamiento del resultado, si adelantamos la
salida de la ALU al registro MDR.
Para comprender mejor lo expuesto, analicemos el código ensamblador que generaría la
anterior instrucción de alto nivel:
Ciclos de Reloj
Instrucción 1 2 3 4 5 6 7 8 9
LW R1,B IF ID EX MEM WB
LW R2,C IF ID EX MEM WB
ADD R3,R1,R2 IF ID detención EX MEM WB
SW A,R3 IF detención ID EX MEM WB
El valor del MDR es adelantado para ADD. Para SUB y para AND ya se lee bien del banco
de registros en el segmento ID de ambas instrucciones.
Lo que hemos tenido que realizar es una espera en la segmentación que se conoce como
burbuja (“bubble”) o detención de cauce (“pipeline stall”)
El proceso que permite que una instrucción se desplace desde la etapa de decodificación de la
instrucción (ID) a la de ejecución (EX) se le llama
emisión de la instrucción (“instruction issue”)
y la instrucción sobre la que se ha realizado este proceso se dice que ha sido emitida (“issued”).
Para la segmentación de enteros sobre DLX (sin punto flotante) todos los riesgos por
dependencias de datos pueden ser comprobados durante la fase ID. Con ello se consigue reducir la
complejidad del hardware, pues nunca una detención de una instrucción interferirá en el estado de la
máquina, ya que los parámetros característicos de la misma solo pueden ser modificados en los
últimos 3 segmentos.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
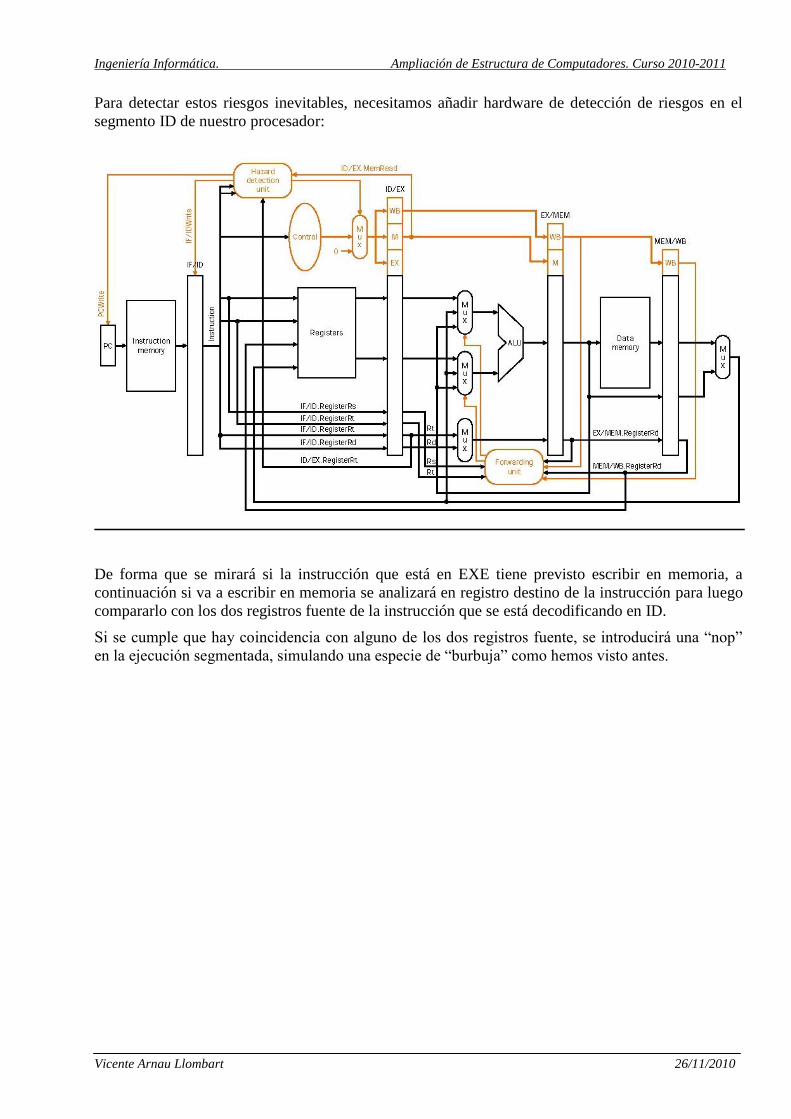
Para detectar estos riesgos inevitables, necesitamos añadir hardware de detección de riesgos en el
segmento ID de nuestro procesador:
De forma que se mirará si la instrucción que está en EXE tiene previsto escribir en memoria, a
continuación si va a escribir en memoria se analizará en registro destino de la instrucción para luego
compararlo con los dos registros fuente de la instrucción que se está decodificando en ID.
Si se cumple que hay coincidencia con alguno de los dos registros fuente, se introducirá una “nop”
en la ejecución segmentada, simulando una especie de “burbuja” como hemos visto antes.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Problema: Sea un procesador segmentado en el cual el 20% de las instrucciones son de carga.
Además, después de una instrucción de carga, en el 50% de los casos hay una instrucción que accede
al dato cargado. Ello determina que en la ejecución segmentada de las instrucciones será necesario
introducir un retardo de 1 ciclo de reloj.
Cuan más rápido (en este caso más lento) es el procesador real aquí presentado respecto a uno
ideal (sin retardos y con CPI = 1).
Solución: Para saber la rapidez deberemos hacer el cociente entre los CPI (Instrucciones Por Ciclo),
es decir:
Rapidez = CPIreal / CPIideal
El CPIideal es 1.
El CPIreal lo podemos saber de la siguiente forma:
1) El 20% de las instrucciones son de carga y de ellas el 50% produce retardo, es decir, el 10% de las
instrucciones produce retardo.
2) En plena segmentación, si de cada 10 instrucciones tengo un retardo, entonces estas 10
instrucciones tardarán 11 ciclos de reloj.
3) El CPIreal se calcula por cociente entre estas cantidades:
CPIreal = 11/10=1,1
4) Por lo tanto tenemos:
Rapidez = (CPIreal / CPIideal ) % = (1,1/1) = 11%
la máquina ideal es un 10% más rápida.

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Problema: Realizar un programa que realice la multiplicación de dos vectores de n datos y almacene
el resultado sobre un tercer vector de datos. Completar el código.
; VECTORES.S
;Datos a partir de esta dirección
.data 0x2000
n: .word 8, 0
datosX: .double 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, …
datosY: .double 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, …
datosZ: .space 64
.text 0x100
...
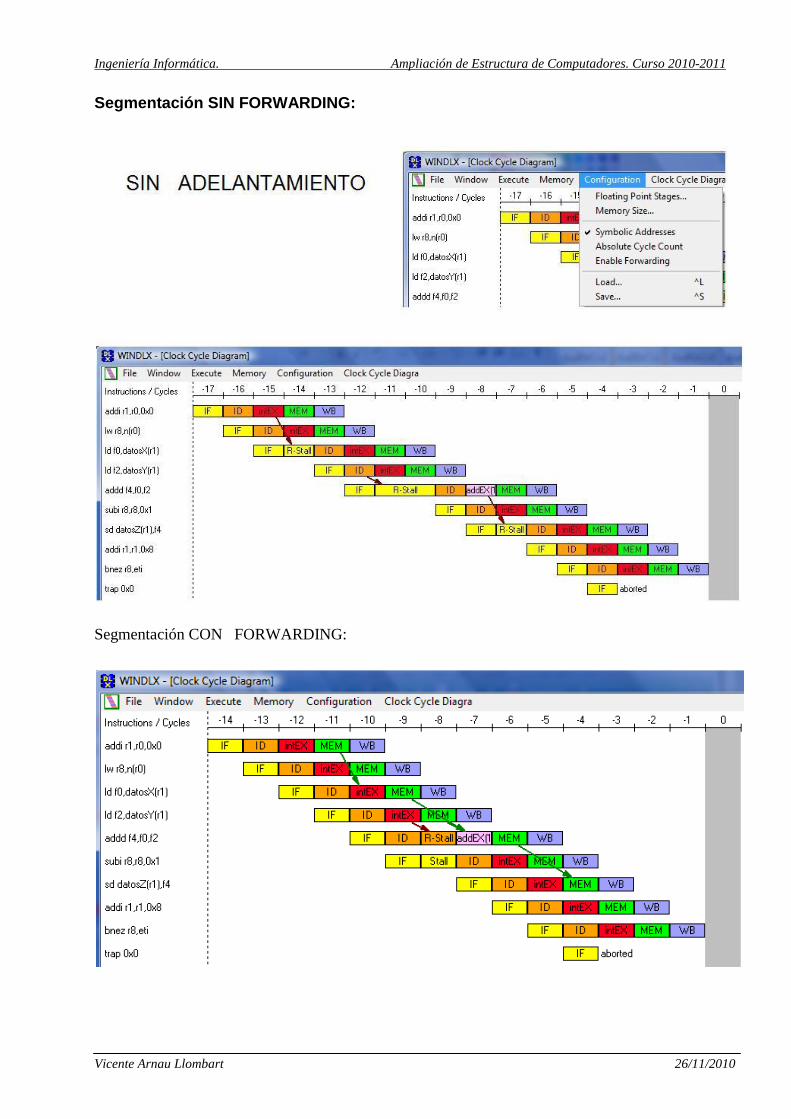
Una vez realizado el programa, mostrar su ejecución segmentada de dos formas:
1) Con la opción forwarding desactivada.
2) Con la opción forwarding activada.
Para este segundo caso describir como se realizan todos los adelantamiento (entre que unidades
funcionales del procesador).
Solución:
; VECTORES.S : Z(i) = X(i) * Y(i).
;Datos a partir de esta dirección
.data 0x2000
n: .word 8, 0
datosX: .double 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8
datosY: .double 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8
datosZ: .space 64
.text 0x100
addi R1, R0, 0
lw R8, n
eti: LD F0, datosX(R1)
LD F2, datosY(R1)
ADDD F4, F0, F2
SUBI R8, R8, 1
SD datosZ(R1), F4
ADDI R1, R1, 8
BNEZ R8, eti
trap 0
Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Segmentación SIN FORWARDING:
Segmentación CON FORWARDING:

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Planificamos el código para eliminar completamente los riesgos por dependencias de datos:

Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Planificación de la emisión de instrucciones.
A nivel hardware ya hemos evitado casi todos los riesgos por dependencia de datos, pero cabe
una solución software al problema de las detenciones. El compilador puede reorganizar la secuencia
de instrucciones para evitar que se produzcan este tipo de detenciones por dependencias de datos. La
técnica de compilación que evita esto se conoce como:
planificación de la segmentación o planificación de instrucciones Si el software nos evita completamente este riesgo, podríamos evitar utilizar el hardware de control
para evitar este tipo de riesgos. La idea es buena, ya que existen máquinas en las cuales, la
responsabilidad de detectar y evitar este tipo de riesgos esta en manos del software completamente.
Pregunta: ¿Pero que ocurría cuando el compilador no podía evitar de ninguna forma este
tipo de riesgos?
Respuesta: No le quedaba más remedio que utilizar una instrucción tipo NOP después de
la carga para evitar el problema.
Esta inclusión no influía en el tiempo de ejecución del programa, pero si en la longitud del
código generado.
De todas formas, tanto si el hardware detecta el interbloqueo y detiene la segmentación como
si no, el rendimiento mejora si el compilador planifica la ejecución de las instrucciones.
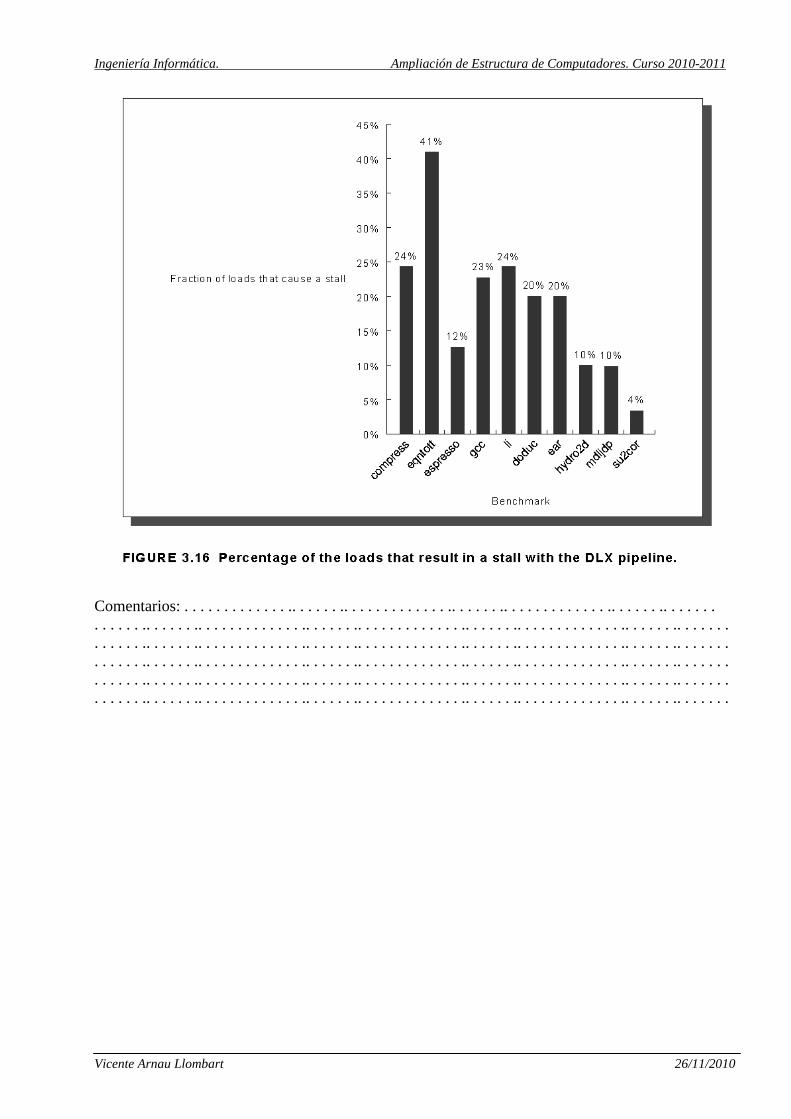
En la figura (6.13) de la página siguiente se observa como mejora el rendimiento de del
procesador si el compilador previamente planifica la ejecución de las instrucciones.
Porcentaje de las cargas que causan detención con la segmentación de DLX.
Ingeniería Informática. Ampliación de Estructura de Computadores. Curso 2010-2011
Vicente Arnau Llombart 26/11/2010
Comentarios: . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . .
. . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . .
. . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . .
. . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . .
. . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . .
. . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . .. . . . . . .. . . . . . .


















